Transformer万字详解
Transformer
- 一、self-attention
-
- 1.self-attention的来源
- 2.self-attention的运行原理
- 3.self-attention的实际操作流程
-
- step1:求矩阵 Q Q Q, K K K, V V V
- step2:求 α ′ \alpha^{'} α′
- step3:求 b 1 b^{1} b1, b 2 b^{2} b2, b 3 b^{3} b3, b 4 b^{4} b4
- step4:总结
- 4.muli-head self-attention
-
- (1)为什么要用mult-head
- (2)具体操作(以两头为例)
- 5.Positional Encoding(尚待研究的问题)
- 6.self-attention的应用领域
-
- (1)NLP
- (2)音频领域
- (3)图像领域
- 7.self-attention vs CNN
- 8.self-attention vs RNN
- 9.self-attention用在graph中(GNN中第一种)
- 二、Transformer
-
- 1.Transformer简介
- 2.Encoder
- 3.Decoder
-
- (1)autoregressive(AT)
- (2)Non-autoregressive(NAT)
- 4.Encoder - Decoder怎么传递信息
一、self-attention
1.self-attention的来源
现实中有很多情况需要把a set of vectors(may change length)作为输入,比如一段英文“this is a cat”,可以把其进行one-hot encoding(独热编码)也可以对其进行word embedding(给每个词一个向量,这个向量有语义的信息,比如说把word embedding画出来,可能动物分类的都在一块),再比如一段音频(25ms当做一个vector,然后每次移动10ms,再建立一个vector,直到把整段音频覆盖),再比如一张社交图(每个节点当做一个vector),再比如一个分子结构(每个节点当做一个vector)。
其输出可能有三种情况:第一种是每一个vector都有一个对应的输出,也就是说输入和输出的数量是一样的,比如说标注每个单词的词性。第二种是整个只有一个输出,比如说识别每段话是消极还是积极的,再比如说识别出来一段音频的speaker是谁。第三种是不知道要有几个输出,由计算机自己决定(seq2seq任务)。
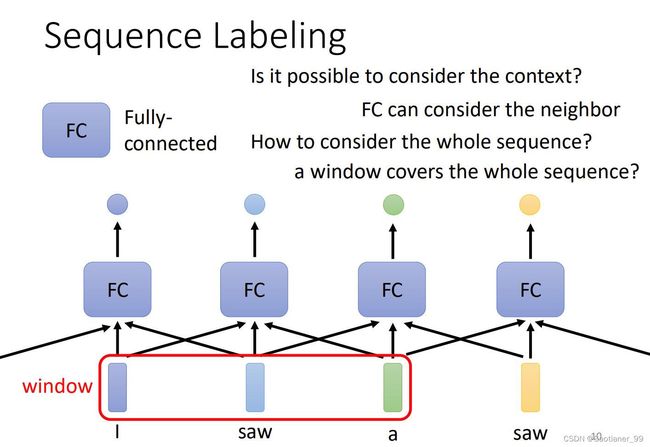
输入和输出数量一样的情况(sequence labeling): 比如说我现在要输入“I saw a saw”(我看见了一个锯子),我现在要输出每个词的词性,这是一个输入和输出数量一样的情况。平常的想法就是我直接对每个单词的vector来embedding,然后直接输入一个FC层,得到每个的输出,但是这样的问题在于,没有联系上下文,第一个saw明显是动词,第二个明显是名词。所以要考虑上下文来进行推理。所以第二种想法就是说把要识别单词前后的单词(window里面)也放进该FC层,使用上下文来得到输出,这种就可以解决上面的问题,但问题又来了,如果要有个任务不是只靠一个window就能解决,而是要靠整个sequence,那怎么办呢,这时候这样也解决不了这个问题了(因为sequence可大可小,太麻烦了),就引出了self-attention。
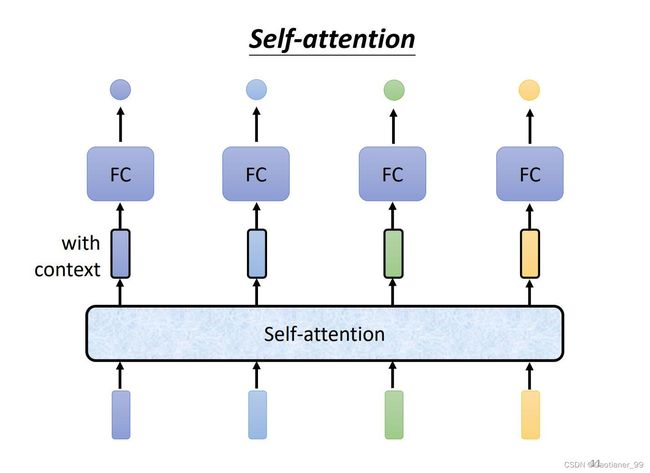
引入self-attention module,我们可以把一开始输入的vector通过self-attention module,得到新的vector,这些vector就已经包含了一整个sequence的信息,然后再把包含了一整个sequence信息的vector通过FC层,得到最后的output,这样FC层也考虑了整个sequence的信息。
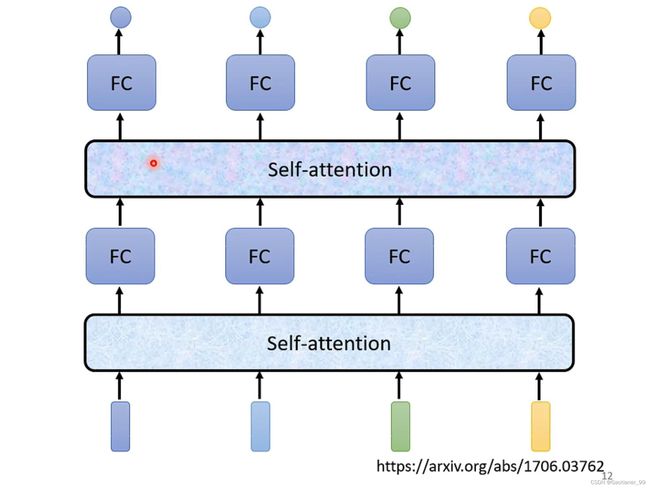
并且,self-attention module可以用多次,可以先用一个self-attention module来融合整个sequence的信息,然后通过FC专注处理某个位置的信息,然后再通过self-attention融合,再通过FC输出。
2.self-attention的运行原理
self-attention的输入是一串vector{ a 1 a^{1} a1, a 2 a^{2} a2, a 3 a^{3} a3, a 4 a^{4} a4},其可能是最原始的input,也可能是某个hidden layer的output,输出也是一串vector{ b 1 b^{1} b1, b 2 b^{2} b2, b 3 b^{3} b3, b 4 b^{4} b4},通过self-attention module之后,每个输出的vector都包括了所有输入vector的信息。
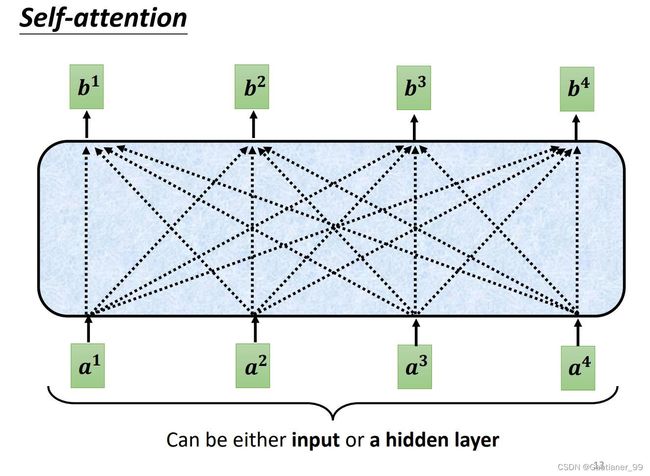
那么如何产生输出的vector呢?以 b 1 b^{1} b1 举例,第一步是根据 a 1 a^{1} a1 找出这个sequence里面跟 a 1 a^{1} a1 相关的其他vector,其他vector与 a 1 a^{1} a1 相关的强弱数值,我们用 α \alpha α 来表示。
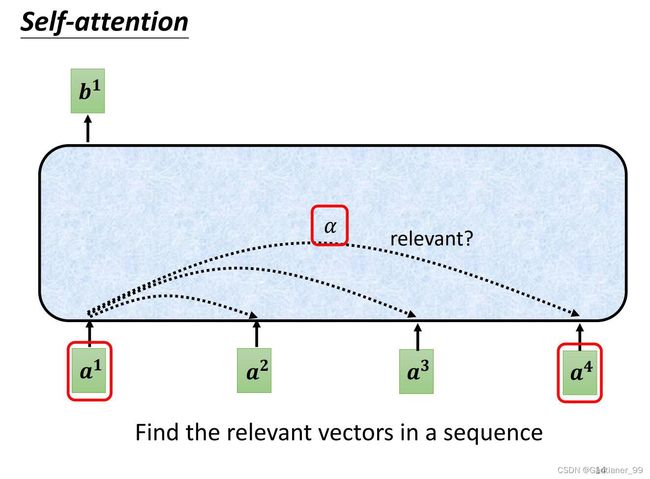
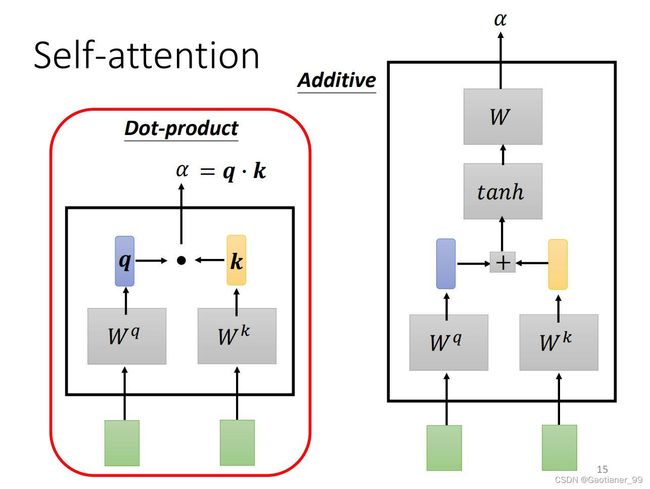
那么self-attention module怎么来决定 α \alpha α 呢?——用计算attention的模组,以 a 1 a^{1} a1 和 a 4 a^{4} a4 举例,把 a 1 a^{1} a1 和 a 4 a^{4} a4 作为输入,通过计算输出 α \alpha α 数值。计算 α \alpha α 的方法有很多种,比较常用的方法是dot-product(点积),就是说把输入的两个vector分别乘上两个不同的矩阵 W q W^{q} Wq 和 W k W^{k} Wk,得到 q 和 k 这两个vector,再把 q 和 k 做dot-product(做element-wise乘法然后再加起来)得到 α \alpha α 。另一种方式叫additive,见下图右边方式。
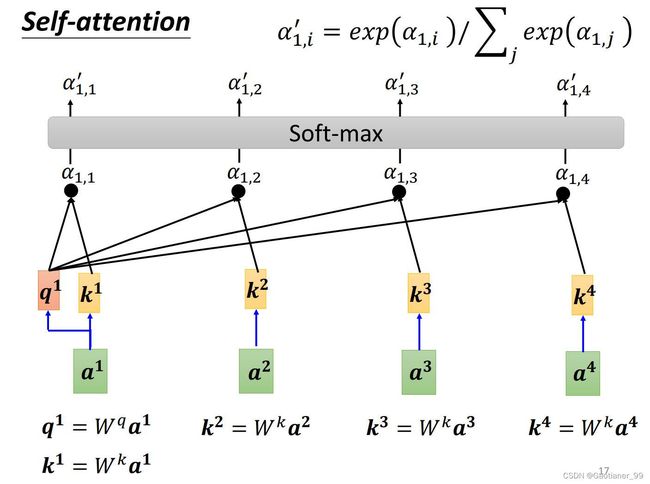
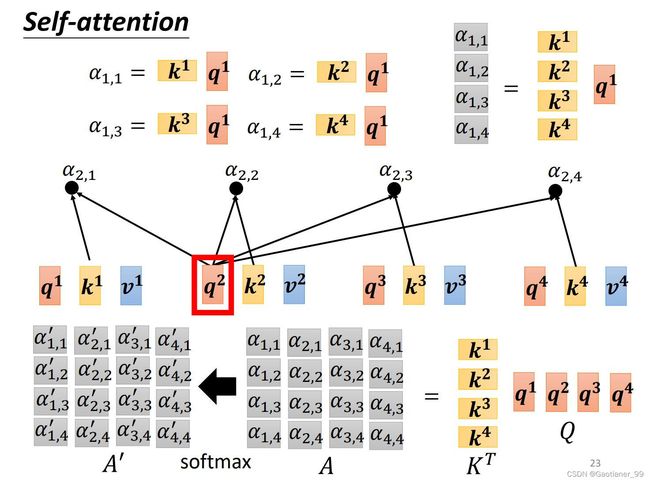
知道这个以后,那么我们就可以完成第一步,输出所有关系强弱值 α \alpha α,也叫作attention score。以 a 1 a^{1} a1 举例,就是说先用 W q W^{q} Wq 乘上 a 1 a^{1} a1 得到query q 1 q^{1} q1 ,然后用 W k W^{k} Wk 乘上 a 1 a^{1} a1, a 2 a^{2} a2, a 3 a^{3} a3, a 4 a^{4} a4 得到key k 1 k^{1} k1, k 2 k^{2} k2, k 3 k^{3} k3, k 4 k^{4} k4,用 q 1 q^{1} q1 对每个 k k k 做dot-prodcut,得到对应的attention score α 1 , 1 \alpha_{1,1} α1,1, α 1 , 2 \alpha_{1,2} α1,2, α 1 , 3 \alpha_{1,3} α1,3, α 1 , 4 \alpha_{1,4} α1,4。然后通过一个soft-max(也可以是relu等等),得到 α 1 , 1 ′ \alpha^{'}_{1,1} α1,1′, α 1 , 2 ′ \alpha^{'}_{1,2} α1,2′, α 1 , 3 ′ \alpha^{'}_{1,3} α1,3′, α 1 , 4 ′ \alpha^{'}_{1,4} α1,4′。
我们得到了 α ′ \alpha^{'} α′ 以后,就知道了每个vector a 1 a^{1} a1, a 2 a^{2} a2, a 3 a^{3} a3, a 4 a^{4} a4 对这个vector a 1 a^{1} a1 的重要程度(关系程度),然后再把每个vector a 1 a^{1} a1, a 2 a^{2} a2, a 3 a^{3} a3, a 4 a^{4} a4 乘上 W v W^{v} Wv 得到每个的value v 1 v^{1} v1, v 2 v^{2} v2, v 3 v^{3} v3, v 4 v^{4} v4。通过把对应的 α ′ \alpha^{'} α′ 与 v v v 相乘,然后加和,得到最终的 b 1 b^{1} b1。
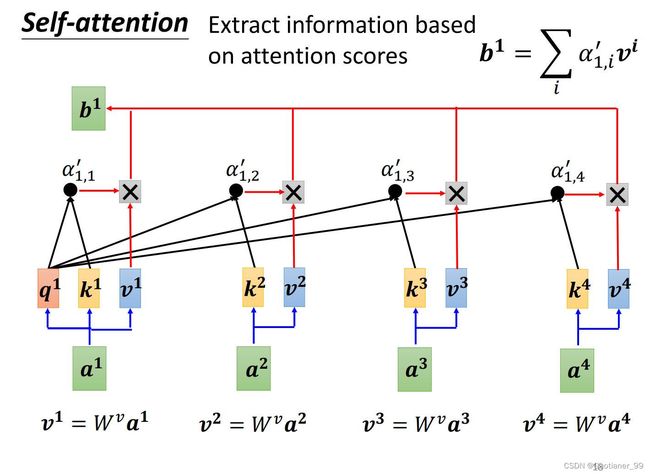
3.self-attention的实际操作流程
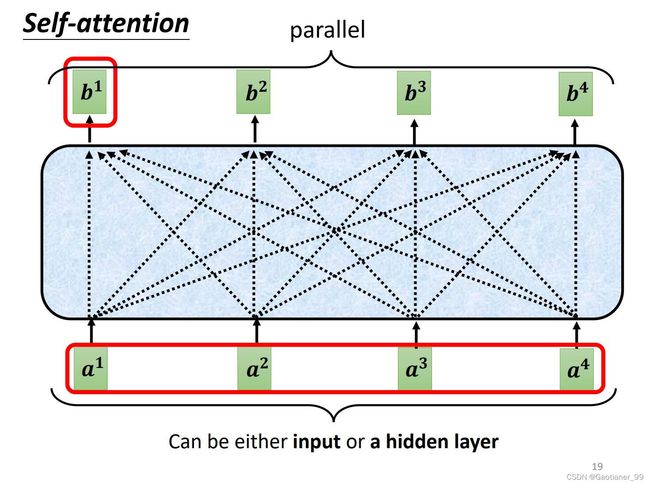
要注意的是, b 1 b^{1} b1, b 2 b^{2} b2, b 3 b^{3} b3, b 4 b^{4} b4 是一起计算产生的。
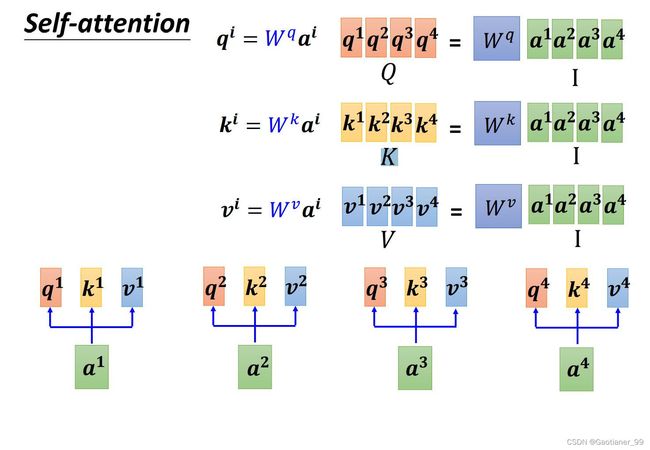
step1:求矩阵 Q Q Q, K K K, V V V
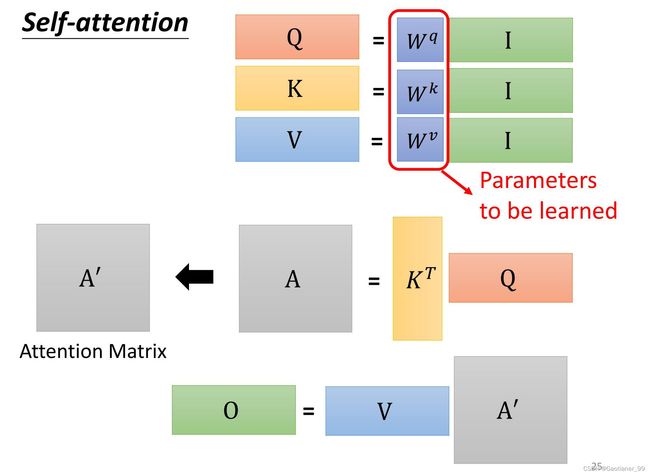
具体实现来说,因为从 α \alpha α 得到 q q q, k k k, a a a 所乘的矩阵 W q W^{q} Wq W k W^{k} Wk W v W^{v} Wv 都是相同的(网络的参数,后期学习得到),所以就可以把 α \alpha α 拼到一起,拼成一个大矩阵,一起计算。以求query举例,把 a 1 a^{1} a1, a 2 a^{2} a2, a 3 a^{3} a3, a 4 a^{4} a4 拼到一起,得到 I I I,然后 I I I 乘上矩阵 W q W^{q} Wq 得到 Q Q Q。同理得到 K K K 和 V V V 。
step2:求 α ′ \alpha^{'} α′
得到了 Q Q Q, K K K , V V V 之后,怎么得到 α ′ \alpha^{'} α′ 呢?——也是用矩阵的思想,直接把矩阵 K K K 转置后乘上矩阵 I I I ,就能得到所有 α \alpha α 的矩阵 A A A ,然后再对矩阵 A A A 做soft-max,得到 α ′ \alpha^{'} α′ 的矩阵 A ′ A^{'} A′ 。
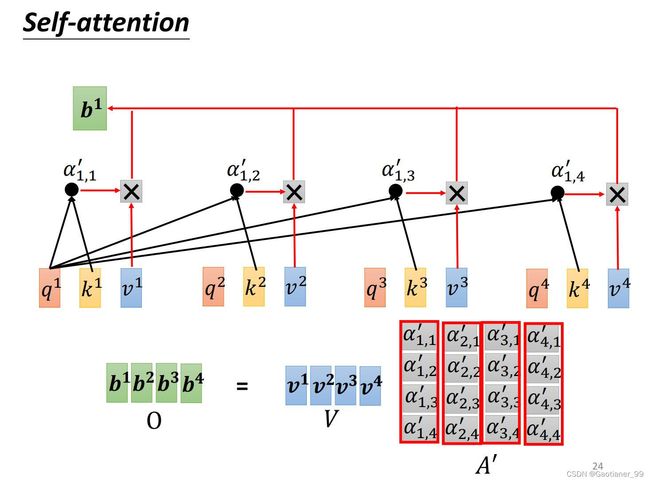
step3:求 b 1 b^{1} b1, b 2 b^{2} b2, b 3 b^{3} b3, b 4 b^{4} b4
最后要得到 b 1 b^{1} b1, b 2 b^{2} b2, b 3 b^{3} b3, b 4 b^{4} b4 ,就是直接用矩阵 V V V 乘上矩阵 A ′ A^{'} A′ 就完事儿了。
step4:总结
最后总结一下,整体步骤就是下图所示,里面唯一要学的参数就是 W q W^{q} Wq, W k W^{k} Wk, W v W^{v} Wv 。
4.muli-head self-attention
(1)为什么要用mult-head
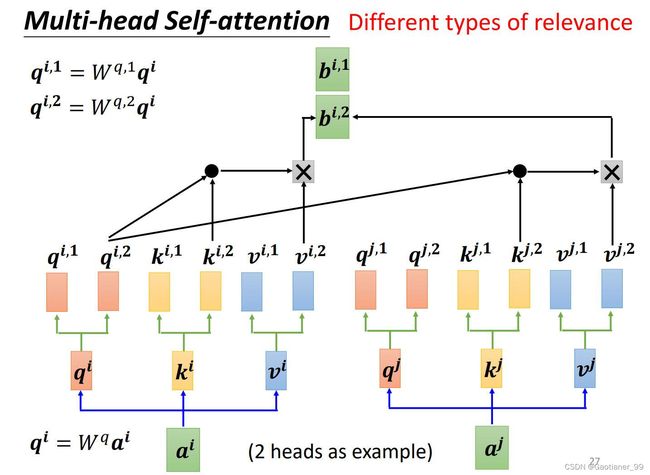
因为在找相关性的时候,可能不只有一种相关性,所以,我定义多个 q q q, k k k, v v v 来寻找不同的相关性(比如说:翻译时整个句子的语义和关键词周围的语义都很重要,这时候就用两头注意力来学习这两个方面的相关性)。
(2)具体操作(以两头为例)
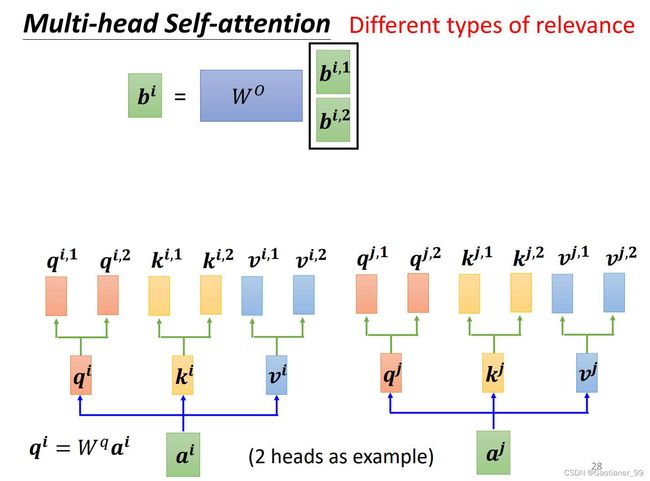
和前面的self-attention几乎一样,就是在得到 q q q , k k k, v v v 之后,根据head数目的不同,分别再乘不同的矩阵,得到 q i , 1 q^{i,1} qi,1, q i , 2 q^{i,2} qi,2; k i , 1 k^{i,1} ki,1, k i , 2 k^{i,2} ki,2; v i , 1 v^{i,1} vi,1, v i , 2 v^{i,2} vi,2。然后1的一组,2的一组,得到自己的 α \alpha α ,再然后得到 b i , 1 b^{i,1} bi,1, b i , 2 b^{i,2} bi,2。
然后再把 b i , 1 b^{i,1} bi,1, b i , 2 b^{i,2} bi,2 通过一个矩阵拼成 b i b^{i} bi 。
5.Positional Encoding(尚待研究的问题)
对于之前所说的所有,其都没有考虑位置信息,比如说到底谁是第一个,谁是第二个,它们都是一样的没有区别。但是其实位置信息也很重要,比如说对于词性标记任务来说,第一个位置大概率是名词等等。所以要把位置信息加进去。
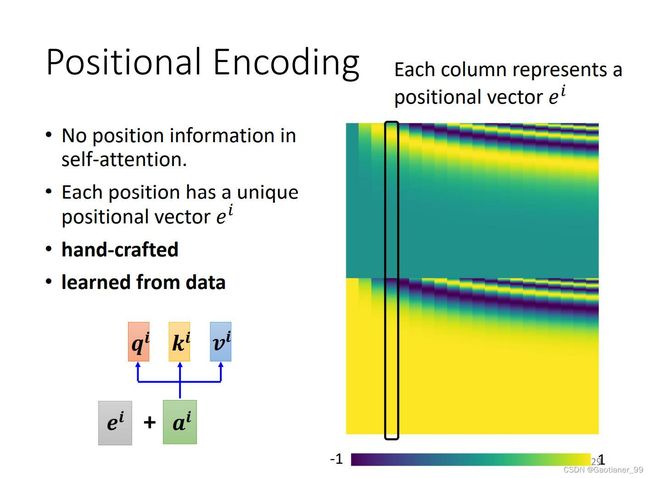
为每一个位置设置一个vctor e i e^{i} ei ,把 e i e^{i} ei 加到 a i a^{i} ai 上。最开始的 e i e^{i} ei 如下图所示,就是暴力划分(人为设置的),一列是一个。
6.self-attention的应用领域
(1)NLP
(2)音频领域
(3)图像领域
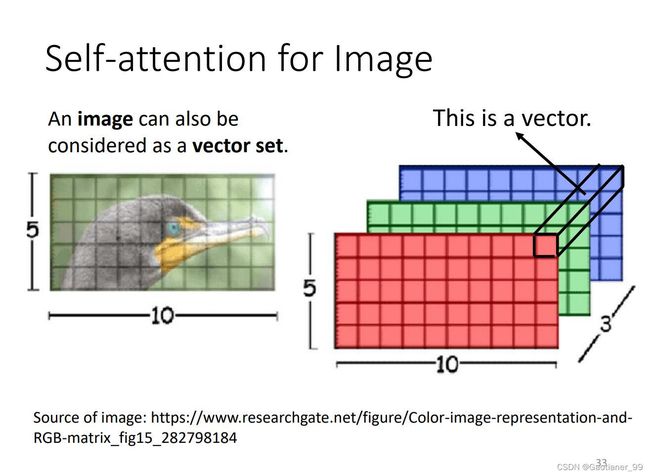
self-attention是对vector set进行操作,但是图像就是width × high,但是把图像看成 width × height × channel,把三个channel当做一个vector。
7.self-attention vs CNN
可以把CNN看做简化版的self-attention,在CNN中只考虑感受野里面的信息,而self-attention考虑的是全局的信息。也可以把self-attention看成复杂版的CNN,可以看成是感受野不是人为规定的大小了,而是自动学出来的,形状大小各异的,和该点相关的。总的来说CNN就是self-attention的一个特例。

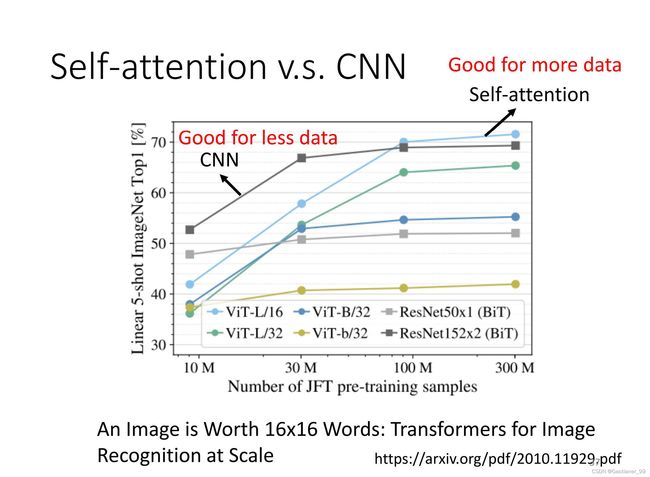
根据下图可知,在资料量小的时候CNN的表现比self-attention好,在资料量大的时候self-attention比CNN好。(可以考虑两种都用)
8.self-attention vs RNN
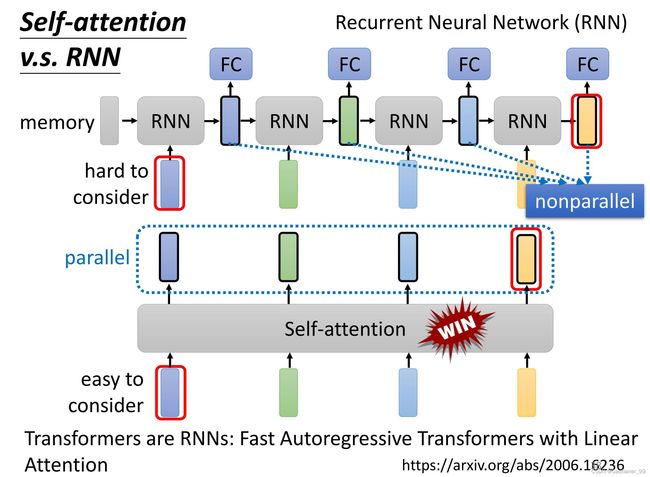
它们的输入都是一个vector sequence(vector set)。
RNN的缺点:很难学习长时的信息,不能并行学习。
self-attention:比较容易学习长时的信息,可以并行学习。
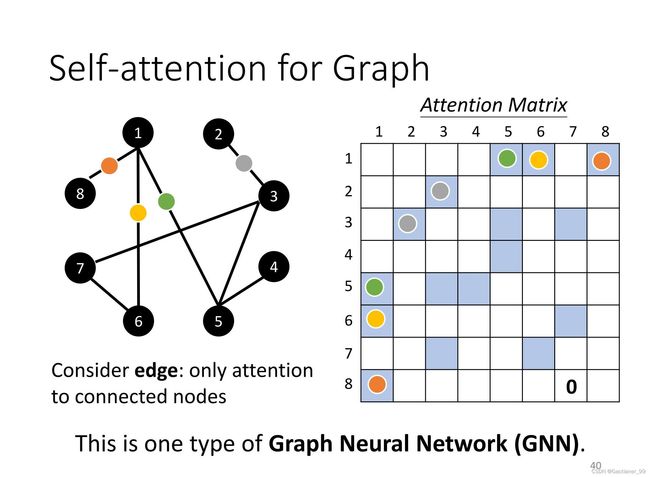
9.self-attention用在graph中(GNN中第一种)
graph有个特点就是有edge,edge就表示两两node之间的关系,所以到时候求Attention Matrix也就是上面的 α ′ \alpha^{'} α′ 矩阵的时候,只需要求有边的就可以了。
二、Transformer
1.Transformer简介
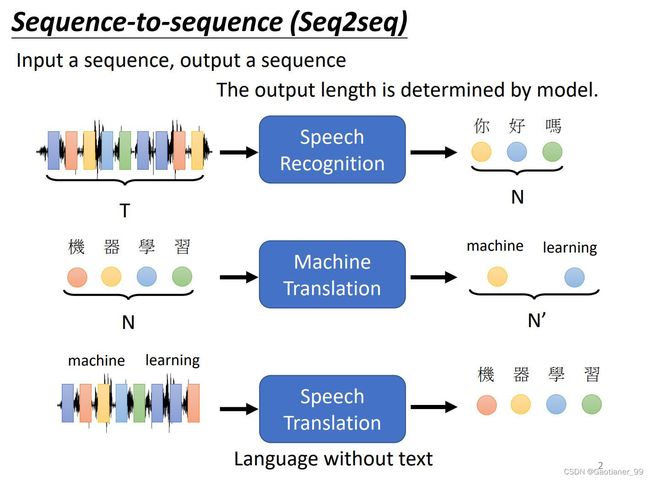
Transformer是一个seq2seq模型,input一个sequence,output一个sequence。输出的长度由模型决定。比如说语音识别、语言翻译等等。
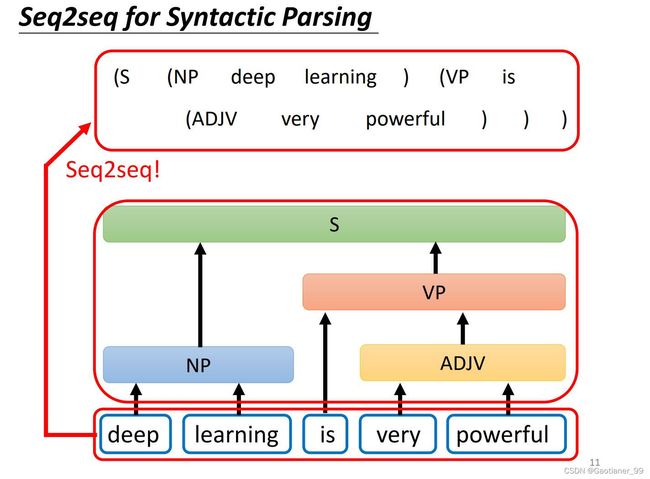
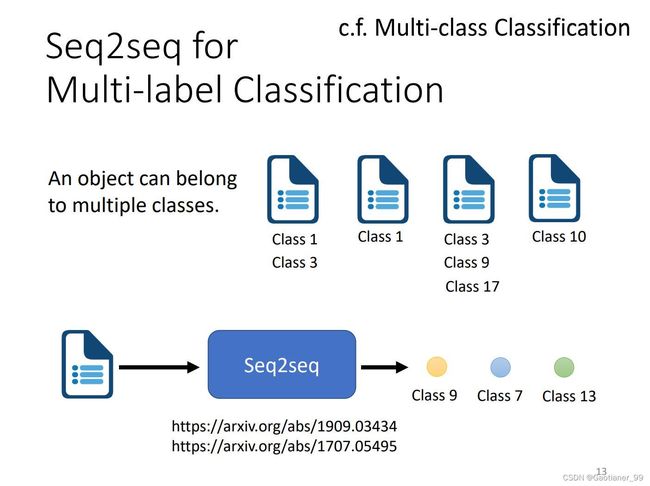
并且很多其他任务也可以看成是一个seq2seq任务,比如句子成分解析任务、多标签分类任务、目标识别任务等等。
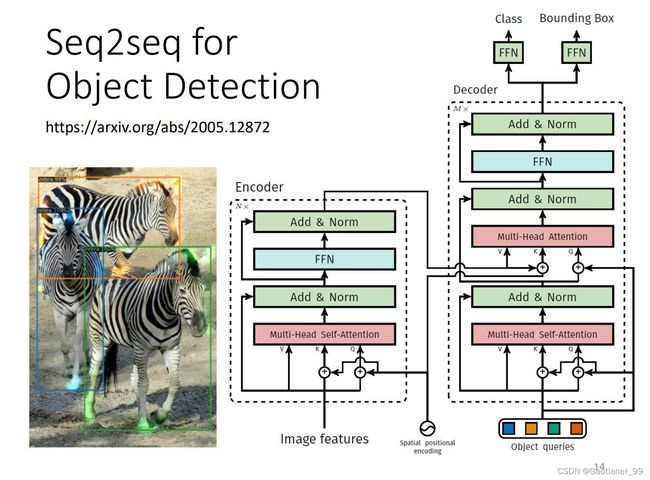
对于一般的seq2seq任务来说,分成两个大的模块,一个是Encoder,一个是Decoder。所以Transformer也分成encoder和decoder两个模块。
2.Encoder
对于一般的Encoder就是输入一系列vector,输出一系列vector,可以用RNN、CNN、self-attention等等。对于Transformer的Encoder来说就是使用了self-attention的Encoder。
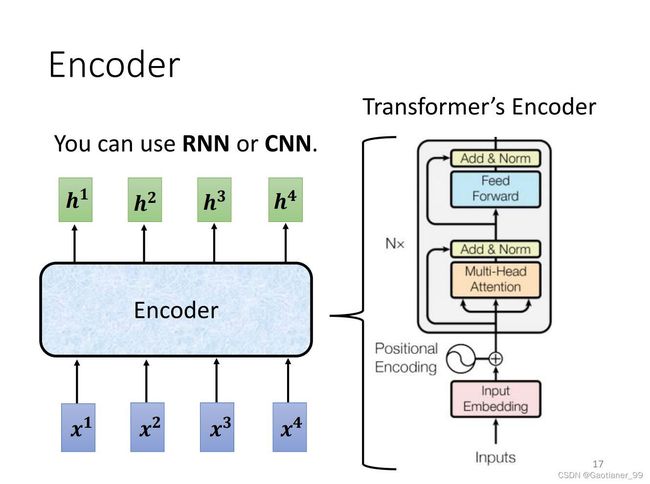
其大体结构如下图所示,encoder里面有很多block,然后每个block内部大体就和self-attention模块一样:先通过self-attention,考虑整体的信息,输出包含了全局信息的vector,然后这些vector通过一个FC层得到输出。但是实际上更为复杂。
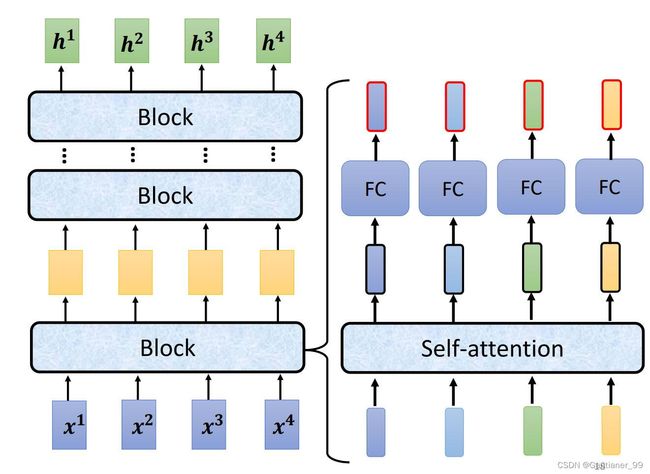
实际上,Transformer的Encoder内部的架构是如下图所示:每个vector通过self-attention模块后,还要加上自己一开始的vector(residual残差操作),得到的向量通过Layer Normalization得到输出的vector。(BN和LN的区别详细可以见这个连接),简单来说就是:Batch Normalization 的处理对象是对一批样本, Layer Normalization 的处理对象是单个样本。Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。
然后把通过LN得到的vector,通过一个FC层,并且加上自己一开始vector,得到residual的结果后,再通过一次LN,最后得到一个Encoder的输出vector。
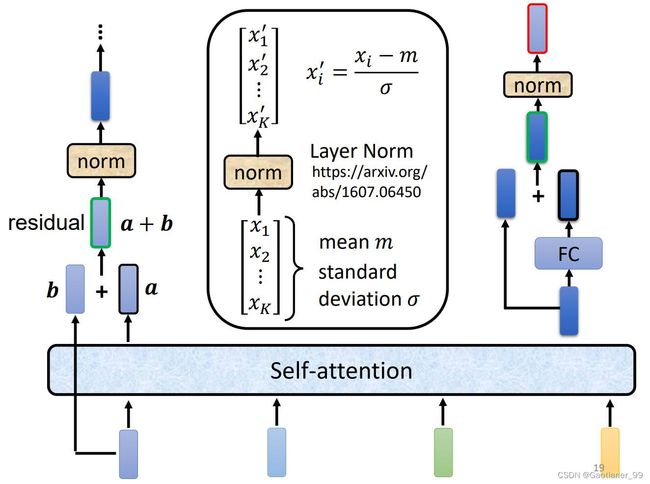
上面就是Transformer里面一个Encoder的block详细流程,一共有N个这样的block,所以循环N次。并且在一开始也要假如positional encoding。
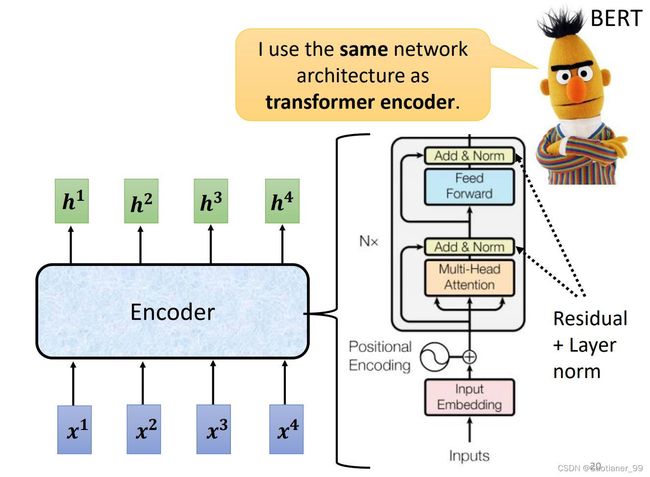
3.Decoder
(1)autoregressive(AT)
首先,先把Encoder的输出送入Decoder中,然后通过Decoder得到输出。首先,先给Decoder一个特殊的符号,代表开始(下图中的special token)。然后Decoder会输出一个向量,其长度和定义的vocabulary(与Decoder的输出文字有关)的长度一样长,然后后面还会跟每一个字的distribution(通过一个softmax之后,得到每个字的可能性)。得到这个向量以后,找到里面最大的得分的字,作为输出。
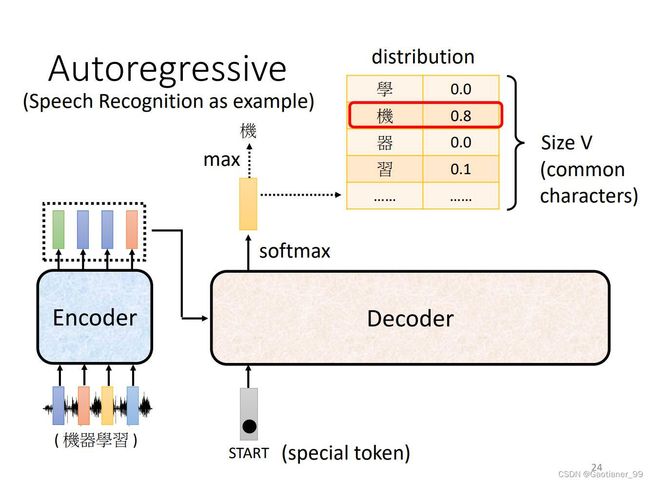
得到第一个输出以后,然后再把该输出当做Decoder的输入,现在Decoder的输入就包括了开始的特殊字符和刚才的第一个输出,再得到输出,依次往复(这样可能会有一个问题,就是一步错步步错)。
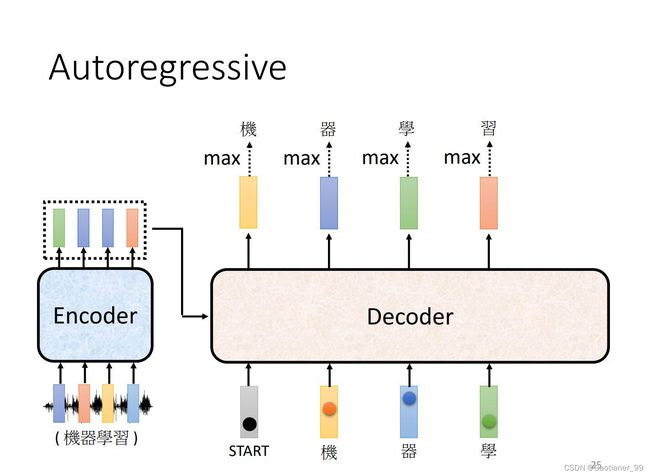
其整体架构如下图所示,其和Encoder的结构差不多,要特别注意的一个点是其第一个模块使用的是masked multi-head attention,原因在于:对于输入来说,是一次全部输入的,所以Encoder可以提取所有的vector学习。但是对于输出来说,也就是Decoder,它上一个的输出是下一个输入的一部分,也就是说它不能一下得到所有输出,所以要用masked self-attention,只能看到之前的信息。
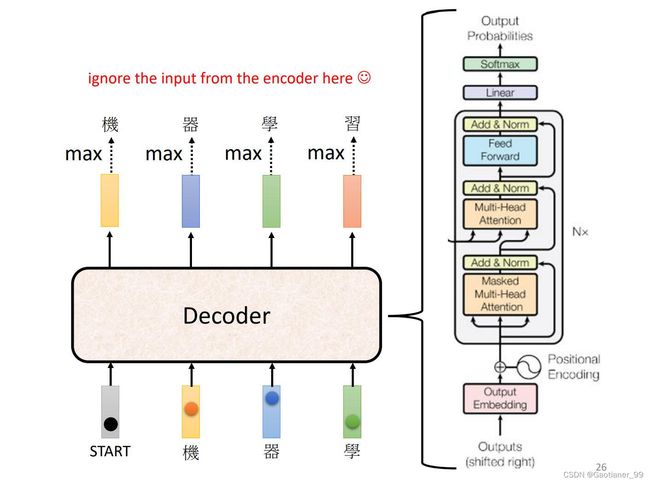
最后怎么让Decoder停止翻译呢?在一开始的vocabulary里面加入一个END特殊字符来终止。
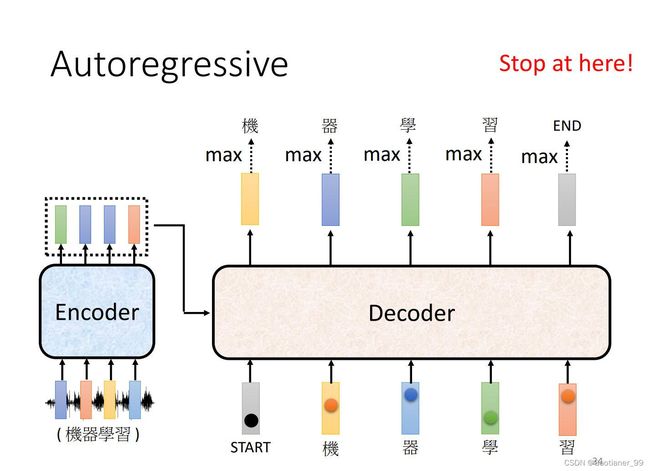
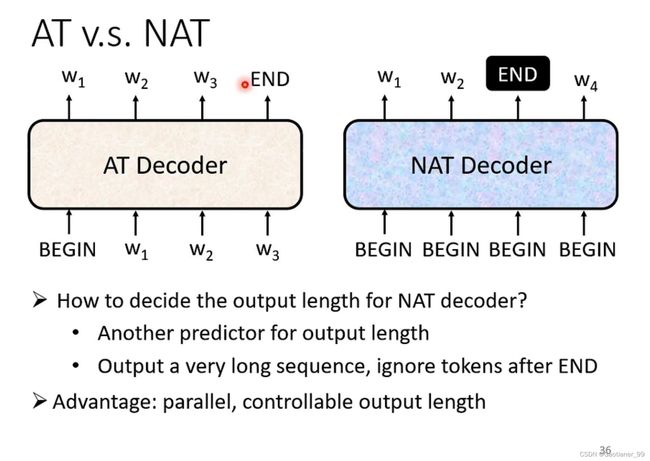
(2)Non-autoregressive(NAT)
AT的运行方式是就是上面所说的,一步一步的输出,最后结束。而NAT的运行方式一次就产生出所有的输出(一次输入一排token,一次输出一排token,结束任务)。
那怎么决定输入、输出的长度呢?
第一个方法是:再建一个模型,专门学长度。
第二个方法是:直接输入最大数值,在输出里面找到END,END右边的丢掉。
NAT相比于AT的优点就在于:它可以并行运算(更快),更好的控制输出的长度(直接通过输入的token个数控制)。
但是NAT的效果一般都比AT差。
4.Encoder - Decoder怎么传递信息
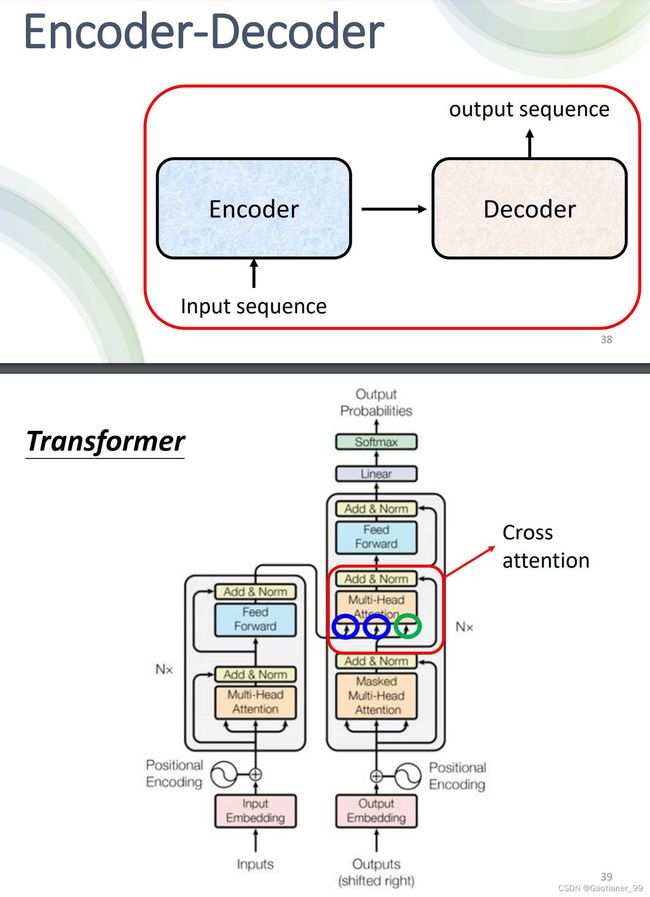
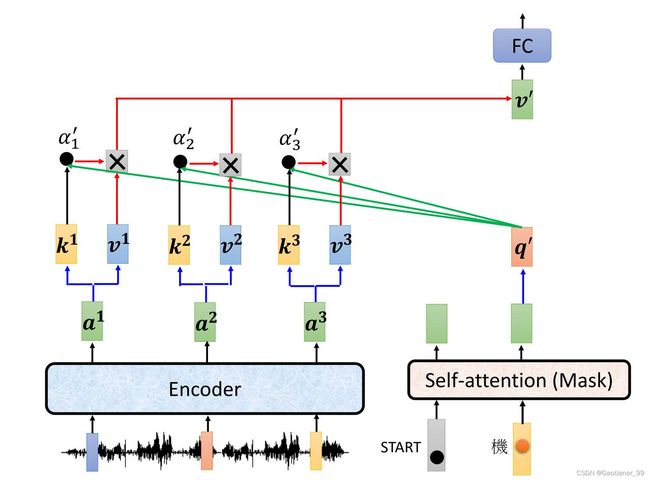
通过cross attention传递encoder和decoder的信息。具体运行流程如下图所示:首先Encoder的一些vector输入通过Encoder的模块得到输出 a 1 a^{1} a1, a 2 a^{2} a2, a 3 a^{3} a3 ,并且乘上对应的矩阵得到 k 1 k^{1} k1, k 2 k^{2} k2, k 3 k^{3} k3和 v 1 v^{1} v1, v 2 v^{2} v2, v 3 v^{3} v3 。然后Decoder方面输入开始符号,通过masked self-attention得到输出的vector,然后这个vector乘上一个矩阵,得到 q q q 。随后就是和之前的操作差不多,用Decoder的 q q q 和Encoder的 k k k, v v v 求出新的vector v v v ,然后再通过最上面的Feed Forward模块,得到对应的输出。
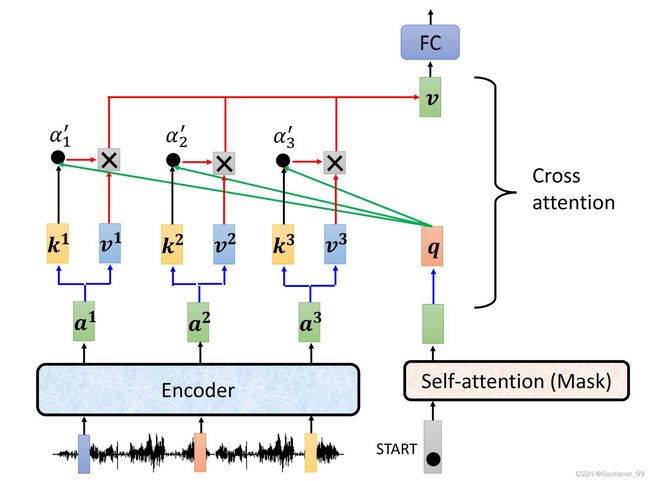
得到第一个vector之后,再走一遍这个流程(这个时候masked self-attention就彻底能用上了,因为它就是这样只能考虑之前的输入和输出,和后面没关系),依次往复。