Python轻松下载整理或删除微信收藏
开发者(KaiFaX)
面向全栈工程师的开发者
专注于前端、Java/Python/Go/PHP的技术社区
作者 | 小小明
来源 | xxmdmst.blog.csdn.net/article/details/119955270
玩微信很久的朋友,微信收藏中往往都积累了大量的链接,时间长了基本只能是落灰。
考虑到群友的实际需求,我们今天的实现目标是下载微信收藏的所有链接数据,并删除所有的微信收藏。
那么下面看看我如何实现通过Python来下载微信收藏的链接吧:
下载微信收藏
首先我们打开微信收藏的链接的界面并获取列表对象:
import uiautomation as auto
wechatWindow = auto.WindowControl(searchDepth=1, Name="微信", ClassName='WeChatMainWndForPC')
button = wechatWindow.ButtonControl(Name='收藏')
button.Click()
button = wechatWindow.ButtonControl(Name='链接')
button.Click()
collect = wechatWindow.ListControl(Name='收藏')
print(collect)ControlType: ListControl ClassName: AutomationId: Rect: (338,99,922,773)[584x674] Name: '收藏' Handle: 0x0(0)运行后程序会自动点击微信的收藏和链接按钮:
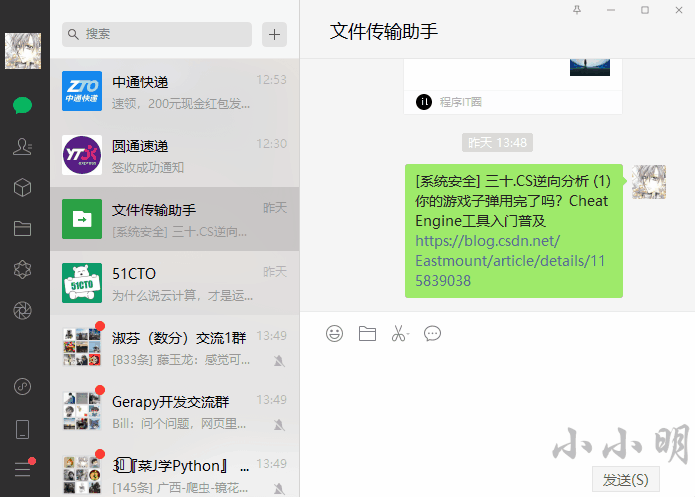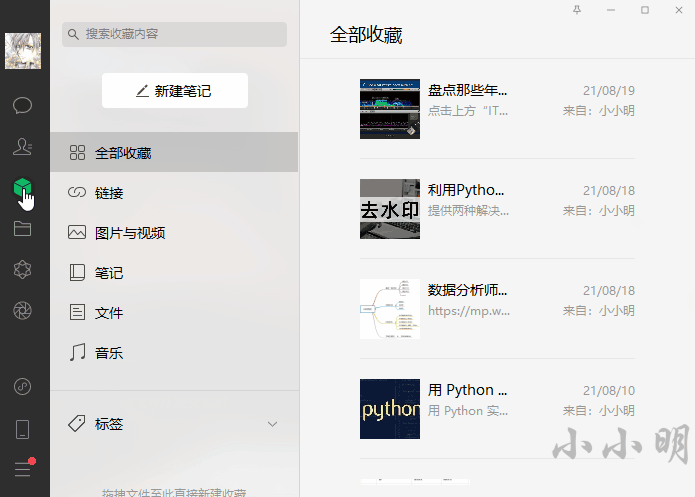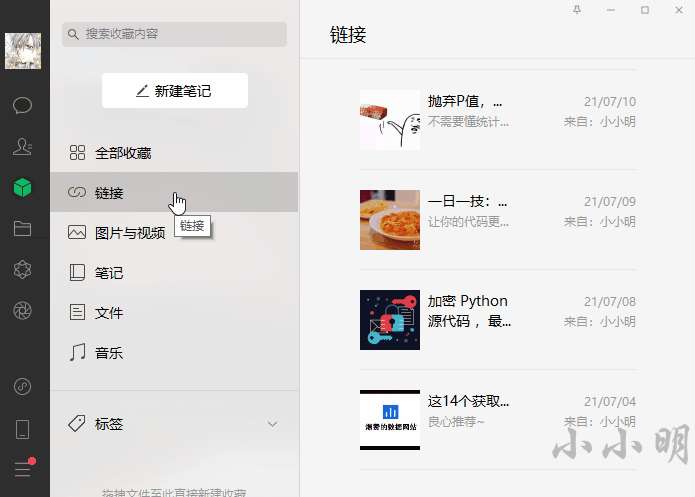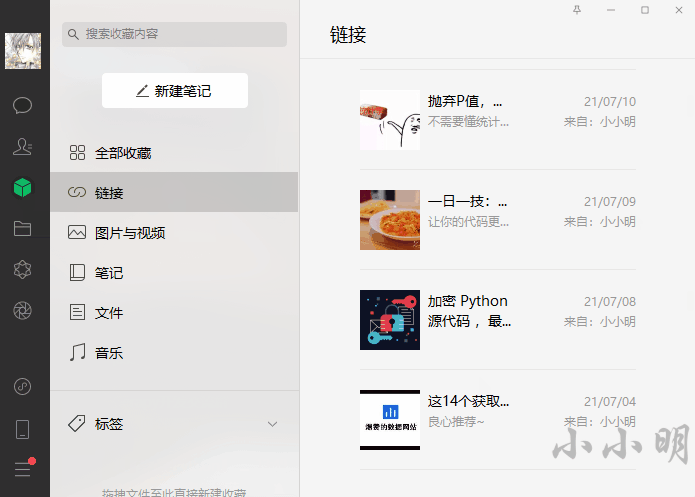
刚点开的微信收藏不能保证列表已经移动到顶部,下面我们用代码让它置顶:
def collectTOP():
last = None
# 点击列表组件左上角空白部分,激活右窗口
collect.Click(10, 10)
while 1:
item = collect.GetFirstChildControl().TextControl()
print(item.Name)
item.SendKeys("{PAGEUP 10}")
if last == item.Name:
break
last = item.Name
collectTOP()原理是激活收藏列表后,每次循环按10次向上翻页键,直到列表头部不再发生变化,从而达到滚动到顶部的效果。
其实这步人工操作也没啥。
下面我们看看如何读取各个列表项UI组件的文本数据,经过节点分析可以清晰的看到节点查找路径:
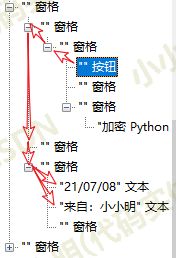
为什么我选择按钮作为起始查找点呢?因为我发现只有左侧的图标按钮才是100%有的,而左侧文本的个数却是不确定的,最终编写代码如下:
def read_collect_info(ico_tag):
# 根据按钮相对位置找到文本节点的位置
desc_tags = ico_tag.GetNextSiblingControl().GetNextSiblingControl().GetChildren()
content = "\n".join([desc_tag.Name for desc_tag in desc_tags])
time_tag, source_tag = ico_tag \
.GetParentControl().GetParentControl() \
.GetNextSiblingControl().GetNextSiblingControl() \
.GetChildren()[:2]
time, source = time_tag.Name, source_tag.Name
return content, time, source
# 每个UI列表元素内部都必定存在左侧的图标按钮
ico_tag = collect.GetFirstChildControl().ButtonControl()
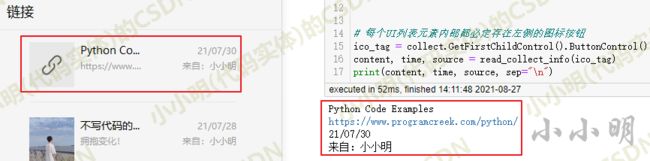
content, time, source = read_collect_info(ico_tag)
print(content, time, source, sep="\n")可以看到数据都正确的提取:
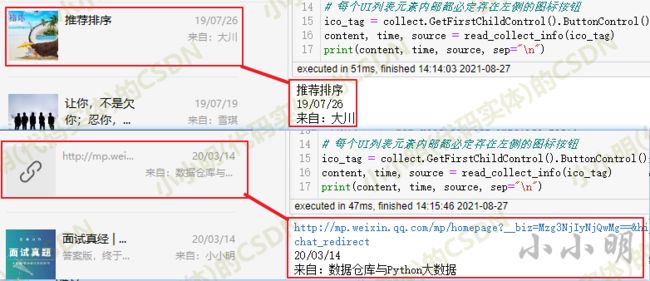
测试2类缺数据的异常节点也没有问题:
对于每条收藏的链接我们需要右键点击复制链接后,再从剪切板读取:
def get_meau_item(name):
menu = wechatWindow.MenuControl()
menu_items = menu.GetLastChildControl().GetFirstChildControl().GetChildren()
for menu_item in menu_items:
if menu_item.ControlTypeName != "MenuItemControl":
continue
if menu_item.Name == name:
return menu_item
ico_tag.RightClick()
menu_item = get_meau_item("复制地址")
menu_item.Click()
url = auto.GetClipboardText()
print(url)可以看到能够正确的提取链接:
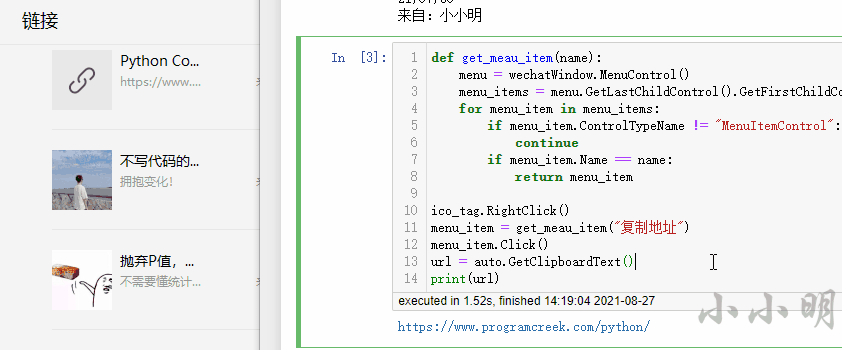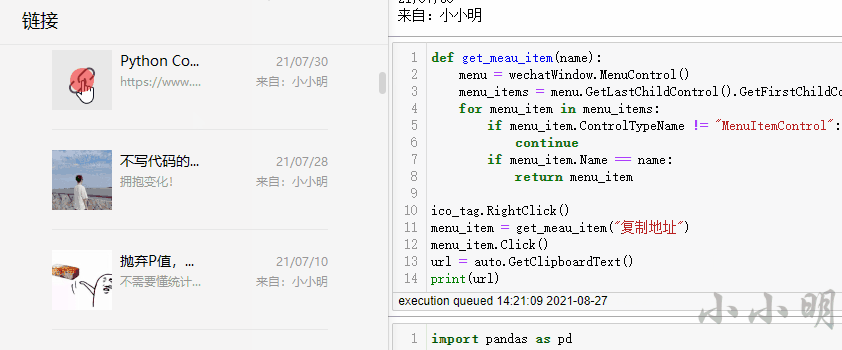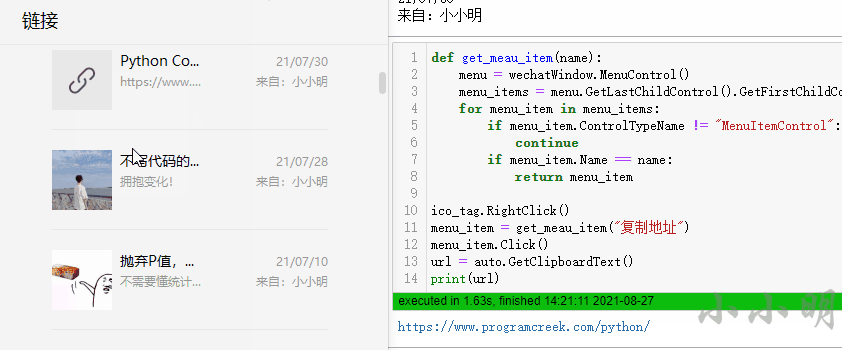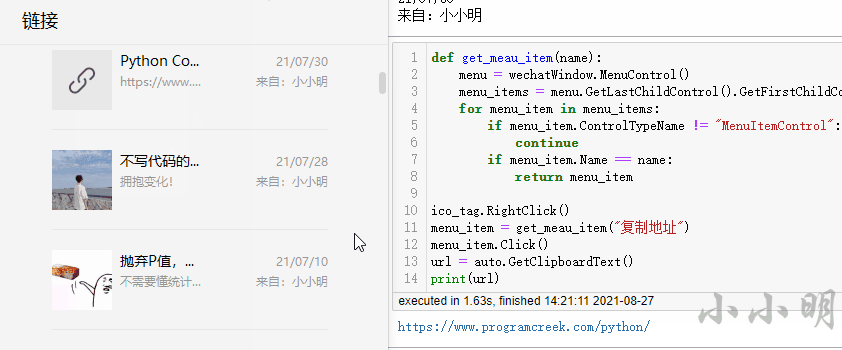
基于以上测试,最终整理修改的完整代码为:
import pandas as pd
import uiautomation as auto
def collectTOP(collect):
last = None
# 点击列表组件左上角空白部分,激活右窗口
collect.Click(10, 10)
while 1:
item = collect.GetFirstChildControl().TextControl()
print(item.Name)
item.SendKeys("{PAGEUP 10}")
if last == item.Name:
break
last = item.Name
def read_collect_info(ico_tag):
# 根据按钮相对位置找到文本节点的位置
desc_tags = ico_tag.GetNextSiblingControl().GetNextSiblingControl().GetChildren()
content = "\n".join([desc_tag.Name for desc_tag in desc_tags])
time_tag, source_tag = ico_tag \
.GetParentControl().GetParentControl() \
.GetNextSiblingControl().GetNextSiblingControl() \
.GetChildren()[:2]
time, source = time_tag.Name, source_tag.Name
return content, time, source
def get_meau_item(name):
menu = wechatWindow.MenuControl()
menu_items = menu.GetLastChildControl().GetFirstChildControl().GetChildren()
for menu_item in menu_items:
if menu_item.ControlTypeName != "MenuItemControl":
continue
if menu_item.Name == name:
return menu_item
wechatWindow = auto.WindowControl(
searchDepth=1, Name="微信", ClassName='WeChatMainWndForPC')
button = wechatWindow.ButtonControl(Name='收藏')
button.Click()
button = wechatWindow.ButtonControl(Name='链接')
button.Click()
collect = wechatWindow.ListControl(Name='收藏')
collectTOP(collect)
result = []
last = None
while 1:
page = []
text = collect.GetFirstChildControl().TextControl().Name
if text == last:
# 首元素无变化说明已经到底部
break
last = text
items = collect.GetChildren()
for i, item in enumerate(items):
# 每个UI列表元素内部都必定存在左侧的图标按钮
ico_tag = item.ButtonControl()
content, time, source = read_collect_info(ico_tag)
# 对首尾位置的节点作偏移处理
item.RightClick(y=-5 if i == 0 else 5 if i == len(items)-1 else None)
get_meau_item("复制地址").Click()
url = auto.GetClipboardText()
row = [content, time, source, url]
print("\r", row, end=" "*1000)
page.append(row)
result.extend(page)
item.SendKeys("{PAGEDOWN}")
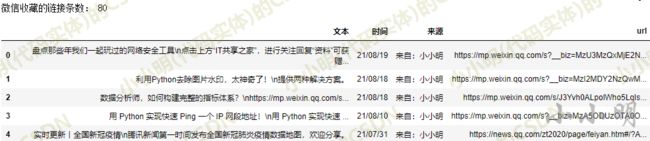
df = pd.DataFrame(result, columns=["文本", "时间", "来源", "url"])
df.drop_duplicates(inplace=True)
print("微信收藏的链接条数:",df.shape[0])
df.head()运行过程中的截图(省略中间部分):
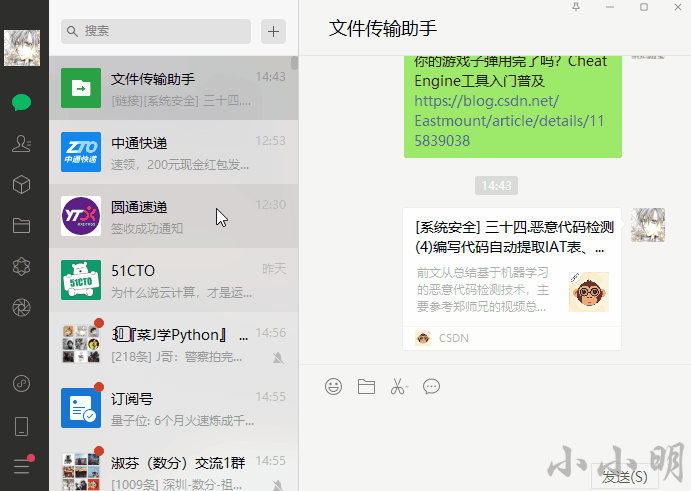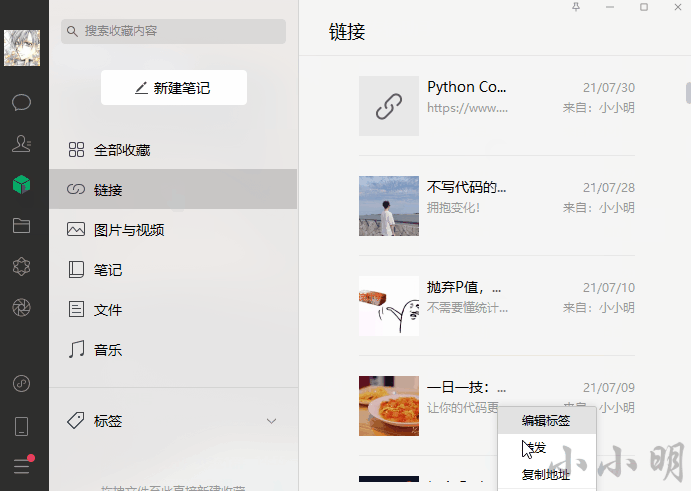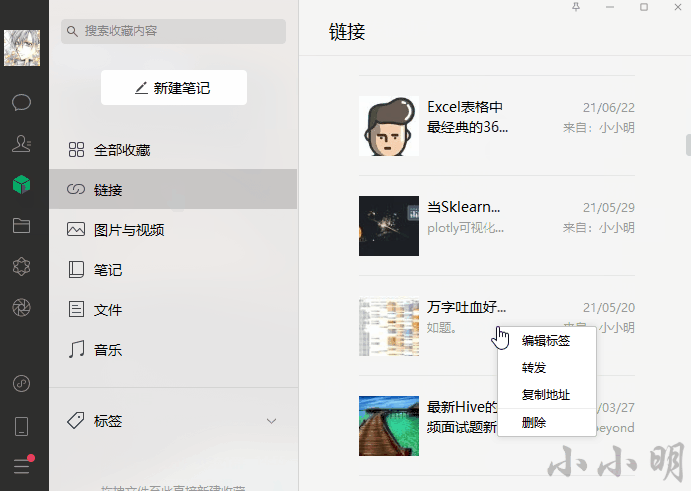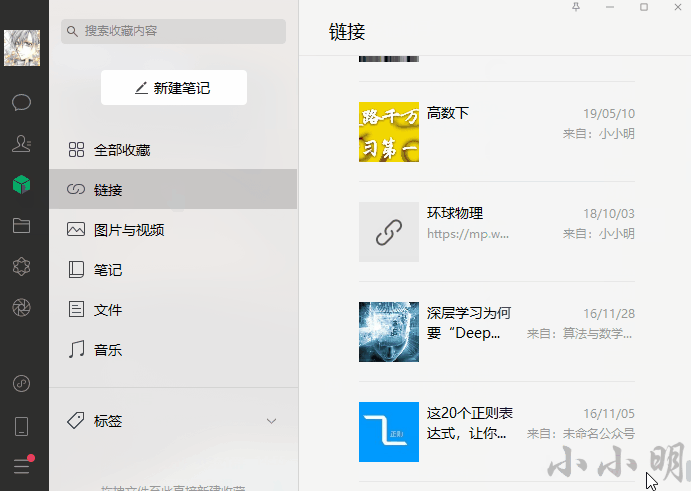
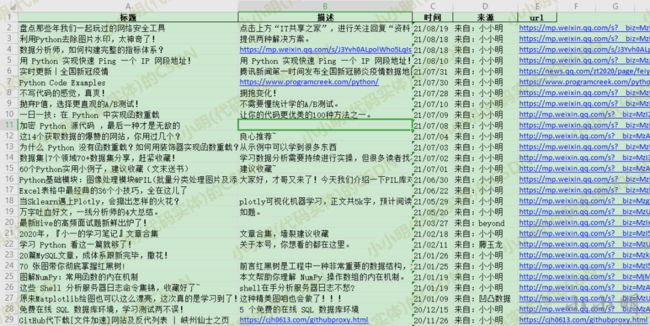
最终结果得到一个结构化表格:
于是我们可以加一行代码,将下载到的微信收藏数据保存起来:
df.to_excel("微信收藏链接.xlsx", index=False)如果需要标题和描述分列,可以作如下处理之后再保存:
df[["标题", "描述"]] = df.文本.str.split(r"\n", 1, True)
df = df[["标题", "描述", "时间", "来源", "url"]]
df.to_excel("微信收藏链接.xlsx", index=False)看到曾经收藏的链接被保存到本地真是身心愉悦:
批量删除微信收藏
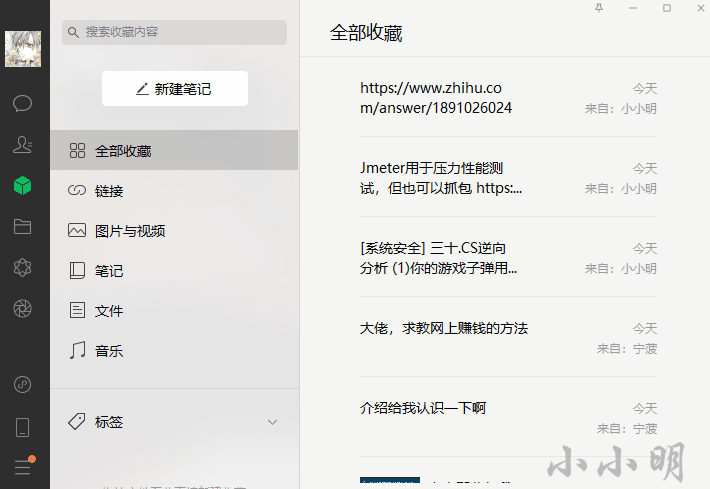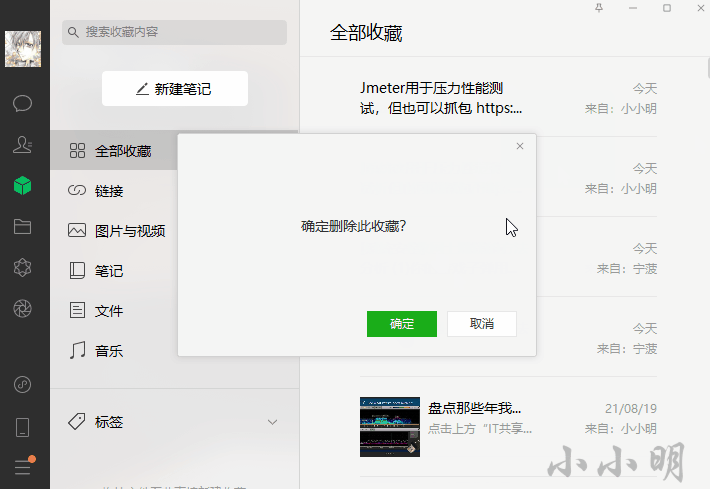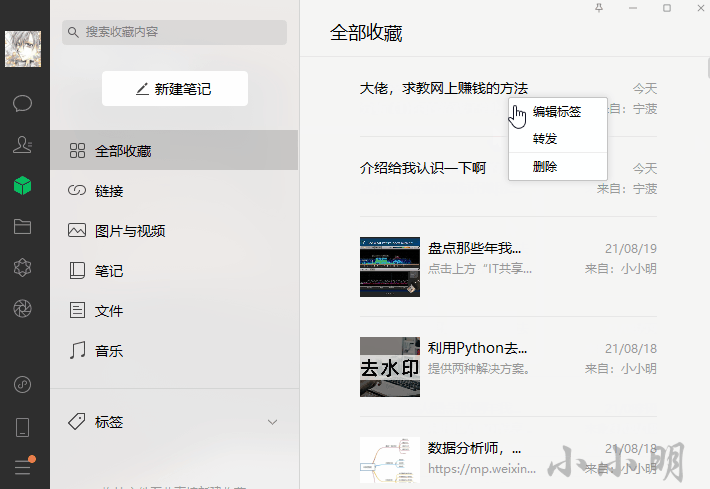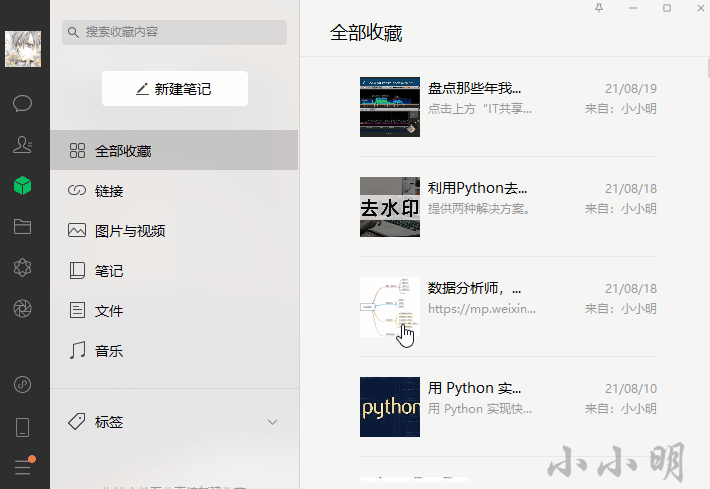
微信收藏对于我个人来说既然已经都下载下来就没有必要继续在里面落灰了,是时候批量清理一波了。
由于删除是危险操作,所以要删除哪里开始的微信由人工自己调好位置。运行代码将将会反复删除第一项微信收藏。
首先测试一下删除5条微信收藏:
import uiautomation as auto
def get_meau_item(name):
menu = wechatWindow.MenuControl()
menu_items = menu.GetLastChildControl().GetFirstChildControl().GetChildren()
for menu_item in menu_items:
if menu_item.ControlTypeName != "MenuItemControl":
continue
if menu_item.Name == name:
return menu_item
wechatWindow = auto.WindowControl(
searchDepth=1, Name="微信", ClassName='WeChatMainWndForPC')
collect = wechatWindow.ListControl(Name='收藏')
for _ in range(5):
item = collect.GetFirstChildControl()
item.RightClick()
get_meau_item("删除").Click()
confirmDialog = wechatWindow.WindowControl(
searchDepth=1, Name="微信", ClassName='ConfirmDialog')
delete_button = confirmDialog.ButtonControl(Name="确定")
delete_button.Click()可以看到完全木有问题:
那么想要批量删除全部微信收藏只需要改一下循环次数即可。
PS:如果觉得我的分享不错,欢迎大家随手点赞、在看。
1. 回复“m”可以查看历史记录;
2. 回复“h”或者“帮助”,查看帮助;
开发者已开通多个技术群交流学习,请加若飞微信:1321113940 (暗号k)进开发群学习交流
说明:我们都是开发者。视频或文章来源于网络,如涉及版权或有误,请您与若飞(1321113940)联系,将在第一时间删除或者修改,谢谢!

面向全栈工程师的开发者
专注于前端、Java/Python/Go/PHP的技术社区