Eclipse提交任务至Hadoop集群遇到的问题
环境:Windows8.1,Eclipse
用Hadoop自带的wordcount示例
hadoop2.7.0
hadoop-eclipse-plugin-2.7.0.jar //Eclipse的插件,需要对应Hadoop当前版本
基本步骤有很多博客已经提及,就不再赘述
1. 将hadoop-eclipse-plugin-2.7.0.jar放入Eclipse的plugins目录,启动Eclipse
2. 配置Eclipse的Hadoop location信息

3. 新建MapReduce Project
4. 将wordcount的代码拷贝进去
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "192.168.1.150:9001");
conf.set("yarn.resourcemanager.address", "192.168.1.150:8032");
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Main方法的头三行代码,需要自己来配置
5. 将部署好的Hadoop集群中的配置文件拷贝至项目中

log4j.properties必须要配置,不然提交任务至集群时,Console无法显示信息,以下是我的配置
log4j.rootLogger=DEBUG, CA log4j.appender.CA=org.apache.log4j.ConsoleAppender log4j.appender.CA.layout=org.apache.log4j.PatternLayout log4j.appender.CA.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
6. 右键点击WordCount.java -> Run as -> Run on Hadoop
错误1:
org.apache.hadoop.util.Shell$ExitCodeException: /bin/bash: line 0: fg: no job control
Hadoop读取Windows和Linux系统变量时的引发的问题,有几种解决方案,嫌麻烦不想重新编译整个Hadoop就在本项目中直接重写来解决
在Hadoop的源代码中找到YARNRunner.java,拷贝至项目中,项目中的Package要和Hadoop源代码中的一样,运行时才会覆盖
修改YARNRunner.java
(1)修改读取Windows系统变量的方式

注释掉的代码是原来的代码
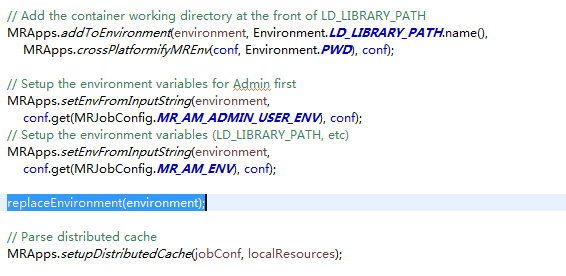
(2)新增一个处理Windows系统变量的方法
private void replaceEnvironment(Map<String, String> environment) {
String tmpClassPath = environment.get("CLASSPATH");
tmpClassPath=tmpClassPath.replaceAll(";", ":");
tmpClassPath=tmpClassPath.replaceAll("%PWD%", "\\$PWD");
tmpClassPath=tmpClassPath.replaceAll("%HADOOP_MAPRED_HOME%", "\\$HADOOP_MAPRED_HOME");
tmpClassPath= tmpClassPath.replaceAll("\\\\", "/" );
environment.put("CLASSPATH",tmpClassPath);
}
在此处使用
错误2:
exited with exitCode: 1 due to: Exception from container-launch
Diagnostics: Exception from container-launch.

修改项目中的mapred-site.xml,增加以下内容
<property> <name>mapreduce.application.classpath</name> <value> $HADOOP_CONF_DIR, $HADOOP_COMMON_HOME/share/hadoop/common/*, $HADOOP_COMMON_HOME/share/hadoop/common/lib/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*, $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*, $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*, $HADOOP_YARN_HOME/share/hadoop/yarn/*, $HADOOP_YARN_HOME/share/hadoop/yarn/lib/* </value> </property>
有时还会遇到Mapper class not found <init>() 这个错误
有2个问题
1. Mapper和Reduce的实现类如果是在其他类里面,例如包含Main方法的类,则必须为Static
2. Hadoop找不到本项目的Jar包,因为是从Windows上提交远程任务
(1)可以Export后传到Hadoop服务器上
(2)本地Export后
conf.set("mapred.jar", "C:/Users/14699_000/Desktop/0725.jar");
后面JAR的文件路径是我Export的路径