《DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation》翻译(上)
Abstract
This paper introduces an extremely efficient CNN architecture named DFANet for semantic segmentation under resource constraints. Our proposed network starts from a single lightweight backbone and aggregates discriminative features through sub-network and sub-stage cascade respectively. Based on the multi-scale feature propagation, DFANet substantially reduces the number of parameters, but still obtains sufficient receptive field and enhances the model learning ability, which strikes a balance between the speed and segmentation performance. Experiments on Cityscapes and CamVid datasets demonstrate the superior performance of DFANet with 8× less FLOPs and 2× faster than the existing state-of-the-art real-time semantic segmentation methods while providing comparable accuracy. Specifically, it achieves 70.3% Mean IOU on the Cityscapes test dataset with only 1.7 GFLOPs and a speed of 160 FPS on one NVIDIA Titan X card, and 71.3% Mean IOU with 3.4 GFLOPs while inferring on a higher resolution image.
摘要
本文介绍了一种非常有效的CNN架构,名为DFANet,用于资源约束下的语义分割。我们提出的网络从单个轻量级网络框架开始,分别通过子网和子级级联聚合判别特征。基于多尺度特征传播,DFANet大大减少了参数的数量,但仍然获得了足够的感受野,提高了模型学习能力,在速度和分割性能之间取得了平衡。 在Cityscapes和CamVid数据集上的实验证明了DFANet的优越性能,其FLOP比现有的最先进的实时语义分割方法少8倍,同时提供相当的精度。具体来说,它在Cityscapes测试数据集上实现了70.3%的平均IOU,在一张NVIDIA Titan X卡上只有1.7 GFLOP和160 FPS的速度,在推出更高分辨率的图像时,有71.3%的平均IOU和3.4 GFLOP。
1. Introduction
Semantic segmentation, which aims to assign dense labels for all pixels in the image, is a fundamental task in computer vision. It has a number of potential applications in the fields of autonomous driving, video surveillance, robot sensing and so on. For most such applications, how to keep efficient inference speed and high accuracy with highresolution images is a critical question.
1.介绍
语义分割旨在为图像中的所有像素分配密集标签,这是计算机视觉中的基本任务。 它在自动驾驶,视频监控,机器人传感等领域具有许多潜在的应用。 对于大多数此类应用,如何使用高分辨率图像保持有效的推理速度和高精度是一个关键问题。
Previous real-time semantic segmentation approaches [1][25][27][29][33][22] have already obtained promising performances on various benchmarks[10][9][18][36][2]. However, the operations on the high-resolution feature maps consume significant amount of time in the U-shape structures. Some works reduce the computation complexity by restricting the input image size[27], or pruning the redundant channels in the network to boost the inference speed[1][22]. Though these methods seem effective, they easily lose the spatial details around boundaries and small objects. Also, a shallow network weakens feature discriminative ability. In order to overcome these drawbacks, other methods [33][29] adopt a multi-branch framework to combine the spatial details and context information. Nevertheless, the additional branches on the high-resolution image limit the speed, and the mutual independence between branches limits the model learning ability in these methods.
以前的实时语义分割方法[1] [25] [27] [29] [33] [22]已经在各种基准上获得了有希望的表现[10] [9] [18] [36] [2]。 然而,高分辨率特征图上的操作在U形结构中消耗大量时间。 一些工作通过限制输入图像大小[27]或修剪网络中的冗余信道来提高推理速度[1] [22],从而降低了计算复杂度。 虽然这些方法似乎很有效,但它们很容易丢失边界和小物体周围的空间细节。 此外,浅网络削弱了特征辨别能力。 为了克服这些缺点,其他方法[33] [29]采用多分支框架来组合空间细节和上下文信息。 然而,高分辨率图像上的附加分支限制了速度,并且分支之间的相互独立性限制了这些方法中的模型学习能力。
Commonly, semantic segmentation task usually borrows ’funnel’ backbone pretrained from image classification task, such as ResNet[11], Xception[8], DenseNet[13] and so on. For real-time inference, we adopt a lightweight backbone model and investigate how to improve the segmentation performance with limited computation. In mainstream semantic segmentation architectures, a pyramid-style feature combination step like Spatial Pyramid Pooling[34][5] is used to enrich features with high-level context, while leading a sharp increase in computational cost. Moreover, traditional methods usually enrich the feature maps from the final output of a single path architecture. In this kind of design, the high-level context is lacking in incorporation with the former level features which also retain the spatial detail and semantic information in the network path. In order to enhance the model learning capacity and increase the receptive field simultaneously, feature reuse is an immediate thought. This motivates us to find a lightweight method to incorporate multi-level context into encoded features.
通常,语义分割任务通常借用从图像分类任务预训练的“漏斗”框架,如ResNet [11],Xception [8],DenseNet [13]等。对于实时推理,我们采用轻量级模型框架,并研究如何通过有限的计算来提高分割性能。在主流语义分割体系结构中,类似于空间金字塔池化[34] [5]的金字塔式特征组合步骤用于丰富具有高级上下文的特征,同时导致计算成本的急剧增加。此外,传统方法通常从单路径架构的最终输出中丰富特征映射。在这种设计中,高级上下文缺乏与前一级特征的结合,这些特征也保留了网络路径中的空间细节和语义信息。为了增强模型学习能力并同时增加感受野,特征重用是一种直接的想法。这促使我们找到一种将多级上下文合并到编码特征中的轻量级方法。
In our work, we deploy two strategies to implement cross-level feature aggregation in our model. First, we reuse high-level features extracted from the backbone to bridge gap between semantic information and structure de- tails. Second, we combine features of different stages in the processing path of the network architecture to enhance feature representation ability. These ideas are visualized in Figure 2.
在我们的工作中,我们部署了两种策略来在我们的模型中实现跨级别的特征聚合。 首先,我们重用从骨干中提取的高级特征来弥合语义信息和结构细节之间的差距。 其次,我们将网络体系结构处理路径中不同阶段的特征结合起来,以增强特征表示能力。 这些想法在图2中可视化。
In detail, we replicate the lightweight backbone to verify our feature aggregation methods. Our proposed Deep Feature Aggregation Network (DFANet) contains three parts: the lightweight backbones, sub-network aggregation and sub-stage aggregation modules. Because depthwise separable convolution is proved to be one of the most efficient operation in real-time inference, we modify the Xception network as the backbone structure. In pursuit of better accuracy, we append a fully-connected attention module in the tail of the backbone to reserve the maximum receptive field. Sub-network aggregation focuses on upsampling the highlevel feature maps of the previous backbone to the input of the next backbone to refine the prediction result. From another perspective, sub-network aggregation can be seen as a coarse-to-fine process for pixel classification. Sub-stage aggregation assembles feature representation between corresponding stages through ”coarse” part and ”fine” part. It delivers the receptive field and high dimension structure details by combining the layers with the same dimension. After these three modules, a slight decoder composed of convolution and bilinear upsampling operations is adopted to combine the outputs of each stage to generate the coarse-to-fine segmentation results. The architecture of the proposed network is shown in Figure 3.
具体来说,我们复制轻量级框架以验证我们的特征聚合方法。我们提出的深度特征聚合网络(DFANet)包含三个部分:轻量级网络框架,子网络聚合和子阶段聚合模块。由于深度可分卷积被证明是实时推理中最有效的操作之一,因此我们将Xception网络修改为backbone结构。为了追求更高的准确性,我们在backbone末端添加了一个基于注意力机制的全连接模块,以保留最大的感受野。子网络聚合侧重于将先前backbone的高级特征映射上采样到下一个backbone的输入以改进预测结果。从另一个角度来看,子网络聚合可以被视为在像素分类中由粗略到精细的过程。子阶段聚合通过“粗略”部分和“精细”部分组装相应阶段之间的特征表示。它通过组合具有相同尺寸的层来提供感受野和高维结构细节。在这三个模块之后,采用由卷积和双线性上采样操作组成的轻量解码器来组合每个阶段的输出以生成粗略到精细的分割结果。所提出的网络的体系结构如图3所示。
We test the proposed DFANet on two standard benchmarks, Cityscapes and CamVid. With a 1024×1024 input, DFANet achieves 71.3% Mean IOU with 3.4G FLOPs and speed of 100 FPS on a NVIDIA Titan X card. While implemented on a smaller input size and a lighter backbone, the Mean IOU still stays in 70.3% and 67.1% with only 1.7G FLOPs and 2.1G FLOPs respectively, better than most of the state-of-the-art real-time segmentation methods.
我们在Cityscapes和CamVid这两个标准基准测试中测试了提出的DFANet。 凭借1024×1024输入,DFANet在NVIDIA Titan X卡上实现了71.3%的平均IOU和3.4G FLOP以及100 FPS的速度。 虽然在较小的输入尺寸和较轻的backbone上实现,但平均IOU仍然分别保持在70.3%和67.1%,仅分别具有1.7G FLOP和2.1G FLOP,优于大多数最先进的实时分割方法。
Our main contributions are summarized as follows:
- We set a new record for the real-time and low calculation semantic segmentation. Compared to existing works, our network can be up to 8× smaller FLOPs and 2× faster with better accuracy.
- We present a brand new segmentation network structure with multiple interconnected encoding streams to incorporate high-level context into the encoded features.
- Our structure provides a better way to maximize the usage of multi-scale receptive fields and refine highlevel features several times while computation burden increases slightly.
- We modify the Xception backbone by adding a FC attention layer to enhance receptive field with little additional computation.
我们的主要贡献总结如下:
- 我们获得了实时和低计算量的语义分割上的新记录。与现有工作相比,我们的网络可以提供高达8倍的FLOP和2倍的更快速度,并且具有更高的准确性。
- 我们提供了一个全新的分段网络结构,其中包含多个互连的编码流,以将高级上下文合并到编码的功能中。
- 我们的结构提供了一种更好的方法,可以最大限度地利用多尺度感知字段并多次优化高级特征,同时计算负担略有增加。
- 我们通过添加FC感知层来修改Xception backbone,以增加感受野,几乎不需要额外的计算。
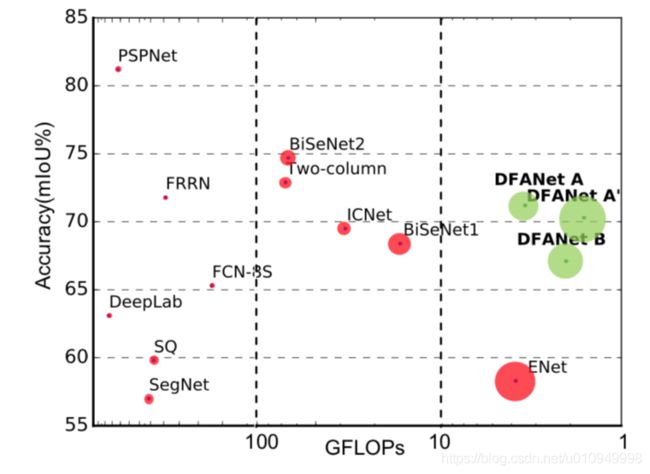
Figure 1. Inference speed, FLOPs and mIoU performance on Cityscapes test set. The bigger the circle, the faster the speed. Results of existing real-time methods, including ICNet[33], ENet[22], SQ[25], SegNet[1], FRRN[24], FCN-8S[19], Two- Column[27], BiSeNet[29]. Two classical networks DeepLab[7] and PSPNet[34] are displayed. Also, Our DFANet based on two backbone networks and two input sizes are compared.
图1. Cityscapes测试集的推理速度,FLOP和mIoU性能。 圆圈越大,速度越快。 现有实时方法的结果,包括ICNet [33],ENet [22],SQ [25],SegNet [1],FRRN [24],FCN-8S [19],双列[27],BiSeNet [29]。 显示两个经典网络DeepLab [7]和PSPNet [34]。 此外,我们比较了基于两个骨干网和两个输入大小的DFANet。
2. Related Work
Real-time Segmentation: Real-time semantic segmentation algorithms are aiming to generate the high-quality prediction under limited calculation. SegNet[1] utilizes a small architecture and pooling indices strategy to reduce network parameters. ENet[22] considers reducing the number of downsampling times in pursuit of an extremely tight framework. Since it drops the last stages of the model, the receptive field of this model is too small to segment larger objects correctly. ESPNet[26] performs new spatial pyramid module to make computation efficient. ICNet[33] uses multi-scale images as input and a cascade network to raise efficiency. BiSeNet[29] introduces spatial path and semantic path to reduce calculation. Both in ICNet and BiSeNet, only one branch is deep CNN for feature extraction, and other branches are designed to make up resolution details. Different from these methods, we enhance a single model capacity in feature space to reserve more detail information.
实时分割:实时语义分割算法旨在在有限的计算下生成高质量的预测。 SegNet [1]利用小型架构和汇集指数策略来减少网络参数。 ENet [22]考虑在追求极其紧凑的框架时减少下采样次数。 由于它会丢弃模型的最后阶段,因此该模型的感知区域太小,无法正确分割较大的对象。 ESPNet [26]执行新的空间金字塔模块以提高计算效率。 ICNet [33]使用多尺度图像作为输入和级联网络来提高效率。 BiSeNet [29]引入了空间路径和语义路径来减少计算。 在ICNet和BiSeNet中,只有一个分支是用于特征提取的深度CNN,而其他分支用于构成分辨率细节。 与这些方法不同,我们在特征空间中增强单个模型容量以保留更多详细信息。
Depthwise Separable Convolution: Depthwise separable convolution (a depthwise convolution followed by a pointwise convolution), is a powerful operation adopted in many recent neural network designs. This operation reduces the computation cost and the number of parameters while maintaining similar (or slightly better) performance. In particular, our backbone network is based on the Xception model[8], and it shows efficiency in terms of both accuracy and speed for the task of semantic segmentation.
深度可分离卷积:深度可分卷积(深度卷积后跟逐点卷积)是最近许多神经网络设计中采用的有力操作。 该操作降低了计算成本和参数数量,同时保持了相似(或略微更好)的性能。 特别是,我们的backbone网络基于Xception模型[8],它表现出了语义分割任务的准确性和速度方面的效率。
High-level Features: The key issues in segmentation task are about the receptive field and the classification ability. In a general encoder-decoder structure, high-level feature of the encoder output depicts the semantic information of the input image. Based on this, PSPNet[34], DeepLab series[7][5][4], PAN[16] apply an additional operation to combine more context information and multi-scale feature representation. Spatial pyramid pooling has been widely employed to provide a good descriptor for overall scene interpretation, especially for various objects in multiple scales. These models have shown high-quality segmentation results on several benchmarks while usually need huge computing resources.
高级特征:分割任务中的关键问题是感知领域和分类能力。 在通用编码器 - 解码器结构中,编码器输出的高级特征描绘了输入图像的语义信息。 基于此,PSPNet [34],DeepLab系列[7] [5] [4],PAN [16]应用了一个额外的操作来组合更多的上下文信息和多尺度特征表示。 空间金字塔池化被广泛用于为整体场景解释提供良好的描述符,尤其是对于多尺度的各种对象。 这些模型在几个基准测试中显示出高质量的分割结果,同时通常需要巨大的计算资源。
Context Encoding: As SE-Net[12] explores the channel information to learn a channel-wise attention and has achieved state-of-the-art performance in image classification, attention mechanism becomes a powerful tool for deep neural networks[3]. It can be seen as a channelwise selection to improve module features representation. EncNet[32][20][6] introduces context encoding to enhance per-pixel prediction that is conditional on the encoded semantics. In this paper, we also propose a fully-connected module to enhance backbone performance, which has little impact on calculation.
上下文编码:随着SE-Net [12]探索渠道信息以学习渠道关注并在图像分类中取得了最先进的性能,注意机制成为深度神经网络的有力工具[3]。 它可以被视为改进模块特征表示的渠道选择。 EncNet [32] [20] [6]引入了上下文编码来增强以像素编码语义为条件的每像素预测。 在本文中,我们还提出了一个完全连接的模块来增强backbone性能,这对计算几乎没有影响。
Feature Aggregation: Traditional approaches implement a single path encoder-decoder network to solve pixelto-pixel prediction. As the depth of network increase, how to aggregate features between blocks deserves further attention. Instead of simple skip connection design, RefineNet[17] introduces a complicated refine module in each upsampling stage between the encoder and decoder to extract multi-scale features. Another aggregation approach is to implement dense connection. The idea of dense connections has been recently proposed for image classification in [13] and extended to semantic segmentation in [14] [28]. DLA[31] extent this method to develop deeper aggregation structures to enhance feature representation ability.
特征聚合:传统方法实现单路径编码器 - 解码器网络以解决像素到像素预测。 随着网络深度的增加,如何在块之间聚合特征值得进一步关注。 RefineNet [17]在编码器和解码器之间的每个上采样阶段引入了一个复杂的细化模块,以提取多尺度特征,而不是简单的跳过连接设计。 另一种聚合方法是实现密集连接。 密集连接的概念最近已被提出用于[13]中的图像分类,并扩展到[14] [28]中的语义分割。 DLA [31]将此方法扩展到更深层次的聚合结构以增强特征表示能力。
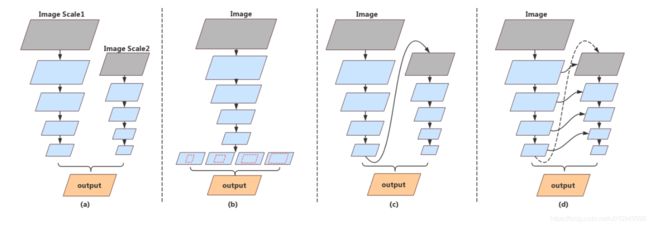
Figure 2. Structure Comparison. From left to right: (a) Multi-branch. (b) Spatial pyramid pooling. (c) Feature reuse in network level. (d) Feature reuse in stage level. As a comparison, the proposed feature reuse methods enrich features with high-level context in another aspect.
图2.结构比较。 从左到右:(a)多分支。(b)空间金字塔汇集。 (c)网络级别的特征重用。 (d)阶段级别的特征重用。 作为比较,所提出的特征重用方法在另一方面丰富了具有高级上下文的特征。
3.Deep Feature Aggregation Network
We start with our observation and analysis of calculation volume when applying current semantic segmentation methods in the real-time task. This motivates our aggregation strategy to combine detail and spatial information in different depth position of the feature extraction network to achieve comparable performance. The whole architecture of Deep Feature Aggregation Network (DFANet) is illustrated in Figure 3.
3.深度特征聚合网络
我们从在实时任务中应用当前语义分割方法时对计算量的观察和分析开始。 这促使我们的聚合策略将特征提取网络的不同深度位置中的细节和空间信息组合以实现可比较的性能。 Deep Feature Aggregation Network(DFANet)的整个架构如图3所示。
3.1. Observations
We take a brief overview of the segmentation network structures, shown in Figure 2.
我们简要概述了分段网络结构,如图2所示。
For real-time inference, [33][29] apply multiple branches to perform multi-scale extraction and preserve image spatial details. For example, BiSeNet[29] proposed a shallow network process for high-resolution images and a deep network with fast downsampling to strike a balance between classification ability and receptive filed. This structure is displayed in Figure 2(a). Nevertheless, the drawback of these methods is obvious that these models are short of dealing with high-level features combined from parallel branches, since it merely implements convolution layers to fuse features. Moreover, features lack communication between parallel branches. Also, the additional branches on high-resolution images limit the acceleration of speed.
对于实时推理,[33] [29]应用多个分支来执行多尺度提取并保留图像空间细节。 例如,BiSeNet [29]提出了一种用于高分辨率图像的浅层网络过程和一种具有快速下采样的深度网络,以在分类能力和接收域之间取得平衡。 该结构如图2(a)所示。 然而,这些方法的缺点显而易见,这些模型缺乏处理由并行分支组合的高级特征,因为它仅仅实现了卷积层以融合特征。 此外,功能缺乏并行分支之间的通信。 此外,高分辨率图像上的附加分支限制了速度的加速。
In semantic segmentation task, spatial pyramid pooling (SPP) module is a common approach to deal with highlevel features [5] (Figure 2(b)). The ability of spatial pyramid module is to extract high-level semantic context and increase receptive field, such as [4][34][16]. However, implementing spatial pyramid module is usually time-consuming.
在语义分割任务中,空间金字塔池(SPP)模块是处理高级特征的常用方法[5](图2(b))。 空间金字塔模块的能力是提取高级语义上下文并增加感受野,如[4] [34] [16]。 但是,实现空间金字塔模块通常很耗时。
Inspired by the above methods, we firstly replace the high-level operation by upsampling the output of a network and refining the feature map with another sub-network, as shown in Figure 2(c). Different from SPP module, the feature maps are refined on a larger resolution and sub-pixel details are learned simultaneously. However, as the whole structure depth grows, high-dimension features and receptive field usually suffer precision loss since the feature flow is a single path.
受上述方法的启发,我们首先通过对网络输出进行上采样并用另一个子网络优化特征映射来替换高级操作,如图2(c)所示。 与SPP模块不同,特征图在更大的分辨率上得到细化,并且同时学习子像素细节。 然而,随着整个结构深度的增加,高维特征和感受场通常会遭受精确损失,因为特征流是单一路径。
Pushing a bit further, we propose stage-level method (Figure 2(d)) to deliver low-level features and spatial information to semantic understanding. Since all these subnetworks have the similar structure, stage-level refinement can be produced by concatenating the layers with the same resolution to generate the multi-stage context. Our proposed Deep Feature Aggregation Network aims to exploit features combined from both network-level and stage-level.
进一步推进,我们提出了阶段级方法(图2(d)),以便将低级特征和空间信息传递给语义理解。 由于所有这些子网都具有相似的结构,因此可以通过以相同的分辨率连接层来生成阶段级细化,以生成多阶段上下文。 我们提出的深度特征聚合网络旨在利用网络级和阶段级结合的功能。

Figure 3. Overview of our Deep Feature Aggregation Network: sub-network aggregation, sub-stage aggregation, and dual-path decoder for multi-level feature fusion. In the figure, ”C” means concatenation, ”xN” is N× up-sampling operation.
图3.深度特征聚合网络概述:子网络聚合,子阶段聚合和用于多级特征融合的双路径解码器。 在该图中,“C”表示连接,“xN”表示N×上采样操作。
3.2. Deep Feature Aggregation
We focus on making the fusion of different depth features in networks. Our aggregation strategy is composed of sub-network aggregate and sub-stage aggregate methods. The structure of DFANet is illustrated in Figure 3.
3.2. 深度特征聚合
我们专注于在网络中融合不同深度特征。 我们的聚合策略由子网络聚合和子阶段聚合方法组成。 DFANet的结构如图3所示。
Sub-network Aggregation. Sub-network aggregation implements combination of high-level features at the network level. Based on the above analysis, we implement our architecture as a stack of backbones by feeding the output of the previous backbone to the next. From another perspective, sub-network aggregation could be seen as a refinement process. A backbone process is defined as y = Φ(x), the output of encoder Φn is the input of encoder Φn+1, so sub-network aggregate can be formulated as: Y = Φn(Φn−1(...Φ1(X))).
子网络聚合。 子网络聚合在网络级别实现了高维特征的组合。基于上述分析,我们通过将前一个backbone的输出提供给下一个backbone,将我们的体系结构实现为一堆backbone。 从另一个角度来看,子网络聚合可以被视为一种细化过程。 backbone运行过程可定义为y =Φ(x),编码器Φn的输出是编码器Φn+ 1的输入,因此子网聚合可以表示为:Y =Φn(Φn-1(...Φ1( X)))。
A similar idea has been introduced in [21]. The structure is composed with a stack of encoder-decoder ”hourglass” network. Sub-network aggregation allows these high-level features to be processed again to further evaluate and reassess higher order spatial relationships.
在[21]中引入了类似的想法。 该结构由一堆编码器 - 解码器“沙漏”网络组成。 子网络聚合允许再次处理这些高级特征,以进一步评估和重新评估更高阶的空间关系。
Sub-stage Aggregation. Sub-stage aggregation focuses on fusing semantic and spatial information in stage-level between multiple networks. As the depth of network grows, spatial details suffer losing. Common approaches, like U-shape, implement skip connection to recover image details in the decoder module. However, the deeper encoder blocks lack low-level features and spatial information to make judgments in large-scale various objects and precise structure edge. Parallel-branch design uses original and decreased resolution as input, and the output is the fusion of large-scale branch and small-scale branch results, while this kind of design has a lack of information communication between parallel branches.
子阶段聚合。 子阶段聚合侧重于在多个网络之间的阶段级融合语义和空间信息。 随着网络的深度增长,空间细节遭受损失。 常见的方法,如U形状,实现了跳过连接以恢复解码器模块中的图像细节。 然而,较深的编码器块缺乏低级特征和空间信息,无法在大规模的各种对象和精确的结构边缘进行判断。 并行分支设计使用原始和降低的分辨率作为输入,输出是大规模分支和小规模分支结果的融合,而这种设计缺乏并行分支之间的信息通信。
Our sub-stage aggregation is proposed to combine features through encoding period. We make the fusion of different stages in the same depth of sub-networks. In detail, the output of a certain stage in the previous sub-network is contributed to the input of the next sub-network in the corresponding stage position.
我们提出的子阶段聚合通过编码周期来组合特征。 我们在相同深度的子网络中进行不同阶段的融合。 详细地说,前一子网中某一级的输出有助于相应级位置中下一个子网的输入。
For a single backbone Φn(x), a stage process can be defined as ![]() . The stage in the previous backbone network is
. The stage in the previous backbone network is ![]() . i means the index of the stage. Sub-stageaggregation method can be formulated as:
. i means the index of the stage. Sub-stageaggregation method can be formulated as:
对于单个backboneΦn(x),阶段过程可以定义为![]() 。 前一个骨干网的阶段是
。 前一个骨干网的阶段是![]() 。 i表示stage的索引。子阶段聚合方法可以表述为:
。 i表示stage的索引。子阶段聚合方法可以表述为:
![]()
![]()
Traditional approaches are learning a mapping of F(x)+x for ![]() . In our proposed method, sub-stage aggregation method is learning a residual formulation of
. In our proposed method, sub-stage aggregation method is learning a residual formulation of ![]() at the beginning of each stage.
at the beginning of each stage.
传统方法是学习F(x)+x对![]() 的映射。在我们提出的方法中,子阶段聚合方法是在每个阶段的开始学习
的映射。在我们提出的方法中,子阶段聚合方法是在每个阶段的开始学习![]() 的残差公式。
的残差公式。
For n > 1 situation, the input of i-th stage in n-th network is given by combining the ith stage output in (n − 1)-th network with the (i − 1)-th stage output in n-th network, then the i-th stage learns a residual representation of ![]() .
. ![]() has the same resolution as
has the same resolution as ![]() , and we implement concatenation operation to fuse features.
, and we implement concatenation operation to fuse features.
对于n> 1的情况,在第n层网络的第i阶段的输入是通过将第(n-1)层网络中的第i级输出与第n层网络中的第(i-1)级输出相结合得到的,然后第i阶段学习![]() 的残差表示。
的残差表示。 ![]() 具有与
具有与![]() 相同的分辨率,并且我们实现级联操作以融合特征。
相同的分辨率,并且我们实现级联操作以融合特征。
We keep the feature always flow from high-resolution into the low-resolution. Our formulation not only learns a new mapping of nth feature maps but also preserves (n − 1)th features and receptive field. Information flow can be transferred through multiple networks.
我们始终保持特征从高分辨率流向低分辨率。 我们的公式不仅学习了第n个特征图的新映射,还保留了(n - 1)个特征和感受野。 信息流可以通过多个网络传输。
3.3. Network Architecture
The whole architecture is shown in Figure 3. In general, our semantic segmentation network could be seen as an encoder-decoder structure. As discussed above, the encoder is an aggregation of three Xception backbones, composed with sub-network aggregate and sub-stage aggregate methods. For real-time inference, we don’t put too much focus on the decoder. The decoder is designed as an efficient feature upsampling module to fuse low-level and high-level features. For convenience to implement our aggregate strategy, our sub-network is implemented by a backbone with single bilinear upsampling as a naive decoder. All these backbones have the same structure and are initalized with same pretrained weight.
3.3. 网络结构
整个架构如图3所示。总的来讲,我们的语义分割网络可以看作是编码器 - 解码器结构。 正如之前所叙述的,编码器是三个Xception backbone的集合,由子网络聚合和子阶段聚合方法组成。 对于实时推理,我们不会过多关注解码器。 解码器设计为高效的特征上采样模块,用于融合低层次特征和高层次特征。 为了方便实现我们的聚合策略,我们的子网络由一个backbone实现,单个双线性上采样作为一个简易的解码器。 所有这些骨架具有相同的结构并且使用相同的预训练权重进行初始化。
Backbone. The basic backbone is a lightweight Xception model with little modification for segmentation task, we will discuss the network configuration in the next section. For semantic segmentation, not only providing dense feature representation, how to gain semantic context effectively remains a problem. Therefore, we preserve fullyconnected layers from ImageNet pretraining to enhance semantic extraction. In classification task, fully-connected (FC) layer is followed by global pooling layers to make final probability vectors. Since classification task dataset [15] provides large amount of categories than segmentation datasets [10][36]. Fully-connected layer from ImageNet pretraining could be more powerful to extract category information than training from segmentation datasets. We apply a 1 × 1 convolution layer followed with FC layer to reduce channels to match the feature maps from Xception backbone. Then N ×C ×1×1 encoding vector is multiplied with original extracted features in channel-wise manner.
Backbone。基本backbone是轻量级Xception模型,对分段任务几乎没有修改,我们将在下一节讨论网络配置。对于语义分割,不仅提供密集的特征表示,如何有效地获得语义上下文仍然是一个问题。因此,我们保留ImageNet预训练中的完全连接层以增强语义提取。在分类任务中,全连接(FC)层之后是全局池化层以产生最终概率向量。由于分类任务数据集[15]提供了大量的类别而不是分割数据集[10] [36]。与使用分段数据集进行训练相比,ImageNet预训练中的完全连接层可以更强大地提取类别信息。我们应用1×1卷积层,然后使用FC层来减少通道以匹配来自Xception backbone的特征映射。然后,以通道方式将N×C×1×1编码矢量与原始提取特征相乘。
Decoder. Our proposed decoder module is illustrated in Figure 3. For real-time inference, we don’t put too much focus on designing complicated decoder module. According to DeepLabV3+[7], not all the features of the stages are necessary to contribute to decoder module. We propose to fuse high-level and low-level features directly. Because our encoder is composed of three backbones, we firstly fuse highlevel representation from the bottom of three backbones. Then the high-level features are bilinearly upsampled by a factor of 4, and low-level information from each backbone that have the same spatial resolution is fused respectively. Then the high-level features and low-level details are added together and upsampled by a factor of 4 to make the final prediction. In decoder module, we only implement a few convolution calculations to reduce the number of channels.
解码器。 我们提出的解码器模块如图3所示。对于实时推理,我们不太关注设计复杂的解码器模块。 根据DeepLabV3 + [7],并非所有阶段的功能都必须为解码器模块做出贡献。 我们建议直接融合高级和低级功能。 因为我们的编码器由三个主干组成,我们首先融合三个主干底部的高级表示。 然后将高级特征双线性上采样4倍,并且分别融合来自具有相同空间分辨率的每个主干的低级信息。 然后将高级特征和低级细节相加并上采样4倍以进行最终预测。 在解码器模块中,我们仅实现一些卷积计算以减少通道数量。