【NLP】N-LTP:基于预训练模型的中文自然语言处理平台
论文名称:N-LTP: A Open-source Neural Chinese Language Technology Platform with Pretrained Models
论文作者:车万翔,冯云龙,覃立波,刘挺
原创作者:冯云龙
论文链接:https://arxiv.org/abs/2009.11616
转载须标注出处:哈工大SCIR
背景
现有种类繁多的自然语言处理(NLP)工具包,例如CoreNLP [1],UDPipe [2],FLAIR [3],spaCy 和Stanza [4]的英文版,这使用户可以更轻松地构建具有复杂语言处理能力的工具。最近,在许多下游应用中对中文NLP的需求急剧增加。中文NLP平台通常包括词法分析(中文分词(CWS),词性(POS)标记和命名实体识别(NER)),语法分析(依赖项解析(DEP))和语义分析(语义依赖解析(SDP)和语义角色标记(SRL))。不过用于中文NLP任务的高性能和高效率工具包相对较少。
介绍
基于以上背景,我们搭建了N-LTP,这是一个基于PyTorch的中文自然语言处理的神经自然语言处理工具包,它是基于SOTA预训练模型构建的。
如图1所示,在输入中文语料库的情况下,N-LTP产生了相对丰富和快速的分析结果,包括词法分析,句法分析和语义分析等。此外,N-LTP还提供了易于使用的API和可视化工具。

图1 N-LTP模型概览
与现有的广泛使用的NLP工具包相比,N-LTP具有以下优点:
丰富的中文基础NLP任务:N-LTP支持丰富的中文基础NLP任务,包括词法分析(分词,词性标记,命名实体识别和语义角色标记),语法解析和语义解析(语义依赖解析)。
多任务学习:现有的中文NLP工具包均针对每个任务采用独立的模型,从而忽略了各个任务之间的共享知识。为了缓解这个问题,我们建议使用多任务框架 [8] 来利用所有任务之间的共享知识。同时,针对所有六个任务使用共享编码器进行的多任务学习可以大大减少占用的内存并提高速度,从而使N-LTP更加高效,从而减少了对硬件的需求。
可扩展性:N-LTP与用户的自定义模块一起使用。用户可以轻松地通过配置文件添加新的预训练模型,通过更改配置,用户可以轻松地将预训练模型更改为变压器支持的任何类似BERT的模型 [9]。我们已经使所有任务训练配置文件开源。
易于使用的API和可视化工具:N-LTP提供了基本API的集合,这使用户无需任何知识即可方便地使用该工具包。我们还提供了可视化工具,使用户可以直接查看处理结果。此外,N-LTP具有许多编程语言可用的绑定,比如C++,Python,Java和Rust等。
最先进的性能:我们对一共六项中文NLP任务进行了评估,发现它在每项任务上均达到了最先进的水平或具有竞争力的表现。
使用方法
安装方法
$ pip install ltp
快速使用
Python
from ltp import LTP
ltp = LTP() # 默认加载 Small 模型
seg, hidden = ltp.seg(["他叫汤姆去拿外衣。"])
pos = ltp.pos(hidden)
ner = ltp.ner(hidden)
srl = ltp.srl(hidden)
dep = ltp.dep(hidden)
sdp = ltp.sdp(hidden)
其他语言绑定等
// RUST 语言
use ltp_rs::{LTPError, LTP};
fn main() -> Result<(), LTPError> {
let mut ltp = LTP::new("path/to/model", 16)?;
let sentences = vec![String::from("他叫汤姆去拿外衣。")];
let result = ltp.pipeline_batch(&sentences)?;
println!("{:?}", result);
Ok(())
}
多任务模型
共享编码器
为了提取所有中文相关任务的共享知识,我们采用了多任务框架,其中六个中文任务共享一个编码器。在我们的框架中,我们采用SOTA预训练模型(ELECTRA [5])作为编码器。
给定输入序列 = ( ),我们首先通过添加特定标记 = ( )构造输入序列),其中 是表示整个序列的特殊符号, 是用于分隔非连续令牌序列的特殊符号(Devlin et al。,2019)。ELECTRA接受构造的输入,并输出序列 = ( , , )的相应隐藏表示。
分词
中文分词(CWS)是中文自然语言处理(NLP)的首要任务。在N-LTP中,CWS被视为基于字符的序列标记问题。具体来说,给定隐层的表示形式 = ( , , ),我们采用线性解码器对每个字符进行分类:

其中, 表示标签概率分布每个字符; 和 是可训练的参数。
词性标注
词性(POS)标记是另一个基本的NLP任务,它可以简化诸如语法分析之类的下游任务。和分词任务一样,我们这里也是使用一个简单地MLP来对每个词语进行分类。
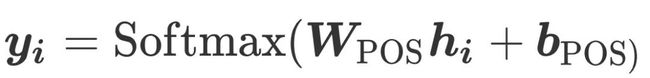
命名实体识别
命名实体识别(NER)是一项常见的自然语言处理任务,目的是在一个句子中查找一个实体(人员,位置,组织等)的起点和终点,并为此实体分配一个类别。
这里我们使用了 Adapted-Transformer[6] 来获取方向和距离敏感的词语表示,然后使用线性分类器对其进行分类:

其中 表示每个字符的NER标签概率分布。
依存句法分析
依存关系分析是分析句子的语义结构的任务。在N-LTP中,我们使用 deep biaffine parser [10](Dozat and Manning,2017)和einser算法 [7](Eisner,1996)以获取解析结果,其公式为:

上面的过程通过将1维向量 扩展为 维来对 进行评分,其中 为标签的总数。
语义依存分析
与依存关系分析相似,语义依存分析[11]是捕获句子语义结构的任务。具体来说,给定一个输入语句,SDP的目的是确定所有彼此语义相关的词对,并分配特定的预定义语义关系。
这里我们仍然使用 Biaffine 模型来对结果进行预测,不过之后我们使用
如果 我们则认为从 到 存在一个边。
语义角色标注
语义角色标记(SRL)是确定句子的潜在谓语-参数结构的任务,它可以提供表示形式来回答有关句子含义的基本问题,包括谁对谁做了什么等。
这里我们使用 Biaffine 和 CRF 的解码器相结合的方法构建了一个端到端的 SRL 模型。
其中 表示谓词为 时的任意标签序列,而 表示从 到 对于 的分数。
实验结果
主实验
表1展示了LTP和Stanza模型在LTP数据集上的结果。
表1 LTP 和 Stanza 在 LTP 数据集上的结果。
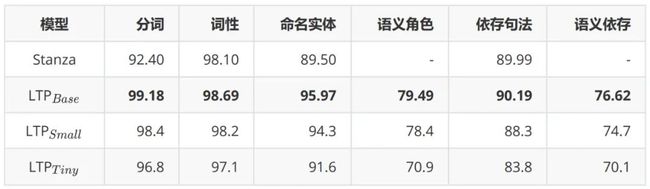
表2展示了LTP 和 Stanza 在 UD 和 Ontonotes 上的结果,这里报的是Stanza的官方结果,指标采用Stanza提供的评测脚本计算得出。
表2 LTP 和 Stanza 在 UD 和 Ontonotes 上的结果

由于Stanza并没有使用BERT等预训练模型,因此我们另外查找了一些使用预训练模型的SOTA模型进行比较,基本上都取得了相对不错的结果。
表3 LTP模型与不同任务上的SOTA预训练模型进行比较

速度
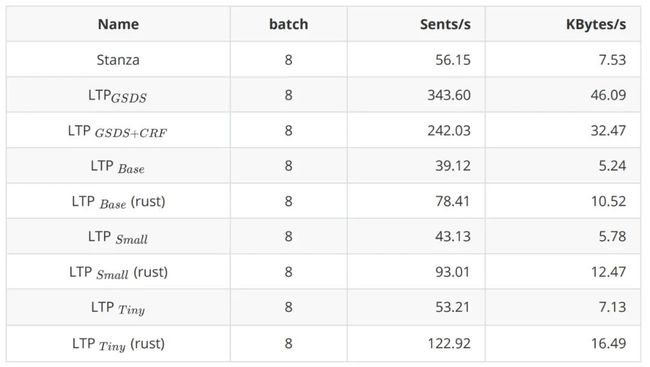
另外,我们也对模型的速度进行了比较,从表4可以看到LTP在与Stanza同样的任务量下 LTP /LTP 速度是Stanza的4~6倍。另外,我们也制作了其他语言的 Binding。从表4可以看到,Rust版本相比较于Python版本快了大约两倍左右。
表4 模型速度的比较
总结
我们介绍了N-LTP,一个面向中文自然语言处理的工具包。我们在6个基本的中文NLP任务对N-LTP进行了评估,并获得了最先进的或具有竞争力的性能,希望它能够促进中文NLP的研究和应用。将来,我们将通过添加新的模型或者任务来继续扩展N-LTP。
参考文献
[1]. Christopher Manning, Mihai Surdeanu, John Bauer, Jenny Finkel, Steven Bethard, and David McClosky. 2014. The Stanford CoreNLP natural language pro- cessing toolkit. In Proceedings of 52nd Annual Meeting of the Association for Computational Lin- guistics: System Demonstrations, pages 55–60, Bal- timore, Maryland. Association for Computational Linguistics.
[2]. Straka, Milan, and Jana Straková. 2017. Tokenizing, POS tagging, lemmatizing and parsing UD 2.0 with UDPipe. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Univer- sal Dependencies, pages 88–99, Vancouver, Canada. Association for Computational Linguistics.
[3]. Alan Akbik, Tanja Bergmann, Duncan Blythe, Kashif Rasul, Stefan Schweter, and Roland Vollgraf. 2019. FLAIR: An easy-to-use framework for state-of-the- art NLP. In Proceedings of the 2019 Confer- ence of the North American Chapter of the Asso- ciation for Computational Linguistics (Demonstra- tions), pages 54–59, Minneapolis, Minnesota. Asso- ciation for Computational Linguistics.
[4]. Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, and Christopher D. Manning. 2020. Stanza: A python natural language processing toolkit for many human languages. In Proceedings of the 58th An- nual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 101– 108, Online. Association for Computational Linguistics.
[5]. Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. 2020. ELECTRA: pre-training text encoders as discriminators rather than generators. In 8th International Confer- ence on Learning Representations, ICLR 2020, Ad- dis Ababa, Ethiopia, April 26-30, 2020. OpenRe- view.net.
[6]. Hang Yan, Bocao Deng, Xiaonan Li, and Xipeng Qiu. 2019a. Tener: Adapting transformer encoder for named entity recognition.
[7]. Jason M. Eisner. 1996. Three new probabilistic models for dependency parsing: An exploration. In COL- ING 1996 Volume 1: The 16th International Confer- ence on Computational Linguistics.
[8]. Kevin Clark, Minh-Thang Luong, Urvashi Khandel- wal, Christopher D. Manning, and Quoc V. Le. 2019. BAM! born-again multi-task networks for natural language understanding. In Proceedings of the 57th Annual Meeting of the Association for Computa- tional Linguistics, pages 5931–5937, Florence, Italy. Association for Computational Linguistics.
[9]. Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Re ́mi Louf, Morgan Funtow- icz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2019. Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
[10]. Timothy Dozat and Christopher D. Manning. 2017. Deep biaffine attention for neural dependency pars- ing. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. Open- Review.net.
[11]. Wanxiang Che, Meishan Zhang, Yanqiu Shao, and Ting Liu. 2012. SemEval-2012 task 5: Chinese semantic dependency parsing. In **SEM 2012: The First Joint Conference on Lexical and Computational Seman- tics – Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Eval- uation (SemEval 2012)*, pages 378–384, Montre ́al, Canada. Association for Computational Linguistics.
本期责任编辑:冯骁骋
本期编辑:钟蔚弘
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: