论文阅读《Knowledge Graph Refinement: A Survey of Approaches and Evaluation Methods》
论文链接
一、谷歌的知识图谱
谷歌的知识图谱是在2012年向公众推出的,也是在这个时候,“知识图谱”这个术语被创造出来。
谷歌本身对于知识图谱的构建是相当保密的;只有少数外部来源讨论了一些基于经验的信息流向知识图谱的机制。
由此可以推测,主要的半结构化网络资源如维基百科,对知识图谱做出了贡献,以及来自谷歌的网页和内容上的结构化信息。
知识仓库是谷歌的另一个项目。它从不同来源提取知识,如文本文档、HTML表格、网络上使用微数据或微格式的结构化注释。提取的事实使用的置信度值以及语句的先验概率进行组合,这些先验概率是使用Freebase知识图谱计算的。从这些组件中,计算出每个事实的置信度值,只有置信高的事实才会被纳入知识库。
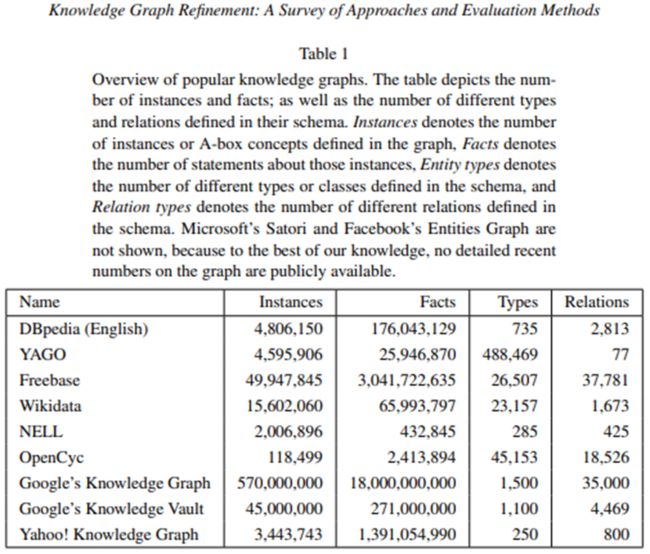 各大公司图谱中本体和图谱的情况
各大公司图谱中本体和图谱的情况
二、知识图谱的细化概览
知识图谱构建:从无到有。
知识图谱细化:已经有了一 个知识图谱,对其进行改进, 如提高完整性(补全)或提高正确率(质检)。

知识图谱细化的三个维度(可以是正交的关系)
①目标:图谱补全和图谱纠正。
②对象:实体类型、实体间的关系、实体的属性值
③数据:内部方法仅使用图谱自身数据、外部方法使用图谱数据和进一步的外部来源数据(也包括众包)
三、知识图谱细化的评价方法
知识图谱细化评价方法的分类:
gold-standard:
①对于一个子图手动标记正例/负例。
②使用外部知识图谱/数据库作为评价标准。
silver-standard:
假设给定的知识图谱已经具有合理的质量,将给定知识图谱作为测试数据集。不适合用于错误检测。
回顾性评价
自动细化方法会导致大量的发现,例如,包含成千上万个可能是错误的结果的列表。
在评估错误检测方法时,来自高质量图谱的gold-standard的错误覆盖度有限。在这些情况下,回顾性评估方法往往比gold-standard更受青睐。
回顾性评估的另一个优点是,它们允许对方法的结果进行非常详细的分析。特别是,检查一种方法所犯的错误通常会揭示出关于特定方法的优点和局限性的有价值的发现。
补全任务,经常通过召回率、准确率和f1来衡量。
纠正任务,通常通过准确率、AUC曲线来衡量。
四、知识图谱的补全方法
两种补全任务:
链接预测,预测缺失的实体、预测实体的缺失类型、实体之间的缺失关系。
三元组置信度检测,以现有图谱为参照,对待插入的三元组做质检。
内部方法
预测实体类别
在知识图谱的应用场景考虑需要单标签分类还是多标签分类,
①对于内部方法,用于分类的特征通常是连接一个实体与其他实体的关系。
②由于许多知识图谱都带有类层次结构,例如本体中的定义,因此类型预测问题也可以理解为层次分类问题。
③关联规则挖掘。④主题建模。
预测缺失的实体
表示学习方法学习了成对实体与关系到低维空间的嵌入,用于预测关系。
预测关系
①使用类似于关联规则挖掘用于发现有意义的关系链进行关系预测。
②表示学习方法学习了成对实体与关系到低维空间的嵌入,用于预测关系。
外部方法 外部方法的知识来源于文本语料库或其他知识图谱
预测实体类别
①利用维基百科页面之间的相互链接来创建特征向量, 使用k近邻分类器预测知识图谱中的类型。
预测关系
①基于命名实体识别和远程监督的关系抽取。
②使用网络搜索引擎来填补知识图谱中缺失的关系值。
③知识图谱之间的互联可以用来从另一个知识图谱中定义的信息中填补一个知识图谱中的空白。如在一个知识图谱中持有的类型可以用来预测那些应该在另一个知识图谱中持有的类型。
④利用预训练模型来补全。
五、知识图谱的错误检测方法
内部方法
检查实体类别 发现错误类型断言的方法是很罕见的
检查关系
①对于每一种类型的关系,我们计算边缘的主体和客体类型的特征分布,图中主体和客体类型强烈偏离特征分布的边被识别为潜在的错误。
②在知识图谱中利用推理进行错误检查,需要一个丰富的本体,它定义知识图谱中可能的节点和边的类型,以及对它们的限制。
查找错误文字值的方法
离群点检测或异常检测方法旨在识别数据集中偏离大多数数据的那些实例(与其他数据特征不相符),大多数情况下处理数值数据,已有研究表明,识别出的绝大多数离群点都是DBpedia中的实际错误,大多是在使用各种数字格式和测量单位解析字符串时所犯的错误。
外部方法
检查关系
将知识图谱中的语句转换为自然语言句子,并使用网络搜索引擎查找包含这些句子的网页。没有或只 有很少的网页支持相应的句子的语句被赋予较低的置信度分数。
六、总结
 知识图谱补全方法比较(第一部分)
知识图谱补全方法比较(第一部分)
 知识图谱补全方法比较(第二部分)
知识图谱补全方法比较(第二部分)
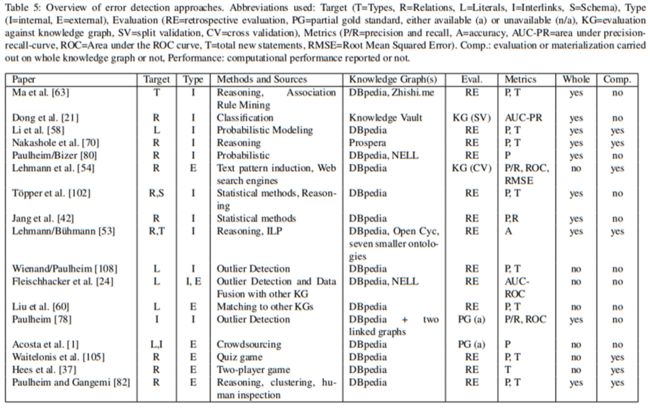 知识图谱错误检测方法比较
知识图谱错误检测方法比较
七、思考
①补全和错误检测的区分是严格的。也就是说,不存在同时完成补全和纠正的方法。但是可以共享计算。
②几乎没有任何错误检测方法也适用于纠正错误,在这里补全和错误检测方法的结合可能有很大的价值。
③错误检测方法的另一个发现是,这些方法通常会输出一个潜在错误语句的列表。来自这些错误的更高层次的模式,这些模式将暗示知识图谱构建中的设计级问题。
④考虑计算性能非常重要,很少有人去考虑计算性能。
虽然是比较老的一篇论文了,虽然技术已经进步了但图谱面临的问题改变不是很大,所以也是一篇考虑知识图谱质量的同学值得阅读的文章。