ICCV2019语义分割/UDA:ACE: Adapting to Changing Environments for Semantic SegmentationACE:适应变化环境下的语义分割
ACE: Adapting to Changing Environments for Semantic Segmentation ACE:适应变化环境下的语义分割
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.无监督领域适应
- 2.2.图像合成和风格化
- 2.3.终身学习
- 2.4.元学习
- 3.方法
-
- 3.1.通过编码器和生成器进行样式化
- 3.2.语义分割网络
- 3.3.记忆单元和风格回放
- 3.4.通过自适应元学习实现更快的适应
- 4.实验
-
- 4.1.实验设置
-
- 4.1.1.数据集和评估指标
- 4.1.2.网络架构
- 4.1.3.实现细节
- 4.2.结果和讨论
-
- 4.2.1.适应新任务的有效性
- 4.2.2.风格回放的有效性
- 4.2.3.与现有技术的比较
- 4.2.4.快速适应元更新
- 4.2.5.用GANs生成图像
- 5.结论
- 参考文献
论文下载
开源代码
0.摘要
当深层神经网络在相同的数据分布上进行训练和测试时,它们表现出非凡的准确性。然而,当面对输入分布随时间发生的域转移变化时,神经分类器往往非常脆弱。我们提出了ACE,这是一个语义分割框架,可以随着时间的推移动态地适应不断变化的环境。通过将原始源域中的标记训练数据的分布与移位域中的传入数据的分布相一致,ACE为它所看到的环境合成标记训练数据。然后使用这些样式化的数据更新分割模型,使其在新环境中表现良好。为了避免忘记过去环境中的知识,我们引入了一种存储以前看到的域的特征统计信息的内存。这些统计数据可以用来重放之前观察到的任何域中的图像,从而防止灾难性遗忘。除了使用随机梯度下降(SGD)的标准批量训练外,我们还实验了基于自适应元学习的快速自适应方法。在SYNTHIA的两个数据集上进行了大量实验,结果证明了该方法在适应多个任务时的有效性。
1.概述
当计算机视觉系统部署在现实世界中时,它们会暴露在不断变化的环境和非平稳的输入分布中,这会带来重大挑战。例如,使用晴朗天气下采集的图像优化的深度网络在夜间不同的照明条件下可能会出现严重故障。事实上,最近观察到,即使在输入分布发生微小变化[12]的情况下,深层网络也表现出严重的不稳定性,更不用说面对动态变化的信息流了。
通过收集足够的训练数据来覆盖测试时发生的所有可能的输入分布,可以避免域转移问题。然而,收集和手动注释数据的费用使得这在许多应用程序中不可行。这对于详细的视觉理解任务尤其如此,比如目标检测和语义分割,在这些任务中,图像注释是非常费力的。值得注意的是,人类具有“终身学习”的能力,即利用过去积累的知识分析新的任务和环境。然而,在深度神经网络中实现同样的目标并非易事,因为(i)新的数据域在没有标签的情况下实时出现,(ii)深度网络遭受灾难性遗忘[33],在优化新任务时,先前学习的任务的性能会下降。
我们考虑了将预训练模型适应动态变化的环境的终身学习问题,这些环境的分布反映了不同的光照和天气条件。特别地,我们假设从一个原始的源环境访问图像标签对,而只有来自新的目标环境的未标记的图像,这些图像在训练数据中没有观察到。此外,我们考虑了随着时间的推移而造成的困难,目标环境依次出现。
我们关注语义分割的具体任务,因为它在自动驾驶中的实际应用,视觉识别系统有望处理变化的天气和照明条件。这个应用程序使我们能够利用图形渲染工具从不同分布收集数据的便利性[43,42]。
为此,我们引入了ACE,这是一个框架,它将预先训练好的分割模型适应以顺序方式到达的新任务流,同时将历史风格信息存储在紧凑的内存中以避免遗忘。特别是,给定一个新任务,我们使用图像生成器在像素级别将(标记的)源数据的分布与(未标记的)传入目标数据的分布对齐。这会生成带有颜色和纹理属性的标记图像,这些属性密切反映目标域,然后直接用于在新的目标域上训练分割网络。样式转换是通过重新规范化源图像的特征映射来实现的,因此它们具有与目标图像匹配的一阶和二阶特征统计信息[19,60]。这些重新规范化的特征映射然后被输入到生成样式化图像的生成器网络中。
ACE的独特之处在于其终生学习的能力。为了防止遗忘,ACE包含一个紧凑且轻量级的内存,用于存储不同样式的特征统计信息。这些统计数据足以以任何历史样式重新生成图像,而无需存储历史图像库。利用记忆,历史图像可以被重新生成,并在整个时间内用于训练,从而阻止灾难性遗忘的有害影响。整个生成和细分框架可以与SGD进行端到端的联合培训。最后,我们考虑使用自适应元学习的主题,以便于在遇到新环境时更快地适应新环境。
我们的主要贡献总结如下:
- 我们提出了一个轻量级的语义分割框架,它能够通过简单快速的优化来适应源源不断的传入分布;
- 我们引入了一个存储特征统计信息的内存,用于高效的风格回放,这有助于在不忘记以前任务的知识的情况下对新任务进行概括;
- 我们考虑元学习策略以加快适应新问题域的速率;
- 我们在SYNTHIA[44]的两个子集上进行了大量实验,实验证明了我们的方法在适应不同天气和光照条件下的一系列任务时的有效性。
2.相关工作
2.1.无监督领域适应
我们的工作涉及无监督领域自适应,其目的是在不访问标签的情况下测试新分布时,提高预训练模型的泛化能力。沿着这条研究路线的现有方法可以减少特征或像素级别的域差异。特别是,特征级自适应侧重于通过最小化源域和目标域之间距离的概念来对齐用于目标任务(例如,分类或分割)的特征表示。这种距离概念可以是以最大平均差异(MMD)[31,4]和协方差[54]等形式表示的明确度量。;或者通过反向梯度[8,9]、域混淆[57]或生成性对抗网络[58,16,17,45,18]等对抗损失函数隐式估计使特征域不变
像素级自适应通过使用减少纹理和照明不一致的映射,将来自不同域的图像转换为看起来像来自相同分布的图像[3,52,55,29]。最近也有一些方法试图同时对齐像素级和特征级表示[15、62、69]。此外,Zhang等人介绍了一种课程策略,该策略使用全局标签分布和局部超像素分布进行调整。Saleh等人在处理域移位时使用检测方法处理前景类[46]。我们的框架与之前的工作不同,因为我们正在适应一系列按顺序到达的测试域,而不是单一的固定域,这是一个挑战,因为它需要网络在当前和所有以前的域上都能很好地执行。请注意,虽然我们主要关注像素级对齐,但我们的方法可以进一步受益于分割网络中的特征级对齐,但代价是保存原始图像,而不仅仅是特征统计。此外,我们的方法还与[63,2,14]有关,它们通过在特征级别对齐来执行分类任务的顺序自适应,而我们的方法则侧重于在像素级别对齐的语义分割。
2.2.图像合成和风格化
人们越来越有兴趣使用生成性对抗网络(GAN)合成图像[65,38,29],这是一个生成器和鉴别器之间的极大极小博弈[11]。为了控制生成过程,添加了大量附加信息,包括标签[36]、文本[41]、属性[49]和图像[21,25]。GANs也被用于图像到图像的翻译,即使用循环一致性[71]或映射到共享特征空间[28,20]将图像的样式转换为参考图像的样式。在不知道域的联合分布的情况下,这些方法试图从每个域学习具有边缘分布的条件分布。然而,使用GANs生成高分辨率图像仍然是一个困难的问题,并且需要大量计算[23]。相比之下,神经风格转移的方法[10,19,59,37,22]通常避免了生成建模的困难,只需匹配Gram矩阵的特征统计信息[10,22],或执行均值和方差的通道对齐[27,19]。在我们的工作中,我们建立在风格转换的基础上,以当前任务中的图像风格合成新图像,同时保留源图像的内容。
2.3.终身学习
我们的工作还与终身学习或持续学习有关,即利用过去积累的知识逐步学习并适应新任务。大多数现有的研究都集中在减轻学习新任务时的灾难性遗忘[24,67,40,50,51,32,5]。最近的几种方法建议在新任务到达时动态增加模型容量[66,64]。我们的工作重点是如何以无监督的方式使学习到的分割模型适应一系列新任务,每个任务的图像分布都不同于最初用于训练的图像分布。此外,为了避免忘记过去学习到的知识,使用样式的特征统计信息来表示和编目样式。因为这种表示比原始图像小得多,所以该框架是可伸缩的。
2.4.元学习
元学习[48,56],也称为learning to learn,是一种设置,其中一个代理接收一组任务,每个任务本身就是一个学习问题,然后建立一个模型,该模型可以快速适应来自同一分布的不可见任务。元学习者分为三类:(i)基于模型的外部记忆[47,34];(ii)基于公制的[61];(iii)基于优化[7,35]。现有的方法主要关注镜头分类、回归和强化学习问题,而我们的方法则关注如何有效地适应分割模型。
3.方法
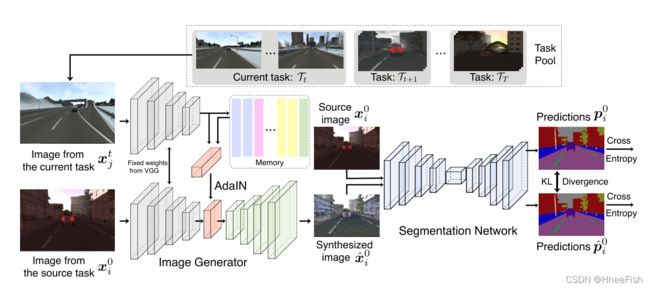
图2:提议框架的概述。给定一个传入任务,ACE合成新的图像,保留源任务的内容,但采用目标任务的风格。这可以通过将传入图像的样式信息传输到源图像,或者从内存单元采样样式信息来实现。利用这些不同风格的合成图像,训练分割网络在不忘记过去所学知识的情况下对新的任务进行归纳。
ACE的目标是将一个分割模型从一个源任务调整到多个具有不同图像分布的顺序呈现的目标任务。该方法将标记的源图像传输到目标域,为分割模型创建合成训练数据,同时存储样式信息,用于样式回放,以防止遗忘
更正式地说,T0表示源任务,{Ti}Ti=0表示按顺序到达的T个目标任务。我们进一步使用X0={(x01,y01),··,(x0N,y0N)}来表示用于源任务的N个图像及其相应的标签。标签y0i包含图像x0i中每个像素的独热标签向量;我们将第i个图像样本表示为x0i∈ R3×H×W和y0i∈ {0,1}C×H×W表示相应的标签映射,H和W分别表示高度和宽度,C表示类的数量。
对于每个后续的目标任务,我们假设只访问图像,而不是像在源任务中那样访问图像标签对。我们进一步将目标任务的数量表示为T,并使用Xt={xt1,···,xtNt}t∈ [1···T]表示第T个传入任务的图像集,该任务具有与源数据相同分辨率的Nt个图像。
ACE包含四个关键组件:编码器、生成器、内存和分割网络。编码器网络将源图像x0i转换为特征表示z0i(在我们的例子中,是512个输出特征映射的堆栈)。 生成器网络将要素表达z转换为图像。结果图像的样式可以通过修改z的统计数据(每个特征图的平均值和标准偏差)来控制/操纵,然后再将其交给生成器。内存单元记住每个图像样式\域的特征统计信息(每个样式1024个标量值,对应于512个特征映射中每个特征映射的平均值和标准偏差)。通过从存储单元中检索相关的样式统计信息,重新规范化源图像的特征映射以获得相应的统计信息,然后将重新规范化的特征传递给生成器以创建图像,可以将源图像样式化为任何先前看到的域。
3.1.通过编码器和生成器进行样式化
显示新任务时,通过将源图像(及其附带的标签)传输到目标域,在新任务域中创建带标签的图像。为此,我们联合训练了一个生成网络,用于生成目标样式化图像,以及一个分割网络,用于处理目标域中的图像。
图像生成管道从一个编码器开始,该编码器从图像中提取特征映射。我们使用一个经过预训练的VGG19网络[53]作为编码器,从relu4获取输出来定义fenc。[26,19]之后,编码器的权重在训练期间被冻结,以分别从图像x0i和xtj中提取固定表示形式fenc(x0i)=z0i和fenc(xtj)=ztj。
图像生成器fgen由权重ψgen参数化,将特征映射解卷积为图像。输出图像的样式可以借用具有AdaIN【19】的目标图像,其重新规范化源图像的特征映射(即通道) z0i,以具有与所选目标图像zti的映射相同的平均值和标准偏差:

这里,σ(z)和µ(z)分别计算z的每个通道的平均值和方差。归一化特征映射zˆ0i可以填充到生成器中,以合成新图像xˆ0i=fgen(zˆ0i;ψgen)。如果适当调整参数ψgen,生成的图像将具有x0i的内容,但样式为xtj。
我们训练生成器,使其充当编码器的逆对象;编码器应该将解码后的图像(大致)映射到生成它的特征上。我们通过最小化以下损失函数来实现这一点:

这里,第一项(内容丢失)测量生成的图像的特征和源图像的对齐特征之间的差异,目的是保留源图像中的内容。剩下的两个项通过匹配每个通道特征映射的均值和方差,将生成的图像强制为xtj样式。请注意,一些作者匹配gram矩阵[10,62],以使样式一致。我们匹配特征图的均值和方差,如[27,59]所示,因为这些统计数据易于优化,并且包含足够的信息,可以获得良好的样式化。与使用几层进行对齐[27,19]不同,我们只需匹配VGG编码器中的一层特征图,这一点更快但足够了。更重要的是,这有助于轻量级风格的回溯,如下所述。
3.2.语义分割网络
新合成的图像x0i=fdec(z~;ψgen)被交给分割网络fseg,由权重ψseg参数化。该网络产生标签向量pˆ0i=fseg(xˆ0i;ψseg)的映射,并通过最小化像素上求和的多类交叉熵损失来训练。此外,由于合成图像可能会丢失原始图像的某些细节,这可能会降低分割网络的性能,因此我们进一步限制来自分割网络对合成图像xˆ0i预测的输出pˆ0i,使其在样式化之前接近原始图像x0i的预测p0i。这是通过测量这两个输出之间的KL差异来实现的,这在本质上类似于知识提炼[13],原始图像的输出充当教师。分割损失的形式如下:

最后,结合Eqn.2和Eqn.3.我们有以下目标函数:

其中ψ={ψseg,ψgen}表示网络的参数。请注意,分割损失隐含地取决于生成器参数,因为分割是在生成器的输出上执行的。
3.3.记忆单元和风格回放
优化Eqn 4可以减少源任务和目标任务之间的差异,但目前尚不清楚如何在不忘记过去学习到的知识的情况下,使模型持续适应包含潜在不同图像分布的传入任务序列。一种简单的方法是存储以前任务的历史图像库,然后在学习新任务时从库中随机抽取图像进行回放。然而,这需要大的工作内存,这可能是不可行的,尤其是在分割任务中,图像通常具有高分辨率(例如,城市景观中的图像为1024×2048[42])。
幸运的是,Eqn.1中提出的对齐过程仅使用源图像合成来自目标分布的图像,并且特征映射ztj中每个通道的均值和方差来自目标图像。因此,我们只需要将特征统计数据(均值和方差均为512-D)保存在内存M中,以便高效地重放。在学习第t个任务Tt时,我们选择一个测试图像样本,并将其1024-D特征统计信息存储在内存中。在适应下一个任务Tt+1时,除了从Xt中采样外,我们还随机访问内存M(其中包含来自前一个任务的样式信息),以合成类似于实时看到的任务的图像,以便回放。
3.4.通过自适应元学习实现更快的适应
元学习[7,35,39]中的最新方法产生了灵活的模型,该模型具有元参数的特性,它们可以通过几次SGD更新快速适应新任务。而标准SGD在优化Eqn4时提供了良好的性能。对于足够多的epoch,我们现在探索适应性元学习能否产生加速适应性的模型。
为此,我们使用Reptile[35],这是MAML[7]方法的廉价近似方法。Reptile首先随机选择一个任务,然后执行SGD的多个步骤来微调该任务的模型,从而更新元模型的参数。然后在微调参数的方向上采取“meta-gradient”步骤。下一次迭代将继续执行不同的任务,以此类推,以生成一个元模型,其中的参数与各种任务的最佳参数之间只有很小的差异。
准确地说,Reptile的元梯度gt(ψ)定义为:
![]()
这里Uk(ψt)表示随机选择任务的标准SGD的k个步骤。为了实现快速适应,我们从当前任务和内存中取样,使用整个任务历史中的元梯度执行元更新。然后对当前任务的元梯度进行微调,以评估性能。算法在Alg1中进行了总结。
4.实验
在本节中,我们首先介绍实验设置和实现细节。然后,我们在两个数据集上报告了我们提出的框架的结果,并进行了一些讨论。


4.1.实验设置
4.1.1.数据集和评估指标
由于我们的方法旨在处理共享相同标签空间的不同输入分布,用于分割任务,我们使用来自SYNTHIA[44]的各种天气和照明条件的数据,这是一个使用渲染引擎生成的用于城市场景语义分割的大规模合成数据集。我们使用SYNTHIA- seqs,这是SYNTHIA的一个子集,显示了在不同季节捕获的虚拟汽车的观点。这个数据集可以分解为“夏”、“冬”、“雨”、“冬夜”等各种天气和光照条件(见表1)。我们考虑SYNTHIA-SEQS中的两个地方,HIGHWAY和NYC-LIKE CITY,分别包含9个和10个光照条件不同的视频序列。我们将每个序列视为一个任务,平均大约有1000张图像,每个任务被进一步均匀地分成一个训练集和一个验证集。
我们首先在“黎明”场景中使用标记图像训练一个分割模型,然后在无监督设置中使学习到的模型适应每个序列中的剩余任务。在适应过程中[68,16],我们只访问来自第一个任务(即“dawn”)的带标签的图像,以及来自当前任务的未带标签的图像。为了评估分割模型的性能,我们报告了每个任务的验证集上的平均相交-过并集(mIoU)以及所有任务的平均mIoU。
4.1.2.网络架构
我们使用预训练的VGG19网络作为编码器,解码器的结构在补充材料中详细介绍。我们用三种不同的分割架构(FCN-8s-ResNet101、DeepLab V3+[6]和ResNet50-PSPNet[70])评估了我们的框架的性能,它们在标准基准上显示了巨大的成功。FCN-8sResNet101是FCN-8s-VGG网络[30]的扩展,使用ResNet101作为骨干,而不是VGG19。ResNet50-PSPNet包含一个金字塔池模块,用于派生包含足够上下文信息的不同级别的表示[70]。DeepLab V3+[6]引入了一个解码器来沿着对象边界细化分割结果。
4.1.3.实现细节
我们使用PyTorch进行实现,并使用SGD作为优化器,其权重衰减为5 × 10−5,动量为0.99。我们将学习率设置为10−3,并使用标准SGD对源任务和目标任务进行培训,优化10000次迭代。为了使用元梯度进行快速适应,我们执行了50个元更新步骤。我们在一个小批量中抽取三个源图像进行训练,对于源任务中的每个图像,我们随机抽取两个参考图像,一个来自当前目标任务,一个来自记忆,作为生成新图像的样式参考。对于样式重放,内存缓存每个任务100个特征向量,表示来自100个目标图像的样式信息。
4.2.结果和讨论
4.2.1.适应新任务的有效性

表1:不同骨干网适应变化环境的结果。这里的“Source”表示直接将segmentation model应用到目标任务中,而不需要进行适应。A、B、C分别代表FCN-8s-ResNet101、DeepLab V3+[6]、ResNet50-PSPNet[70]。
表1给出了ACE的结果以及与纯源方法的比较,纯源方法直接将源任务训练后的模型应用到目标任务中,不需要任何自适应。我们可以看到,当目标任务的分布与源任务的分布显著不同时(即FCN-8s-ResNet101从“dawn”到“‘winter”下降15.4%,从“dawn”到“winter night”下降10.9%),源模型的性能大幅下降。另一方面,ACE可以有效地对齐源任务和目标任务之间的特征分布,比纯源方法表现出明显的优势。例如,ACE使用FCN8s-ResNet101在HIGHWAY和NYC-LIKE CITY上分别获得了3.4和9.6个(绝对百分点)的收益。此外,使用ResNet50-PSPNet和DeepLab V3+,我们可以看到类似的趋势,证实该框架适用于不同的高性能网络的细分。在不同的网络中比较,ResNet50-PSPNet在两个数据集上提供了最佳的平均miou。虽然DeepLab V3+在源任务上取得了最好的效果,但其泛化能力有限,应用于“冬夜”任务时性能下降超过36.3%。然而,ACE可以成功地恢复具有适应性的性能。此外,我们还观察到高速公路上的表现比使用不同网络的NYC-LIKE CITY上的表现更高,这是因为与高速公路相比,场景中城市中的“交通标志”等小物体更杂乱。图4利用高速公路上的ResNet50-PSPNet进一步可视化了ACE和纯源方法生成的预测图。
4.2.2.风格回放的有效性

表2:ACE的性能取决于存储在内存单元中的范例样式特性的数量。每个任务的默认特性数是100,尽管我们发现可以通过增加存储向量的数量来略微改进。
我们现在使用内存中每个任务不同数量的特征向量来研究样式重放的性能。表2给出了结果。在HIGHWAY和NYC-LIKE CITY上,当不使用样本进行重放时,ACE的准确率分别下降了2.4%和2.9%,这证实了风格重放确实有助于回忆已学过的知识,防止遗忘。没有回复的ACE仍然比只有来源的方法更好,因为分割网络仍然在更新不同风格的输入。当存储更多的范例特征向量(即每个任务200)到内存中,ACE在HIGHWAY和NYC-LIKE CITY上分别可以略微提高0.4%和0.3%。在这里,我们只是使用随机抽样的方法来重新生成任何历史样式的图像,我们相信抽样方法可以通过更高级的策略[5]进一步改进。
4.2.3.与现有技术的比较

表3:与现有技术的比较。除了IADA[63]和ADDAREPLAY[2]之外,我们还比较了两种基线方法。

图4:不同方法的预测图可视化。使用ResNet50-PSPNet和相应的源模型对采样图像的预测结果。黑色表示在培训期间将忽略的类。
我们现在比较了几种最近提出的基于FCN-8sResNet101的方法:(1)source - reverse将测试图像传输到源图像的风格,然后直接应用分割模型;(2) IADA使用对抗性损失函数[58]将当前任务的特征分布与源任务的特征分布[63]以连续的方式对齐,这样,经过训练的评论家就不能再区分特征分布;(3) ADDA-REPLAY存储以前的样本和预测分数,并使用匹配损失来约束从以前的任务分割输出保持不变的适应进展。结果汇总于表3。我们可以看到,ACE取得了最好的结果,明显优于其他方法,特别是在NYC-LIKE CITY,实现了6.9%的增长。
尽管source - reverse是一种对齐特性分布的直接方法,但性能比直接应用源模型更差。我们怀疑这种性能下降是由于分割引擎所训练的原始源数据与从未进行过训练的样式所传输的数据之间微小但系统的差异造成的。ACE则对合成图像进行分割网络训练,并对生成图像的分割输出进行约束,使其与源图像的输出相兼容。此外,IADA通过按顺序排列特征分布,略微改进了仅源模型,然而,它依赖于一个很难优化[1]的对抗性损失函数。更重要的是,虽然IADA对于分类任务是成功的,但对于分割这样的任务,在不同的距离尺度上使用多个分类器进行深度监督[70,30],很难知道应该对齐哪些feature map来获得最佳性能。此外,我们还可以看到,通过使用内存重放,ADDA-REPLAY比IADA提供了更好的结果,但这需要存储以前任务的所有样本。
注意,ADDA[58]侧重于在特性级而不是像素级对齐分布,这减少了我们方法中的低级差异。等,我们的方法是互补的方法,探索在分割网络中的特征级对齐,以存储图像样本的重放的代价。当ADDA与ACE相结合时,在高速公路和类似nyc的城市中,分别取得了0.7%和0.6%的进一步改善。
4.2.4.快速适应元更新

图3:使用ACE-Meta快速适应的结果。ACE-Slow:使用SGD进行10K迭代的全批训练。ACE-Fast:使用600次迭代的SGD批量训练(与ACE-Meta相同)。
ACE通过使用数万次SGD更新对每个任务进行批量训练,取得了良好的效果。我们也对如何利用元学习的最新进展来快速适应目标任务感兴趣。我们提出了元更新方法(ACE-Meta),它使用爬行器学习元参数,然后使用600次SGD迭代对特定任务进行微调。我们比较了ACE-Fast,它也使用每个任务600次迭代,但没有元学习,还有ACE-Slow,它使用SGD进行10K次迭代的完整批处理训练。结果总结在图3中。几乎在相同的设置下,无论是高速公路还是NYC-LIKE城市的所有目标任务,ACE-Meta都比ACE-Fast取得了更好的性能,当我们将模型应用于“冬季”和“冬夜”时,我们观察到明显的收益。此外,ACE-Meta的结果与SGD的全批训练不相上下,表明元更新能够学习不同任务之间的结构。
4.2.5.用GANs生成图像

图5:不同图像合成方法的比较。将该方法生成的图像从“黎明”转换为“冬季”,并与MUNIT进行比较。
在图5中,我们比较了ACE生成的图像与MUNIT[20]生成的图像。MUNIT学习风格的图像从一个领域转移到另一个一致性,通过学习共享空间正规化循环相比,CycleGAN[71],它可以合成不同的结果集的编码风格和内容编码器解开一代的风格和内容。注意,MUNIT也依赖于AdaIN来控制风格,但使用GAN损耗来生成。我们可以看到,使用我们的方法生成的图像保留了更详细的内容(例如,建筑的立面),并成功地将雪转移到人行道上,而使用MUNIT生成的图像中存在伪影(例如,模糊区域)。
5.结论
我们提出了ACE框架,该框架可以动态地适应一个预先训练的模型,以适应受域转移影响的未标记任务序列流。ACE利用风格回放来很好地概括新任务,而不会忘记过去获得的知识。特别是,给定一个新任务,我们介绍了一个图像发生器使分布在由合成新图像进行像素级的内容源任务,但风格的目标任务,这样标签的地图从源图像可以直接用于训练网络分割。这些生成的图像用于优化分割网络,以适应新的目标分布。为了防止遗忘,我们还引入了一个存储单元,存储生成不同图像样式所需的图像统计数据,并随着时间的推移回放这些样式,以防止遗忘。我们还研究了如何使用元学习策略来加速适应的速度。在SYNTHIA上进行了广泛的实验,表明所提出的框架可以有效地适应天气和光照条件变化的一系列任务。未来的研究方向包括如何处理涉及重大几何不匹配的分布变化
参考文献
[1] M. Arjovsky and L. Bottou. Towards principled methods for training generative adversarial networks. In ICLR, 2017. 7
[2] A. Bobu, E. Tzeng, J. Hoffman, and T. Darrell. Adapting to continuously shifting domains. In ICLR Workshop, 2018. 2, 7
[3] K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Krishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. In CVPR, 2017. 2
[4] K. Bousmalis, G. Trigeorgis, N. Silberman, D. Krishnan, and D. Erhan. Domain separation networks. In NIPS, 2016. 2
[5] F. M. Castro, M. J. Marin-Jimenez, N. Guil, C. Schmid, and K. Alahari. End-to-end incremental learning. In ECCV, 2018. 3, 7
[6] L.-C. Chen, Y . Zhu, G. Papandreou, F. Schroff, and H. Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 2018. 5, 6
[7] C. Finn, P . Abbeel, and S. Levine. Model-agnostic metalearning for fast adaptation of deep networks. In ICML, 2017. 3, 5
[8] Y . Ganin and V . S. Lempitsky. Unsupervised domain adaptation by backpropagation. In ICML, 2015. 2
[9] Y . Ganin, E. Ustinova, H. Ajakan, P . Germain, H. Larochelle, F. Laviolette, M. Marchand, and V . Lempitsky. Domainadversarial training of neural networks. JMLR, 2016. 2
[10] L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. In CVPR, 2016. 2, 4
[11] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Generative adversarial nets. In NIPS, 2014. 2
[12] D. Hendrycks and T. Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. In ILCR, 2019. 1
[13] G. E. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. CoRR, 2015. 4
[14] J. Hoffman, T. Darrell, and K. Saenko. Continuous manifold based adaptation for evolving visual domains. In CVPR, 2014. 2
[15] J. Hoffman, E. Tzeng, T. Park, J.-Y . Zhu, P . Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In ICML, 2018. 2
[16] J. Hoffman, D. Wang, F. Y u, and T. Darrell. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. CoRR, 2016. 2, 5
[17] W. Hong, Z. Wang, M. Yang, and J. Y uan. Conditional generative adversarial network for structured domain adaptation. In CVPR, 2018. 2
[18] H. Huang, Q. Huang, and P . Krahenbuhl. Domain transfer through deep activation matching. In ECCV, 2018. 2
[19] X. Huang and S. Belongie. Arbitrary style transfer in realtime with adaptive instance normalization. In ICCV, 2017. 2, 4
[20] X. Huang, M.-Y . Liu, S. Belongie, and J. Kautz. Multimodal unsupervised image-to-image translation. In ECCV, 2018. 2, 8
[21] P . Isola, J.-Y . Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In CVPR, 2017. 2
[22] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016. 2
[23] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of gans for improved quality, stability, and variation. In ICLR, 2018. 2
[24] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. V eness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. PNAS, 2017. 3
[25] C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In CVPR, 2017. 2
[26] Y . Li, C. Fang, J. Yang, Z. Wang, X. Lu, and M.-H. Yang. Universal style transfer via feature transforms. In NIPS, 2017. 4
[27] Y . Li, N. Wang, J. Liu, and X. Hou. Demystifying neural style transfer. In IJCAI, 2018. 2, 4
[28] M.-Y . Liu, T. Breuel, and J. Kautz. Unsupervised image-toimage translation networks. In NIPS, 2017. 2
[29] M.-Y . L. Liu and O. Tuzel. Coupled generative adversarial networks. In NIPS, 2016. 2
[30] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. 6, 7
[31] M. Long, Y . Cao, J. Wang, and M. I. Jordan. Learning transferable features with deep adaptation networks. In ICML, 2015. 2
[32] D. Lopez-Paz et al. Gradient episodic memory for continual learning. In NIPS, 2017. 3
[33] M. McCloskey and N. J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation. 1989. 1
[34] T. Munkhdalai and H. Y u. Meta networks. In ICML, 2017. 3
[35] A. Nichol, J. Achiam, and J. Schulman. On first-order metalearning algorithms. CoRR, 2018. 3, 5
[36] A. Odena, C. Olah, and J. Shlens. Conditional image synthesis with auxiliary classifier gans. In ICML, 2017. 2
[37] G. Perarnau, J. van de Weijer, B. Raducanu, and J. M. Álvarez. Invertible conditional gans for image editing. In NIPS Workshop, 2016. 2
[38] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016. 2
[39] S. Ravi and H. Larochelle. Optimization as a model for fewshot learning. In ILCR, 2017. 5
[40] S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert. icarl: Incremental classifier and representation learning. In CVPR, 2017. 3
[41] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image synthesis. In ICML, 2016. 2
[42] S. R. Richter, V . Vineet, S. Roth, and V . Koltun. Playing for data: Ground truth from computer games. In ECCV, 2016.
[43] G. Ros, L. Sellart, J. Materzynska, D. V azquez, and A. M. Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, 2016. 2
[44] G. Ros, S. Stent, P . F. Alcantarilla, and T. Watanabe. Training constrained deconvolutional networks for road scene semantic segmentation. CoRR, 2016. 2, 5
[45] K. Saito, K. Watanabe, Y . Ushiku, and T. Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In CVPR, 2018. 2
[46] F. S. Saleh, M. S. Aliakbarian, M. Salzmann, L. Petersson, and J. M. Alvarez. Effective use of synthetic data for urban scene semantic segmentation. In ECCV. Springer, 2018. 2
[47] A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap. Meta-learning with memory-augmented neural networks. In ICML, 2016. 3
[48] J. Schmidhuber, J. Zhao, and M. Wiering. Shifting inductive bias with success-story algorithm, adaptive levin search, and incremental self-improvement. Machine Learning, 1997. 3
[49] W. Shen and R. Liu. Learning residual images for face attribute manipulation. In CVPR, 2017. 2
[50] H. Shin, J. K. Lee, J. Kim, and J. Kim. Continual learning with deep generative replay. In NIPS, 2017. 3
[51] K. Shmelkov, C. Schmid, and K. Alahari. Incremental learning of object detectors without catastrophic forgetting. In ICCV, 2017. 3
[52] A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb. Learning from simulated and unsupervised images through adversarial training. In CVPR, 2017. 2
[53] K. Simonyan and A. Zisserman. V ery deep convolutional networks for large-scale image recognition. In ICLR, 2015. 4
[54] B. Sun and K. Saenko. Deep CORAL - correlation alignment for deep domain adaptation. In ECCV, 2016. 2
[55] Y . Taigman, A. Polyak, and L. Wolf. Unsupervised crossdomain image generation. In ICLR, 2017. 2
[56] S. Thrun and L. Pratt. Learning to learn: Introduction and overview. In Learning to learn. 1996. 3
[57] E. Tzeng, J. Hoffman, T. Darrell, and K. Saenko. Simultaneous deep transfer across domains and tasks. In ICCV, 2015. 2
[58] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In CVPR, 2017. 2, 7
[59] D. Ulyanov, V . Lebedev, A. V edaldi, and V . S. Lempitsky. Texture networks: Feed-forward synthesis of textures and stylized images. In ICML, 2016. 2, 4
[60] D. Ulyanov, A. V edaldi, and V . S. Lempitsky. Instance normalization: The missing ingredient for fast stylization. CoRR, 2016. 2
[61] O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra, et al. Matching networks for one shot learning. In NIPS, 2016. 3
[62] Z. Wu, X. Han, Y .-L. Lin, M. Gokhan Uzunbas, T. Goldstein, S. Nam Lim, and L. S. Davis. Dcan: Dual channel-wise alignment networks for unsupervised scene adaptation. In ECCV, 2018. 2, 4
[63] M. Wulfmeier, A. Bewley, and I. Posner. Incremental adversarial domain adaptation for continually changing environments. In ICRA, 2018. 2, 7
[64] J. Xu and Z. Zhu. Reinforced continual learning. In NIPS, 2018. 3
[65] D. Y oo, N. Kim, S. Park, A. S. Paek, and I.-S. Kweon. Pixellevel domain transfer. In ECCV, 2016. 2
[66] J. Y oon, E. Yang, J. Lee, and S. J. Hwang. Lifelong learning with dynamically expandable networks. In ICLR, 2018. 3
[67] F. Zenke, B. Poole, and S. Ganguli. Continual learning through synaptic intelligence. In ICML, 2017. 3
[68] Y . Zhang, P . David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In ICCV, 2017. 5
[69] Y . Zhang, Z. Qiu, T. Yao, D. Liu, and T. Mei. Fully convolutional adaptation networks for semantic segmentation. In CVPR, 2018. 2
[70] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene parsing network. In CVPR, 2017. 5, 6, 7
[71] J.-Y . Zhu, T. Park, P . Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. In ICCV, 2017. 2, 8