《Checking Smart Contracts with Structural Code Embedding》论文笔记
年份: 2020(TSE)
论文下载地址:点击进入
论文代码Github地址:点击进入
论文模型web应用地址:点击进入
论文主要内容:
论文提出了一种自动化学习Solidity编写的智能合约特性的方法(称为:“SMARTEMBED”)。该方法基于词嵌入和向量空间比较。通过将智能合约代码解析成带有代码结构信息的词流,将代码元素(如声明、函数)转换成编码代码语法和语义的数值型向量,然后比较编码代码的向量和已知bug代码之间的相似度,来识别潜在的问题。实验结果表明,论文的方法可以有效识别许多重复的实例。
问题:
现有的一些bug检测工具它们的缺点是:需要人类专家手动来定义某种特定bug模式或规则,以便构建bug检测器和代码模型检查器来检测智能合约。
介绍:
论文是第一个提出通过代码嵌入进行相似性检查,来进行智能合约代码bug检测的,特别是代码嵌入还引入了代码的结构信息。
而论文提出的方法则是基于深度学习技术,可以随着代码或者bug的变化,不断的自动改进bug检查规则以便更有效地检查智能合约。即能够通过使用词嵌入,灵活和自适应地去检测任意的新的bug。该方法主要有两部分要点:
1.代码和bug的模式,包括词汇、语法甚至语义信息能够被自动编码成数值型向量(即词嵌入)。
2.代码bug的检查可以通过智能合约中不同粒度级别的各种代码元素的数值型向量之间的相似性检查来实现。
论文收集了22725份Solidity语言编写的智能合约和17份常见的bug智能合约。
论文主要贡献:
1.为智能合约代码检测提出了一种基于代码嵌入和相似性检测的新方法,能够用于类型合约代码的检测,bug检测和合约验证等多方面。
2.在超过22000份以太坊区块链收集的智能合约代码上进行模型的验证。
3.在代码克隆检测方面,实验结果表明论文的方法能够有效地识别出许多重复的Solidity智能合约代码(克隆比率为90%),并且相比于常见的一些克隆检测工具能够更准确的检测出更多的语义克隆。
4.在bug检测方面,实验结果表明论文的方法在基于其bug数据库上,能够识别出超过1000多个与克隆相关的bugs。
方法:
以下是SMARTEMBED模型的整体框架图:
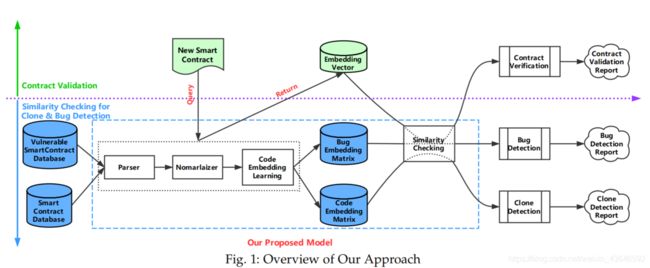
基于代码embedding和相似性检测,SMARTEMBED针对3个任务:
1.clone detection(克隆检测)
2.bug detection(bug检测)
3.contract validation(合约验证)
对于克隆检测和bug检测,论文的目标是在现有的以太坊区块链上识别代码克隆和代码克隆相关的bug。
而对于这个合约验证,当给定一个新的智能合约代码,SMARTEMBED将会验证其是否包含有与bug数据库中相关的漏洞语句。
首先,收集到的智能合约代码将会通过论文构建的解析器加载和解析后,生成抽象语法树AST。
接着,通过序列化AST来提取一个token流。
然后,通过上图中的Normalizer部分重新组合token流以消除不同智能合约之间的差异(如停用词,常量值,文字)。
再然后,将Normalizer输出的序列输入代码表示子模型,通过模型的训练与构建,每个代码片段都会被嵌入成一个固定长度维度的向量。所有源代码和漏洞代码都会被编码进对应的嵌入矩阵。
最后,在向量空间中使用相似度检测进行克隆检测、bug检测、合约验证。
下面对各部分关键技术进行讲解:
1.Data Collection:
论文通过“EtherScan”(它是一个块浏览器和以太坊分析平台)收集智能合约代码。通过网络爬虫去系统地搜索和下载整个网站上的HTML页面。然后解析HTML,得到一些关键信息(如合约地址、源代码、字节码等)用于进一步的评估。
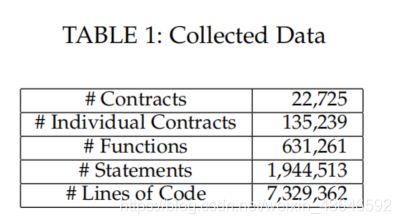
一共收集了22725份经过验证的智能合约。平均每份智能合约包含:6个单独的合约,27个函数,85个声明,323行代码。
以下是具体的统计信息:
2.Parsing:
AST是程序结构信息的表示,论文使用了一个自定义的Solidity解析器来解析智能合约代码为AST。然后基于AST构建code embedding。
具体地,使用ANTLR和一个自定义的Solidity语法生成XML解析树,作为代码的中间表示(即AST)。下面是一个智能合约即其对应AST的例子:

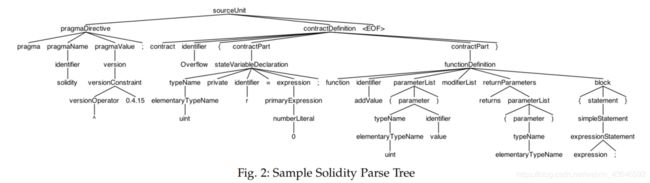
论文根据树节点的类型,在不同层面(合约层面、函数层面、声明层面)对解析树进行序列化操作。这样做是为了捕获代码的结构化信息(如我们关注点周围的分支、循环条件)。
进一步地,重要的token和identifier names被处理并放入从树序列化得到的code element sequence中,这样明确的数据流信息(通过定义或者使用相同的名字)就被添加到序列中了。

合约级别的tokenization:
通过中序遍历XML解析树,提取出所有的终端token(用的是上图的Solidity代码):

函数级别的tokenization:
在函数token后面加上合约的签名。结果如下:

声明级别的tokenization:
它合约级别的tokenization和函数级别的tokenization不同,基于terminal tokens,加上更多的结构和语义关系的细节信息。比如,对于上面的代码,在AST中的祖先链和函数签名都可以从XML解析树中得到。通过添加AST中的祖先链,我们的模型可以捕获这种结构化关系;通过添加不同的邻居节点,我们的模型可以捕获关于关注点的上下文信息。

通过上述的解析树进行代码的序列化,可以捕捉多数的结构和语义信息。
3.Normalization:
通过移除一些语义无关的信息来规范化token序列,具体步骤如下:
Stop words:
对于单个字符的变量。使用“SimpleVar”代替它,例如:

Punctuation:
移除一些对代码操作语义没有影响的标记,一些非必要的标点符号,必要的会保留。例如:

Constants:
对于常量类型,我们统一称其为:“StringLiteral”, “DecimalNumber”, “HexNumber” and “HexLiteral” 等。例如:

Camel Case Identifiers:
对于驼峰式的标识符,我们将其作为保留的token,并将其拆分成单独组成的单词,例如:

经过上述的规范化处理后,保留了1.2GB的干净文本,总计119568 tokens。这组成了最后输入训练算法的训练数据集。
4.Code embedding learning:
基于上述规范化的结果,我们将每个可能的代码段(例如声明,函数,合约)分别映射到高维的向量。论文采用了以下2两种embedding算法:
Word2Vec:
它学习词的向量表示,对于预测统一句子中周围的词很有用。然而,传统的Word2Vec并不能捕获到词的形态结构。
FastText:
FastText则尝试解决这一问题。其通过把每个单词作为它的子词的聚合(子词是从这个单词的n-gram得到的),所以使用FastText得出的单词的向量是组成其的所有n-gram的向量的和。
对于这两个算法的实现,论文是采用了python的gensim库(它包含了这两种算法 )。对于接下来的实验,采用FastText作为主要的embedding算法。原因有如下2点:
1.根据实验结果,FastText在语法任务上比Word2Vec出色。原因可能是因为FastText考虑了子词的信息,它能够从上下文中捕获更多的语义以及语法信息。
2.FastText可以获得词汇量外的单词的向量(通过组成该单词的char-ngrams的向量求和获得)。
详细的code embedding学习过程描述如下:
Token Embedding:
我们把从规范化得到的token流作为训练语料库。然后使用embedding算法对合约级别、函数级别、声明级别的训练语料库进行训练。
因为在Solidity语法文件中有308个节点类型,所以论文为了压缩和节点类型无关或重叠的含义,设置了词嵌入向量维度大小为其一半:150。
这个token embedding 过程作为构建higher level embedding 的一个预训练阶段。
Higher Level Embedding:
当我们得到了token的基本向量表示后,代码段的higher level embedding(如声明级别。函数级别、合约级别)可以由这些token的基本向量构成。
为了捕获语义特征和代码大小,我们使用求和的方法来组成这个共享的嵌入。对于一个特定的代码段的code embedding由其所有可能的token embedding求和组成。具体定义如下:
给定一段Solidity代码T,对于每个在T中的token w,我们定义这一段代码T的code embedding为:(有点类似NLP中的将一句话所有单词的embedding相加构成这句话的embedding)
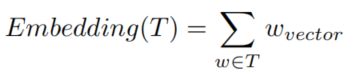
5.Embedding Matrix Building:
在上面得到embedding后,我们将这些单个的向量堆叠起来分别构成3个code embedding矩阵(分别对应contract-level、function-level、statement-level)
![]()
Contract Embedding Matrix:
![]()
c:表示所有论文收集的智能合约的个数,为22725。
d:表示code embedding size,前面设置为150。
![]()
所以将Ci作为第i个合约的code embedding,它是一个150维的向量。
Function Embedding Matrix:
![]()
f:表示所有论文收集的相关函数的个数,为631261。
d:表示code embedding size,前面设置为150。
同理矩阵每一行的Fi代表第i个函数的code embedding,它是一个150维的向量。
Statement Embedding Matrix:
![]()
f:表示所有论文收集的相关声明的个数,为1944513。
d:表示code embedding size,前面设置为150。
同理矩阵每一行的Si代表第i个声明的code embedding,它是一个150维的向量。
6.Similarity Checking:
下面定义相似度检查的方法,它会用于接下来的clone detection, bug detection, contract validation。
给定两个代码段C1和C2,e1和e2为其对应的code embedding。我们定义两个代码段的语义距离如下(即向量欧式距离除它们的模长和):
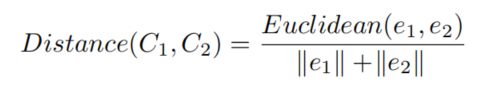
则这两个代码段的相似度定义如下:
![]()
当两代码段的相似度超过一个预先定义好的阈值时,我们将这两代码段视为克隆对(clone pair)。
7.Clone Detection, Bug Detection, Contract Validation:
基于上述的code embedding我们构建了相似度检查方法。可将其应用于多个任务,
对于clone detection:我们通过计算两智能合约代码的相似度是否超过某一预先定义的阈值来判断其是否clone。
对于bug detection:我们通过计算在我们代码库中的代码和已知的bug代码的相似度是否超过某一预先定义的阈值来判断其是否buggy。
对于contract validation:当开发者输入一个新的智能合约,我们通过计算它和收集到的buggy statements 的相似度,超过某一特定阈值,则新的智能合约中的错误statements会被识别出来。
对于以上3个不同给的任务,这个预先定义的相似度阈值可能不同。
实验部分:
1.Code Embedding Evaluation:
我们知道,如果两个符号在一些方面越相似,那么它们在对应特征维度中的值也应该越相似。我们选取了前100个频率最高的tokens的code embedding,并利用T-SNE算法将其映射到二维平面,如下(相似的单词它们在对应的向量空间中会很相近,也即在下面这个二维平面中会很相近):
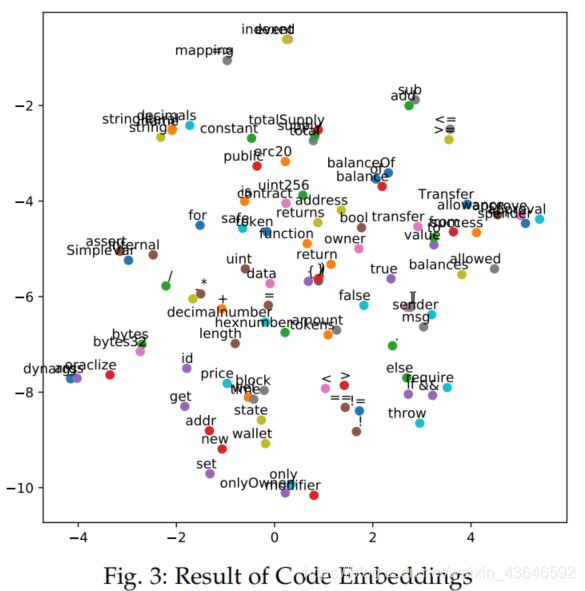
从图中,可以看出哪些具有相似语法和词汇意义的tokens都聚集在了一起。例如+,-,*,/等操作符聚集在了一起。这说明了高维的code embedding能够很好地捕获tokens的共现统计信息和分布式语义。
2.Similarity Checking Evaluation:
为证明论文提出的相似性检查的有效性,我们在3个任务中评估该方法:code
clone detection, bug detection, and contract validation。并且使用Deckard(用于clone detection)、SmartCheck(用于bug detection和contract validation)这两个工具做结果对比。
以下部分,主要围绕以下6个问题展开:
RQ-1: Clone Detection Evaluation:
实验设置:
该部分实验通过相似性检查来评估code clone detection(分别对3个方面进行检测:contract-level, function-level, statement-level):
Contract-level clone detection:
在上面,我们将每个合约都映射成了一个固定维度的向量,现在我们构建一个相似度矩阵M,维度是22718 x 22718(这里移除了7个解析错误的案例)。其中每个元素Mij对应合约si和sj的相似度得分。如果Mij大于预先定义的相似度阈值,则将它们认为是一个克隆对。
Function-level clone detection:
理论上我们也可以定义一个和上述合约级别中一样的相似度矩阵,但是由于我们函数有631261个,如果要两两计算相似度的话会很耗计算成本。所以我们随机抽取了200个智能合约,然后利用其中的5307个函数。我们由此构建了一个相似度矩阵N,维度是5307 x 631261。其中每个元素Nij对应采样函数fi和fj的相似度得分。如果Nij大于预先定义的相似度阈值,则将它们认为是一个克隆对。
Statement-level clone detection:
和函数级别中一样,考虑到计算量大的问题。利用上述随机抽取的200份合约中的16350个声明,构建了一个相似度矩阵Q,维度是16359 x 1944513。其中每个元素Qij对应采样声明si和sj的相似度得分。如果Qij大于预先定义的相似度阈值,则将它们认为是一个克隆对。
实验结果:
实验部分与代码克隆检测工具Deckard检测的结果进行对比。我们为Deckard和SMARTEMBED设置了相似度阈值为1.0和0.95的两种情况进行测试,结果如下:
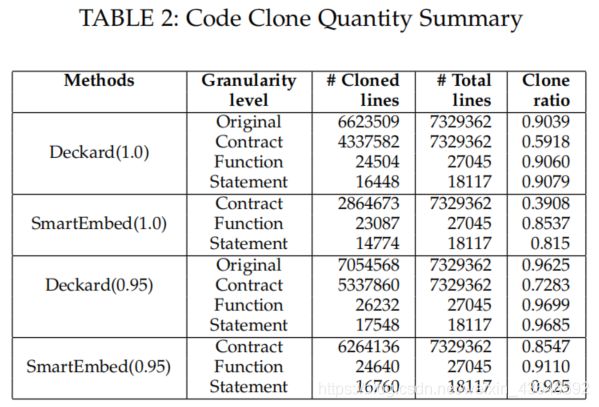
从上表中我们可以知道,在智能合约中代码克隆比率是相当高的。
在不同粒度级别和相似度阈值上,SMARTEMBED的代码克隆比率整体上是比Deckard要低的。我们认为SMARTEMBED比Deckard检测克隆代码更为精确,因为SMARTEMBED它的代码编码过程不仅考虑了代码的结构信息,还考虑了代码语义信息。而Deckard只考虑了结构信息。
大多数被SMARTEMBED检测到的克隆代码也被Deckard检测到了。我们统计了两种方法检测到的克隆代码的重叠率,结果如下表:

用Venn图直观地表示它们的重叠率:
contract-level:

function-level:
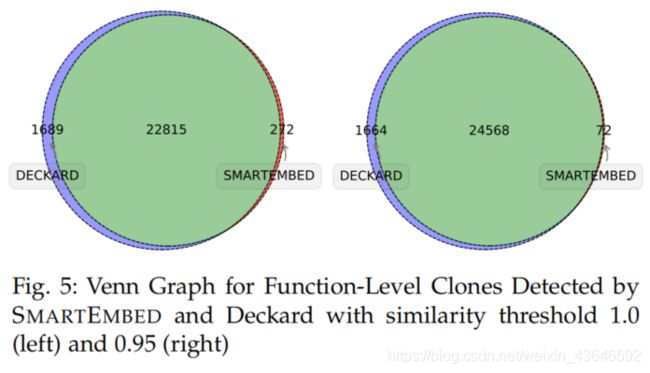
statement-level:
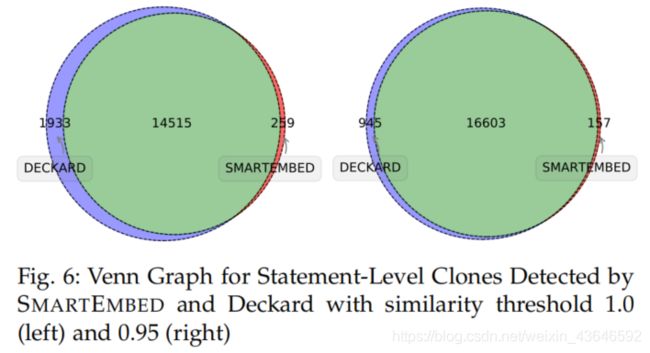
关于在智能合约中存在如此高的代码克隆比率,我们将原因归结为以下几点:
1.一个主要原因是因为以太坊区块链上的智能合约代码的不可篡改性。当我们升级了当前的代码并重新部署时,旧的代码仍会继续保留在区块链上。我们考虑了当检测到的克隆代码属于同一个创造者时,将不考虑它。即使这样,代码克隆的比率还是很高。
2.ERC20智能合约模版是一个主要的技术标准,它包含有很多函数以及事件的接口。根据实验发现有68.3%的智能合约中包含了ERC20标准,这说明了ERC20也是代码克隆比率较高的原因之一。
代码克隆检测的一些例子:
为了对比SMARTEMBED和Deckard两种检测方法的,我们手动挑出一些能够被SMARTEMBED检测出但是不能被Deckard检测出的克隆案例:

如上两图,这两份代码有着相似的语句,只是添加或修改了部分语句。它们可以认为是语义克隆。因为Deckard是注重于语法结构形式的检测,所以没检测出来。
同时,我们挑选了Deckard能检测出但SMARTEMBED不能检测出的案例,如下:

由上两图可知,虽然这两函数的名字都叫“addCompany”,但是它们使用了不同的数据结构,所以不能被当作语法克隆。由于Deckard忽略了代码中不同标识符的名字,所以才会偶然识别出这种克隆的情况。而SMARTEMBED则是结合了代码嵌入向量来加以区分这些不同标识符的区别。所以说SMARTEMBED相比于Deckard更加精准、有效。
RQ-2: Bug Detection Evaluation:
为了能够快速使用某些函数,开发者们往往会复制一些代码,这可能会引入克隆相关的bug。为了使我们的方法能够更准确地检测出bug,我们在statement-level粒度级别上执行bug检测。
实验设置:
为了检测bug,我们需要收集一些错误语句来构建bug数据库。我们收集了52份已知的属于10种常见类型漏洞的智能合约。然后手动确定这些合约中的漏洞语句(通过查阅论文、网络上的文章、社区讨论确定)。然后整理了一个表如下:
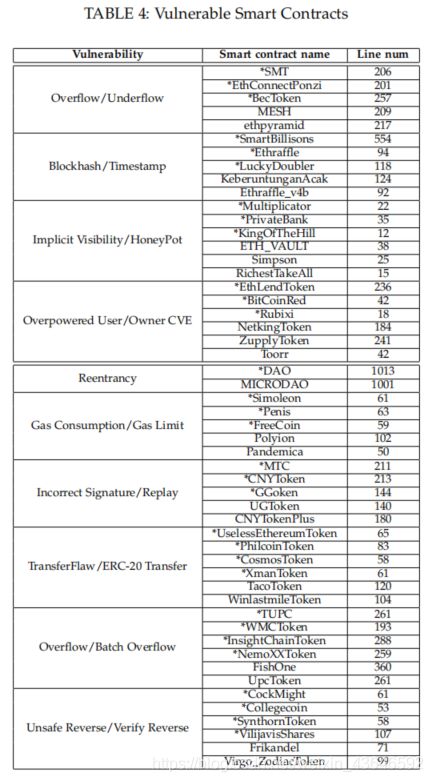
表格中带‘*’号的32个智能合约用于bug detection(包含63个buggy statement,然后通过code embedding处理好后作为我们的bug database,它是一个63x150的矩阵 )。其它20个用于contract validation。
我们将会对比由我们的方法报告的bug候选代码行和真实的bug代码行。如果候选bug代码行满足以下3个条件之一,即可被确认(手动确认候选bug代码行是否检测正确):
1.候选的bug语句和真实的bug语句完全一样,则判定为type-I 类型clone-related bugs。
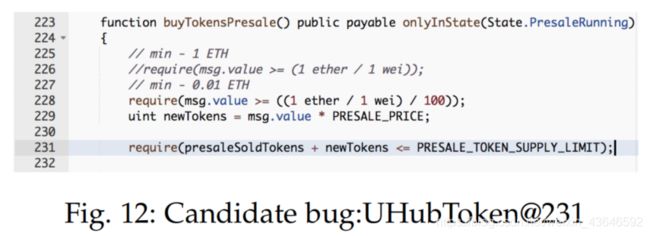
2.候选的bug代码语句包含了与真实bug代码语法等价的代码片段(带有标识符、文字或类型的变化),则判定为type-II类型clone-related bugs。例如下面两图的例子:

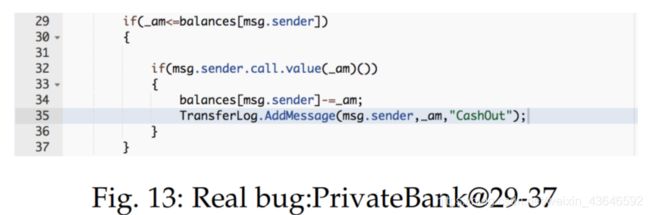
3.候选bug代码语句涉及与真实bug代码语句类似的代码插入、删除。更新语句。则被判定为type-III和type-IV类型clone-related bugs。例如下面两图的例子:
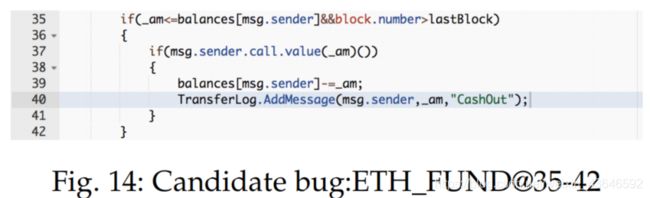
实验结果:
对于不同类型的bug-related bugs,SMARTEMBED的检测结果如下表(相似度阈值设置为0.9):
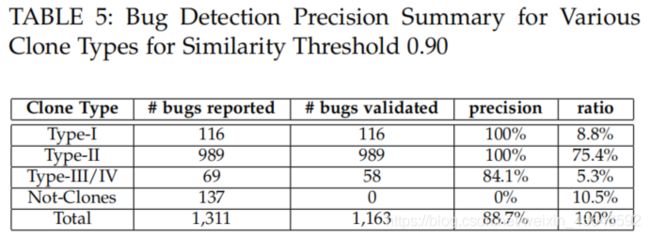
从上表我们可得到如下3点信息:
1.大多数由SMARTEMBED识别出的候选bug代码属于type-II类型,这说明开发人员在确实通过复制别处的代码引入了clone-related bugs。
2.SMARTEMBED在识别type-I和类型type-II上能够达到100%的识别准确率。这是因为这两种类型不会引入代码结构的改变,所以能够被轻易识别出来。
3.而在识别type-III/type-IV上则有所下降,,所以为了识别出这种类型的bug,需要降低相似度阈值,但是这同时可能会引入更多的假阳性案例。
下面是对采取不同相似度阈值时,模型的性能表现结果:
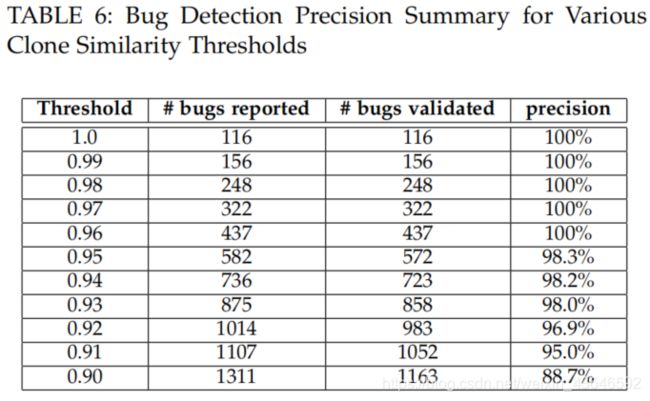
从上表我们可得到如下3点信息:
1.相似度阈值越高,模型准确率越高。
2.相似度阈值越低,将会有更多的语句被识别为候选bug语句,及时如此,模型还是保持了一个较高的准确率。
3.而当相似度阈值设置为0.9时,准确率下降为88.7%,这是因为过小的相似度阈值,会引入更多噪声(即更多不准确的候选bug代码语句)。同时也说明了0.9和0.91可能是一个较好的相似度阈值。
下面我们将进行和SmartCheck漏洞检测工具的对比:
由于在所有20k+的智能合约上检测,计算成本比较高,所以我们只使用我们上述Table 5中手动验证好的带有1163个bug语句的合约中运行SmartCheck。为了公平起见,关于SmartCheck工具的bug检测模式我们按上面Table 4中的10种常见bug类型设置。然而SmartCheck只检测出了1163个中的697个,这足以显示出我们提出的模型在检测clone-related bugs上的优势。
bug detection 的一些例子:
我们手动挑选了一些能够被SMARTEMBED检测出的bug而不能被SmartCheck检测出。一些bug,如Tabel 4中的“Honeypots”不能被SmartCheck有效地检测出。例如下面的例子:

因为msg.values是发送给payable public函数的ETH,而this.balance是存储在智能合约中的ETH,所以当调用这个函数时,this.balance将会更新为this.balance+msg.values。所以上图中的第7行的if条件将永远不会成立,除非this.balance初始为0。所以这是一个bug。
所以呢,使用类似SmartCheck这种检测工具去定义这种特殊的bug识别模式需要额外的精力。而使用SMARTEMBED则仅需要将bug代码进行code embedding进行相似性检查。当然我们方法的优势也是建立于良好的对代码结构以及语义信息embedding上的。
总的来说,我们的方法在大量的智能合约中进行clone-related bug detection是非常有效的。
RQ-3: Practical Analysis:
智能合约中代码克隆率高的一个关键问题是:原始代码最好应该在其后续版本的每个副本中得到修复。下面将通过实际的分析去验证SMARTEMBED能否区分修复了bug的语句和原始存在bug的语句。
实验设置:
因为智能合约一旦部署不可篡改,所以当发现一个智能合约中存在bug时,需要重新部署一个修复bug后的新合约。对于每个在我们构建的bug数据库中的buggy智能合约,我们手动调查了合约创建者的历史创建记录,以查看是否存在对某个特定buggy语句修复的修复版本的合约。最后我们发现,在我们构建的bug数据库中的52个buggy智能合约中,有5个智能合约是包含一个修复版本的合约的。同时我们指出了修复的语句,并评估了修复的语句和它对应的buggy语句的相似度。
实验结果:
实验结果如下表(我们计算了修复的语句和它对应的buggy语句的相似度):
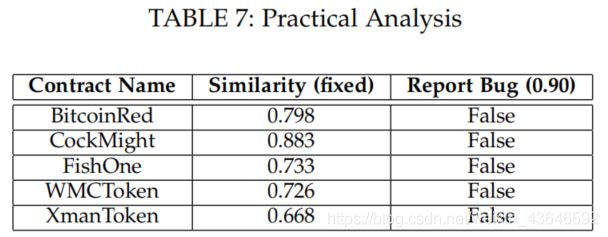
从表中我们可以得出如下2点信息:
1.通过设置相似度阈值为0.9,则所有修复后的智能合约不会被SMARTEMBED检测出bug。即使修复后的版本和原始版本很相似,SMARTEMBED也能够很好地检测出。这是因为SMARTEMBED集中于statement-level的bug检测,任何微小的修复也会使code embedding得到的向量不同,这样一来也就降低了它们之间的相似度。
2.从上表结果可以证明SMARTEMBED能够很好地区分开原始存在bug的语句和修复bug后的语句。
bug及其对应的修复bug后的例子:

从图15的193行代码我们可以知道,这很容易发生溢出的情况。如果_value是一个十分大的数字,则经过这个乘法运算,amount会溢出,然后变成一个十分小的数字。这样一来会造成transfers超过balances[msg.balance]的代币。
而在图16的283行使用了_value.mul(),这可以通过使用安全的数学运算(例如SafeMath)来处理溢出问题。这样,通过修复后的bug语句的改变,可以达到降低它和原始bug语句的相似度的目的。
总的来说,SMARTEMBED能够非常有效地区分开修复bug后的代码和原始bug代码。
RQ-4: Ablation Analysis:
当我们进行bug detection时,SMARTEMBED的一个主要新奇之处是它基于AST解析树序列化来进行结构以及语义信息的提取。例如,前面我们通过在AST解析树中添加祖先链来捕获序列的派生,以及利用函数签名来捕获不同邻居节点的关系。同时我们也在前面通过实验证明了SMARTEMBED在bug detection的准确性。这一部分,为了验证对SMARTEMBED添加的结构以及语义信息的有效性,我们在bug detection任务上进行了消融实验。
实验设置:
为了进行消融实验,我们使用了SMARTEMBED的不完整版本BASICEMBED,它从statement tokenization结果中移除了所有结构以及语义信息,只保留了简单的statement token序列。其他如Normalization等步骤与SMARTEMBED相同,我们我们将为其构建一个新的code embedding模型,然后也同样使用上面表4的bug数据库进行相似度计算。
实验结果:
SMARTEMBED和BASICEMBED的bug detection结果如下表:
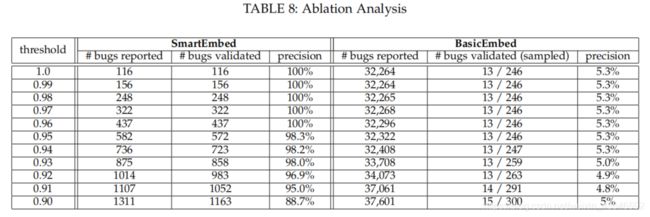
从上表我们可以得到如下3点信息:
1.BASICEMBED的整体精度在5%左右,这说明简单地提取语句的token序列不足以进行bug检测任务。
2.对于各相似度阈值,SMARTEMBED的精度大幅度超越BASICEMBED。这说明添加结构以及语义信息能够对模型的整体检测性能带来很大提升。
3。87%由BASICEMBED检测出的bug属于type-I 类型的bug。这是因为没有考虑语句上下文结构信息以及语义信息,BASICEMBED只能简单地检测出一些简单类型的bug语句。
BASICEMBED的bug检测的例子:
如下图:

上面的错误是,原本正确的话,函数DynamicPyramid的名字应为Rubixi(即作为合约的构造函数),即合约的创建者才能调用,不然像这样,任何外部调用者都能调用成为了合约的owner,则合约的代币将会被外部调用者盗取。
然而BASICEMBED指出的bug语句是第5行的代码:owner=msg.sender。这显然是不合理的,像这样没有考虑上下文信息,在和其他合约中的语句进行相似度计算时和容易造成假阳性的识别案例。这就是为什么BASICEMBED的识别精度低的原因。
而使用SMARTEMBED,则会在code embedding 向量中到考虑函数名字:function DunamicPyramid和合约的祖先节点:Rubixi。这样能够有效降低假阳性的案例,检测出更多真实的bug。
总的来说,SMARTEMBED中引入的结构以及语义信息对模型的整体性能带来了很大的好处。
RQ-5: Contract Validation Evaluation:
因为智能合约一旦部署将不能修改,所以在部署前最好确保其正确性。所以这一部分的实验是为了测试SMARTEMBED检测合约中的所有bug的能力,以验证合约的正确性。即使SMARTEMBED不是一个正式的验证工具,但因为我们的方法能够通过添加新的bug到bug数据库,从而很容易地进行扩展以检测合约中是否存在和bug数据库相似的bug。
实验设置:
给定一个待检测的智能合约,我们将为其中的每一条代码语句生成一个150维的向量,并与我们构建的bug数据库中的所有bug进行相似度检查(相似度阈值设置为0.95、0.90、0.85)。
这一部分测试数据我们采用了Table 4中没带‘*’号的20个bug智能合约,和从Zeppelin收集来的20个无bug的智能合约。总共2857条语句,其中45条bug语句。
对比了SMARTEMBED和SmartCheck的bug检测效果。结果如下表:

同时计算了precision,recall,F1-Score,FPR(false positive rate),FNR(false negative rate),结果如下表:
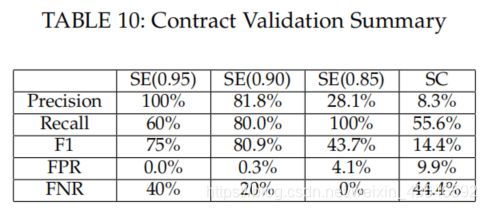
实验结果:
从表9和表10可以得到如下4点信息:
1.对比SMARTEMBED和SmartCheck的结果,SMARTEMBED能够更准确地检测出clone-related bugs。
2.SmartCheck比我们的方法检测出了更多假阳性的案例。为了公平起见,我们对SmartCheck的bug检测模式也是按Table 4 中的bug来设置的。
3.仔细地可以看出,相似度阈值为0.95和0.9时检测出的clone-related bugs数量为:27和36。这可能是因为开发者在克隆代码时,对克隆的代码做了少许修改,所以需要降低一点相似度阈值来检测出它们。
4.当设置相似度阈值为0.85时,假阴性数量下降为0。这意味着所有bug都被SMARTEMBED检测出来了。其他各指标也均优于SmartCheck。
总的来说,我们的模型能够很有效的捕获出类似假阳性的bug。我们将来的研究也将继续丰富我们的bug数据库,并进一步改进code embedding。
RQ-6: Time Cost Analysis:
我们的SMARTEMBED的时间消耗主要在code embedding的训练和向量的相似度计算上,还取决于合约数据库和bug数据库的大小。
实验测试环境:Intel Xeon CPU E5-2640 v4 @2.40GHz。
训练code embedding需要大约一天时间。
我们对 clone detection, bug detection,contract validation三个任务进行时间复杂度的测试。在Deckard和SmartCheck上检测一个智能合约平均用时分别为:79.2ms和416.3ms。而SMARTEMBED:在clone detection任务上只需要0.26ms。在bug detection任务上只需要2.3ms。在contract validation任务上只需要4.7ms。
总的来说,SMARTEMBED在克隆检测以及bug检测的任务中,实用性是很好的。
DISCUSSION部分:
主要讲的是作者联系了一些Solidity开发人员,并发送了一些SMARTEMBED的检测结果给他们,让他们提提意见。部分开发者对SMARTEMBED很感兴趣,部分觉得对他们来说不适用。(具体关于他们对SMARTEMBED的评论意见请参看论文)
根据大部分开发者的建议,作者将SMARTEMBED实现成了一个Web应用工具供外部测试人员使用(有对应一篇论文介绍)。同事SMARTEMBED的源码以及使用到的智能合约数据也开源了在Github上。
还有部分开发者建议将SMARTEMBED作为一个扩展与增强工具发布在Etherscan上。还有部分建议将SMARTEMBED集成在一些IDE中(如Remix,VScode)。
我们将会根据这些建议改善我们的模型。
对有效性的威胁:
1.内部有效性:
对于code embedding 可能会因为代码段大小的不同影响我们方法的检测。目前有很多相关的方法做code embedding(具体看论文有介绍)。所以在未来,我们将对同一任务采取不同的code embedding技术进行测试。
2.数据有效性:
我们从Etherscan中收集了22725份智能合约,但是由于以太坊智能合约数量的飞速发展,我们在未来需要引进更多的数据以扩大我们的代码数据库和bug数据库,来重新训练我们的模型。甚至可能尝试对Solidity字节码进行code embedding。
3.外部有效性:
因为我们只是从SmartCheck基准测试中验证了SMARTEMBED检测到的克隆相关错误。而SmartCheck也会出现检测到假阳性和假阴性的案例,所以也会对结果造成影响。在未来,我们将对现有的一些其他安全分析工具进行大规模测试,并从从业者那获取更多的意见。
总结:
基于code embedding对代码的结构信息以及语义信息进行了嵌入,提出了SMARTEMBED。
使用相似性检查对3个任务进行检测(在超过22000分智能合约上进行):
1.clone detection
2.bug detection
3.contract validation
并与安全分析工具Deckard, SmartCheck进行了性能的对比。实验表明论文的SMARTEMBED模型在以上3个任务中表现更为出色。并且SMARTEMBED在实际应用中也能达到实时高效的性能。