汇编与反汇编入门-X86 AT&T汇编
汇编与反汇编入门-X86 AT&T汇编
- 前言
- 反汇编一段C语言代码
- 人工分析函数堆栈变化情况
- 使用gdb调试
- 总结
前言
要懂缓冲区溢出首先需要一些汇编的知识(以下均为X86汇编),比如其实我们程序工作是通过堆栈,这就涉及了三个寄存器esp,ebp和eip。esp是栈顶指针,ebp是栈基指针,eip寄存器是CPU需要读取的指令的地址,(注意实际只有一个函数栈)可以理解为程序执行的那个地址。当然还有一些寄存器。
EAX 是"累加器"(accumulator), 它是很多加法乘法指令的缺省寄存器。
EBX 是"基地址"(base)寄存器, 在内存寻址时存放基地址。
ECX 是计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器。
EDX 则总是被用来放整数除法产生的余数。
反汇编一段C语言代码
首先来一段简单的C程序
int g(int x){
return x+6;
}
int f(int x){
return g(x);
}
int main(){
return f(17)+1;
}
有一点语言基础的应该都看得懂这个程序,首先程序入口是main,main调用f函数进入f函数,f函数再调用g函数,进入g函数。我们来反编译一下
gcc -S test_compile.c -o test_compile.s -m32
可以回忆一下gcc -E是将C程序预编译为.i文件, -S是编译为汇编语言.s文件,-c是汇编为.o文件,最后还有链接环节变为可执行文件,这里就是将C语言文件编译为.s汇编文件,-m32是32位编译,需要下载一些库,具体的可以去查。当然编译后会有许多无用的行,即.以后的东西,我们可以删除它们,留下有用信息。使用如下命令
sed -i '/[.]/d' com_compile.s
或者进入.s文件然后按下ESC,:输入g/.s*/d。最后剩下的汇编语句如下(Linux汇编为AT&T风格-源操作数在前,目的操作数在后。):
g:
1 endbr32
2 pushl %ebp
3 movl %esp, %ebp
4 addl $_GLOBAL_OFFSET_TABLE_, %eax
5 movl 8(%ebp), %eax
6 addl $6, %eax
7 popl %ebp
8 ret
f:
9 endbr32
10 pushl %ebp
11 movl %esp, %ebp
12 addl $_GLOBAL_OFFSET_TABLE_, %eax
13 pushl 8(%ebp)
14 call g
15 addl $4, %esp
16 leave
17 ret
main:
18 endbr32
19 pushl %ebp
20 movl %esp, %ebp
21 addl $_GLOBAL_OFFSET_TABLE_, %eax
22 pushl $17
23 call f
24 addl $4, %esp
25 addl $1, %eax
26 leave
27 ret
28 movl (%esp), %eax
29 ret
汇编想快速入门,能够分析这一段应该就可以了。现在来人工分析每一段汇编语句,可能会弄错,请见谅,毕竟本人水平有限。
人工分析函数堆栈变化情况
现在假设堆栈初始情况如下:地址是我随机写的,需要注意的是压栈是往低地址走,出栈是往高地址走。
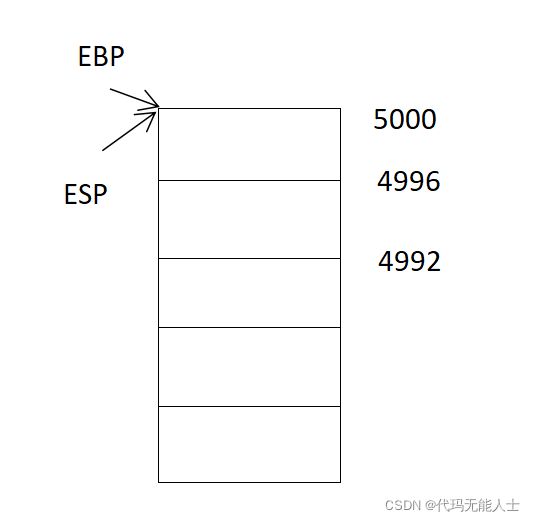
5000是高地址,往下地址在降低。也可以看到栈中每一格相差4个单位。(4字节),计算机内存地址都是十六进制。32位系统堆栈情况才是如此,4B就是32位。如果是64位就是每一格相差8Byte,所以我们为了简单,这里只分析32位的情况。
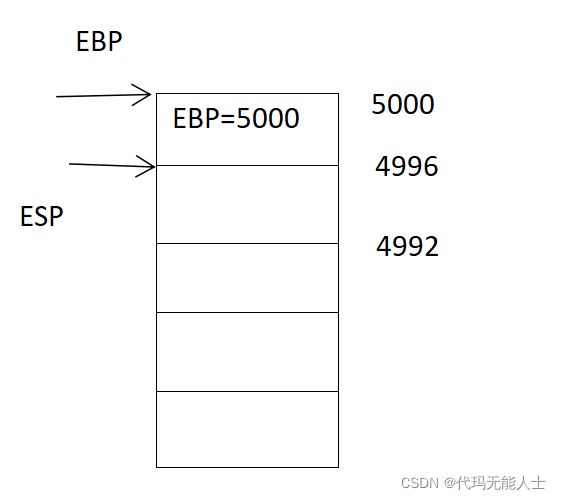
- 汇编第19句
19 pushl %ebp
意思是将ebp寄存器的值压入栈中。
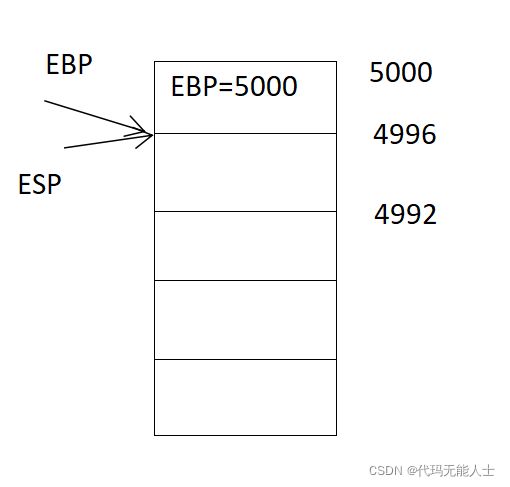
- 汇编第20句
20 movl %esp, %ebp
这一句是将ebp位置更新,将ebp位置移到esp位置。我的理解是%ebp=%esp
3. 21句这一句是将全局偏移表加入eax
21 addl $_GLOBAL_OFFSET_TABLE_, %eax
这一句我觉得不重要,应该是某种规范。
- 22句这一句是将17入栈
22 pushl $17
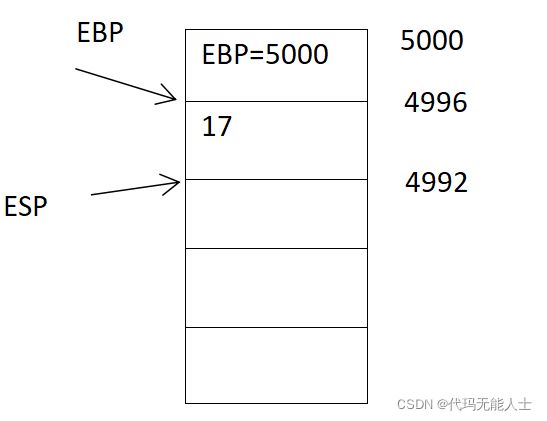
5. 23句是调用f函数
23 call f
调用f函数后会进入f函数,但是会将返回地址压入栈,如果f函数能够返回会执行第24句汇编(这里eip存储的是地址)
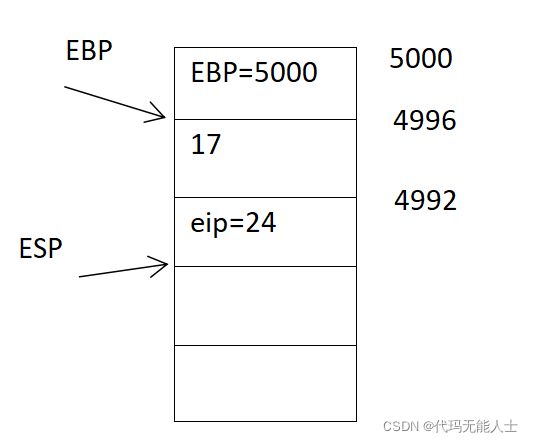
- 现在进入f函数,执行第十句
10 pushl %ebp
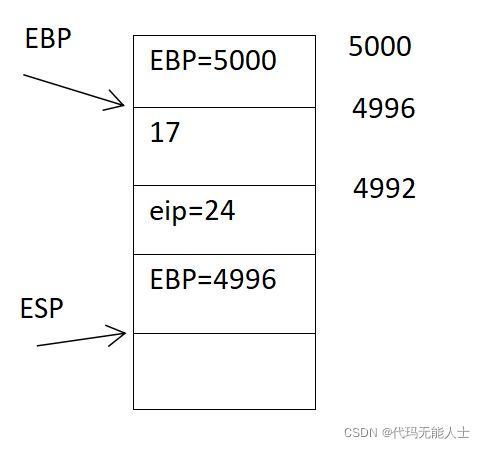
- 执行第十一句,将ebp位置移到esp的位置
11 movl %esp, %ebp
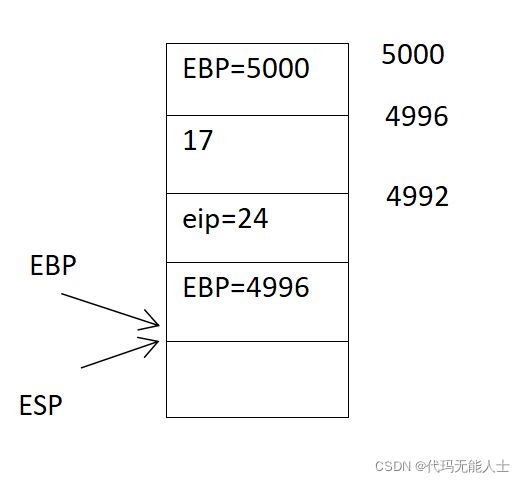
- 执行第十三句
13 pushl 8(%ebp)
这个是压栈操作,8(%ebp)是将现在ebp寄存器的值加8对应的值,可能有点拗口,现在ebp寄存器的值是4984,加上8也就是回到4992,4992位置存放的值是17,所以其实就是把17压入栈中。
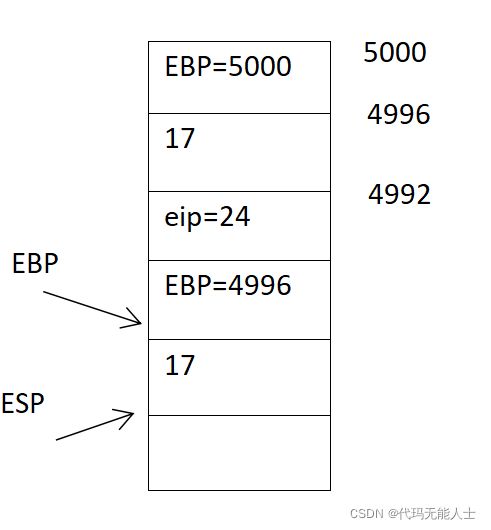
- 执行第14句,调用函数g
14 call g
当能成功返回时会从第15句继续执行。

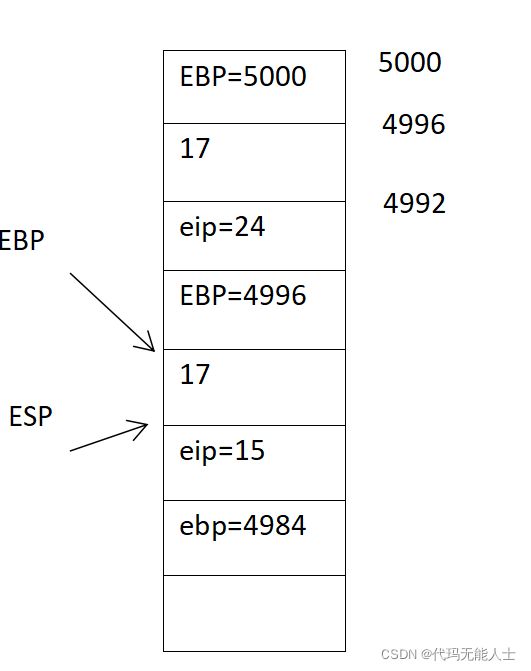
10. 进入g函数执行第2句
2 pushl %ebp
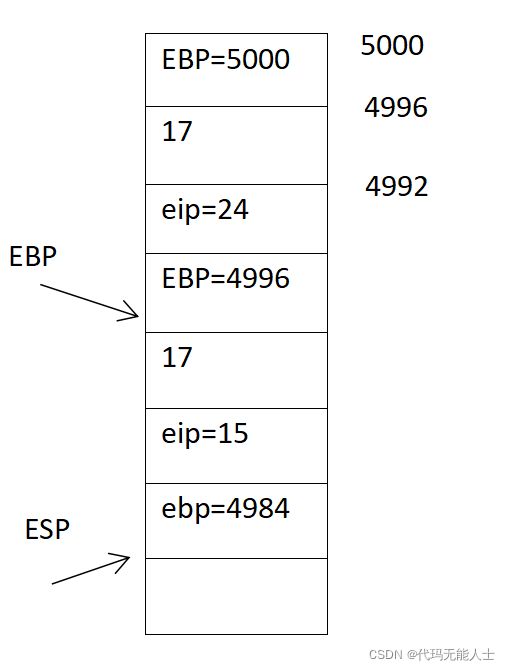
11. 执行第3句,ebp移到esp的位置
12. 执行第5句,这一句需要好好理解
5 movl 8(%ebp), %eax
相当于把%ebp的值加上8(字节),堆栈是从高地址到低地址,加相当于往高地址走,现在%ebp寄存器的值是4976,加上8也就是回到4984,在地址4984存放的值是17,这一句意思是将8(%ebp)移到寄存器eax中,即将17移入eax中,所以现在寄存器eax存放的值为17。
13. 执行第6句,也就是eax的值加上6
6 addl $6, %eax
之前eax的值为17,现在为23
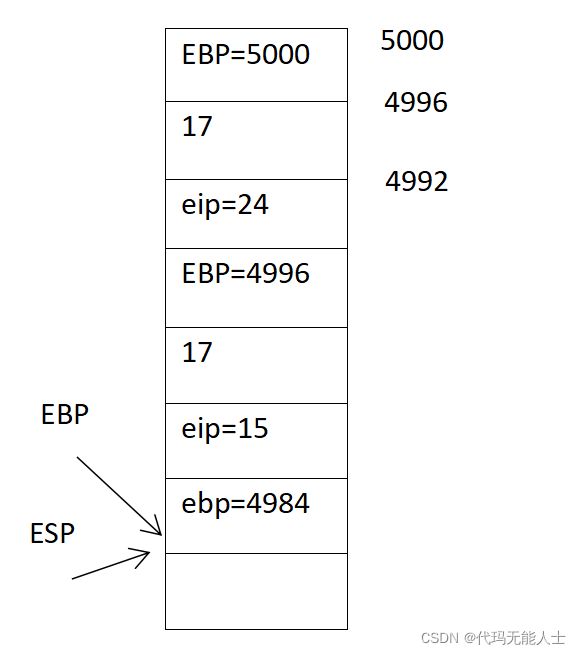
14. 执行第7句,抛栈
7 popl %ebp
这句话的意思是ebp回到之前那个ebp的位置,同时esp位置也回退一格(+4)
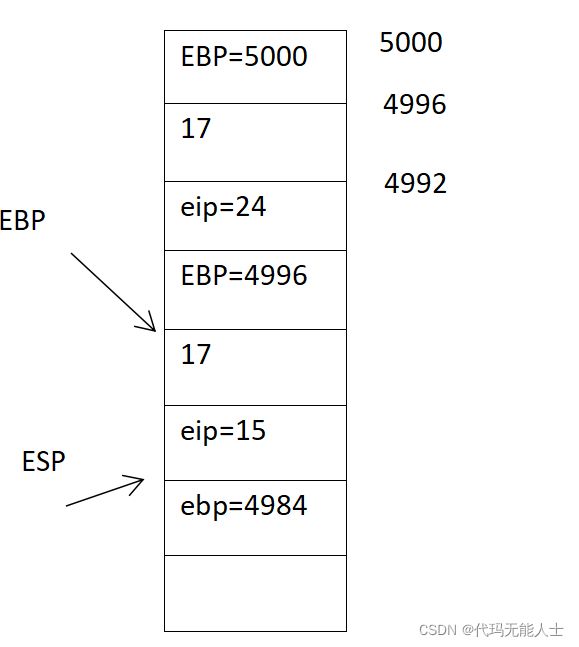
15. 执行第8句,ret,即退出g函数,ret相当于是popl %eip
8 ret
同时%eip的值为15即从第15行继续执行
16. 执行第15句,ret,即回到f函数
15 addl $4, %esp
esp的位置向高位置移动4字节,也就是一格
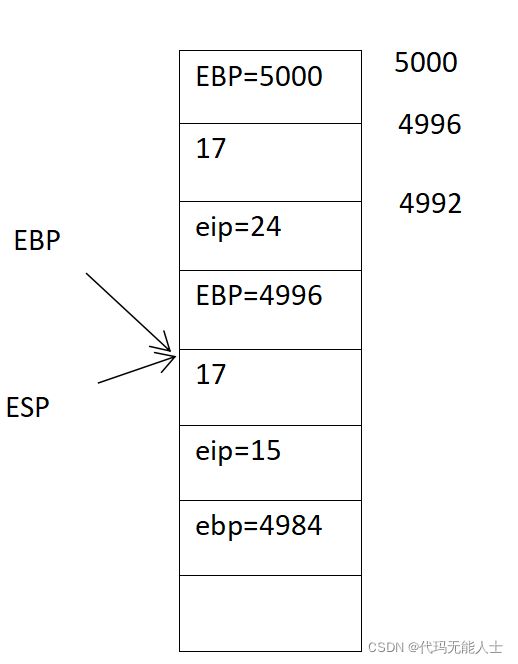
- 执行第16句,leave
16 leave
这个leave执令,相当于如下
movl %ebp,%esp
popl %ebp
即esp的位置移到ebp的位置,然后抛栈
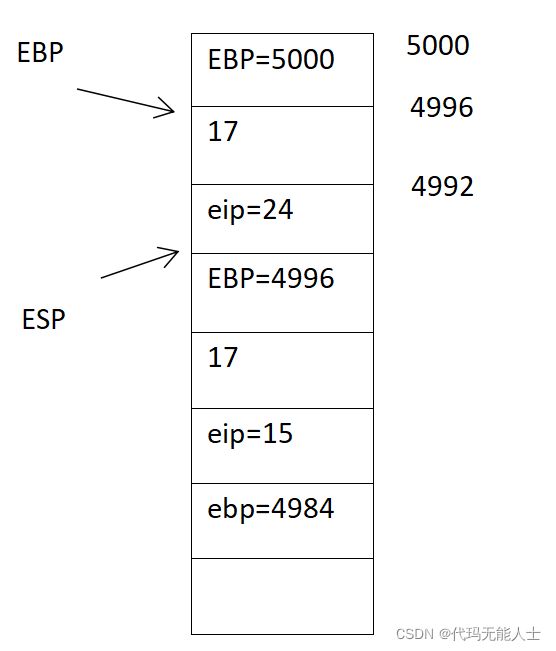
18. 执行第17句,ret,相当于popl %eip,然后eip的值更新到24行的地址,回到main函数
17 ret
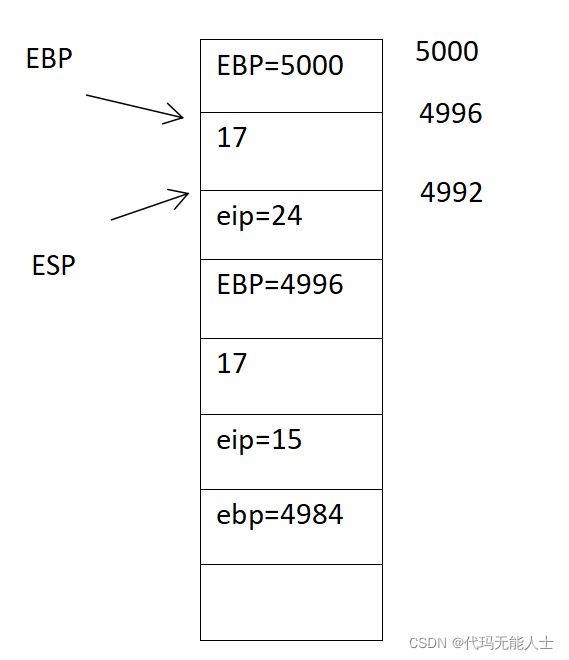
19. 执行第24句,将esp的位置回退1
24 addl $4, %esp
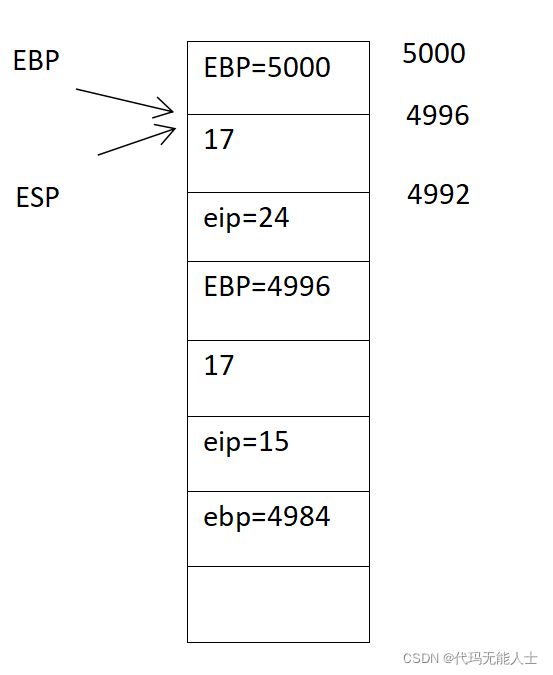
20. 执行第25句,将eax的值加上1
25 addl $1, %eax
之前eax的值为23(步骤13),现在加上1得到eax的值为24
21. 执行第26句,leave
26 leave
之前提到过leave等价于movl %ebp,%esp与popl %ebp。
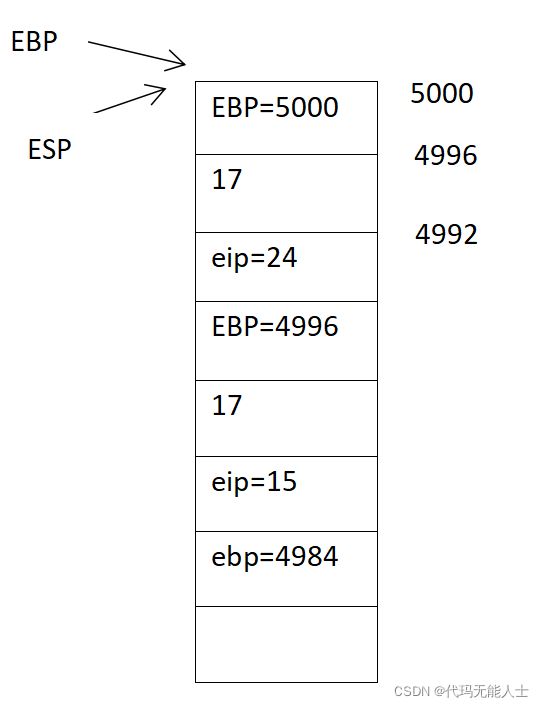
之后就不用分析了,有一行movl (%esp), %eax是将eax的值更新为esp寄存器的值。
使用gdb调试
这个程序相对简单,人工分析是可以的,如果汇编程序很长怎么办,并且人工分析也容易错,我们就需要借助一些工具,这里使用gdb进行调试。
首先要知道gdb中si,ni,n和s
n(next) C语言级别,不会进入函数内部
s(step) C语言级别,会进入函数内部
si(step in) 汇编语言级,会进入函数内部
ni(next in) 汇编语言级,不会进入函数内部
要使用gdb调试要加入-g
gcc -g test_compile.c -o test_compile -m32
gdb test_compile
进入后,可以按l来展示代码
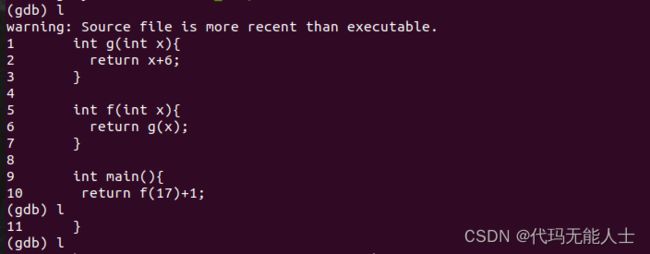
可以反汇编,这里有三个函数,我们来看看反汇编

这里最左边的那些蓝色地址其实就是地址,是eip地址。
现在在三个函数那里设置断点
b main
b g
b f
然后按下r,启动程序
为了观察汇编代码,可以输入
display /i $pc
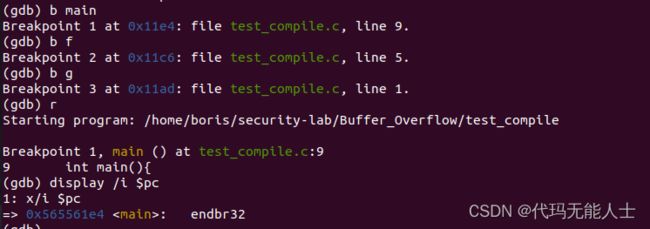
因为是进入汇编函数体内,所以要用si,继续下一语句,因为要观察寄存器变化,所以可以使用i(info) r(register) XXX(ebp,esp,eip,eax)。
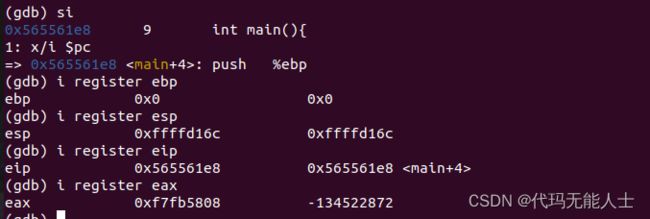
可以使用这个方法继续跟踪语句,列出一个表,注意以下数据的寄存器信息是上一条汇编语句执行后的
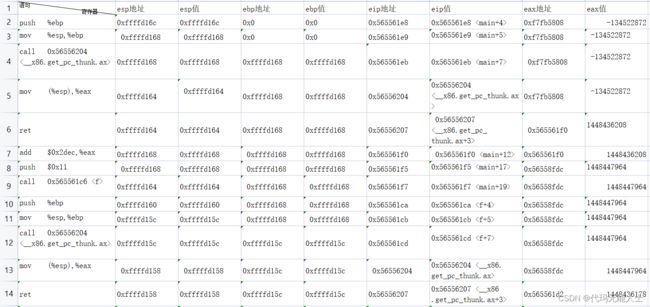
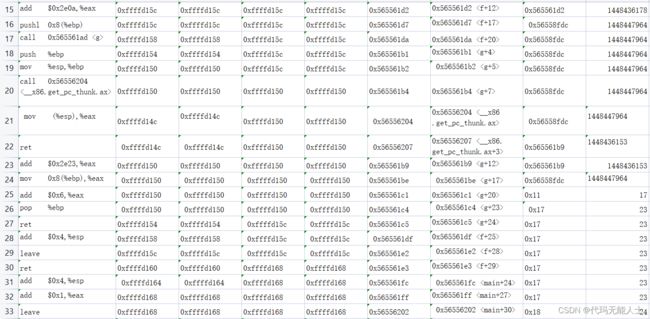
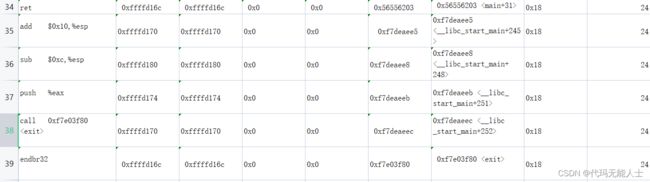
通过以上表格寄存器变化一目了然,其实和我人工分析出来的结果差不多,如果搞清楚这些,汇编应该是入门了。
总结
通过这次反汇编的分析加深了我对汇编的一些基础,要搞懂汇编主要是要弄懂寄存器的变化,有两个寄存器特别重要,分别是%ebp和%esp,函数堆栈就是靠这两个寄存器。32位汇编可以减少分析难度,入栈或者出栈都只变化4字节。
希望这篇文章对您有帮助,也算花了很多时间,对我个人也是一种再次学习。