基于Docker快速搭建Hadoop集群和Flink运行环境
- 前言
- 搭建集群
- 环境升级
- 配置Hadoop
- 配置Flink
- 打包镜像
- 启动集群
前言
本文主要讲,基于Docker在本地快速搭建一个Hadoop 2.7.2集群和Flink 1.11.2运行环境,用于日常Flink任务运行测试。
前任栽树,后人乘凉,我们直接用Docker Hadoop镜像kiwenlau/hadoop-cluster-docker来搭建,这个镜像内已经配置部署好了Hadoop 2.7.2,感谢前辈们造好轮子。
该Docker Hadoop镜像优点:基于Docker快速搭建多节点Hadoop集群
我们要搭建一个3节点的Hadoop集群,集群架构如下图,一个主节点hadoop-master,两个数据节点hadoop-slave1和hadoop-slave2。每个Hadoop节点运行在一个Docker容器中,容器之间互相连通,构成一个Hadoop集群。

还不熟悉Docker的可以参见:菜鸟教程-Docker教程
搭建过程部分搬运自镜像作者教程:基于Docker搭建Hadoop集群之升级版
搭建集群
1.下载Docker镜像
sudo docker pull kiwenlau/hadoop:1.0
2.下载GitHub仓库
git clone https://github.com/kiwenlau/hadoop-cluster-docker
3.创建Hadoop网络
sudo docker network create --driver=bridge hadoop
4.运行Docker容器
cd hadoop-cluster-docker
./start-container.sh
运行结果
start hadoop-master container...
start hadoop-slave1 container...
start hadoop-slave2 container...
root@hadoop-master:~#
启动了3个容器,1个master, 2个slave
运行后就进入了hadoop-master容器的/root目录,我们在目录下新建一个自己的文件夹shadow
这时候不要着急启动Hadoop集群,我们先升级一下环境配置
环境升级
1.更新包
apt-get update
apt-get install vim
2.升级JDK
将JDK 1.7升级到JDK 1.8,先去官网下载一个JDK 1.8:jdk-8u261-linux-x64.tar.gz
从本地拷贝JDK 1.8到Docker容器hadoop-master
docker cp jdk-8u261-linux-x64.tar.gz hadoop-master:/root/shadow
解压升级
tar -zxvf jdk-8u261-linux-x64.tar.gz
sudo update-alternatives --install /usr/bin/java java /root/shadow/jdk1.8.0_261/bin/java 300
sudo update-alternatives --config java
sudo update-alternatives --install /usr/bin/javac javac /root/shadow/jdk1.8.0_261/bin/javac 300
sudo update-alternatives --config javac
java -version
javac -version
卸载JDK1.7:删除JDK1.7的目录即可
3.配置环境变量
vi ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
export JAVA_HOME=/root/shadow/jdk1.8.0_261
export JAVA=/root/shadow/jdk1.8.0_261/bin/java
export PATH=$JAVA_HOME/bin:$PATH
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASS_PATH:$HADOOP_CLASSPATH
source ~/.bashrc
4.修改集群启动脚本
vi start-hadoop.sh
关闭Hadoop安全模式,末尾加上:hadoop dfsadmin -safemode leave
配置Hadoop
修改Hadoop配置,Hadoop配置路径:/usr/local/hadoop/etc/hadoop
core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop-master:9000/value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/tmpvalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/usr/local/hadoop/journalvalue>
property>
configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop-mastervalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>1024value>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>1024value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>1024value>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.nodemanager.log-aggregation.roll-monitoring-interval-secondsname>
<value>3600value>
property>
<property>
<name>yarn.nodemanager.remote-app-log-dirname>
<value>/tmp/logsvalue>
property>
configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///root/hdfs/namenodevalue>
<description>NameNode directory for namespace and transaction logs storage.description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///root/hdfs/datanodevalue>
<description>DataNode directorydescription>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.safemode.threshold.pctname>
<value>1value>
property>
<property>
<name>dfs.client.use.datanode.hostnamename>
<value>truevalue>
property>
<property>
<name>dfs.datanode.use.datanode.hostnamename>
<value>truevalue>
property>
configuration>
配置Flink
1.Flink官网下载:Flink 1.11.2
2.从本地拷贝JDK 1.8到Docker容器hadoop-master
docker cp flink-1.11.2-bin-scala_2.11.tgz hadoop-master:/root/shadow
3.修改Flink配置
tar -zxvf flink-1.11.2-bin-scala_2.11.tgz
cd flink-1.11.2/conf/
vi flink-conf.yaml
flink-conf.yaml
jobmanager.rpc.address: hadoop-master
jobmanager.memory.process.size: 1024m
taskmanager.memory.process.size: 1024m
taskmanager.numberOfTaskSlots: 2
parallelism.default: 2
打包镜像
1.将刚刚配置好的容器hadoop-master打包成新的镜像
docker commit -m="Hadoop&Flink" -a="shadow" fd5163c5baac kiwenlau/hadoop:1.1
2.删除正在运行的容器
cd hadoop-cluster-docker
./rm-container.sh
3.修改启动脚本,将镜像版本改为1.1
vi start-container.sh
start-container.sh
#!/bin/bash
# the default node number is 3
N=${1:-3}
# start hadoop master container
sudo docker rm -f hadoop-master &> /dev/null
echo "start hadoop-master container..."
sudo docker run -itd \
--net=hadoop \
-p 50070:50070 \
-p 8088:8088 \
-p 8032:8032 \
-p 9000:9000 \
--name hadoop-master \
--hostname hadoop-master \
kiwenlau/hadoop:1.1 &> /dev/null
# start hadoop slave container
i=1
while [ $i -lt $N ]
do
sudo docker rm -f hadoop-slave$i &> /dev/null
echo "start hadoop-slave$i container..."
sudo docker run -itd \
--net=hadoop \
--name hadoop-slave$i \
--hostname hadoop-slave$i \
kiwenlau/hadoop:1.1 &> /dev/null
i=$(( $i + 1 ))
done
# get into hadoop master container
sudo docker exec -it hadoop-master bash
启动集群
1.运行Docker容器
./start-container.sh
运行后就进入了hadoop-master容器的/root目录
2.启动Hadoop集群
./start-hadoop.sh
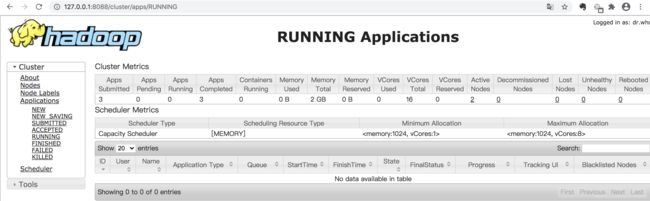
打开本机浏览器,查看已经启动的Hadoop集群:Hadoop集群
查看集群概况:集群概况
然后就可以愉快的在Docker Hadoop集群中测试Flink任务了!