yolov5和rknn模型的问题
rknn官方目前1.7.0
对新算子的支持还没跟上, 需要将yolov5中的模型做下面的改变,
改变之后重新训练新的模型. 再去转onnx, 然后转rknn
(吐槽一下, rknn官方真是 效率太低了. 售后也很不到位, 恨不得去咬他两口.)
额, 下文其实都是抄自
https://github.com/EASY-EAI/yolov5
https://github.com/littledeep/YOLOv5-RK3399Pro
其中 YOLOv5-RK3399Pro 属于功能比较全面的项目.
建议不要使用官方的yolov5 模型, 官方的由于更新太快了, rknn的速度跟不上, 训练和转换模型是往往会出现各种各样的算子不支持的问题. 还是使用 YOLOv5-RK3399Pro 比较好.
其实下面的文章你可以不看, 去下载 https://github.com/littledeep/YOLOv5-RK3399Pro
把, 训练的时候可能会遇到点小问题,
- 记得模型转换onnx的时候要把 opset 改成 11
- 把训练的weights 参数改成 ‘’ 空字符串, 这样是全新的训练. 不用下载官方模型.
其它的我就不啰嗦了,
关于转换, 说一下我对这个库的总结.
如果yolov5 导出的onnx包含了 Detect层, 也就是最后一层, 会在onnx转rknn的时候出现各种失败. 所以一定要在导出onnx的时候把 Detect层去掉. YOLOv5-RK3399Pro的model/export.py 中 , --grid 一定要设置为False
parser.add_argument('--grid', default=False, action='store_true', help='export Detect() layer grid')
–rknn_mode 要默认True
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=r'F:\project\AI\yolov5_3399pro\best.pt', help='weights path') # from yolov5/models/
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--dynamic', action='store_true', help='dynamic ONNX axes')
parser.add_argument('--grid', default=False, action='store_true', help='export Detect() layer grid')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--rknn_mode', default=True, action='store_true', help='export rknn-friendly onnx model')
parser.add_argument('--ignore_output_permute', action='store_true', help='export model without permute layer,which can be used for rknn_yolov5_demo c++ code')
parser.add_argument('--add_image_preprocess_layer',default=False, action='store_true', help='add image preprocess layer, benefit for decreasing rknn_input_set time-cost')
opt = parser.parse_args()
在第 161行, 这里我写死了onnx 输出的3个节点, 改成了下面的3个名字. 后面转rknn的时候就定死即可.
# output_names=['classes', 'boxes'] if y is None else ['output'],
output_names=['output80x', 'output40x','output20x'],
onnx 转rknn 我用了我自己的代码. 比较简洁. 易懂.
onnx2rknn.py
#!./bin/python3.6
# -*- coding:utf-8 -*-
from rknn.api import RKNN
INPUT_SIZE = 64
if __name__ == '__main__':
# 创建RKNN执行对象
rknn = RKNN()
# 配置模型输入,用于NPU对数据输入的预处理
# channel_mean_value='0 0 0 255',那么模型推理时,将会对RGB数据做如下转换
# (R - 0)/255, (G - 0)/255, (B - 0)/255。推理时,RKNN模型会自动做均值和归一化处理
# reorder_channel=’0 1 2’用于指定是否调整图像通道顺序,设置成0 1 2即按输入的图像通道顺序不做调整
# reorder_channel=’2 1 0’表示交换0和2通道,如果输入是RGB,将会被调整为BGR。如果是BGR将会被调整为RGB
#图像通道顺序不做调整
# rknn.config(channel_mean_value='0 0 0 255', reorder_channel='0 1 2')
# rknn.config(
# mean_values=[[123.675, 116.28, 103.53]],
# std_values=[[58.395, 58.395, 58.395]],
# reorder_channel='0 1 2')
add_perm = False # 如果设置成True,则将模型输入layout修改成NHWC
rknn.config(
batch_size=1,
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
reorder_channel='0 1 2',
force_builtin_perm=add_perm,
output_optimize=1,
target_platform='rk3399pro')
# 加载TensorFlow模型
# tf_pb='digital_gesture.pb'指定待转换的TensorFlow模型
# inputs指定模型中的输入节点
# outputs指定模型中输出节点
# input_size_list指定模型输入的大小
print('--> Loading model')
# rknn.load_tensorflow(tf_pb='digital_gesture.pb',
# inputs=['input_x'],
# outputs=['probability'],
# input_size_list=[[INPUT_SIZE, INPUT_SIZE, 3]])
# rknn.load_onnx("/home/roota/Desktop/AI/rknntools/yolov5s.onnx")
# print('done')
ret = rknn.load_onnx( model='best.onnx' ,
inputs=['images'],
outputs=['output80x', 'output40x','output20x'],
input_size_list=[[3,640,640]],)
if ret != 0:
print('Load onnx failed!')
exit(ret)
print('done')
# 创建解析pb模型
# do_quantization=False指定不进行量化
# 量化会减小模型的体积和提升运算速度,但是会有精度的丢失
print('--> Building model')
rknn.build(do_quantization=True)
print('done')
# 导出保存rknn模型文件
ret = rknn.export_rknn('./best.rknn')
if ret != 0:
print('Export rknn failed!')
exit(ret)
else:
print('Export rknn success!')
# Release RKNN Context
rknn.release()
识别用的代码用的是. YOLOv5-RK3399Pro 中的
rknn_detect\rknn_detect_for_yolov5_original.py
代码我就不贴了.
整体能跑通显示图片了, 等我训练出一个合适的模型再继续测试.
下面的你可以不看.直接用上面的库就能正常训练和转换
下面的你可以不看.直接用上面的库就能正常训练和转换
下面的你可以不看.直接用上面的库就能正常训练和转换
下面的你可以不看.直接用上面的库就能正常训练和转换
下面的你可以不看.直接用上面的库就能正常训练和转换
改变如下:
- 将Focus层改成Conv层
- 将Swish激活函数改成Relu激活函数
- 将大kernel_size的MaxPooling改成3x3 MaxPooling Stack结构
第一个 将Focus层改成Conv层, 参考自 @Shmily丶
将 common.py 的
# 将Focus层改成Conv层
# class Focus(nn.Module):
# # Focus wh information into c-space
# def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
# super().__init__()
# self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# # self.contract = Contract(gain=2)
# def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
# return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# # return self.conv(self.contract(x))
# 改成下面的
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(x)
# return self.conv(self.contract(x))
将Swish激活函数改成Relu激活函数
这个比较简单, 因为Swish激活函数是最新出的算法, 所以rknn还没来得及支持.
改变 方法也很简单 目前版本V6.0 只需要改两个地方.
将 common.py 的
# 所有的nn.SiLU() 改成 nn.ReLu 就可以了.
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# 改成
self.act = nn.ReLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
将export.py中
m.act = SiLU()
# 改成
m.act = nn.ReLU()
第三个,将大kernel_size的MaxPooling改成3x3 MaxPooling Stack结构
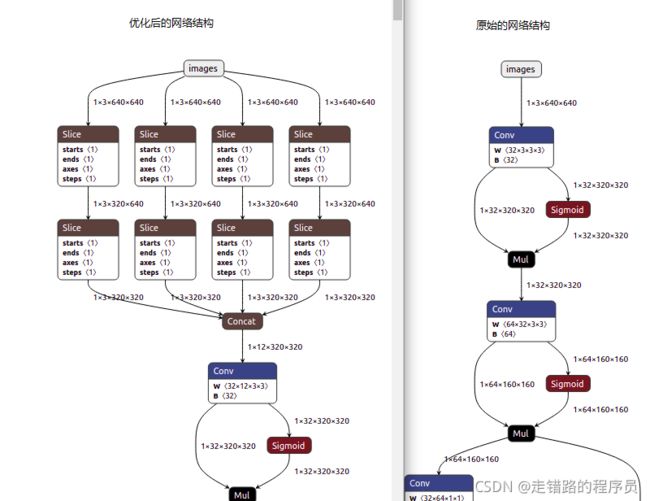
别人转换后的结构, 如上图, 但是代码还不知道怎么写…
关于yolov5 输出结果结构的后处理
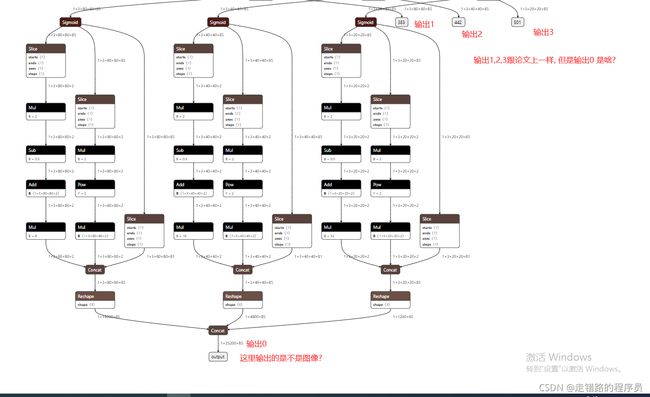
据网友说 rknn-toolkit的github issue有人问过这个问题,也有对应的答复。但是我没搜到。
这个输出0的结构是 1 * 25200 * 85
网友提示 25200=40403 + 20203 + 80803
所以 应该怎么解这个矩阵应该也是比较容易理解的了.
关于输出结构后处理可以参考文章.
https://cumtchw.blog.csdn.net/article/details/120860799
如果你的项目模型转换正常了,也不报错了, 但是识别不了.
问题可能出在 img = img[…, ::-1] 这里.
代码在下面
rknn_detect\rknn_detect_for_yolov5_original.py 文件中.
不需要拆分 start
和
不需要拆分 end
之间的注释掉.
这里是对原图片进行了,切割拆分, 重组.
def _predict(self, img_src, img, gain):
src_h, src_w = img_src.shape[:2]
# _img = cv2.cvtColor(_img, cv2.COLOR_BGR2RGB)
# 不需要拆分 start
# img = img[..., ::-1] #
# img = np.concatenate([img[::2, ::2], img[1::2, ::2], img[::2, 1::2], img[1::2, 1::2]], 2)
# 不需要拆分 end
# t0 = time.time()
pred_onx = self._rknn.inference(inputs=[img])
# print("inference time:\t", time.time() - t0)
boxes, classes, scores = [], [], []
for t in range(1,3):
input0_data = sigmoid(pred_onx[t][0]) # di yi ge cai shi kuang kuang
input0_data = np.transpose(input0_data, (1, 2, 0, 3))
grid_h, grid_w, channel_n, predict_n = input0_data.shape
参考文章:
https://github.com/rockchip-linux/rknpu/tree/master/rknn/rknn_api/examples/rknn_yolov5_demo (官方的必看)
https://github.com/rockchip-linux/rknpu
https://github.com/EASY-EAI/yolov5