Python数据分析入门(1)——数据分析基础步骤知识
数据分析的步骤
第一步:提出问题
第二步:收集数据
第三步:数据处理和清洗
第四步:数据分析
第五步:可视化,得出结论
一、提出问题
一个数据分析的过程,其实是从数据中得到结论的过程。但分析的起点并非数据,而是问题! 先确定问题是什么,再投入精力从相关的数据中挖掘答案。
二、收集数据
通常情况下,我们想要收集数据,会有4种数据的来源:
1.观测和统计得到的数据
2.问卷和调研得到的数据
3.从数据库中获取的数据
4.从网络爬虫获取的数据
需要根据我们希望获得数据,来判断应该从哪些来源获取。
1)观测和统计数据
是指经过实地获取的实测数据。这类数据可大可小。
例如:一个商场的客流量。
这是对商场各个出入口的人员进出,按人头统计,汇总的数据,也是实地观测获得的。只是目前会有红外感应装置来获取,不需要人工来数了。
2)问卷和调研数据
是指通过抽取样本,用问卷或访谈的方式,获取的数据。 有一些需要获取到个人信息、心理感受的数据,我们需要通过询问访谈获得。
3)从数据库中获取的数据
数据库,可以简单理解为储存数据的一种结构。 我们在计算机、手机上产生的操作行为,被捕捉下来会存储到数据库中。例如:在电商平台上购买商品记录,会存储在这个电商平台的数据库中。
数据库通过一些工具和SQL语言,可以将数据查询出来,下载成Excel、csv文件,供我们使用。
从数据库中查询数据,不是这门课的重点。我们重点来解决的是:数据拿到手后,应该如何使用和分析
4)从网络爬虫获取的数据
有时,我们想要获取的数据,并不归属自己所有的数据库。
例如,想要豆瓣的电影评论。
这时就会使用网络爬虫,按照一定规则自动抓取网页信息。组织成我们需要的数据形式。
三、数据处理和清洗
在收集完问卷数据,开展进一步的分析之前。对问卷中,填写时长少于5s的问卷数据进行了剔除。因为填写时长少于5s,大概率是随意填写的,这一部分随便填写的数据,可能会干扰数据的有效性。
这是数据分析的第3步:“数据处理和清洗”。
四、数据分析
数据分析,是一个循序渐进的过程。
1)图表可视化的部分,是数据分析最前置的描述性分析。
是对得到的大量数据资料进行整理和归纳的初步分析方法。目的是找出数据的大致分布状态,进行单个因素分析。
2)探索分析
探索性数据分析,是指仅有一些非常浅的假设,通过数据分析方法,深入探索数据。
它有三大作用,包括分析现状、分析原因、预测未来。
如果缺失一些基本的数据分析思路,那么面对处理好的数据,也会不知道从何入手。
但其实,数据分析的思路非常简单。三大作用分别对应着三个基本思路:对比、细分、预测。
1、对比
数据的高低,通常需要进行比较,分析它们的差异。
对比可以非常直观地看出变化/差距,并且量化变化/差距是多少。
比如,相同方法调研了《Python办公效率化》的学员。明显对比看到,《Python数据分析》课程的学生占比相较更多一些。
2、同比和环比
同比,通常是本期数据和过往的同一期数据的对比。
例如,2020二季度GDP的同比增长,是和2019二季度GDP对比,这就是年同比。可以消除不同季度的季节因素影响。
环比,通常是本期数据和连续周期的上一期数据的对比。
例如,2020二季度全国GDP的环比增长,是和2020一季度对比,这就是环比。可以观测数据连续的变化趋势。
3、细分
在深入挖掘数据现状,和追溯内部原因的时候。需要在对比的基础上,进行细分分析。
细分,是指将数据划分成不同的部分,从而对比内部各个部分之间异同和关系的思路。
***细分分析,可以对比量的直接大小外,还可以对比内部结构。***内部结构中,某个部分的比例越大,说明其重要程度越高,影响越大。
比如:对比各课程学生/职场人的内部占比。
《办公效率化》职场人占比更大,职场人的特点会更大的影响整体。《网络爬虫》学生占比更大,学生的特点会有更大的影响。
一次探索性分析的过程,通常是从问题出发,不断细分对比,从而发现有洞见和针对性的结论。
在单一的维度上,不断向下细分,进行维度下钻。 或者,在单一的维度上,不断添加新的维度,进行维度交叉。 可以说,细分是数据分析的本源。
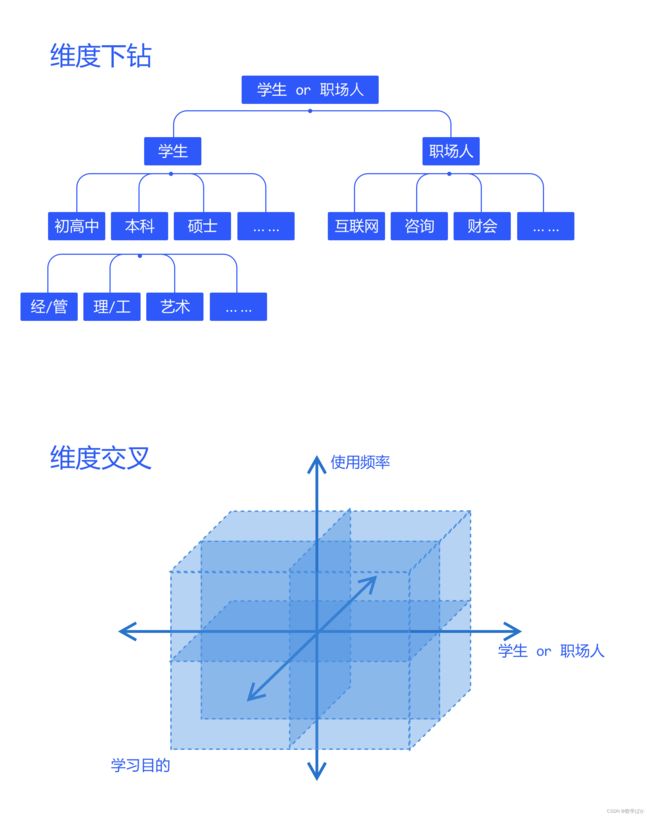
细分分析中,还有一种知名的分析方法,叫“杜邦分析法”。
杜邦分析的本质,就是将想要分析的一个指标,不断拆解为所有影响它的细分指标,分析细分指标的变动,从而挖掘目标的指标。
比如,一个电商平台的销量 = 浏览量 × 转化率,浏览量可以往下拆解,转化率也可以往下拆解。
4、yuce
数据分析中,预测未来是一个非常重要的问题。数据之间客观上存在互相影响和依存的关系。
挖掘这种数据间的关系,就可以通过一个因素的发展,从而推断另一个因素的发展,这就实现了预测。
预测,往往要通过更复杂的数学模型来实现。一般来说分为三种:
- 相关性分析
- 回归分析
- 时间序列模型
因为图像能更加凸显数据结果,所以,数据分析和可视化往往同时进行。
不同的问题,可以根据不同的图像来展现,每种图像各有各的优势。