python文件操作(一看就懂)
python文件操作
-
- 历史遗留问题
- 文件介绍
- 打开文件
- 转定义字符
-
- Python格式化字符串的替代符以及含义
- Python的转义字符及其含义
- Final~
历史遗留问题
现在我们接着上文讲,如果没有看过我上篇文章的萌新朋友们可以先去看看,不然一会儿容易读的你满脸问号。python字符编码

现在我们来思考一个问题,我们在PyCharm里敲字符,这个字符应当先存到内存中去,而内存里都存的是unicode格式的二进制,如果我们现在就把他存到硬盘里,理论上来说就可以把unicode格式的二进制直接存到硬盘里就行了,如果是这样的话世界上就不会有乱码的问题了,但是内存的数据一旦断电就马上丢失了,而硬盘的数据是会永久保存的,这些硬盘里保存的有。
整个人类历史的长河中留下了数量非常之庞大的老文件,在这些文件里有很多都是用GBK编码、ASCII编码、Shift_JIS、Euc-kr等等的。对于这些老文件咱们肯定不能全删掉,如果能全部删掉我们也不会遇到乱码的问题了,因为所有文件都是unicode编码,所以我们做不到秦始皇那样,所以我们经常遇到乱码问题也是正常的,其原因就是残留了太多的各种的文件。
现在我们电脑内存里的编码方法都被替换成unicode了,所以我们现在在程序的过程中输入任何人类所用的字符都不会乱码,但是在电脑上的老文件也是需要正常显示的,所以unicode编码除了需要兼容玩过字符以外还需要与原来每个国家的字符编码有对应关系,把新的unicode的二进制数与老的编码表的二进制数一一对应起来,就相当于unicode需要充当一个第三方中介。
我们在文件中存下的数据在内存中存的是unicode的二进制数,然后当我们要保存到硬盘的时候我们要将文件保存成GBK格式,然后就会按照unicode对应上GBK的二进制编码进行保存。当我们要读取GBK格式的文件的时候也是照着以上步骤反过来,先看这个文件是以什么编码格式保存的,然后对应成unicode编码的二进制数,再根据unicode编码显示出来原来的字符。
如果我们在文件里输入韩文字符在内存里显示是没有问题的,当我们将它写入硬盘的时候我们给它保存成GBK格式的文件就会有问题,因为GBK根本就没有对应韩文字符,所以有的平台改写昵称是不允许使用除中文、指定符号、英文外的任何字符。如果我想将硬盘里存的GBK格式的文件转化成Euc-kr格式,由于GBK编码里面转成了英文和中文,Euc-kr编码里面又编定了英文和韩文,而unicode里面是包括所有国家的字符的,所以当我们把GBK格式的文件通过unicode转成Euc-kr的时候,英文也是可以正常显示的,但如果是中文的话就会乱码,这是因为Euc-kr里面没有中文的对应关系,所以说以前的老字符编码都是可以转成unicode的,但是它们不能通过unicode进行相互转换。
文件介绍
上面我们费了这么多的篇幅来讲字符编码,最终你只需要记住一个结论就行了:遇见乱码就加文件头,用python3加文件头直接加,用python2加文件头前面先加一个小写u。
到底什么是文件呢?我们常说计算机有三层体系结构:最下层是硬件,硬件之上就是操作系统,最上层就是用户和应用程序。
用户和应用程序如果想操作硬件就必须通过操作系统,比如用户或者应用程序想要操作硬盘这个硬件就得操作操作系统,而操作系统提供了一种虚拟的概念,那就是文件,或者叫做操作系统提供的操作硬盘功能。用户或者应用程序想要把数据存到硬盘里去就需要对操作系统的文件发起系统调用,操作系统会把用户或者应用程序对文件的调用功能转成具体的硬盘操作,比如磁盘怎么转、磁头臂怎么摆,然后再把数据写到硬盘我们平时修改的文件都是借助文本编译器来实现修改文件的。
我们平时修改文件,都是借助文本编译工具来实现修改文件的,比如Visual Studio Code、Visual Studio、PyCharm、Word等等。当然,图片和视频也可以修改,图片对应的工具就是PS,图片数据就是16进制的,PS内所有的工具、画笔都是对颜色的修改,只不过是经过封装的而已。
打开文件
如果用代码来操作文件python就为我们提供了一个名为 open() 的功能,这个open功能就是用来打开操作系统文件的,然后去用操作系统的文件去对应具体的硬盘空间,所以以后我们用open功能打开一个文件,然后对文件进行操作,其实open就是通过操作这个文件然后转换成具体的硬盘操作。
在讲open之前open功能有两大类模式我们需要掌握。
第一大类的模式就是控制文件读写操作的模式,在这类模式当中r模式就是控制只读模式,w控制只写模式,a是只追加写模式。a和a都是只写模式,其区别就在于w模式下如果一个文件里原本有数据,w模式就会将其清空后再写;a模式则会在原有的数据后追加写,不清空原有数据。还有一个模式就是+模式,这个+不能够单独使用,他必须和r、w、a配合使用,也就是r+、w+、a+,+号会在他们原有的基础上给你增加一个你原来没有的功能,r+就是在只读的基础上增加了写的功能;w+功能就是原来只能写,有了加号以后就可以读了;a+就是除了原来的追加写以外也可以读了。虽然上述的三种模式都是可读可写,但是在他们原有的基础上增加的功能,所以受限于它原有的功能,受限在哪里我们后面再具体说。
第二类模式就是控制控制文件读写内容的模式,这个模式控制的是你读文件的时候读的是什么格式的数据、写文件又是写的什么格式的数据,如果读写的是文本格式的数据就是t模式,t模式是默认的模式,如果我们不指定这个模式他就会默认为t模式。
t模式是以字符串为单位的,说到这里我们来思考一下:我们为什么要学文件处理?学习文件处理的目的其实就是把原本存放于内存的数据保存到硬盘里面去。如果内存里现在存的是一堆unicode数据存到硬盘,就是要把unicode数据encode一下才能存,不管是编码成utf-8,还是编码成gbk都是要编码一下,总之不能把unicode存到硬盘,因为unicode只存于内存,所以才要encode一下。
刚刚我们说的t模式的读写都是以字符串为单位的,而python3的字符串类型在内存里都是unicode格式的。我们要把字符串存到硬盘就应该把字符串编码一下才能存到硬盘,所以以后我们遇到字符串类型直接把它想象成unicode就行了。
转定义字符
用python操作文件的第一步就是打开文件,第二步就是具体操作文件(包括读写文件),最后一步就是关闭文件。
打开文件的方法就是在open()功能中传一个参数再给它指定我们要打开的文件的路径,示例代码如下:
file = open(r'C:\trees\app.txt')
当我们将以上代码放到PyCharm中后大家就会发现字符串中的\t、\a和其他的字符的颜色有些不同,那是因为在python的字符串中这个斜杠是具有转义的作用的,例如\n就是换行符、\t是制表符、\a具有响铃的作用。

比如说我们运行以下代码电脑就会出现响铃:
print('/a')
除了以上的转义符之外还有许多别的转义符,我们下面列出了两个表格为大家介绍:
Python格式化字符串的替代符以及含义
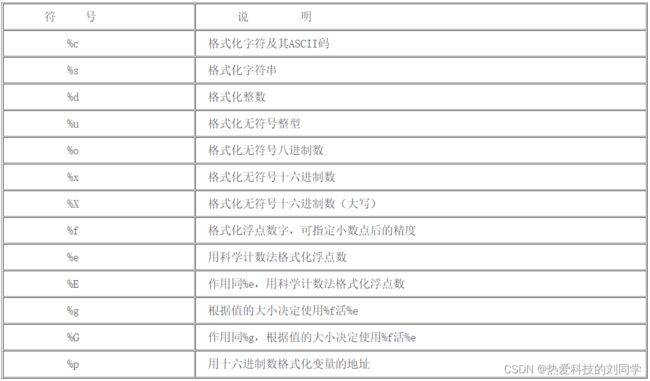
Python的转义字符及其含义

Final~
以上就是这篇文章的全部内容了,希望本文《python文件操作》的内容对大家的学习或者工作具有一定的参考学习价值,bye~