语义分割/UDA-Bidirectional Learning for Domain Adaptation of Semantic Segmentation语义分割领域适应的双向学习
Bidirectional Learning for Domain Adaptation of Semantic Segmentation语义分割领域适应的双向学习
- 0.摘要
- 1.概述
- 2.相关工作
- 3.方法
-
- 3.1.双向学习
- 3.2. 自我监督学习提高M
- 3.3.网络架构和损失函数
- 4.讨论
-
- 4.1. 无SSL的双向学习
- 4.2. 使用SSL进行双向学习
- 4.3. 超参数学习
- 5.实验
-
- 5.1.网络架构
- 5.2.训练
- 5.3.数据集
- 5.4.与最新技术的比较
- 5.5.性能差距达到上限
- 6.结论
- 参考文献
论文地址
代码下载
0.摘要
语义图像分割的领域自适应是非常必要的,因为用像素级标签手动标记大型数据集既昂贵又耗时。现有的领域自适应技术要么在有限的数据集上工作,要么与有监督学习相比性能不佳。在本文中,我们提出了一种新的双向学习框架,用于领域自适应分割。通过双向学习,图像翻译模型和分割适应模型可以交替学习并相互促进。此外,我们还提出了一种自监督学习算法来学习更好的分割适应模型,从而改进图像翻译模型。实验表明,我们的方法在分割的领域自适应方面比现有的方法有很大的优势。
1.概述
图像语义分割的最新进展[18]是由在大型数据集上训练的深层神经网络推动的。不幸的是,由于需要大量人力,收集和手动注释具有密集像素级标签的大型数据集的成本非常高。计算机图形学的最新进展使得在具有计算机生成注释的真实照片合成图像上训练CNN成为可能[27,28]。尽管如此,真实图像(目标)和合成数据(源)之间的域不匹配削弱了模型的性能。域自适应解决了这个域转移问题。具体来说,我们关注的是问题的硬案例,即目标域中没有可用的标签。这类技术通常被称为无监督领域适应。
传统的域自适应方法需要最小化源分布和目标分布之间的距离。两种常用的度量是一阶矩和二阶矩[2],以及使用对抗性方法学习距离度量[34,35]。这两种方法在分类问题上都取得了很好的成功(例如,MNIST[16]、USPS[7]和SVHN[22]);然而,正如[37]所指出的,它们在语义分割问题上的性能相当有限
近年来,语义分割领域自适应技术已经取得了很大进展,它将语义分割分分为两个连续的步骤。它首先使用图像到图像转换模型(例如CycleGAN[38])将图像从源域转换到目标域,然后在分割模型的特征上添加一个鉴别器,以进一步减小域间距[12,36]。当前一步缩小域间距时,后一步易于学习,可以进一步减少域偏移。不幸的是,分割模型非常依赖于图像到图像转换的质量。一旦图像到图像的翻译失败,在接下来的阶段中就无法弥补。
本文提出了一种新的图像语义分割领域自适应双向学习框架。该系统包括两个独立的模块:图像到图像的翻译模型和类似于[12,36]的分割适应模型,但学习过程涉及两个方向(即“翻译到分割”和“分割到翻译”)。整个系统形成一个闭环学习。这两种模式将被激励相互促进,导致领域差距逐渐缩小。因此,如何让两个模块中的一个向另一个模块提供积极反馈是成功的关键。
在正向(即“translation-to - segmentation”,类似于[12,36])方向上,我们提出了一种自监督学习(self-supervised learning, SSL)方法来训练我们的segmentation adaptive model。与在真实数据上训练的分割模型不同,分割自适应模型是在合成数据集和真实数据集上训练的,但真实数据没有标注。在任何时候,我们都可以将对真实数据具有高置信度的预测标签视为ground truth标签的近似值,然后只使用它们来更新分割自适应模型,而将置信度较低的预测标签排除。这个过程被称为自我监督学习,它将两个领域结合起来,比在现有方法中广泛使用的一次尝试学习更好。此外,更好的分割自适应模型将有助于我们通过反向学习更好地构建翻译模型。
在反向方向上(即“segmentation-totranslation”),我们的平移模型会通过segmentation adaptive模型进行迭代改进,这与[12,36]中训练模型后,图像到图像的平移不会更新不同。为此,我们提出了一种新的感知损失,强制图像中每个像素点与其翻译版本之间的语义一致性,以建立翻译模型与分割自适应模型之间的桥梁。有了平移模型的约束,可以进一步减小平移后的图像与真实数据集(目标)在视觉外观(如光照、物体纹理)上的差距。因此,我们可以通过正向学习进一步改进分割模型。
在以上两个方向上,平移模型和分割自适应模型相互补充,实现了将大规模渲染图像数据集SYNTHIA [28]/GTA5[27]适配到真实图像数据集cityscape[5]上的最新性能,并大大优于其他方法。此外,该方法适用于不同类型的骨干网
总之,我们的主要贡献是:
- 提出了一种双向语义分割学习系统,该系统是一个闭环,可交替学习分割自适应模型和图像翻译模型。
- 我们提出了一种分割自适应模型的自监督学习算法,该算法基于翻译结果,在特征级增量对齐源域和目标域。
- 我们在图像-图像转换中引入了一种新的感知损失,通过更新的分割自适应模型来监督图像的转换。
2.相关工作
领域适应
在将知识从虚拟图像转移到真实照片的过程中,常常会出现从训练到测试阶段存在一定差异的情况。领域适应性旨在纠正这种不匹配,并在测试[24]时将模型调整为更好的泛化。现有的领域自适应研究主要集中在图像分类[30]上。许多研究的目标是通过最小化域分布差异来学习域不变表示。最大平均差异(MMD)损失[8],计算表示的平均值,是两个域之间的公共距离度量。作为MMD的扩展,一些特征分布的统计量如均值和协方差[2,21]被用来匹配两个不同的域。不幸的是,当分布不是高斯分布时,仅匹配均值和协方差不足以很好地对齐两个不同的域。
对抗学习[9]是近年来流行的一种领域自适应方法。它通过强迫来自不同域的特征来欺骗鉴别器来减少域漂移。[34]是该方法的先锋,它在两个域的高级特征的基础上引入了对抗损失和源数据集的分类损失,取得了比统计匹配方法更好的性能。除了对抗损耗外,一些研究还提出了一些额外的损耗函数来进一步减小域移动,如对每个类[4]的重权函数,以及对分离匹配[35]的解纠缠表示。所有这些方法都适用于简单和小型的分类数据集(如MNIST[16]和SVHN[22]),在更有挑战性的任务(如分割)中可能有相当有限的性能。
语义分割的领域自适应
近年来,针对语义分割模型提出了更多的领域自适应技术,因为对大量图像进行标注需要大量的劳动密集型工作,而这些工作又需要训练出高质量的分割网络。减轻人类工作的一个可能的解决方案是在自动标记的虚拟数据上训练网络。例如,GTA5[27]和SYHTHIA[28]是两个流行的城市街道合成数据集,它们具有重叠的类别,与真实数据集的视图相似(例如,CITYSCAPE [5], CamVid[1])。领域适应性可以用来对齐合成数据集和实际数据集。
为语义分割引入领域自适应的第一个工作是[13],它在特征级对两个领域进行全局和局部对齐。课程域自适应[37]估计超像素的全局分布和标签,然后学习更细像素的分割模型。在[33]中,对不同的层次特征使用多个鉴别器来减少域差异。在[31]中,分别对前景类和背景类进行处理,以减小域位移。所有这些方法的目标都是直接对齐两个域之间的特征。不幸的是,合成数据和真实数据之间的视觉(如外观、规模等)领域差距通常使网络难以学习可转移的知识。
受近期未配对图像到图像转换工作(如CycleGAN [38], UNIT [17], MUNIT[14])的进展推动,从虚拟到真实数据的映射被视为图像合成问题。在训练分割模型之前,可以有效地减少领域差异。基于翻译结果,Cycada[12]和DCAN[36]进一步在特征级对齐两个域之间的特征。通过分别减少学习中的领域转移,这些方法获得了最先进的性能。然而,图像到图像转换的质量限制了其性能。一旦失败,接下来的步骤就什么也做不了了。为了解决这个问题,我们引入了一个双向学习框架,在这个框架中,翻译和分割的自适应模型可以在一个闭环中相互促进。
有两个最相关的工作。在[6]中,分割模型也被用来改善图像的平移,但由于它只是在源数据上进行训练,所以不能使源域适应目标域。[39]还提出了一种自训练方法,对分割模型进行迭代训练。然而,分割模型只对源数据进行训练,没有使用任何图像平移技术。
双向学习
此类技术最早被提出是为了解决神经机器翻译问题,如[10,23],它们针对语言对的两个方向训练语言翻译模型。与单向学习相比,该方法提高了学习性能,减少了对大量数据的依赖。双向学习技术也被扩展到图像生成问题[25],它从上到下和下到上两个方向训练单个网络的分类和图像生成问题。更相关的工作[29]提出了双向图像平移(即源到目标和目标到源),然后分别在两个域上训练两个分类器,最后融合分类结果。而我们的双向学习指的是翻译促进了分割的表现,反之亦然。该方法用于处理语义分割任务。
3.方法
假设源数据集S有分割标签YS(如计算机图形学生成的合成数据),而目标数据集T没有标签(如真实数据),我们想训练一个用于语义分割的网络,最后在目标数据集T上进行测试。我们的目标是使它的性能尽可能接近T训练的模型得到地面真实标签YT。任务是无监督的领域适应语义分割。这一任务并不容易,因为S和T之间的视觉(如照明、比例、对象纹理等)领域差距使得网络很难一次性学习可转移知识。

图1:顺序学习vs双向学习
为了解决这个问题,最近的工作[12]提出了两个分离的子网。一个是图像到图像的平移子网络F,它学习在没有成对示例的情况下将图像从S转换到T。另一个是分割自适应子网络M,对翻译结果F(S)进行训练,翻译结果F(S)具有和S相同的标签YS,目标图像T没有标签。两个子网都是按图1(a)所示的顺序学习的。这样的两阶段解决方案有两个优点:1)F有助于缩小视觉域的差距;2)当领域差距减小时,M更容易学习,性能更好。然而,该解决方案有一些局限性。一旦学习F,它就固定了。M没有反馈来提高F的绩效,而且对M来说,一次尝试学习似乎只学习了有限的可转移知识。
在本节中,我们提出了一个新的学习框架,可以很好地解决上述两个问题。我们继承了分离子网络的方式,但采用了双向学习(3.1节),双向学习使用闭环迭代更新F和M。此外,我们引入了一种自我监督学习,允许M在训练中自我激励(3.2节)。网络结构和损耗函数在第3.3节中介绍。
3.1.双向学习
我们的学习由图1(b)所示的两个方向组成。
正向(即F→M)类似于之前的顺序学习[12]的行为。我们首先利用T和S的图像训练图像到图像的翻译模型F,然后得到翻译结果S’= F(S)。注意F不会改变S’的标签,这和YS (S的标签)是一样的,接下来,我们用S’和YS、T训练分割适应模型M。学习M的损失函数可以定义为:
![]()
其中ladv为对抗损失,使S’的特征表示与T的特征表示(将S’, T馈入M后得到)之间的距离尽可能小。lseg衡量的是语义分割的损失。由于只有S’有标签,所以我们只对翻译后的源图像S’进行精度评定。
反方向(即M→F)是新增的。动机是使用更新的M来提升F。在[35,14]中,在图像翻译网络中使用了一种感知损失,它测量了从一个预先训练的网络中获得的特征在物体识别上的距离,以提高平移结果的质量。在这里,我们使用M来计算特征来测量知觉损失。将GAN损失和图像重建损失相加,学习F的损失函数可以定义为:
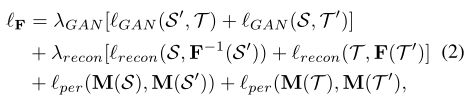
其中,对称计算S→T和T→S三个损耗,以保证图像到图像的平移一致。GAN损失lGAN在S’和T之间执行两个相似的分布。T’ = F−1 (T),其中F−1是F的反函数,它将图像从T映射到S。当图像从S’转换回S时,lrecon测量重建误差。lper是我们建议保持S和S’之间或T和T’之间语义一致性的感知损失。也就是说,一旦我们获得了一个理想的分割适应模型M,无论是S和S’,还是T和T’都应该有相同的标签,即使S和S’之间,或者T和T’之间存在视觉间隙。
- GAN:希望S’和T、T’和S之间具有相似的分布
- Reconstruction:希望S→F(S)=S’→F−1(S’)= (F−1 (F(S))=S,T→F(T)=T’→F−1(T’)= (F−1 (F(T))=T。也就是说希望翻译过去再翻译回来,内容保持一致
- Perception:希望S和S’、T和T’,在经过M进行特征提取之后,具有相似的特征,相同的标签
3.2. 自我监督学习提高M
在前进方向(即F→ M) 如果源域S和目标域T都有标签,则全监督分割损失lseg始终是减少域差异的最佳选择。但在我们的例子中,目标数据集的标签丢失了。正如我们所知,自监督学习(SSL)以前已经被用于半监督学习,尤其是当数据集的标签不足或有噪声时。在这里,我们使用SSL来帮助推广分割适应模型M。
基于T的预测概率,我们可以获得一些高置信度的伪标签。一旦我们有了伪标签,相应的像素可以根据分割损失直接与S对齐。因此,我们将用于学习M(方程式1)的总损失函数修改为:
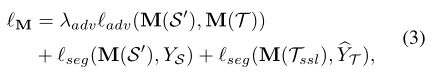
其中Tssl⊂T是目标数据集的子集,其中像素具有伪标签YΛT。一开始可以是空的。当实现了较好的分割自适应模型M时,我们可以使用M来预测T的高度自信的标签,从而导致Tssl的大小增长。最近的工作[39]也使用SSL进行分割适应。相比之下,在我们的工作中使用的SSL与对抗学习相结合,这可以更好地工作于分割适应模型。

我们使用图示(如图2所示)来解释这个过程的原理。当我们第一次学习分割适应模型时,Tssl为空,S和T之间的区域间隙可以减小,损耗如公式1所示。这个过程如图2 (a)所示。然后我们在目标域T中选取与S很好对齐的点来构造子集Tssl。在第二步中,我们可以很容易地将Tssl移到S,并利用伪标签提供的分割损失使它们保持对齐。这个过程如图2 (b)中间所示。因此,T中需要与S对齐的数据量减少了。我们能继续剩余的数据转移到步骤1一样,见图2 (b)的右边。值得注意的是,SSL可以帮助对抗学习过程,让对抗学习关注其余的数据没有完全对齐的每一步,因为ladv很难将来自S和Tssl的数据改变直至对齐
3.3.网络架构和损失函数

图3:网络模型和损失函数
在这一节中,我们介绍了网络的结构(如图3所示),损失函数的细节和训练过程(如图算法1所示)。网络主要由图像翻译模型和分割自适应模型两部分组成。
在学习平移模型的过程中,可以将lGAN和lrecon(如图3和方程2所示)定义为:

其中IS和IT是来自源数据集和目标数据集的输入图像。I’S是F.给出的经过翻译的图像,DF是为了减小IT和I’S之间的差异而增加的鉴别器。对于重构损失,当F−1是F的逆函数时,使用L1范数来保持IS和F−1(I’S)之间的循环一致性。这里我们只给出了一个方向的两个损耗,lGAN(S, T’),lrecon(T, F(T’))的定义类似。
如图3所示,知觉损失lper连接了翻译模型和分割适应模型。当我们学习翻译模型的感知损失时,除了保持IS及其翻译结果I’S之间的语义一致性外,我们还添加了另一个以λper_recon加权的项,以保持IS及其对应的重构F−1(I’S)之间的语义一致性。有了新的项,平移模型更加稳定,尤其是重构部分。lper被定义为:
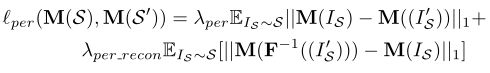
由于对称性,lper(M(T), M(T’))(如式2所示)也可以用类似的方法定义。
在训练分段适应模型时,它需要使用ladv进行对抗性学习,使用lseg进行自我监督学习(如等式3所示)。对于对抗性学习,我们添加了一个鉴别器DM,以减少图3所示的源概率和目标概率之间的差异。ladv可以定义为:

分割损失的lseg使用交叉熵损失。对于源图像,seg可以定义为:

其中,YS是Is的标签映射,C是类数,H和W是输出概率映射的高度和宽度。PS是分割适应模型的源概率,可以定义为PS=M(I’S)。对于目标图像,我们需要定义如何为其选择伪标签映射yΛT。我们选择使用一种我们称之为**“最大概率阈值(MPT)”的常用方法来过滤具有高预测置信度的像素**。因此,我们可以将yΛT定义为yΛT=argmax M(IT),将yΛT的掩码映射定义为mT=1 [argmax M(IT)>threshold]。因此,它的分割损失可以表示为:

式中,PT是M的目标输出。
我们在算法1中介绍了训练过程。培训过程包括两个循环。外环主要是通过前向和后向学习翻译模型和分段适应模型。内部循环主要用于实现SSL进程。在下一节中,我们将介绍如何选择学习F,M的迭代次数,以及如何估计SSL的MPT。

4.讨论
为了了解双向学习和自我监督学习对提高M的有效性,我们进行了一些研究。我们使用GTA5[27]作为源数据集,城市景观[5]作为目标数据集。翻译模型为CycleGAN[38],分割适应模型为DeepLab V2[3],主干为ResNet101[11]。以下所有实验均使用相同的模型,除非另有规定。
在这里,我们首先提供以下消融研究和表格中使用的符号说明。M(0)是启动双向学习的初始模型,仅使用源数据进行训练。M(1)使用源数据和目标数据进行对抗性学习。对于M(0)(F(1)),使用翻译模型F(1)翻译源数据,然后基于翻译后的源数据学习分割模型M(0)。对于k=1,2和i=0,1,2,M(k)i(F(k))表示算法1中外环的第k次迭代和内环的第i次迭代的模型。


图4:双向学习中每一步的分割结果
4.1. 无SSL的双向学习
我们展示了在没有SSL的双向学习系统中训练的模型得到的结果。在表1中,M(0)是我们的基线模型,它给出了mIoU的下限。我们发现模型M(1)和M(0)(F(1))的性能相似,两者都比M(0)提高了7%以上,M(1)(F(1))进一步提高了约1.6%。这意味着分割适应模型和翻译模型可以独立工作,当它们结合在一起时,基本上是双向学习的一个迭代,它们可以相互补充。我们进一步证明,通过继续训练双向学习系统,在这种情况下,用M(1)(F(1))代替M(0)作为向后方向,新模型M(2)0(F(2))可以提供更好的性能。
4.2. 使用SSL进行双向学习
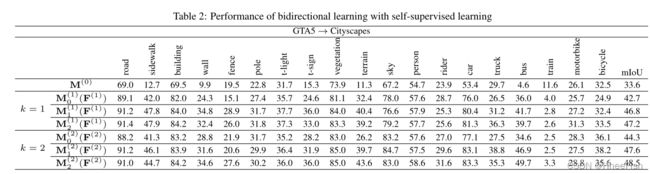
在本节中,我们将展示SSL如何进一步提高分段自适应模型的能力,并反过来影响双向学习过程。在表2中,我们展示了基于算法1的两次迭代(k=1,2)给出的结果。在图4中,我们展示了分割结果和由最大概率阈值(MPT)给出的相应掩模图,该阈值为0.9。在图4中,白色像素是预测置信度高于MPT的像素,黑色像素是低置信度像素
当k=1时,当使用SSL将模型M(1)0(F(1))更新为M(1)2(F(1))时,mIoU可以提高4.5%。我们可以发现,对于每个类别,当IoU低于50时,可以从M(1)0(F(1))到M(1)2(F(1))得到很大的改进。它可以证明我们之前在第3.2节中的分析,即使用SSL可以保留来自源域和目标域的对齐数据,并且可以通过对抗性学习过程进一步对齐其余数据。
当k=2时,我们首先用M(1)2(F(1))替换M(0)来开始向后的方向。在没有SSL的情况下,mIoU为44.3,与表1所示的结果相比,这是一个更大的改进。它可以进一步证明我们在第4.1节中关于分段适应模型在向后方向上所起的重要作用的讨论。此外,我们可以从表2中发现,尽管在第二次迭代开始时,mIoU从47.2下降到44.3,但在引入SSL时,mIoU可以提升到48.5 ,这比第一次迭代的结果要好。从图4所示的分割结果可以进一步证实我们的发现,最重要的是,随着我们提高分割性能,分割自适应模型可以提供更可靠的预测,这可以通过增加掩模图中的白色区域来观察。它让我们有动力使用掩码映射为算法1中的SSL进程选择阈值和迭代次数。
4.3. 超参数学习
我们将描述如何在算法1中选择阈值以高置信度过滤数据,以及迭代次数N。
当我们选择阈值时,我们必须在两倍之间保持平衡。一方面,我们希望预测的标签具有尽可能多的高置信度(在图4中显示为白色区域)。另一方面,我们希望避免由于错误的预测而产生过多的噪声,即阈值应尽可能高。我们在图5的左侧展示了预测置信度(M中每像素的最大类别概率)与选定像素和所有像素之间的比率(即图4中显示的所有白色区域的百分比)之间的关系,然后在图5的右侧展示了斜率。我们可以发现,当预测置信度从0.5增加到0.9时,比率几乎呈线性下降,斜率几乎保持不变。但从0.9到0.99,比率下降得更快。根据观察结果,我们选择拐点0.9作为阈值,作为所选标签数量和质量之间的权衡
为了进一步证明我们的选择,在表3中,我们展示了当算法1中的K=1和N=1时,使用不同阈值对MKN进行自监督学习的分割结果。作为另一种选择,我们也考虑软阈值而不是硬阈值,即每个像素被其最大类概率加权。我们在最下面一行显示结果。所有的结果都证实了我们的分析。当阈值低于0.9时,未修正的预测成为影响SSL性能的关键问题。当我们将阈值增加到0.95时,SSL过程对可以使用的像素数更敏感。当我们使用软阈值时,结果更糟。这可能是因为涉及到大量的标签噪声,并且不能通过为噪声标签分配较低的权重来很好地减轻不良影响。因此,在接下来的实验中,0.9似乎是一个很好的阈值选择。
对于迭代次数N,我们也根据预测的标签选择适当的值。当N增加时,分段适应模型变得更强,导致更多标签用于SSL。一旦SSL的像素比停止增加,这意味着分割自适应模型的学习收敛,几乎没有改善。我们肯定会增加K的值来开始另一个迭代。在表4中,我们展示了当我们增加N的值时,保持0.9的一些分割结果。我们可以发现,随着N的增加,mIoU变得更好。当N=2或3时,mIoU几乎停止增加,像素比率保持不变。这可能表明N=2是一个不错的选择,我们在工作中使用它。
5.实验
在本节中,我们将比较我们的方法和最先进的方法之间获得的结果。
5.1.网络架构
在我们的实验中,我们选择使用带有ResNet101[11]的DeepLab V2[3]和带有VGG16[32]的FCN-8s[18]作为分割模型。它们通过ImageNet预先训练的网络进行初始化[15]。我们为分段自适应模型选择的鉴别器类似于[26],它有5个卷积层,内核为4×4,通道号为{64、128、256、512、1},步长为2。对于除最后一层之外的每个卷积层,后面是参数化为0.2的泄漏ReLU[20]。对于图像翻译模型,我们遵循CycleGAN[38]的体系结构,包含9个块,并添加分割适应模型作为感知损失。
5.2.训练
当训练CycleGAN[38]时,图像被随机裁剪为452×452的大小,并训练20个时代。对于前10个阶段,学习率为0.0002,10个阶段后线性下降至0。我们在方程3中设置λGAN=1,λrecon=10,并设置λper=0.1,λ~per recon~=10,用于感知损失。在训练分割自适应模型时,图像的长边调整为1024,并且比例保持不变。DeepLab V2[3]和FCN-8s[18]使用了不同的参数。对于带有ResNet 101的DeepLab V2,我们使用SGD作为优化器。初始学习率为2.5×10−4,随着“poly”学习率政策的实施而降低,功率为0.9。对于带有VGG16的FCN-8s,我们使用Adam作为优化器,动量为0.9和0.99。初始学习率为1×10−5,并随着步长为5000且γ=0.1的“步长”学习率策略而降低。对于DeepLab V2和FCN-8s,我们使用的鉴别器与Adam optimizer训练的鉴别器相同,初始学习率为1×10−4个用于DeepLab V2和1×10−6个用于FCN-8s。动量设置为0.9和0.99。对于方程式1,我们为ResNet101设置λadv=0.001和为FCN-8s设置λadv=1×10−4。
5.3.数据集
正如我们之前提到的,两个合成数据集——GTA5[27]和SYNTHIA[28]被用作源数据集,城市景观[5]被用作目标数据集。对于GTA5[27],它包含24966张分辨率为1914×1052的图像,我们使用GTA5和Cityscapes数据集之间的19个常见类别。对于SYNTHIA[28],我们使用SYNTHIA-RAND-CITYSCAPES集合,其中包含9400张分辨率为1280×760的图像,以及16种常见的城市景观类别[5]。对于城市景观[5],它被分为训练集、验证集和测试集。该训练集包含2975幅分辨率为2048×1024的图像。我们仅将训练集用作目标数据集。由于测试集的地面真值标签缺失,我们必须使用包含500张图像的验证集作为我们实验中的测试集。
5.4.与最新技术的比较
我们将我们的方法与最先进的方法在两个不同的主干网络(分别是ResNet101和VGG16)上的结果进行了比较。我们在两个任务上进行比较:“GTA5到城市景观”和“SYNTHIA到城市景观”。在表5中,我们用ResNet101和VGG16展示了任务“GTA5到城市景观”的适应结果。我们可以观察到主干在所有域自适应方法中的作用,即ResNet101比VGG16获得更好的结果。在[37,33,19]中,他们主要关注具有不同对抗损失功能的特征级对齐。但仅仅在功能层面上工作是不够的,尽管其中最好的结果[36]仍然比我们的结果差5%左右。Cycada[12](我们使用ResNet101运行了他们的代码)和DCAN[36]使用翻译模型和分段适应模型进一步缩小了视觉领域的差距,两者都实现了非常相似的性能。与Cycada[12]相比,我们使用了类似的损失函数,但通过一种新的双向学习方法,可以实现6%的改进。CBST[39]提出了一种自训练方法,并利用空间先验信息进一步提高了性能。为了公平比较,我们展示了只使用自我训练的结果。使用VGG16,我们可以获得10.4%的改善。因此,我们可以发现,没有双向学习,自我训练的方法是不够的,以实现良好的表现。
在表6中,我们展示了针对ResNet101和VGG16的“SYNTHIA到城市景观”任务的适应结果。SYNTHIA和Cityscapes之间的领域差距远大于GTA5和Cityscapes之间的差距,而且它们的类别没有完全重叠。由于为ResNet101选择的基线结果[33,19]仅使用13个类别,我们还列出了13个类别的结果,以进行公平比较。我们可以从表6中发现,随着领域差距的增加,城市景观的适应结果比表5中的结果差得多。例如,像“道路”、“人行道”和“汽车”这样的类别要差10%以上。由于预测置信度较低,这个问题将对SSL产生不利影响。但我们仍然可以比[37,39,36,33]给出的大多数其他结果至少好4%。


5.5.性能差距达到上限
我们使用带有地面真值标签的目标数据集来训练分割模型,该模型与我们使用的主干相同,以获得上界结果。对于19个类别的“GTA5到城市景观”,ResNet101和VGG16的上限分别为65.1和60.3。对于“SYNTHIA to Cityscapes”,ResNet101有13个类别,VGG16有16个类别,上限分别为71.7和59.5。对于我们的方法,虽然性能差距至少为16.6,但与其他方法相比,它已显著降低。然而,这意味着仍有很大的改进空间。我们把它留在以后的工作中。
6.结论
在本文中,我们提出了一种基于自监督学习的双向学习方法来解决分割自适应问题。我们通过大量的实验表明,当模型进行双向训练时,可以提高真实数据集的分割性能,并在不同网络的多个任务中达到最先进的结果。
参考文献
[1] G. J. Brostow, J. Shotton, J. Fauqueur, and R. Cipolla. Segmentation and recognition using structure from motion point clouds. In ECCV (1), pages 44–57, 2008. 2
[2] F. M. Carlucci, L. Porzi, B. Caputo, E. Ricci, and S. R. Bulò. Autodial: Automatic domain alignment layers. In ICCV, pages 5077–5085, 2017. 1, 2
[3] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Y uille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2018. 5, 7
[4] Q. Chen, Y . Liu, Z. Wang, I. Wassell, and K. Chetty. Reweighted adversarial adaptation network for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7976– 7985, 2018. 2
[5] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 2, 5, 7
[6] A. Dundar, M.-Y . Liu, T.-C. Wang, J. Zedlewski, and J. Kautz. Domain stylization: A strong, simple baseline for synthetic to real image domain adaptation. arXiv preprint arXiv:1807.09384, 2018. 3
[7] J. Friedman, T. Hastie, and R. Tibshirani. The elements of statistical learning, volume 1. Springer series in statistics New Y ork, NY , USA:, 2001. 1
[8] B. Geng, D. Tao, and C. Xu. Daml: Domain adaptation metric learning. IEEE Transactions on Image Processing, 20(10):2980–2989, 2011. 2
[9] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014. 2
[10] D. He, Y . Xia, T. Qin, L. Wang, N. Y u, T. Liu, and W.-Y . Ma. Dual learning for machine translation. In Advances in Neural Information Processing Systems, pages 820–828, 2016. 3
[11] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 5, 7, 8
[12] J. Hoffman, E. Tzeng, T. Park, J.-Y . Zhu, P . Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle-consistent adversarial domain adaptation. arXiv preprint arXiv:1711.03213, 2017. 1, 2, 3, 8
[13] J. Hoffman, D. Wang, F. Y u, and T. Darrell. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016. 2, 8
[14] X. Huang, M.-Y . Liu, S. Belongie, and J. Kautz. Multimodal unsupervised image-to-image translation. arXiv preprint arXiv:1804.04732, 2018. 2, 3
[15] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012. 7
[16] Y . LeCun, L. Bottou, Y . Bengio, and P . Haffner. Gradientbased learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. 1, 2
[17] M.-Y . Liu, T. Breuel, and J. Kautz. Unsupervised image-toimage translation networks. In Advances in Neural Information Processing Systems, pages 700–708, 2017. 2
[18] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015. 1, 7
[19] Y . Luo, L. Zheng, T. Guan, J. Y u, and Y . Yang. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. arXiv preprint arXiv:1809.09478, 2018. 8
[20] A. L. Maas, A. Y . Hannun, and A. Y . Ng. Rectifier nonlinearities improve neural network acoustic models. In Proc. icml, volume 30, page 3, 2013. 7
[21] M. Mancini, L. Porzi, S. R. Bulò, B. Caputo, and E. Ricci. Boosting domain adaptation by discovering latent domains. arXiv preprint arXiv:1805.01386, 2018. 2
[22] Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y . Ng. Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, volume 2011, page 5, 2011. 1, 2
[23] X. Niu, M. Denkowski, and M. Carpuat. Bi-directional neural machine translation with synthetic parallel data. arXiv preprint arXiv:1805.11213, 2018. 3
[24] V . M. Patel, R. Gopalan, R. Li, and R. Chellappa. Visual domain adaptation: A survey of recent advances. IEEE signal processing magazine, 32(3):53–69, 2015. 2
[25] S. Pontes-Filho and M. Liwicki. Bidirectional learning for robust neural networks. arXiv preprint arXiv:1805.08006, 2018. 3
[26] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015. 7
[27] S. R. Richter, V . Vineet, S. Roth, and V . Koltun. Playing for data: Ground truth from computer games. In European Conference on Computer Vision, pages 102–118. Springer, 2016. 1, 2, 5, 7
[28] G. Ros, L. Sellart, J. Materzynska, D. V azquez, and A. M. Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3234–3243, 2016. 1, 2, 7
[29] P . Russo, F. M. Carlucci, T. Tommasi, and B. Caputo. From source to target and back: symmetric bi-directional adaptive gan. arXiv preprint arXiv:1705.08824, 3, 2017. 3
[30] K. Saenko, B. Kulis, M. Fritz, and T. Darrell. Adapting visual category models to new domains. In European conference on computer vision, pages 213–226. Springer, 2010. 2
[31] F. S. Saleh, M. S. Aliakbarian, M. Salzmann, L. Petersson, and J. M. Alvarez. Effective use of synthetic data for urban scene semantic segmentation. In European Conference on Computer Vision, pages 86–103. Springer, Cham, 2018. 2
[32] K. Simonyan and A. Zisserman. V ery deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 7, 8
[33] Y .-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. arXiv preprint arXiv:1802.10349, 2018. 2, 8
[34] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In Computer Vision and Pattern Recognition (CVPR), volume 1, page 4, 2017. 1, 2
[35] H. T. Vu and C.-C. Huang. Domain adaptation meets disentangled representation learning and style transfer. CoRR, 2017. 1, 2, 3
[36] Z. Wu, X. Han, Y .-L. Lin, M. G. Uzunbas, T. Goldstein, S. N. Lim, and L. S. Davis. Dcan: Dual channel-wise alignment networks for unsupervised scene adaptation. arXiv preprint arXiv:1804.05827, 2018. 1, 2, 3, 8
[37] Y . Zhang, P . David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In The IEEE International Conference on Computer Vision (ICCV), volume 2, page 6, 2017. 1, 2, 8
[38] J.-Y . Zhu, T. Park, P . Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. arXiv preprint, 2017. 1, 2, 5, 7
[39] Y . Zou, Z. Y u, B. V . Kumar, and J. Wang. Unsupervised domain adaptation for semantic segmentation via classbalanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), pages 289–305, 2018.