卷积神经网络(二)——AlexNet,VGGNet,ResNet,InceptionNet,MobileNet
目录
一. 模型的演变与进化
二. AlexNet介绍
1. AlexNet的特点
2. dropout:
三. VGGNet
1. 网络结构
(1) 更深
(2) 多使用3*3 的卷积核
(3) 视野域:
(4)1*1的卷积层可以看做是非线性变换
(5)每经过一个pooling层,通道数目翻倍
2. VGGNet从11层增至19层
(1)LRN: 局部归一化
(2)为什么一般在靠后的一些层次中加卷积层
3. 训练技巧
(1) 递进式训练
(2) 多尺度输入
四.ResNet
1. ResNet是怎样解决加深层次这个问题呢?
(1)模型深度达到某个程度后继续加深会导致训练集/测试集准确率下降
(2) 加深层次的问题解决
2. ResNet的模型结构
3. ResNet模型的特点
(1)残差结构使得网络需要学习的知识变少,容易学习。
(2)残差结构使得每一层的数据分布接近,容易学习。
五. InceptionNet
1. V1结构
(1) Inception优势
(2) V1结构—卷积参数和计算量
2. V2结构
3. V3结构
4. V4结构
六. MobileNet
1. 普通卷积层,InceptionNet 和MobileNet的参数对比
2. 普通卷积层与mobileNet的计算量的对比
(1)普通卷积层的计算量(Ci:输入通道,Co:输出通道,Kw:卷积核的宽,Kh:卷积核的长,Ow:输出的长,Oh:输出的宽)
(2)深度可分离卷积层的计算量
(3)优化比例
七.各个模型的效果分析
Q:为什么需要不同的网络结构
不同的网络结构解决的问题不同
不同的网络结构使用的技巧不同
不同的网络结构应用的场景不同
一. 模型的演变与进化
模型演变
AlexNet, VGG, ResNet, Inception, MobileNet
模型的进化
更深更宽——AlexNet到VGGNet
不同的模型结构——VGG到InceptionNet/ResNet
优势组合——Inception+Res = InceptionResNet
自我学习——NASNet
实用——MobileNet
二. AlexNet介绍
详见论文ImageNet Classification with Deep Convolutional Neural Networks
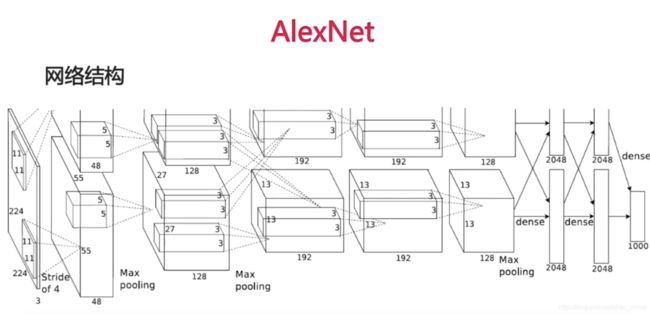
第一层卷积:
输入224 * 224, 3通道
Stride = 4,卷积核 11 * 11
输出大小 = (输入大小 – 卷积核 + padding)/stride + 1 = 55
参数数目 = 3 * (11 * 11) * 96 = 35k
第二层卷积:
输入 55 * 55
Stride = 4,卷积核 5 * 5
输出大小 = (输入大小 – 卷积核 + padding)/stride + 1 = 55
参数数目 = 2 * 48 * (5 * 5) * 128
第二层maxpoling 2*2
……
第一层全连接层:4096
第二层全连接层:4096
Softmax:1000,概率值
1. AlexNet的特点
- 首次使用Relu
- 2-GPU并行结构
- 1,2,5卷积层后跟随max-pooling层
- 两个全连接层上使用了dropout = 0.5 (dropout详见小节(2))(dropout = 0.5即50%的点保留,50%的点被设置成0)
- 数据增强,图片随机采样。[256, 256]采样[224, 224](用[224, 224]块在[256, 256]图像上随机采,这样1张图片变为好多张图片,相当于“从不同的角度”去看图片)
- Batch size = 128
- SGD momentum = 0.9
- Learning rate = 0.01, 过一定次数降低1/10
- 7个CNN做ensemble:错误率由18.2%->15.4%
2. dropout:
在某个神经元做输入时,把上一层神经元的输出随机地加一个mask(即随机地把其中的一些位置置0)。且在每一次训练迭代时,每次dropout的值都是随机的,不一样的。
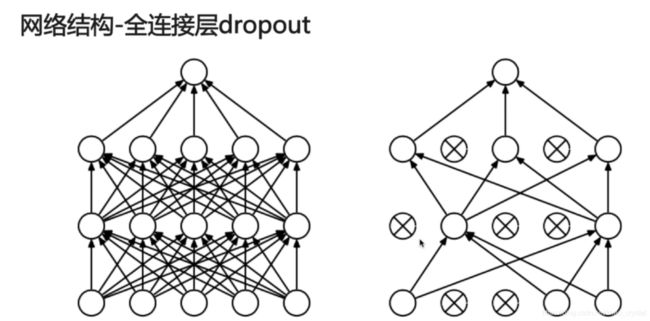
Q1: 为什么用在全连接层上?
全连接层参数占全部参数数目的大部分,容易过拟合
Q2: dropout原理?
组合解释:
每次dropout都相当于训练了一个子网络
最后的结果相当于很多子网络组合
动机解释:
消除了神经元之间的依赖,增强泛化能力
数据解释:
对于dropout后的结果,总能找到一个样本与其对应。相当于数据增强。
eg:dropout之前有6个神经元(1,2,3,4,5,6)相当于数据进到神经元中去,在某个全连接层上得到的输出是(1,2,3,4,5,6),即某个样本经过神经网络之后的特征表示。做dropout之后,就变为(1,0,3,4,0,6),认为总能找到一个新的样本,进入神经网络之后,得到的输出恰恰是(1,0,3,4,0,6),所以,做dropout就相当于增加了数据,模型的优化能力变强。
三. VGGNet
详见论文 VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
该论文物质检测第一,分类第二
1. 网络结构
(1) 更深
(2) 多使用3*3 的卷积核
2个3*3的卷积层可以看做一层5*5的卷积层
3个3*3的卷积层可以看做一层7*7的卷积层
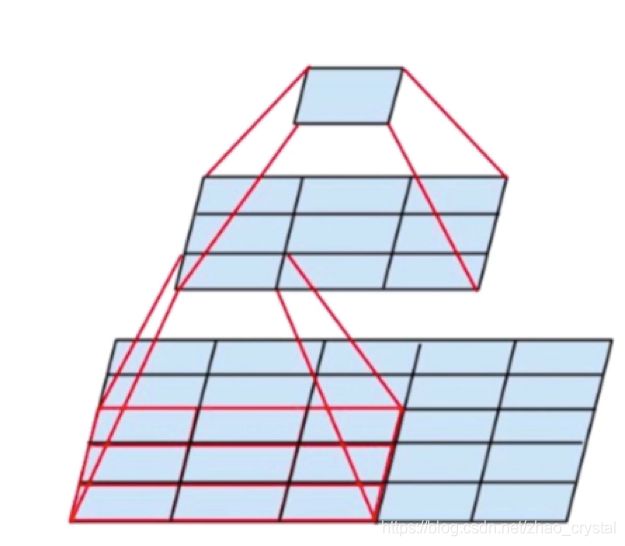
(3) 视野域:
2个3*3卷积层 = 1个5*5卷积层
2层比1层更多一次非线性变换
参数降低28% (假设每层输入的通道为Ci,输出的通道为Co)
对于2个3*3的卷积,参数为:Ci *(3 * 3)* Co + Ci *(3 * 3)* Co = 18*Ci*Co
对于1个5*5的卷积,参数为:Ci * (5*5) * Co = 25 * Ci*Co
故2个3*3的卷积,相较于1个5*5的卷积,参数降低(25*Ci*Co-18*Ci*Co)/(25*Ci*Co) = 28%
(4)1*1的卷积层可以看做是非线性变换
非线性变换能够使得整个模型拟合能力变好。另外,1*1的卷积层,可对通道进行将维操作,且不损失信息。
(5)每经过一个pooling层,通道数目翻倍
调参经验,可防止信息瓶颈。因为经过一个pooling层,某些信息要丢失,故需要提取更多的特征,从而使得信息丢失的没有那么多。
2. VGGNet从11层增至19层
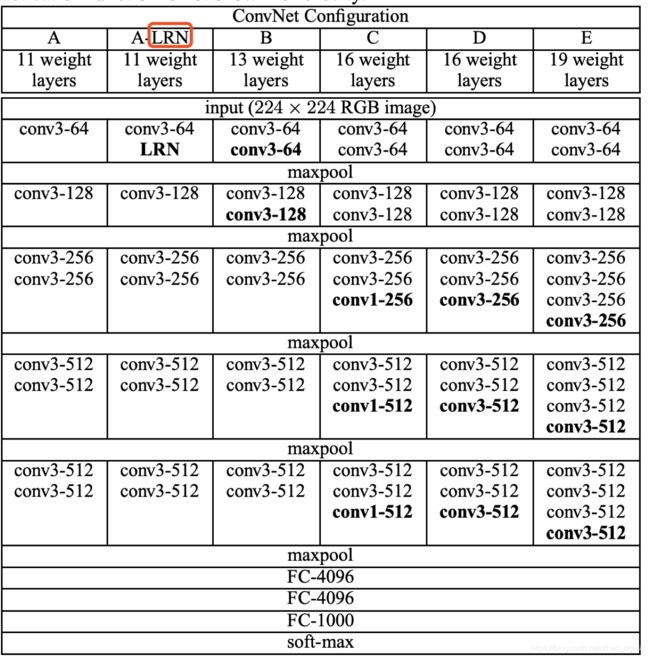
(1)LRN: 局部归一化
比如,某一层输出的是32个通道,对于某一个通道和周边的5层通道去做归一化处理(使得均值为0,方差为1,其值在(0,1)之间)。
(2)为什么一般在靠后的一些层次中加卷积层
因为最开始的图像比较大,计算起来比较耗时,在经过一些max_pooling之后,神经元图变的比较小,此时多加卷积层,其所耗的运算是比较小的。
3. 训练技巧
(1) 递进式训练
先训练浅层网络如A,再去训练深层网络(即从A上训练出来的模型,可以直接用在B的初始化的模型)
(2) 多尺度输入
不同的尺度训练多个分类器,然后做ensemble
随机使用不同的尺度缩放然后输入进分类器进行训练
(Alexnet是将图片缩放到[256, 256], 然后再用[224, 224]“从不同的角度看图”。VGGNet是将图片缩放到不同的尺度,比如[256, 256], [512, 512], 然后再用[224, 224]“从不同的角度看”)
github代码详见:https://github.com/crystal30/Deep_learning 2_3vgg.ipynb
四.ResNet
详见论文:Deep Residual Learning for Image Recognition
ILSVRC 2015 分类比赛冠军
VGGNet 将网络加深到了一定的层次后,就不能再继续加深了。因为继续加深,也不能够提升效果。ResNet正解决了这个问题,可以使得网络加深到更深的层次,最深可达到1000层。
1. ResNet是怎样解决加深层次这个问题呢?
(1)模型深度达到某个程度后继续加深会导致训练集/测试集准确率下降
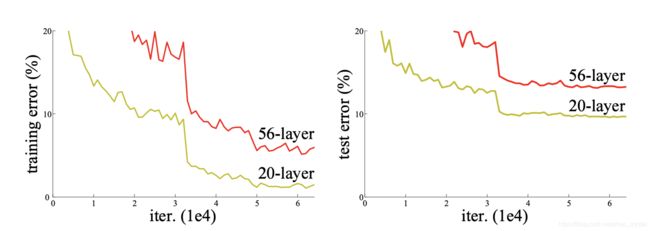
(2) 加深层次的问题解决
假设:深层网络更难优化而非深层网络学不到东西
深层网络至少可以和浅层网络持平
y=x, 虽然增加了深度,但误差不会增加
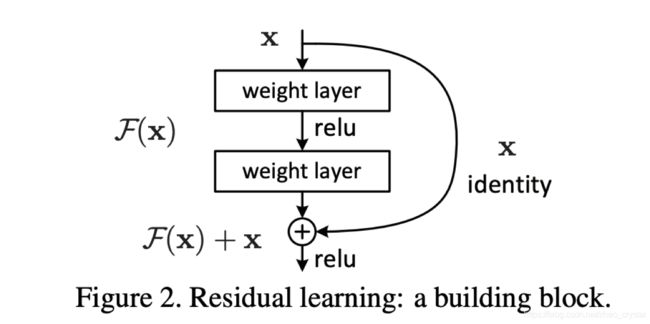
其中:Identity部分是恒等变换,F(x)是残差学习
其中F(x)可能使用降采样等,使得F(X)和x的大小不一样,不能进行相加操作,一般使用max_pooling对x进行降采样,使得其与F(x)大小一样,再进行相加。
2. ResNet的模型结构
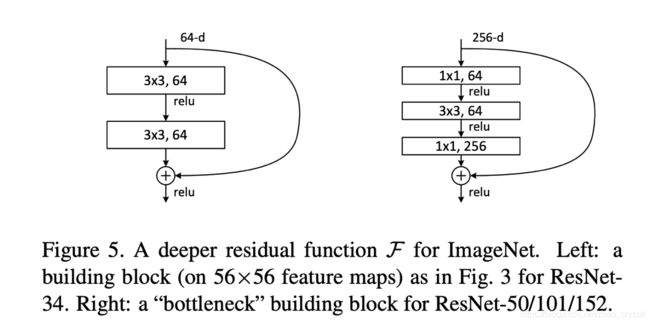
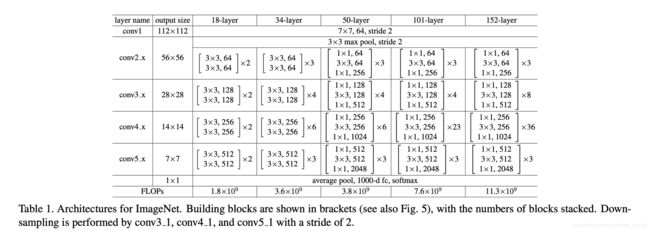
由table1可以看出:
- 先用一个普通的卷积层,stride = 2
- 再经过一个3*3的max_pooling, stride = 2
- 再经过残差结构(经过残差结构后可能会有一个降采样的操作,max_pooling及让卷积层的步长为2,就是一种降采样操作)
- 没有中间的全连接层,直接到输出
参数数目可以一定程度上反映模型的容量,即参数数目越多,意味着这个模型能学到更多的东西,但太多的参数容易过拟合。为保证参数适量,该模型强化了卷积层,弱化了全连接层。
3. ResNet模型的特点
(1)残差结构使得网络需要学习的知识变少,容易学习。
每一层,若想要分类的更准,需要学习到图像的所有信息。故每一层都需要保持所有图像的信息。但对于一个残差网络来说,因为其有残差的存在。残差也可认为是图像的信息,图像信息可直接传递过来,故在卷积层上学到的东西就会比较少(只是学到了比较特殊的表达而已)而全部的信息可以保证由残差恒等式保存下来,故残差结构使网络要学习的知识变少,比较容易学习。
(2)残差结构使得每一层的数据分布接近,容易学习。
Y = F(x) + x, 得到的数据分布肯定更靠近x,因此使得每一层的数据分布比较接近,使得整个网络容易学习。
Eg:在之前的网络中,加入输入的图片在[0,255]之间,经过很多个卷积层和pooling层之后,在比较高的层次上,此batch输出得到的区间是[0, 512]。但是对另一个minibatch来说,得到的可能是[512, 1024],使得模型需要兼容各种区间的数据。对于残差网络,会保证模型在一定程度上会更接近输入数据的分布,使得网络容易学习。
代码详见 https://github.com/crystal30/Deep_learning 2_4resnet.ipynb
五. InceptionNet
AlexNet——> VGGNet使得网络变得更深和更宽——>ResNet可继续加深网络的层次
疑问:这里的更宽指的是什么呢?
InceptionNet 同样可以解决网络层次不能再加深的问题
除了在调优之外,还更关注一些工程上的优化。同样的参数量,使得计算效率更高,计算效果越好。
深层网络遇到的问题
(1) 更深的网络容易过拟和
(2) 更深的网络有更大的计算量
稀疏网络虽然减少了参数但没有减少计算量(稀疏网络类似于dropout)
(卷积层的每个神经单元和之前的局部区域做全连接,某些参数总是接近于0,或是通过某种方法,其没有太大的效果。此时,稀疏网络就可以把这些参数设为0,从而不用存储这些参数,达到压缩模型大小的目的。但这种压缩不能减少计算量,在计算时为追求效果,仍然是采用密集计算的方式,而不是用稀疏矩阵计算的方式。稀疏矩阵如果用稀疏的方式计算,会比密集矩阵用密集的方式计算更低效。)
1. V1结构
GoogleNet相当于InceptionNet V1

分组卷积:比较类似于最开始的AlexNet,在2个GPU上,某些层也是不相互交叉的,不相互交叉就能降低计算量。
中间层再加1*1的卷积,计算量进行优化,比如输入是100通道,用1*1卷积去做非线性变换,降维,此时3*3,5*5输入尺寸就变小了,参数数目变少。如下图所示。
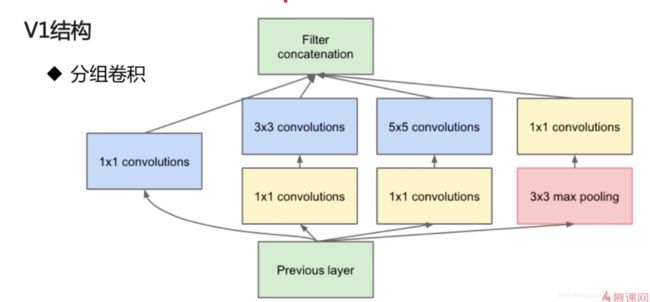
(1) Inception优势
一层上同时使用卷积核,看到各种层级的feature
其中,Filter concatenation 和 Previous layer之间的可看作一层(其中使用了多种卷积核),由于有不同的卷积核,视野域从小到大,可以看到从小到大的不同的feature。
不同组之间的feature不交叉计算,减少了计算量
同理,在AlexNet中,2个GPU也可减少计算量
(2) V1结构—卷积参数和计算量
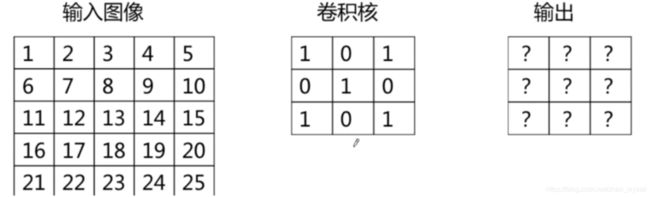
一个卷积层的参数:Ci *(Kw * Kh)* Co
一个卷积层的计算量:(Kw * Kh)* Ci) * ((Ow * Oh)*Co)
其中,Kw, Kh分别表示卷积核的长和宽,Ow, Oh分别表示输出的长和宽。Ci和Co分别表示输入/输出的通道数目。
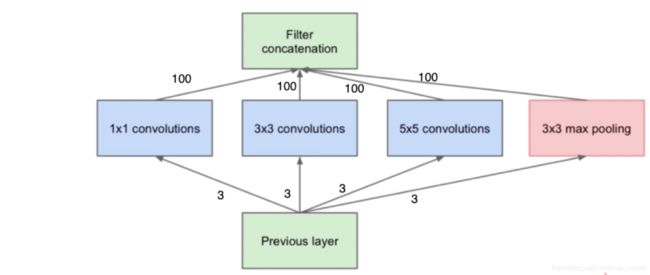
其中:假设输入通道是3, 输出通道是400,输出是10 * 10
Inception与普通3*3卷积相比
参数比较
普通3*3: 3*3*3*400 = 10.8k
Inception:3*1*1*100 + 3*3*3*100 + 3*5*5*100 = 10.5k
计算量比较
普通3*3: 3*3*3*10*10*400 = 1.08M
Inception:3*(1*1*10 * 10 + 3*3*10*10 + 5*5*10*10)*100 = 1.05M
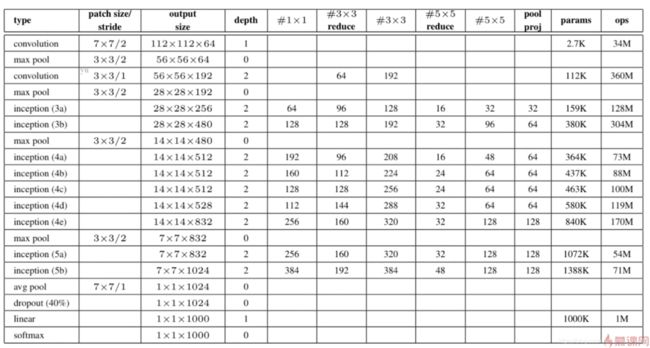
图中reduce表示步长比较长
2. V2结构
引入3*3视野域同等卷积替换
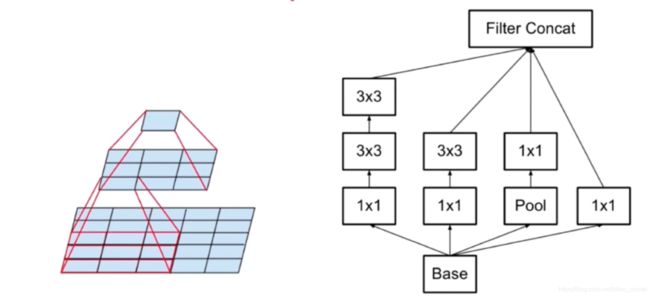
V2结构与VGG比较类似,用两个3*3的去替换5*5的,这样可以降低参数数目,降低的幅度是28%(前面小节介绍过原因)。
3. V3结构
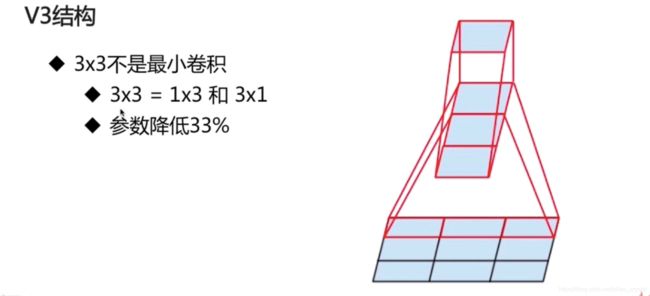
参数降低33%的具体计算:假设每层的输入通道为Ci,输出通道为Co。
3*3的卷积的参数:Ci * 3* 3* Co = 9*Ci*Co
对于1*3和3*1的卷积核:Ci * 1*3 * Co + Ci * 3 * 1 * Co = 6*Ci*Co
故1个1*3和3*1的卷积核相较于3*3的卷积,参数降低了(9*Ci*Co – 6*Ci*Co)/9*Ci*Co = 33%
Note:可以从3扩展到n,n越大,参数降低的幅度越大。
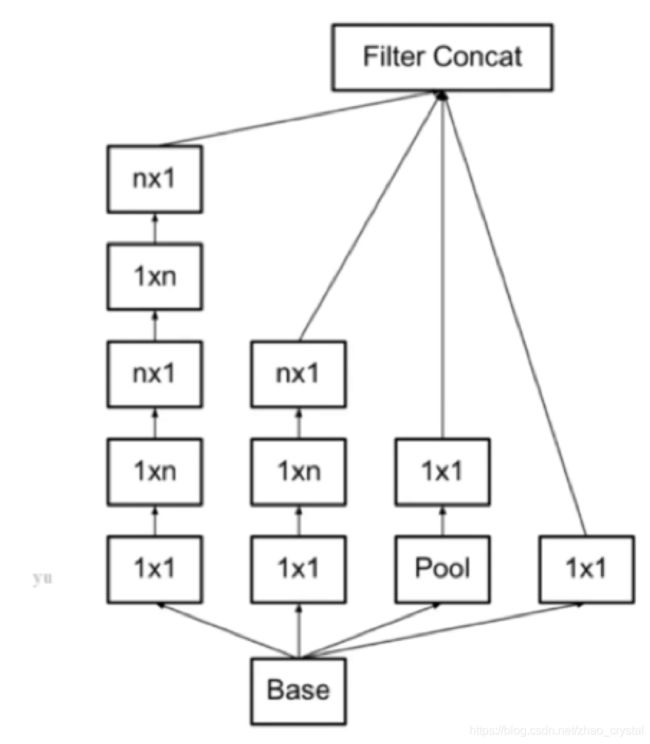
4. V4结构
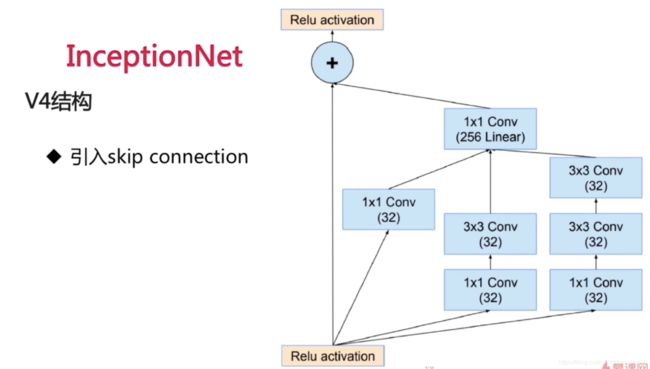
skip connection类似于残差连接。即把resNet引入到inceptionNet中,得到如上图所示的结构。
代码详见 https://github.com/crystal30/Deep_learning 2_5inception_net.ipynb
六. MobileNet
能够保证精度损失在可控的范围之内,可大幅度降低参数的数目和计算量。
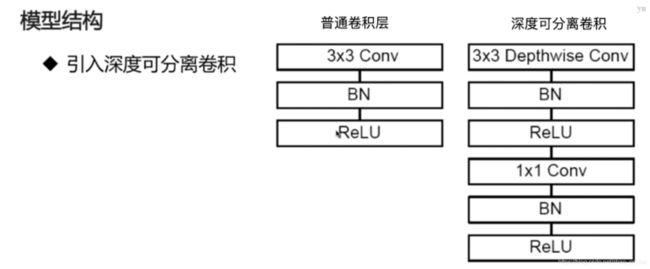
其中:Depthwise Conv 深度可分离卷积,BN:即P归一化。
1. 普通卷积层,InceptionNet 和MobileNet的参数对比
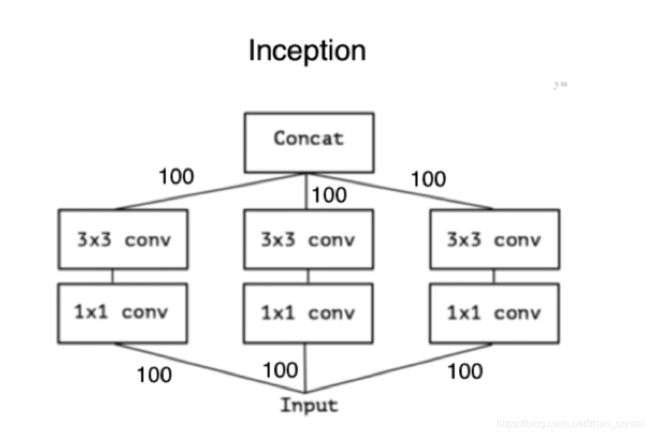
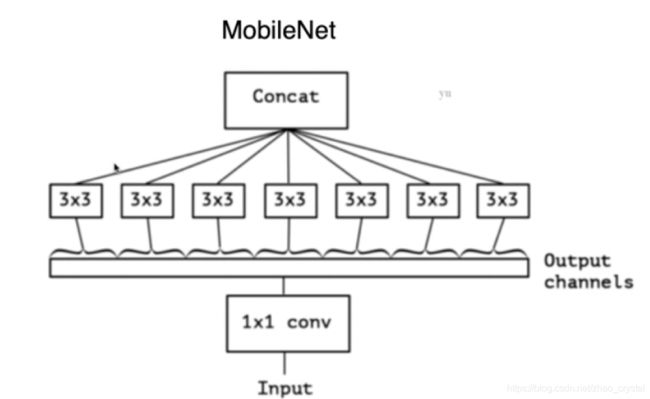
假设输入/输出通道数:300/300
普通卷积层:300 * 3*3 * 300
Inception分组:100 * 3 * 3 * 100 * 3
MobileNet引入深度可分离卷积——分到极致:(1*3*3*1)*300
深度可分离卷积——>分到极致,input经过1*1的卷积层之后,得到1个多通道的输出。对于多通道的输出,深度可分离卷积中1个3*3卷积核只关注输出通道中的其中某个通道——>生成1个通道,做拼接,得到最后的输出结果(降低了卷积核对输入的范畴),本来卷积核需要读取所有的通道,但现在只剩一个通道。
2. 普通卷积层与mobileNet的计算量的对比
(1)普通卷积层的计算量(Ci:输入通道,Co:输出通道,Kw:卷积核的宽,Kh:卷积核的长,Ow:输出的长,Oh:输出的宽)
Kw * Kh * Ci * Co * Ow * Oh
(2)深度可分离卷积层的计算量
深度可分离层(Ci = 1):1 * Kw * Kh * Co * Ow * Oh
1*1卷积:Ci * Co * Ow * Oh
(3)优化比例
(Kw * Kh * Co * Ow * Oh + Ci * Co * Ow * Oh)/ Kw * Kh * Ci * Co * Ow * Oh = 1/Ci + 1/Kw*Kh
代码详见 https://github.com/crystal30/Deep_learning 2_6mobile_net.ipynb
七.各个模型的效果分析
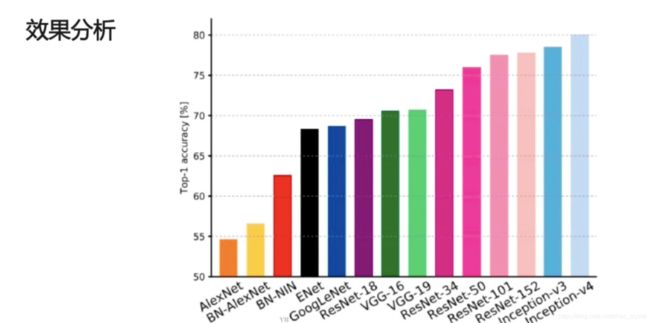
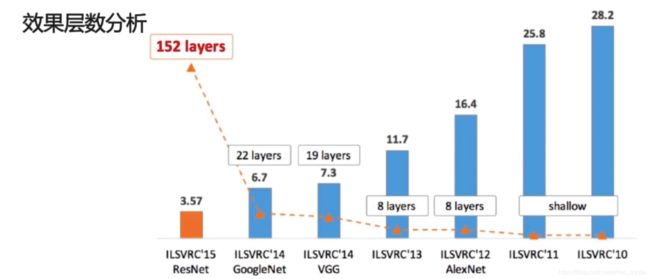
柱状图表示错误率,从右到左,错误率越来越低。
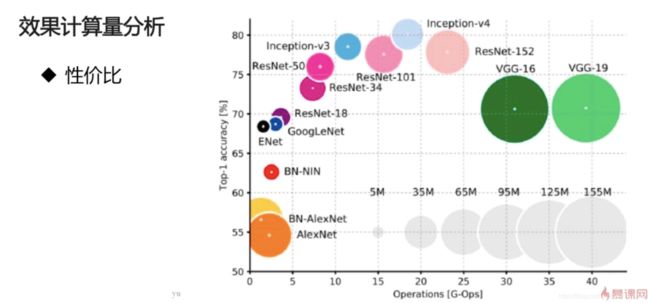
圆圈的大小表示参数的多少(模型的大小)