SoundTouch与Rubber Band Library变声算法对比与ASR结果分析
详细内容见群文件,欢迎大家加入音频/识别/合成算法群(696554058)交流学习,谢谢!
本内容原创,转载和使用请注明出处,谢谢配合;
- 变声背景与目的
目前基于对语音识别数据收集缓慢且质量不高的情况,内部开会决定尝试用变声算法来实现数据翻倍,前期已实现通过加不同特征的噪声实现数据翻倍,测试结果证明识别鲁棒性明显增强了。变声算法理论上可以实现任意维度的声音变化,但基于对K12口语语音识别考虑,暂时考虑性别和年龄维度的变化。测试数据集分为两部分,一部分是开源数据集librispeech,另一部分是内部整理的所有已标注数据集summarize_all_corpus*。
- 算法原理与内容
常用的开源变声算法有SoundTouch 和Rubber Band Library。其中 SoundTouch是一款用C++编写的开源的音频处理库,可以改变音频文件或实时音频流的节拍(Tempo)、音调(Pitch)、回放率(Playback Rates),还支持估算音轨的稳定节拍率(BPM rate),采用32位浮点或者16位定点,支持单声道或者双声道,采样率范围为8k - 48k。ST的3个效果互相独立,也可以一起使用。这些效果通过采样率转换、时间拉伸结合实现,常用于音乐变声变调。Tempo节拍 :通过拉伸时间,改变声音的播放速率而不影响音调。Playback Rate回放率 : 以不同的速率来播放,通过采样率转换实现。Pitch音调 :在保持节拍不变的前提下改变声音的音调,结合采样率转换+时间拉伸实现。如:增高音调的处理过程是:将原音频拉伸时长,再通过采样率转换,同时减少时长与增高音调变为原时长。通常ST处理的对象是PCM数据,一般是wav音频文件,对于其他格式的文件需要先转码成wav文件再进行变声。根据GNU宽通用公共许可证(LGPL)v2.1获得许可 。 可根据要求提供商业非LGPL许可证替代品。图1和图2 分别给出常用的变声算法SOLA和相位声码器。(具体参见http://www.surina.net/soundtouch/ )
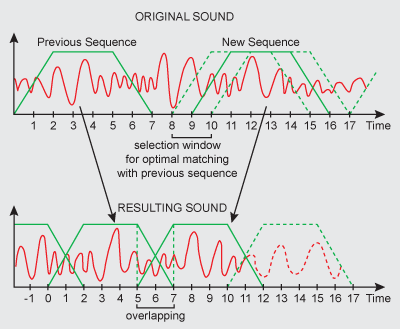
图1 SOLA算法图(https://www.surina.net/article/time-and-pitch-scaling.html )
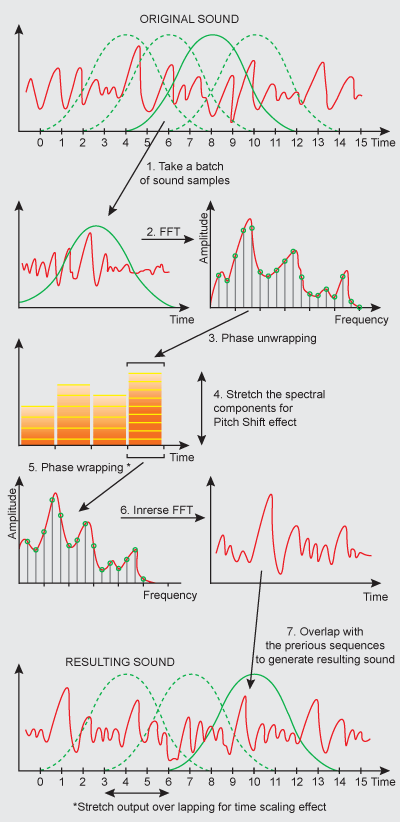
图2 相位声码器
Rubber Band Library是一个高质量的C++软件库,用于音频时间拉伸和音高变换。它可以改变音频流的速度和音高,或者实现动态单独变化来进行音乐录制。该库旨在供开发人员使用,而不是直接由最终用户创建自己的应用程序,尽管它还包括一个简单的(免费)命令行实用程序,可用于固定调整现有的速度和间距音频文件。它是GNU通用公共许可证下的开源软件。如果要将其分发到专有商业应用程序中,则需要购买许可证。 (具体参见 https://www.breakfastquay.com/ )
- 特性对比与测试
ST主要特性:
1.易于实现:ST为所有支持gcc编译器或者visual Studio的处理器或操作系统进行了编译,支持Windows、Mac OS、Linux、Android、Apple iOS等。
2.完全开源:ST库与示例工程完全开源可下载
3.容易使用:编程接口使用单一的C++类
4.支持16位整型或32位浮点型的单声道、立体声、多通道的音频格式
RB主要特性:
1.能实现精确的时间拉伸和音高变化。
2.满足实时处理要求,多线程,多核支持,准确计算延迟;
3.能够在运行中平稳地改变BPM ;
4.以任何采样率支持任意数量的通道,能够应对任意BPM 。
5.高品质的变声结果,更适合音乐使用其默认设置,从打击乐循环到单独的乐器录音和完整的混音,提供两个参数的微调设置。
6.支持真正的实时无锁流模式,实时性好,允许在使用过程中自由调整时间和音高比例。
测试数据:
Librispeech
(原声)
1.train-clean-5_tempo(10)_rate_(1)_pitch_(3) 年龄偏小,语速过快,女声更明显,相对2声音厚实一点且慢一点
2.train-clean-5_tempo(15)_rate_(1)_pitch_(5) 年龄更小,声音更尖更细,相对1更快一点
3.train-clean-5_tempo(15)_rate_(2)_pitch_(5) 跟2没有明显区别,从频率成分来看都是往高频移动了100-200Hz
4.train-clean-5_tempo(15)_rate_(5)_pitch_(5) 语速更快,声音和2,3区别不大
5.train-clean-5_tempo(15)_rate_(5)_pitch_(7) 声音很嗲,很尖,语速快无情感成分,很干,很涩
(具体数据见\LibriSpeech\train-clean-5)
summarize_all_corpus
(原声)
1.summarize_all_corpus_tempo(15)_rate_(-5)_pitch_(-3) 年龄偏大,但非成人声音,语速比正常慢一点,鼻音很重,男声更明显
2.summarize_all_corpus_tempo(15)_rate_(-5)_pitch_(-5) 效果跟上差不多,但声音更闷,缺乏明亮
3.summarize_all_corpus_tempo(10)_rate_(-5)_pitch_(-3) 声音更加清脆,但年龄偏大
(具体数据见\summarize_all_corpus)
- 结果分析
最终反复对比选择librispeech 中第一组合第三组分别对kaldi中GMM-HMM模型训练,最后结果来看单独变声数据WER达到17%多,与原始数据合并以后的WER比原始的WER略低。对于summarize_all_corpus数据目前还在测试当中,无详细数据。
附件:
批处理matlab代码和C编译可执行程序包(test.zip),详细内容见群(696554058)文件;
本文简单介绍了不同变声算法功能特性和针对kaldi语音识别的测试结果,具体使用需根据使用场景做进一步测试,欢迎大家加入音频/识别/合成算法群(696554058)交流学习,谢谢!