室内设计交给AI靠谱么?emmm;Python日常任务脚本100+;数据可视化实战入门·电子书;CVPR论文扩展LaTeX模板;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
InteriorAI:拍一张照,AI 就能帮你做室内设计了
https://interiorai.com/
InteriorAI 是一个新的AI图像生成平台,基于 DALL-E 和 Midjourney 等图像生成模型,为上传的室内图像生成17种候选设计图。用户只需上传一张照片,并选择好房间用途(卧室、厨房、书房等)和装修风格(赛博朋克、波西米亚等),InteriorAI 就会自动生成设计图。
不过,使用 AI 生成的设计图看起来非常酷却存在诸多的不合理,比如整体布局或家具摆设的不协调,或者细节处的不切实际。因此,短时间内AI无法具备室内设计师必须的洞察力与沟通技巧,但仍旧可以作为预览风格或者获取灵感的一种途径。
工具&框架
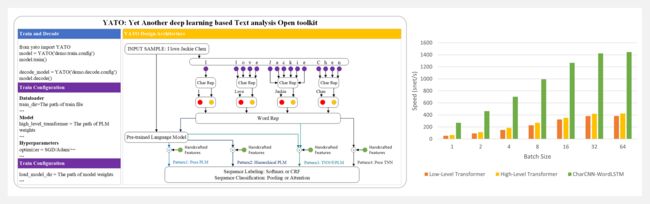
『YATO』深度学习文本分析工具包
https://github.com/jiesutd/YATO
YATO 是一个用于文本分析的开源 Python 库,专注于序列标记和序列分类任务,包括典型 NLP 任务:语音识别、词性标注、NER、CCG超标记、情感分析和句子分类。

YATO 可以通过用户友好的配置和整合 SOTA 预训练的语言模型(如BERT)来设计基于 RNN 和基于 Transformer 的特定模型。
YATO 是一个基于 PyTorch 的框架,可灵活选择输入特征和输出结构。用 YATO 设计的神经序列模型可以通过一个配置文件完全配置,不需要任何代码工作。
『Obsei』面向文本分析的低代码自动化工具
https://github.com/lalitpagaria/obsei
https://obsei.com/
Obsei是一个开源的、低代码的、由人工智能驱动的自动化工具。它可以用于各种商业流程,如社交处理、舆情监控、基于AI的警报、品牌形象分析、比较研究等。

Obsei 由 Observer、Analyzer、Informer 三个部分组成,支持多种数据库(Sqlite、Postgres、MySQL等):
① Observer:从各种来源收集非结构化数据,如 Twitter 推文、Reddit 评论、Facebook 帖子评论、App Stores 评论、Google 评论、Amazon 评论、新闻、网站等。
② Analyzer:用各种人工智能任务分析收集的非结构化数据,如分类、情感分析、翻译、PII等。
③ Informer:将分析的数据发送到各种目的地,如票务平台、数据存储、数据框架等,以便用户可以采取进一步的处理,并对数据进行分析。

『Daily Python Scripts』Python日常脚本库,用于自动化日常任务
https://github.com/metafy-social/py-scripts
Daily Python Scripts 是一个项目,包含 Python 日常脚本库,用于自动化日常任务。涉及的功能包括:天气、二维码处理、数据爬取、图片处理、音视频处理、文本处理、文件格式转换、下载等等。

『COCO Viewer』Tkinter 中的简单 COCO 对象查看器
https://github.com/trsvchn/coco-viewer
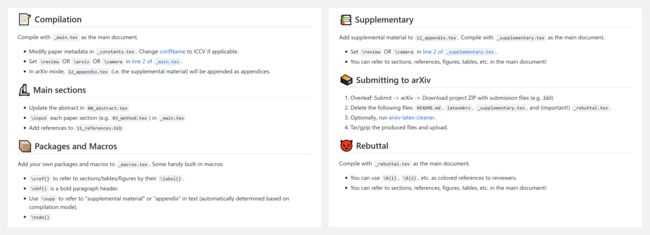
『CVPR / ICCV LaTeX Template』CVPR/ICCV论文扩展LaTeX模板
https://github.com/apoorvkh/cvpr-latex-template
这个项目包含用 LaTeX 编写 CVPR/ICCV 论文的样例模板。它是官方模板(用于CVPR 2022及以后)的一个扩展,并支持直接提交。你可以 fork 这个 repo 并导入 Overleaf 或用 pdflatex 编译。
博文&分享
『Data Visualization:A practical introduction』数据可视化实战入门(R&ggplot) · 电子书
https://socviz.co/
良好的数据可视化可以更轻松地将想法和发现传达给其他人。本书的目标就是使用 R 和 ggplot 介绍数据可视化的思想与方法。R 是一种功能强大、使用广泛且免费的数据分析编程语言;ggplot 是 R语言的开源数据可视化包。

本书通过一系列的示例讲解如何逐个构建图表——从散点图和单个变量开始,然后转向更复杂的图形。完整学习本书及示例,可以了解数据可视化背后的基本原理,了解如何使用 ggplot2 在 R 中创建各种绘图,知道如何细化绘图以进行有效演示等,主要章节包括:
- Look at data(查看数据)
- Get started(开始)
- Make a plot(制作一个图表)
- Show the right numbers(显示正确的数字)
- Graph tables, add labels, make notes(图表、添加标签、做笔记)
- Work with models(使用模型)
- Draw maps(绘制地图)
- Refine your plots(图表优化)

『Fine-tuning a BERT model with skorch and Hugging Face』用skorch和Hugging Face Transformer库实现BERT模型微调·实例教程
https://nbviewer.org/github/skorch-dev/skorch/blob/master/notebooks/Hugging_Face_Finetuning.ipynb
https://huggingface.co/docs/transformers/training
本实例遵循 Hugging Face 官方文档中的微调指南。如想了解更多关于 BERT 和微调的信息,请查看上方第二个链接。完整学习本教程,你可以收获:
- 将 Hugging Face transformers 库与 skorch 集成
- 使用 skorch 在文本分类任务上微调 BERT 模型
- 使用带有 Hugging Face 加速库的 skorch 进行自动混合精度 (AMP) 训练

数据&资源
『OpenCC』无人驾驶长尾/边角案例场景数据集
https://github.com/Charmve/OpenCC
边角案例 (Corner Case,CC) 是不经常出现或代表危急情况的数据,仅在有限范围内(如果有的话)的数据集中可用。边角案例对于机器学习很重要,是自动驾驶系统推理过程中 ML 模型训练、验证和改进性能所必需的。
CODA 数据集主要来自 KITTI、nuScenes、ONCE 等目标检测数据集,选取了1500个场景图片、包含约 6000 个目标级别的边角案例。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.10.12 『3D形状生成』 LION: Latent Point Diffusion Models for 3D Shape Generation
- 2022.10.10 『计算机视觉』NerfAcc: A General NeRF Acceleration Toolbox
- 2022.08.02 『图像生成』 Prompt-to-Prompt Image Editing with Cross Attention Control
⚡ 论文:LION: Latent Point Diffusion Models for 3D Shape Generation
论文时间:12 Oct 2022
领域任务:3D Shape Generation, Denoising, 3D形状生成
论文地址:https://arxiv.org/abs/2210.06978
代码实现:https://github.com/nv-tlabs/LION
论文作者:Xiaohui Zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, Karsten Kreis
论文简介:To advance 3D DDMs and make them useful for digital artists, we require (i) high generation quality, (ii) flexibility for manipulation and applications such as conditional synthesis and shape interpolation, and (iii) the ability to output smooth surfaces or meshes./为了推进3D DDMs并使其对数字艺术家有用,我们需要(i)高的生成质量,(ii)操作和应用的灵活性,如条件合成和形状插值,以及(iii)输出光滑表面或网格的能力。
论文摘要:扩大扩散模型(DDMs)在三维点云合成中表现出了很好的效果。为了推进3D DDMs并使其对数字艺术家有用,我们需要(i)高的生成质量,(ii)操作和应用的灵活性,如条件合成和形状插值,以及(iii)输出光滑表面或网格的能力。为此,我们介绍了用于三维形状生成的层次化的潜点扩散模型(LION)。LION被设定为一个具有分层潜望空间的变异自动编码器(VAE),它将全局形状潜望表示与点结构潜望空间结合起来。为了生成,我们在这些潜空间中训练两个分层的DDMs。与直接在点云上操作的DDM相比,分层的VAE方法提高了性能,而点结构的潜势仍然非常适合于基于DDM的建模。通过实验,LION在多个ShapeNet基准上取得了最先进的生成性能。此外,我们的VAE框架使我们能够轻松地将LION用于不同的相关任务。LION在多模态形状去噪和体素条件合成方面表现出色,而且它可以被用于文本和图像驱动的三维生成。我们还展示了形状自动编码和潜伏形状插值,并且我们用现代表面重建技术增强了LION以生成平滑的三维网格。我们希望LION因其高质量的生成、灵活性和表面重建,为艺术家处理三维形状提供一个强大的工具。项目页面和代码:https://nv-tlabs.github.io/LION
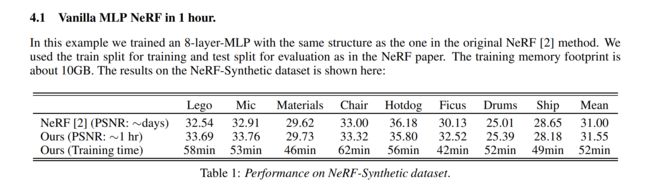
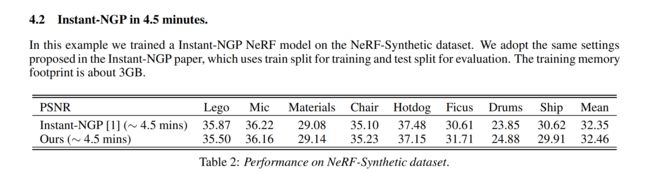
⚡ 论文:NerfAcc: A General NeRF Acceleration Toolbox
论文时间:10 Oct 2022
领域任务:Computer Vision, Pattern Recognition, 计算机视觉、模式识别
论文地址:https://arxiv.org/abs/2210.04847
代码实现:https://github.com/kair-bair/nerfacc
论文作者:RuiLong Li, Matthew Tancik, Angjoo Kanazawa
论文简介:We propose NerfAcc, a toolbox for efficient volumetric rendering of radiance fields./我们提出了NerfAcc,一个用于有效地对辐射场进行体积渲染的工具箱。
论文摘要:我们提出了NerfAcc,一个高效的辐射场体积化渲染的工具箱。我们以Instant-NGP中提出的技术为基础,并将这些技术扩展到不仅支持有界静态场景,而且支持动态场景和无界场景。NerfAcc带有一个用户友好的Python API,并且可以对大多数NeRFs进行即插即用的加速。我们提供了各种例子来展示如何使用这个工具箱。代码可以在这里找到:https://github.com/KAIR-BAIR/nerfacc。

⚡ 论文:Prompt-to-Prompt Image Editing with Cross Attention Control
论文时间:2 Aug 2022
领域任务:Image Generation, 图像生成
论文地址:https://arxiv.org/abs/2208.01626
代码实现:https://github.com/google/prompt-to-prompt
论文作者:Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, Daniel Cohen-Or
论文简介:Editing is challenging for these generative models, since an innate property of an editing technique is to preserve most of the original image, while in the text-based models, even a small modification of the text prompt often leads to a completely different outcome./对于这些生成模型来说,编辑是具有挑战性的,因为编辑技术的一个先天属性是保留大部分的原始图像,而在基于文本的模型中,即使对文本提示做一个小的修改,也会导致完全不同的结果。
论文摘要:最近大规模的文本驱动的合成模型吸引了很多人的注意,因为它们具有按照给定的文本提示生成高度多样化图像的显著能力。这种基于文本的合成方法对习惯于口头描述其意图的人类来说特别有吸引力。因此,将文本驱动的图像合成扩展到文本驱动的图像编辑是很自然的。编辑对这些生成模型来说是一个挑战,因为编辑技术的一个先天属性是保留大部分原始图像,而在基于文本的模型中,即使是对文本提示的一个小修改,也常常导致完全不同的结果。最先进的方法通过要求用户提供一个空间掩码来定位编辑,从而忽略了被掩码区域内的原始结构和内容来缓解这一问题。在本文中,我们追求一种直观的提示到提示的编辑框架,其中的编辑只由文本控制。为此,我们深入分析了一个文本条件模型,并观察到交叉注意力层是控制图像的空间布局与提示中每个词之间关系的关键。有了这个观察结果,我们提出了几个只通过编辑文字提示来监控图像合成的应用。这包括通过替换一个词来进行局部编辑,通过增加一个规范来进行全局编辑,甚至微妙地控制一个词在图像中的反映程度。我们在不同的图像和提示上展示了我们的结果,证明了高质量的合成和对编辑过的提示的忠实性。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
