详述进程控制【Linux】
文章目录
- 1. 创建进程
-
- 1.1 认识fork
-
- fork函数的返回值
- 1.2 写时拷贝
-
-
- 意义
-
- 1.3 fork的常规用法
- 1.4 fork调用失败的原因
- 2. 进程终止
-
- 2.1 进程退出的情况
- 2.2 进程退出的方法
-
- return语句退出
- exit函数退出
- _exit函数退出
- 三者的区别
- 三者的联系
- 3. 进程等待
-
- 3.1 原因
- 3.2 子进程status参数
- 3.3 进程等待的方法
-
- wait函数
- waitpid函数
- wait和waitpid的区别
- 阻塞等待和非阻塞等待
- 阻塞调用和非阻塞调用
- 4. 进程程序替换
-
- 4.1 替换原理
- 4.2 exec函数族
- 4.3 exec函数用例
-
- execl
- execv
- execlp
- execle
-
- 补充
- execve
- 小结
- 5. 自制简易shell
-
- 5.1 shell运行原理
- 5.2 模拟实现
-
- 打印提示信息
- 获取键入的信息
- 解析命令
- 创建子进程
- 替换子进程(子进程)
- 等待子进程退出(父进程)
- 5.3 测试及补充
- 5.4 小结
1. 创建进程
1.1 认识fork
在进程概念中已经说明fork函数的用法:在已有的进程中使用fork函数,会创建一个子进程,而父进程就是原进程。
fork函数的位置就是一个分界点,fork之前的代码由父进程执行,之后的代码分别由父子进程执行。
实际上,这里的父子进程共享所有代码,只是fork函数在语法上限制了子进程执行的语句范围,原因是OS会将fork的位置传给子进程,让子进程从这个位置开始执行。
进程调用fork函数,当控制转移到内核中的fork代码后,内核会做以下事情:
- 分配新的内存块和内核数据结构给子进程;
- 将父进程部分数据结构内容拷贝至子进程;
- 添加子进程到系统进程列表当中;
- fork返回,开始调度器调度。
#include 运行以上代码,查看PID和PPID:

可以看到,fork之前的代码只执行了一次,fork之后的代码执行了两次。说明fork之后的代码父子进程都会执行。
fork函数的返回值
给子进程返回0;给父进程返回子进程的PID,子进程创建失败则返回-1。
为什么给子进程返回0,而对父进程返回子进程的PID呢?
首先要明确创建子进程的目的:指派任务给子进程执行。PID对于进程而言就是一个名字,标识。父进程可以有多个子进程,子进程只有一个父进程,所以父进程必须知道子进程的标识。
为什么fork有两个返回值?
fork之后的代码中,包括最后的return语句,由于fork之后的语句父子进程都要执行,return语句也不例外。
1.2 写时拷贝
在任意一方未进行写入数据的操作时,父子进程是共享代码和数据的。只要当任意一方写入数据,这时才会拷贝一份,然后修改部分代码和数据,得到属于各自的代码和数据。

为什么不在创建子进程的一开始就进行数据拷贝、修改等操作?
- 为了按需分配内存,高效地使用内存空间。子进程不一定会使用父进程的所有数据和代码,而且子进程在不写入数据的情况下,也没有必要对数据进行拷贝、修改。
意义
分离父子进程,保证其独立性。写时拷贝本质是一种延时申请的技术,提高内存使用率。
1.3 fork的常规用法
- 一个进程希望复制自己,使子进程同时执行不同的代码段。例如父进程等待客户端请求,生成子进程来处理请求;
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
1.4 fork调用失败的原因
-
系统中有太多的进程,内存空间不足,子进程创建失败;
-
实际用户的进程数超过了限制,子进程创建失败。
2. 进程终止
进程终止,本质就是OS释放系统资源,释放进程之前申请的相关内核数据结构和对于的数据和代码。
2.1 进程退出的情况
进程退出有三种情况:
-
代码执行完,结果正确;
-
代码执行完,结果不正确;
-
代码未执行完,程序崩溃。
对于前两种代码执行完的情况,OS是怎么知道结果是正确还是错误?
- 在学习C语言的初期,我们就知道main函数是程序的入口,但是我们并没有理解它。实际上,每个程序都有一个main函数。那么main函数的返回值的意义就在于此,可以让OS知道程序运行后的情况如何,以便OS调度或提醒用户。
为什么main函数的return语句总是return 0?它有什么含义吗?return 1、2、3不行吗?
- main函数的返回值是可以自己设置的,这个返回值叫做「退出码」,程序员或OS以退出码判断运行结果是否正确。return语句的意义就是返回给上一级进程,以批判该进程执行结果(可以忽略)。
- 非零值有无数个,不同的非零值就可以表示不同的错误原因。返回值(退出码)可以有不同的结果,方便定位错误原因。
使用指令echo $?查看上一个进程的退出码:

对于程序员,我们只看返回码是无法知道是什么错误的,所以每个返回码都有对应的错误表。就像ls指令打印出的错误一样(后面的选项是随便打的)。

实际上,退出码都是有映射到各种不同的字符串的,这些字符串就像上面ls的报错一样。
通过strerror函数可以获取错误码和错误信息字符串的映射关系:
#include 
可以看到,上面ls的错误就是退出码为2映射的字符串。
退出码映射的字符串都有不同的含义,帮助程序员定位执行失败的原因,这是C语言中的退出码和字符串的映射关系,映射关系是人为规定的,不同情况下会有不同的含义。
2.2 进程退出的方法
正常退出:
- main函数中的return语句;
- 在任何地方调用exit函数;
- 在任何地方调用_exit函数。
return代表函数调用结束,exit是一个接口。
异常退出:
- ctrl + c,信号终止。
return语句退出
上面演示过,return后可以自定义退出码,通过echo $?指令可以查看验证。
exit函数退出
#include 
在这段代码中,exit会在进程终止前将缓冲区中的数据刷新出来。
_exit函数退出
同样是上面的代码,将exit换成_exit,注意包含头文件
#include 
但是如果在打印语句中加上换行符呢:
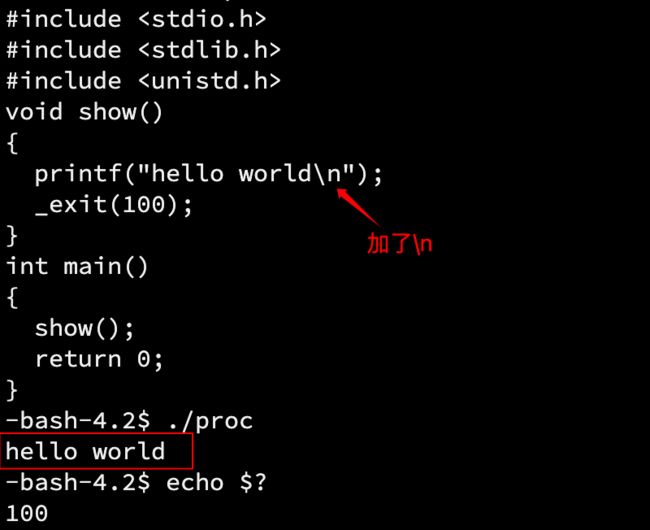
结果却可以打印,为什么?
三者的区别
- return:只有main函数中的return语句才能让进程退出,其他函数中的return语句不能;exit和_exit函数在任何地方都可以让进程退出。
- exit函数在退出进程前,会执行用户定义的清理函数,冲刷缓冲,关闭流等操作,然后才终止进程;而_exit直接终止进程,不会做任何收尾操作。
- exit是一个函数,而_exit是一个系统调用。
「系统调用」,是system calls的直译,可以简单地理解为OS提供给上层的接口,是系统级别的函数。

重新回看那个\n的问题,因为exit会冲刷缓冲,所以就算不加\n最后也会打印出来,而没有收尾操作的_exit,就没办法打印。这就说明「缓冲区」一定不在OS内部,而是C标准库为我们维护的。如果是OS维护,_exit也可以将缓冲区中的内容刷新出来。
三者的联系
事实上,main函数中的return语句会隐式地调用exit函数。
而exit函数在执行完毕收尾操作后,会调用_exit函数终止进程。
也就是说,_exit是最底层的函数,其他两个函数都是由封装而来的。
3. 进程等待
3.1 原因
进程等待是对于父进程而言的,也就是说等待的进程是子进程。
- 如果子进程退出,父进程不回收,那么子进程会变成僵尸进程;
- 僵尸进程是无法用
kill -9指令杀死的; - 父进程创建子进程,其目的是让子进程工作,如果父进程对子进程不管不顾,这就违背了创建子进程的初衷;
- 父进程需要通过进程等待,回收子进程的资源,获取子进程的退出信息。
3.2 子进程status参数
进程的status参数是一个int类型参数,但是它的不同范围的比特位储存着不同的信息(此处只研究低16位)。
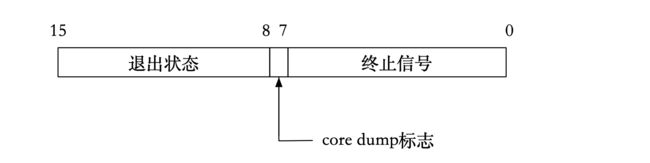
在status的低16比特位当中,高8位表示进程的退出状态,即退出码。进程若是被信号所杀,则低7位表示终止信号,第8位比特位是core dump标志。

在头文件
if (WIFEXITED(status)) {
// 正常退出:((status) & 0x7f) == 0
// 打印退出码:(status >> 8) & 0xff
printf("child return: %d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
// 异常退出:((signed char) (((status) & 0x7f) + 1) >> 1) > 0
// 打印异常信号值:(status) & 0x7f
printf("child signal: %d\n", WTERMSIG(status));
}
其中,我们需要了解两个宏:
- WIFEXITED(status):如果进程正常退出,返回的值是非零值。作用是用值的真假判断进程是否正常退出;
- WEXITSTATUS(status):如果WIFEXITED非零,得到的是进程的退出码。
这里的status参数是针对进程正常退出而言的,如果进程因为崩溃(或其他不正常的方式)退出,这里的参数也是没有意义的。对于return语句,如果进程在它之前因为崩溃而退出,那么return的退出码也就没有意义了,因为根本没有执行return语句。
程序异常退出或崩溃,本质上是OS杀掉了进程,这和语言是无关的。OS如何杀掉进程?–发送信号。
3.3 进程等待的方法
wait函数
函数声明和头文件
#include参数
指向status参数的指针,如果不需要监视,设置为NULL。
返回值
- 成功:返回进程PID;
- 失败:返回-1。
作用
等待任意子进程。
下面用fork创建一个子进程,然后让子进程工作一段时间,在这段时间中,使用wait函数让父进程等待子进程结束。子进程结束以后父进程读取子进程的信息,然后打印子进程的status参数。
#include 
在进程运行时,在另一个终端用下面的脚本监控系统进程的情况:
while :; do ps axj | head -1 && ps axj | grep proc | grep -v grep;echo "#####################";sleep 1;done

从监控结果可以看到,子进程结束以后被父进程回收,不会变成僵尸进程。
waitpid函数
函数声明和头文件
#include参数
- pid:待等待的子进程的PID。如果为-1,表示等待任意子进程;
- status:同上;
- options:
WNOHANG,如果等待的子进程未结束,则waitpid函数的返回值为0,不再等待;如果正常结束,则返回子进程的PID;WUNTRACED,如果子进程进入暂停执行情况则马上返回,但结束状态不予以理会。
options的不同选项,实际上是C语言中的宏。为什么是C语言?原因:Linux内核是由C语言写的,而wait和waitpid是系统调用,也就是内核对外开放的接口,也就是C语言函数。
宏的作用是将抽象的数据赋予意义。
返回值
- 等待成功则返回等待进程的PID;
- 如果设置了选项
WNOHANG,而调用中 waitpid函数如果判断没有已退出的子进程的信息,返回0; - 如果出错,返回-1,errno会被设置成相应的值以指示错误所在。
作用
- 等待指定PID进程或任意进程。
wait和waitpid的区别
效果不同:
wait会令调用者阻塞,直至某个子进程终止。
waitpid可以设置一个选项(options)设置为非阻塞,另外waitpid并不是等待第一个进程结束而是等待PID指定的进程。
waitpid有wait没有的三个特性:
- waitpid使我们可以等待指定的进程;
- waitpid提供了一个无阻塞的wait;
- waitpid支持工作控制。
wait和waitpid作为系统调用,它的执行者是OS,本质上就是OS帮我们拿到进程的信息(task_struct)。
父进程不等待子进程,会造成僵尸进程,这是系统层面上的内存泄漏,跟我们new或malloc出来的内存空间造成的内存泄漏是不一样的。
通过status参数,父进程可以知道子进程的状态。
阻塞等待和非阻塞等待
阻塞等待
使用wait会令调用者阻塞。被阻塞的进程对于系统而言,无非两种情况:一是等待被调度,也就是这个进程没有被CPU调度(CPU本来就很忙);二是在阻塞队列中。
非阻塞等待
父进程通过waitpid等待子进程,如果子进程没有退出,waitpid直接返回。
阻塞和唤醒
一般进程阻塞,伴随着被切换的操作,也就是如果进程不运行了,OS将它的PCB放到排队队列中,在用户层面看来,就好像卡住了一样。将PCB放到运行队列中,就是进程运行起来了。
阻塞调用和非阻塞调用
调用的主体是父进程,被调用的是wait和waitpid函数。
- 阻塞调用:父进程一直等待子进程结束;
- 非阻塞调用:父进程会每隔一段时间后查询子进程是否结束,在这些间隔内,父进程可以做自己的事情。
示例
4. 进程程序替换
4.1 替换原理
fork之后,父子进程各自执行父进程代码的一部分,这一部分对于用户而言是重复的,而创建子进程的初衷就是让它去干父进程之外的事情(这一点在接触『进程』后已经提到过不止一次)。虽然可以通过写时拷贝让父子进程拥有属于它们各自的数据,但是代码依然是共享的,也就是说,它们虽然数据不同,但是执行的任务还是一样的。
**进程程序替换就是让子进程通过特定的接口(exec函数),加载磁盘上的一个全新的程序(代码和数据),加载到调用进程的进程地址空间中。**子进程执行不同的程序,叫做替换。
当执行进程替换操作后,子进程的代码和数据被新程序的代码和数据替换,并从新程序开始执行。
子进程进行进程替换,有没有创建一个新的子进程?
- 没有。进程=内核数据结构(PCB)+代码+数据,因为内核数据结构没有发生改变,所以没有创建新的进程。
子进程进行进程替换后,会影响父进程的代码和数据吗?
- 不会。进程替换,实质上是对子进程的数据进行写入操作。一旦父子进程的任何一方发生数据写入操作,写时拷贝技术就会发挥作用,为写入数据的一方另外创建一份代码和数据。所以父子进程的代码和数据是分离的。
子进程进行程序替换后,环境变量相关数据会被替换吗?
- 不会。因为每个进程都有自己的环境变量。环境变量以进程为单位,子进程继承父进程的环境变量。关于环境变量,可以参看这篇文章:环境变量的来源、原理与应用。
4.2 exec函数族
exec函数族提供了一个在进程中启动另一个程序执行的方法。它可以根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段,在执行完之后,原调用进程的内容除了进程号外,其他全部被新的进程替换了。
头文件
#include 函数原型
int execl(const char * path,const char * arg,…);
int execle(const char * path,const char * arg,char * const envp[]);
int execlp(const char * file,const char * arg,…);
int execv(const char * path,char * const argv[]);
int execve(const char * path,char * const argv[],char * const envp[]);
int execvp(const char * file,char * const argv[]);
参数说明
- path:要执行的程序路径。可以是绝对路径或者是相对路径。在execv、execve、execl和execle这4个函数中,使用带路径名的文件名作为参数;
- file:要执行的程序名称。如果该参数中包含“/”字符,则视为路径名直接执行;否则视为单独的文件名,系统将根据PATH环境变量指定的路径顺序搜索指定的文件;
- argv:命令行参数的数组;
- envp:带有该参数的exec函数可以在调用时指定一个环境变量数组。其他不带该参数的exec函数则使用调用进程的环境变量;
- arg:程序的第0个参数,即程序名自身。相当于argv[O]。
- …:命令行参数列表。调用相应程序时有多少命令行参数,就需要有多少个输入参数项。注意:在使用此类函数时,在所有命令行参数的最后应该增加一个空的参数项(NULL),表明命令行参数结束。
这些参数类型都是字符指针类型,说明这些参数都是以字符串的形式传入的。
返回值
- 一1表明调用exec失败,无返回表明调用成功。即exec函数有返回值则表明调用程序失败。
4.3 exec函数用例
execl
int execl(const char * path,const char * arg,…);
execl中的l,可以看作list的缩写。
使用execl函数进行进程替换操作:
- 第一个参数是要替换的程序的路径,需要包括程序名。下面用常用的ls程序为例,所以先用which指令查看它所在的路径:

- 第二个参数实际上也是有顺序的:第一个参数是程序名,中间的是选项,以字符串形式传入,最后以NULL结尾。也就是在命令行是怎么写的,这里就怎么传,下面的示例也是一样的。
#include 
可以看到execl函数确实成功在这个路径下调用成功了ls程序,但是execl后面的打印语句没有执行。
原因是:一旦exec函数调用成功,即进程替换成功后,所有的数据都被替换了,包括exec前面的语句、return语句等。之所以第一个打印语句能执行,是因为它在exec函数前面。
为什么execl成功没有返回值,只有失败了才返回呢?
- 替换成功了,所有数据都被替换了。即使return返回,也没有地方可以接收,因为替换以后新进程和原来的进程两者无关。
为什么创建子进程?或者说为什么让子进程去进行进程替换操作?
- 为了不影响父进程,保证父进程工作的付利息。父进程的主要任务是读取数据、解析数据、指派进程执行代码等工作,如果替换父进程,那么就没有进程可以管理数据了。
execv
int execv(const char * path,char * const argv[]);
execv中的v,可以认为是vector,和第二个参数argv对应,表示字符串参数是存在一个数组中,以数组的形式传入的。
它和execl功能上没有什么区别,只是传参方式不同。
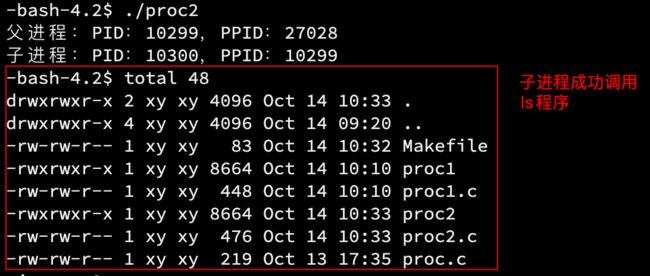
下面把参数放到数组中,然后将数组作为参数传入execv:
#include 把字符串强转为char*,只是为了取消警告(类型匹配)。
execlp
int execlp(const char * file,const char * arg,…);
结合环境变量部分,如果想要让程序直接执行而不指定它的路径,就需要将这个路径添加到环境变量PATH中。
execlp中的p和环境变量PATH对应。
- 第一个参数是要找的程序名;
- 后面的参数是命令行参数。
功能
从环境变量中查找程序,找到然后执行。
也就是说,execlp可以直接调用环境变量中的程序,而不用传入路径。
#include 
效果同上。当然,如果要用它执行自己写的程序,就要将这个程序的路径添加到环境变量PATH中。
实际上,传入的命令行参数(字符串选项),是由被调用程序中的main函数的一个参数接收的。
main函数原型
int main(int argc, char* argv[], char* envp[])
execle
int execle(const char * path,const char * arg,char * const envp[]);
execle中的e和environment variables(环境变量)对应,所以不带p的接口就要带上路径。
上面的示例都是调用系统程序比如ls,如何调用自己写的C/C++程序呢?
- 其实就是设置命令行参数之间的对应关系。
下面写一个名为mycmd的程序,然后用proc2的子进程调用它:
//mycmd
#include //proc2.c
#include 
可以看到,proc2的子进程成功调用了自己写的mycmd程序。
【注意】
-
第一个参数是被调用的程序的路径,相对路径或绝对路径都可以,但是要保证使用相对路径时被调用程序要在当前进程的路径下。
-
后面的参数是命令行参数。
上面只用了两个参数,也可以传入环境变量envp[],它是一个指针数组。
在proc2.c的main函数中定义一个指针数组作为要传入的环境变量:
#include 在mycmd.c中,增加查看环境变量的打印语句:
#include 编译运行proc2

结果表明,proc2的环境变量传给了mycmd。
补充
这就是环境变量具有全局属性,可以被子进程继承的原因。实际上,在子进程内部调用execle函数时,传入main函数接收的环境变量env就可以让子进程继承父进程的环境变量。

将mycmd.c的getenv函数的参数改成"PATH":

编译运行proc2:

这就是main函数接收的系统环境变量PATH。
execve
int execve(const char * path,char * const argv[],char * const envp[]);
这是一个系统调用,是OS提供的接口。实际上exec函数族都是用它封装的函数。原因是封装不同功能的函数以满足上层不同的需要。
小结
命名
- l(list):表示参数采用列表的形式,一一列出。
- v(vector):表示参数采用数组的形式。
- p(path):表示能自动搜索环境变量PATH,进行程序查找。
- e(env):表示可以传入自己设置的环境变量。
| 函数名 | 参数格式 | 是否带路径 | 是否使用当前环境变量 |
|---|---|---|---|
| execl | 列表 | 否 | 是 |
| execlp | 列表 | 是 | 是 |
| execle | 列表 | 否 | 否,需自己组装环境变量 |
| execv | 数组 | 否 | 是 |
| execvp | 数组 | 是 | 是 |
| execve | 数组 | 否 | 否,需自己组装环境变量 |

5. 自制简易shell
通过了解进程程序替换的原理后,介绍shell的运行原理。
5.1 shell运行原理
通过子进程执行命令,父进程完成等待子进程、解析命令等管理操作即可完成命令行解释器(shell)的工作。
外壳程序(shell)就像银行的指导人员,OS相当于银行内部,命令行解释器(shell)对用户输入到终端的命令进行解析,调用对应的执行程序。(回忆我们使用命令行输入命令时,shell做的工作)

5.2 模拟实现
-
首先要明确,shell一定是一个常驻内存的进程(不主动退出),也就是死循环。
-
打印出提示信息;
-
获取用户从键盘键入的信息(指令和选项);
-
解析命令行参数;
-
fork创建子进程;
-
TODO,内置命令;(在最后)
-
替换子进程;
-
等待子进程退出。
既然是常驻内存的进程,那么下面的操作都是在死循环内进行的。如果想退出这个自制shell,可以按ctrl+c;如果是死循环(打印),连续按几次就可以停下了。
打印提示信息
每次输入命令之前,都有这样的提示信息(具体视连接工具和平台而异):![]()
可以通过打印事先写好的字符串达到这种效果:
while(1)
{
printf("[root@localhost myshell]# ");//随便写的
}
这样符号和字符串的组合就是打印给用户看的信息。除此之外,需要注意一些细节:
-
shell并没有在打印提示信息以后换行,但是不加
\n的话,这个字符串会滞留在缓冲区中,所以打印提示信息需要搭配fflush使用,参数是stdout(标准输出),将字符串刷新到显示器上。while(1) { printf("[root@localhost myshell]# ");//随便写的 fflush(stdout); }还增加需要下面的部件,否则这只是一个死循环打印。
获取键入的信息
自己写一个缓冲区
用一个全局的数组储存命令行参数。因为我们输入命令行参数的形式是一个字符串,就像这样:"ls -a -l",所以这个字符数组存储的是字符串。为了等下方便完整且刚好地截取输入的字符串,在初始化这个数组的时候就将所有元素置为\0。
#include 写好缓冲区后,用gets函数获取输入的字符串,stdin表示从标准输入中读取数据:
if(fgets(cmd_line, sizeof(cmd_line), stdin) == NULL)
{
continue;
}
printf("echo:%s\n", cmd_line);
测试一下,输入"ls -a -l",回车:
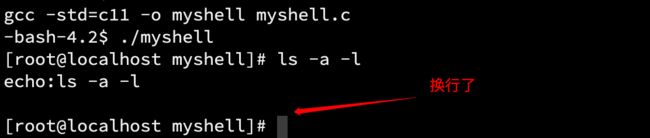
但是回显指令后,会多空一行,原因是:
注意刚刚输入一个字符串后,又按下了「回车」,这就导致缓冲区cmd_line的内容变成这样了:ls -a -l \n\0\0\0...,这就导致刚刚按下的回车输入到了缓冲区,所以要把这个\n去掉。换句话说,我们删除一个尾端的数据,通常将这个元素移除“尾端”的范围内,而\0就是字符串尾端的标志。所以我们对缓冲区读取的字符串做修改,将最后的\n置成\0。
cmd_line[strlen(cmd_line) - 1] = '\0';//除去\n
测试一下:

现在有模有样的,就差解析命令和程序替换(就是让子进程调用命令的程序)了。
解析命令
还记得上面的exec函数族吗?给它们传入的命令参数是一个数组,这个数组的元素是命令或选项,就像这样:“ls”,“-a”,“-l”。但是我们知道,输入的命令行参数是一个字符串,为了使用这个接口,我们需要将这个字符串拆分成若干个命令和选项的小字符串,并且把它们存到一个数组里面,最后传入这个数组到exec函数(至于选哪个,等下再说)中。
#define SIZE 32
#define SEP " " //定义" "为拆散字符串的分隔符
char cmd_line[NUM]; //定义缓冲区字符数组,保存输入的命令行字符串
char *g_argv[SIZE]; //保存拆散后的命令行字符串
int main()
{
while(1)
{
//...
//解析命令
g_argv[0] = strtok(cmd_line, SEP);
int index = 1;
while(g_argv[index++] = strtok(NULL, SEP));
}
return 0;
}
strtok函数是用来分解字符串的,其原型是: char *strtok(char str[], const char *delim); 其中str是要分解的字符串,delim是字符串中用来分解的字符,该函数返回分解后的字符串的起始位置指针。
【测试】用一个循环检查一下字符串是否被拆成功了(等下要删掉):
for(int i = 0; g_argv[i]; i++)
{
printf("g_argv[%d]:%s\n", i, g_argv[i]);
}

删掉它,继续。解析命令行参数的操作完成了,下面就是创建子进程和用子进程调用指定程序了。
创建子进程
用fork创建子进程已经轻车熟路:
pit_t id = fork();
if(id == 0)//子进程
{
printf("子进程开始运行:\n");
//...
exit(1);
}
else//父进程
{
//...
}
替换子进程(子进程)
这部分的操作的主体是子进程。
个人觉得这个操作叫「进程替换」有点不准确,因为它本质上是让子进程去调用、运行其他程序,「替换」体现在当子进程调用其他程序时,子进程的所有数据都会被这个新的程序代替,实行这个操作以后,才是真正地称为进程替换。
那么使用哪个exec函数来进行进程替换?
- 根据需要选择。例如我等下要用ls示例,因为ls是系统程序,它是在环境变量PATH中的,那么可以选择execvp函数,因为第一个参数是file(看最开始的参数说明),默认在环境变量PATH中搜索名为file的程序。
if(id == 0)//子进程
{
printf("子进程开始运行:\n");
execvp(g_argv[0], g_argv);
exit(1);
}
等待子进程退出(父进程)
这部分的操作的主体是父进程。
在前面「进程等待」部分提到,父进程传入一个status变量给子进程,通过这个status参数的低16比特位知晓子进程的状态。
- 成功:返回进程PID;
- 失败:返回-1或0。
else//父进程
{
printf("子进程开始运行:\n");
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)//退出成功,返回子进程pid
{
printf("退出码:%d\n", WEXITSTATUS(status));
}
}
5.3 测试及补充
测试
编译运行以下代码:
#include 
补充
但是如果试图使用cd指令回退到上级目录呢?

上面的程序对cd指令是无效的。
【原因】
首先我们要知道,可执行程序(就是编译后的文件)和进程所在的目录是不一样的,可以看这里了解。
其次我们还要知道,当该命令(cd)执行时,不会为前往另一个目录而创建一个新的进程,而是由外壳代为执行这条命令,ls等其他命令也是这种情况,这些命令叫做「内置指令」。这是因为,创建新的进程时,子进程会继承父进程创建时的目录。而如果cd命令继承了父进程的目录,则它永远也不能达到它的目标。
因为我们上面的操作对于命令行参数(我们输入的命令)而言,都是子进程执行的,子进程的几乎所有数据都会被替换,那么子进程调用cd程序,对于shell本身(父进程)是没有影响的。
【解决】
让父进程调用cd指令。
在真正的shell程序中,这些内置指令都是要由父进程执行的。
在fork后的父进程代码中,使用接口chdir,切换工作目录,切换成功就重新循环。添加下面的代码:
//4. TODO,内置指令
if(strcmp(g_argv[0], "cd") == 0)
{
if(g_argv[1] != NULL) chdir(g_argv[1]); //cd path, cd ..
continue;
}

当然可以把“子进程开始运行”和“退出码”这两个语句删掉,让它更像shell。
【优化】
可以特殊招待以下ls指令,比如像真正的shell上个色?给ls -l起个别名ll?
if(strcmp(g_argv[0], "ls") == 0)
{
g_argv[index++] = "--color=auto";
}
if(strcmp(g_argv[0], "ll") == 0)
{
g_argv[0] = "ls";
g_argv[index++] = "-l";
g_argv[index++] = "--color=auto";
}

come on,有内味了。
有一个细节,我的代码中没有过滤fork失败的判断分支,因为篇幅有限且一般情况下不会失败。
5.4 小结
运用所学的知识,通过解决各种问题,能更深层次地理解我们平常使用的指令,又理解了一点点“一切皆文件”的Linux了。感觉黑乎乎的shell也不再那么神秘,只要抽丝剥茧,高楼大厦也是砂砾筑之。
模拟实现shell的源代码在这里。