风影总结NHibernate3 ModelClass和Mapping
上文回顾:
我们上文说道,如何配置 NHconfig 文件从而达到通过NH来连接数据库的目的。
数据库是连上了,但是如果不能做CRUD的操作那- -,要他何用?
本文概要:
这次我们来聊聊模型类 和 对应的映射文件
模型类
我们都知道不管做什么为了达到解耦和的目的需要通过3层或者多层的架构来进行代码之间耦合度的降低。NH的目的就是帮我们来处理数据访问层的。帮我简化操作,SQL语句神马的都是浮云。自从有了NH以后,腰不酸了,腿不痛了,一口气上六楼不费劲了~~ 咳咳。
其实不光NH可以帮我们简化CRUD的数据库操作,还有很多框架也都可以,比如微软本家的Entity Framework现在最新版本貌似是5了。。我用的那会儿还是4.2呢。I'm old man!
好了废话不多说了(说了不少了- -),我们需要根据数据库的表结构创建对应的模型类

这是我们上一次建立的数据库表,那么我们就需要根据这个表的内容来创建对应的模型类


你发现这里有点奇怪,每一个模型类里的属性上都会出现一个virtual关键字,这是NH的约定所有跟数据库有关的属性都必须加上该关键字。看起来挺诡异的,还有一个注意点,我们通常喜欢把ID属性的set访问器的访问修饰符更改为protected.这样我们就只能对ID进行读取操作,而写入数据的操作我们就完全交给了NH,它会自动继承你的所有的模型类。
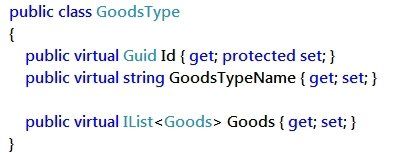
这种写法是NH推荐的写法。
我们还发现,在模型类里还有一个集合属性 
我们可以通过这个集合属性来获取所有相关的外键数据(需要我们在Mapping里进行配置)。
同样我们也在子表类Goods中发现了主表类GoodsType类型的属性

我们可以通过这两个导航属性获取关联表的相关数据。(需要我们在Mapping里进行配置)噢~圣光,这一特性值得期待!
映射文件Mapping
我们先来看主表的映射文件

上一次我们说过,我们需要把这个映射文件设置成嵌入的资源文件,
好了,我们来分析一下这个文件的配置。
首先这个配置文件的根节点是hibernate-mapping,同一个文件中只能有一个。
(1) Schema(可选) :数据表结构名称;
(2) Default-cascade(可选,默认值为none) :数据表级联类型;
(3) Auto-import(可选,默认值true) :指示出是否可以在查询语句中不指定类名;
(4) Default-access(可选,默认值为”property”):指示出NHibernate用于访问字段的策略;
(5) Assembly(可选):如果在引用实体类的程序集时没有指明类名前缀,则用此选项值作为默认的类名前缀;
(6) Namespace(可选):指示同名称空间;
(7) Xmlns 为了引入可以提醒的DTD文件
通常我们只需要设置Assembly,Namespace,Xmlns 就可以了。
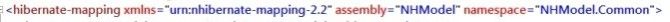
class节点
hibernate-mappin节点的子节点是class节点,它对应的是数据库里的表和model类。

name属性该属性制定的是Model类,要注意的是name是2部分组成的,第一部分是命名空间+对应模型类的类名。第二部分是程序集名。中间用逗号分割。
table属性是数据库里对应的表名(也就是说,我们的表名和模型类名可以不同)
全属性列表
(1) name:持久类在.Net中的类型的的全名及其所在程序集;
(2) table:数据库中的数据表名称;
(3) discriminator-value(可选,默认值为类名):用于区分单独的子集,使用与多态形式;
(4) mutable(可选,默认值为true):指定类实例是否易变;
(5) schema(可选):重新指定hibernate-mapping中的Schema选项值;
(6) proxy(可选):指定用于实现惰性初始的接口,如果所有属性都被声明为Virtual,则可以将类名指定给此选项;
(7) dynamic-update(可选,默认值false):指示出NHibernate在运行时产生的Update SQL语句是否仅包含被修改了的字段;
(8) dynamic-insert:(可选,默认值false):指示出NHibernate在运行时产生的Insert SQL语句是否仅包含被值不为Null的字段;
(9) polymorphism(可选,默认值implict):指示出是否需要有确指明查询是否使用多态性;
(10) where(可选):指定Where SQL语句可以获取这个类类型的对象;
(11) persister(可选):指定用户自定义的IClassPersister;
(12) lazy(可选):将此项设为true等同与将它自己的类名赋予给proxy选项。
先写到这里晚上继续
先到这里吧- -重写了3次。。。晚上继续。。
额。。昨天晚上有点事- -,好我们继续。

参数详解
(1) name:持久类在.Net中的类型的的全名及其所在程序集;
(2) table:数据库中的数据表名称;
(3) discriminator-value(可选,默认值为类名):用于区分单独的子集,使用与多态形式;
(4) mutable(可选,默认值为true):指定类实例是否易变;
(5) schema(可选):重新指定hibernate-mapping中的Schema选项值;
(6) proxy(可选):指定用于实现惰性初始的接口,如果所有属性都被声明为Virtual,则可以将类名指定给此选项;
(7) dynamic-update(可选,默认值false):指示出NHibernate在运行时产生的Update SQL语句是否仅包含被修改了的字段;
(8) dynamic-insert:(可选,默认值false):指示出NHibernate在运行时产生的Insert SQL语句是否仅包含被值不为Null的字段;
(9) polymorphism(可选,默认值implict):指示出是否需要有确指明查询是否使用多态性;
(10) where(可选):指定Where SQL语句可以获取这个类类型的对象;
(11) persister(可选):指定用户自定义的IClassPersister;
(12) lazy(可选):将此项设为true等同与将它自己的类名赋予给proxy选项。
Id
被映射的类必须声明一个Id与数据表中的主键相对应。Id其实也是被映射的类的一个属性,与使用Proerpty声明的属性不同的是ID属性值必须是唯一的,通过ID可以将对象转化为数据表中唯一的一条记录,同样也可以将数据表中的记录转化为对象 
(1) name(可选):属性的名称;
(2) type(可选):属性的类型;
(3) column(可选,默认值和属性名称相同):数据表中的主键字段名称,如果用户定义的属性名称和此字段名称相同,则此选项可忽略不写;
(4) unsaved-value (可选 - 默认为一个切合实际(sensible)的值): 一个特定的标识属性值,用来标志该实例是刚刚创建的,尚未保存。这可以把这种实例和从以前的session中装载过(可能又做过修改--译者注)但未再次持久化的实例区分开来。
(5) access (可选 - 默认为property): Hibernate用来访问属性值的策略。
generator
到了最关键的地方了
这个主键的生成策略
1) assigned
主键由外部程序负责生成,无需Hibernate参与。
2) hilo
通过hi/lo 算法实现的主键生成机制,需要额外的数据库表保存主键生成历史状态。
3) seqhilo
与hilo 类似,通过hi/lo 算法实现的主键生成机制,只是主键历史状态保存在Sequence中,适用于支持Sequence的数据库,如Oracle。
4) increment
主键按数值顺序递增。此方式的实现机制为在当前应用实例中维持一个变量,以保存着当前的最大值,之后每次需要生成主键的时候
将此值加1作为主键。
这种方式可能产生的问题是:如果当前有多个实例访问同一个数据库,那么由于各个实例各自维护主键状态,不同实例可能生成同样
的主键,从而造成主键重复异常。因此,如果同一数据库有多个实例访问,此方式必须避免使用。
5) identity
采用数据库提供的主键生成机制。如DB2、SQL Server、MySQL中的主键生成机制。
6) sequence
采用数据库提供的sequence 机制生成主键。如Oralce 中的Sequence。
7) native
由Hibernate根据底层数据库自行判断采用identity、hilo、sequence其中一种作为主键生成方式。
8) uuid.hex
由Hibernate基于128 位唯一值产生算法生成16 进制数值(编码后以长度32 的字符串表示)作为主键。
9) uuid.string
与uuid.hex 类似,只是生成的主键未进行编码(长度16)。在某些数据库中可能出现问题(如PostgreSQL)。
10) foreign
使用外部表的字段作为主键。
一般而言,利用uuid.hex方式生成主键将提供最好的性能和数据库平台适应性。(NH3.3以前版本的推荐)
11) guid
通过调用 System.Guid.NewGuid() 生成的 GUID.
12) guid.comb
随机10 个字节的 GUID,结合六个字节表示的当前日期和时间,以形成一个新的 GUID。这种算法可以减少索引碎片在保持高性能的同时。强烈推荐
13) guid.native 通过数据库内部的GUID机制
后面这3个是新加的主键生成机制机制。
我们下次讲解Session