kubernetes 核心组件详解
基础概念与组件
1.0 基础
docker
- docker是容器引擎之一,提供
runtime来运行容器 - 是kubernetes的 CRI 接口连接的对象之一
kubernetes
- 是容器集群管理系统的标准工具(容器编排)
- 可以实现容器集群的自动化部署、自动扩缩容、维护等功能
- Master将所有Node节点的资源整合成一个资源池,提供接口给用户,用户只需要向 k8s 提供需求即可
当用户在集群上部署应用时,Master使用调度算法将其自动分配给某个最合适的Node,用户无需关心细节
=
kubernetes分层架构
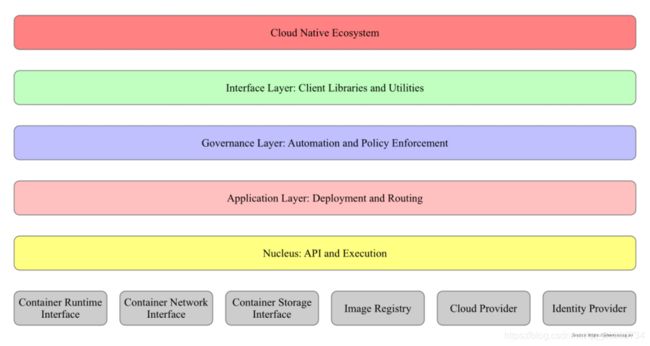
从上自下依次是:
- 云原生生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- K8s外部:日志、监控、配置管理、CI/CD、Workflow、FaaS、OTS应用、ChatOps、GitOps、SecOps等
- K8s内部:CRI、CNI、CSI、镜像仓库、Cloud Provider、集群自身的配置和管理等
- 接口层:kubectl命令行工具、客户端SDK以及集群联邦
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)、Service Mesh(部分位于管理层)
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)、Service Mesh(部分位于应用层)
- 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
API
- Application Programming Interface(应用程序接口)
- 操作系统OS是用户与计算机硬件系统之间的接口。。。OS提供两类接口,其中之一就是API
- 该接口是为程序员在编程时使用的,系统和应用程序通过这个接口,可在执行中访问系统中的资源和取得 OS 的服务,它也是程序能取得操作系统服务的唯一途径
软件测试版本
- Alpha 指的是内测,即现在说的 CB,即开发团队内部测试的版本或者有限用户的体验测试版本
- Beta 指的是公测,即针对所有用户公开的测试版本
- 而做过一些修改,成为正式发布的候选版本时(现在叫做 RC - Release Candidate),叫做 Gamma
- 稳定版
stable
1.1 实体概念
工作架构⭐
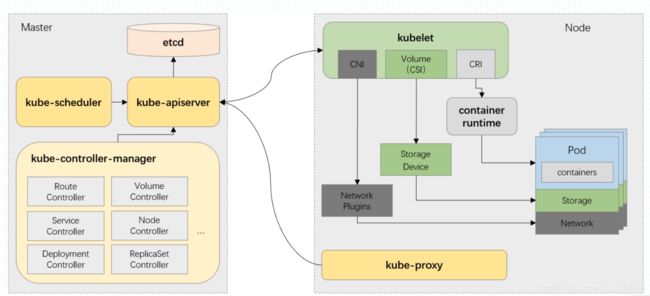
Master
- 是整个kubernetes集群的网关与中枢
- 以最优方式实现负载均衡
- 是各部分的核心联络点
- 单个Master即可实现自身的所有功能(但实际配置多台实现负载均衡和高可用)
=
Node
- 是kubernetes集群的工作节点
- 接收Master节点的指令,据此创建或销毁Pod
- 通过调整网络规则来实现合理地进行路由和转发流量
- 生产环境中Node节点数量众多
基本工作原理:
- Master将所有Node节点的资源整合成一个资源池,提供接口给用户,用户只需要向 k8s 提供需求即可
- 当用户在集群上部署应用时,Master使用调度算法将其自动分配给某个最合适的Node,用户无需关心细节
1.2 资源抽象
Pod
- 是一个标准的资源类型(最基本的)
- 是在 Kubernetes 集群的最小调度单元
- 封装一个或多个容器
- 一个 Pod 中的所有容器共享
NET namespace和存储资源- 内部容器可通过
lo直接通信 - 但彼此又在
MNT/USER/PID等namespace上保持隔离
- 内部容器可通过
- 通常情况下,为了使Pod尽可能小,应该只包含一个主容器(业务),以及必要的辅助容器
Label
- 是将资源进行分类的标识符
- 本质上是键值对
- 标签只对用户有意义,与集群本身并无太大联系(便于管理)
- 标签能在创建对象的同时附加上去,创建后可随时添加或修改
- 一个对象能有多个标签、一个标签能附加给多个对象
Selector
- 根据标签来过滤符合条件的资源对象
- 用户使用标签将资源对象进行分类,使用标签选择器挑选出他们
Controller
- 用户不会直接管理部署Pod,而是借助各种Pod控制器完成
- 控制器有多种,其中用于工作负载的控制器用于管理Pod生命周期
- 比如
Deployment负责确保指定的Pod的副本数量维持在指定值,否则多退少补
- 比如
- 用户只需要声明应用的期望状态,控制器就会以此为目标进行自动管理
Service
- Pod是动态消亡的对象,为了客户端能以固定入口访问容器,于是有了
Service - 本质上是四层代理服务(由
kube-proxy生成的iptables或ipvs规则) - 每个节点的
kube-proxy都会将其所在节点上的每个Service的定义转换为ipvs或iptables规则!!!!!!! - 通过
Selector选定一组Pod,并为这组Pod定义一个统一的固定访问入口(如:ClusterIP) - 若集群存在DNS附件,在Service创建之时会为其自动配置一个DNS_name,以便客户端进行服务发现
- 所有到达Service的请求将会负载均衡调度到后端各个Pod之上(选定的那一组Pod范围内)
- 可引入外部流量进入集群
- 同一Pod内部容器之间可直接通信
- Pod之间或Pod与Service之间使用内部专用地址通信
- 若需要开放指定的Pod给外部用户访问,就需要一个进入集群的通道,Service是实现方式之一
# 服务发现
'定义:针对客户端访问的服务,找到对应的的后端服务实例
'在K8s集群中,客户端需要访问的服务就是 Service对象
每个 Service 会对应一个集群内部的有效的虚拟IP,集群内部通过 虚拟IP 访问一个确定的服务。
# 负载均衡
'集群中微服务的负载均衡是由 Kube-proxy 实现的
Kube-proxy 是一个分布式代理服务器,集群上'每个【工作节点】都有一个Kube-proxy
需要访问服务的节点越多,提供负载均衡能力的 Kube-proxy 就越多,高可用节点也随之增多
Volume
- 是独立于容器文件系统之外的存储空间,常用于扩展容器的存储空间并实现持久存储
- kubernetes集群的存储卷分为:临时卷、本地卷、网络卷
- 临时卷、本地卷位于本节点,若调度到其他节点则无法访问(因此常用于缓存)
- 需要持久化的数据放置于持久卷(
persisent volume)之上
Name
-
是kubernetes集群中资源对象的标识符
-
作用域为一个namespace之内(一个namespace之内资源不能重名)
-
namespace用于资源隔离,形成逻辑分组 -
创建资源对象(如Pod、Service)时,若不指定
namespace,则默认属于default namespace
注:Pod、Service都是namespace级别的资源对象!也存在其他级别的资源!!!
Annotation
- 是除标签之外,另一种附加在对象之上的键值对(比标签的容量更大)
- 常用于将各种**非标识型元数据(metadata)**附加给对象
- 不能用于标识或选择对象!!!主要是为了方便用户或工具来查找对象
Ingress
- 同一Pod内部容器之间可直接通信
- Pod之间或Pod与Service之间使用内部专用地址通信
- 除了Service,Ingress也是引入外部流量的方式之一!!!
1.3 核心组件
# Master(控制节点)
apiserver # 各组件交互中心
scheduler # 调度。为Pod分配合适的节点
controller-manager # 控制中心。终极目标:维持spec期望状态
ETCD # 强一致的分布式K/V数据库。实现集群信息的持久化(自身已实现高可用)
# Node(工作节点)
kubelet # 与容器引擎进行交互,管理Pod的生命周期
kube-proxy # 解决网络问题。将service转化为 iptables/ipvs 规则
Container engine # 容器引擎
1.3.1 Master组件
-
各个Master组件组成了一个完整的集群控制平面
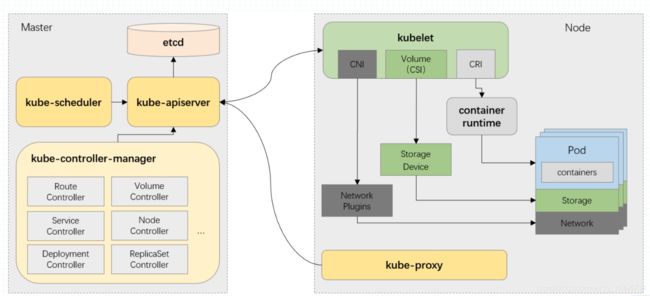
注:
apiserver组件运行时的程序文件名为kube-apiserver,其他类似- Master组件提供集群的管理控制中心
- Master组件可以在集群中任何节点上运行。但是为了简单起见,通常在一台VM/机器上启动所有Master组件,并且不会在此VM/机器上运行用户容器
- 若整个集群中只有一个master节点,称之为单控制平面节点,学习阶段够用,但实际生产中必须设为高可用
=
API-Server
- 是所有组件相互通信的核心,是整个集群的网关
- 是唯一能与ETCD通信的组件,将集群数据持久存储于ETCD之中
- 任何的资源请求/调用操作都是通过
apiserver提供的接口进行的,所有其他组件通过它进行交互 - 是所有Service规则的保存位置
apiserver的高可用,由前端的负载均衡服务器实现(通过健康监测功能实现)- 负载均衡器自身的高可用,由
keepalived设置VIP来实现 apiserver与Etcd基于https通信,状态信息都保存在后者,因此apiserver本身实现了无状态,因此设计冗余的时候不必设置过多,两三台已经足够(与实际业务规模相关)
Scheduler
- 集群的调度器
- 监控
API-Server所有可用资源,为Pod调度最佳Node API-Server确认Pod对象的创建请求之后,接下来便需要Scheduler进行调度选择Node创建Pod
注:kubernetes也支持用户自定义调度
Controller-manager
- 是许许多多的
Controller的集合 - 是整个集群的司令部(决策中心),是集群内部的管理控制中心(实际上真正起作用的控制中心)
- 通过
control loop确保集群的实际状态不断逼近期望状态(维持副本的期望数量) - 当某个Node意外宕机时,它会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态
- 逻辑上,每个控制器是一个单独的进程;但为了降低复杂性,它们都被编译成单个二进制文件
这些控制器包括:- 节点(Node)控制器
- 副本(Replication)控制器:负责维护系统中每个副本中的pod。
- 端点(Endpoints)控制器:填充Endpoints对象(即连接Services&Pods)。
- Service Account和Token控制器:为新的Namespace创建默认帐户访问API Token
ETCD
- 使用
raft一致性算法实现,是一个强一致性的分布式K/V存储系统(注册中心) - 是Kubernetes默认使用的
key-value数据存储系统 - 用于保存集群所有的网络配置和对象的状态信息 (共享配置和服务发现 )
- 应该设置多个节点实现冗余,同时考虑脑裂问题,一般设置为3或5个
- 支持分布式集群功能,在生产环境使用时需要为 etcd数据 提供定期备份机制
安装的时候指定的 Etcd 数据的存储路径是/var/lib/etcd,一定要对该目录做好备份 !!!
整个kubernetes系统中一共有两个服务需要用到etcd用来协同和存储配置:
- 网络插件
flannel、对于其它网络插件也需要用到 etcd存储网络的配置信息 kubernetes本身,包括各种对象的状态和元信息配置
1.3.2 Node组件
-
Node为运行容器提供各种依赖环境,并接受Master的管理
kubelet
- 是每个Node的核心代理程序,它会监视已分配给节点的pod,是运行在工作节点上的守护进程
- 在
API-Server上注册当前节点的工作节点,定期向Master汇报节点资源使用情况 - 通过
cAdvisor监控API-Server中Service的变化间接获得来自于scheduler的指令,
然后调用容器引擎进行相关操作来维持目标状态 - 能管理存储卷!!!!
kube-proxy
- 是一个为了确保分散运行在各个节点上的Pod能够被正常调度的守护进程
- 每个节点的
kube-proxy都会把整个集群的每个Service转换为自己的ipvs或iptables规则,
从而捕获访问当前Service的ClusterIP的流量,并转发至正确的后端Pod - 通过在主机上维护网络规则并执行连接转发 来实现Kubernetes服务抽象
注:Kubernetes 网络代理运行在 Node 上,它反映了 Node 上 Kubernetes API 中定义的服务,并可以通过一组后端进行简单的 TCP、UDP 流转发或循环模式(round robin)的 TCP、UDP 转发,用户必须使用apiserver API创建一个服务来配置代理,其实就是kube-proxy通过在主机上维护网络规则并执行连接转发来实现 Kubernetes服务访问
Container engine
- 容器引擎,提供
runtime环境以下载镜像并运行容器 kubelet以插件的方式载入配置的容器环境
综合解析⚡
关键组件工作原理
-
kube-apiserver是各组件的交互中心,并且是唯一能与ETCD交互的组件,直接负责集群数据存储 -
kube-controller-manager是许许多多的controller的集合(司令部,决策中心) -
kubelet通过某些协议基于HTTPS与kube-apiserver进行连接**(双向证书认证)**
kubelet监视kube-apiserver上与自己所在节点相关的Pod的状态(并不是监听所有数据) -
kubelet包括三个接口- CNI(Network)为容器提供网络服务
- CSI(Storage) 对接外部存储设备,从而为 Pod 提供存储卷
- CRI(Runtime)使之可以支持不同的容器引擎,因此
docker是可被替代的
-
kube-proxy解决客户端的访问
每个节点的kube-proxy都会把整个集群的每个Service转换为自己的ipvs或iptables规则
因此能实现服务的映射访问目的
各组件交互方式
每个worker node都要运行kubelet / kube-proxy / Container engine三个组件,这三个组件都只需与apiserver建立联系,他们都是apiserver的客户端!因此apiserver是整体的交互中心!
但是apiserver并不负责控制,其主要功能是借助ETCD来保存客户端所提交的、希望被存储的数据(实现状态存储),实际上起控制作用的控制中心是controller-manager
controller-manager不会直接指挥kubelet,而是监视apiserver中与自己相关的 Pod 的状态,当状态异常时,就发起请求进行修复;同时,kubelet也会监视apiserver,因此kubelet会实时察觉到apiserver中与自己所在节点相关的Pod的状态的改变,于是通过控制器(如Depolyment)唤起容器引擎进行相关操作,以维持副本的期望状态
注:
- 每个节点上都有
kubelet,注册监听apiserver中与自己相关的Pod的变动信息 Depolyment是controller-manager的组件之一,也会注册监听apiserver中与自己相关的内容Depolyment的实际操作是运行一个control loop实现监控(控制器的常规做法)
1.3.3 核心附件
Master组件、Node组件,再加上一些核心附件,才能构成完整的集群
K8s 必备附件
- CoreDNS:所有Pod、Node相互之间通过主机名联系
- Dashboard:提供Web管理界面
- Prometheus:监控系统,由此可实现故障发现与处理
- Ingress controller :入站流量控制器
- 日志收集与分析
- ELK(
Elasticsearch Logstash Kibana)或 EFK(Elasticsearch Filebeat Kibana) - LG(
Loki Grafana)
- ELK(
# Logstash是基于Java编译器的Ruby语言开发,占用内存很大
# 而Filebeat相同情况下,内存占用可能只需要前者的千分之一!
# Loki是仿照prometheus构建的工具
# Elasticsearch由Java开发(非云原生),而Loki是标准云原生工具
kubeDNS
- 集群中提供DNS服务的Pod。。此Pod为其他所有Pod解决DNS解析问题
- 服务注册和服务发现的总线:统称为 KubeDNS
kubeDNS的实现方案已经发展到第三代,产品名为CoreDNS- 默认使用 CoreDNS 为集群提供服务注册和服务发现的动态名称解析服务
- 由于Pod到service的通信是直接访问service的name,因此需要CoreDNS进行解析
- CoreDNS监听
API-Server中的每一个Service的定义,将其动态解析为自己的记录(A、PTR、SRV)
Dashboard
- 集群的全部功能都要使用 基于Web的 UI 来管理内部应用甚至是集群自身
Prometheus
- 是容器和节点的性能监控与分析系统
- 收集并解析集群的多种指标数据
Ingress Controller
Ingress是在应用层实现的http(s)负载均衡机制Ingress本质是一组路由规则的集合,需要由Ingress Controller发挥作用- 可用的实现方式:
nginx、Envoy、HAprox...
1.4 k8s 网络模型
1.4.1 四种通信
- 同一Pod内的容器间通信
- 各个Pod之间的通信
- Pod与Service之间的通信
- 集群外部流量与Service的通信
1 = 同一Pod内
各容器之间通信:
- 各个容器共享
NET namespace,直接回环通信
2 = 同一节点内
Pod与Pod之间的通信:
- 直接走节点内网桥
cni0(相当于docker内容器通信使用docker0)
2 = 跨节点的
Pod之间的通信(使用叠加或承载):
- 使用网络隧道
flannal.1通信(隧道接口附着在节点的网卡上) - 注:隧道报文需要额外封装一个报文头部,因此需要设定内部Pod间通信的MTU小于1500byte,以确保额外封装隧道报文头之后不会产生 巨型帧 (巨型帧
jumbo frames,是指有效负载超过IEEE 802.3标准所限制的1500字节的以太网帧)
总结:Pod之间通信,无论是否跨主机,都需要借助网络插件来实现
3 = Pod与Service通信
- 每个节点的
kube-proxy都会把整个集群的每个 Service 转换为自己的ipvs或iptables规则 - 因此【每个Pod】的IP地址都会出现在【每个节点】的
iptables规则之中
这些规则就相当于Pod的路由表(在内核网络协议栈中进行路由) - 实际上Pod先访问 Service 的name,由CoreDNS解析为IP,然后通过相关规则进行转发
使用Service的重要意义:实现【服务注册】与【服务发现】
4 = 外部流量访问Service
唯一入口:节点网络(节点网卡)
- 方式一:节点网卡 >> Service网络 >> Pod网络
进入节点之后直接到达节点内核中网络协议栈,从而找到Service定义规则,即可进行转发 - 方式二:节点网卡 >> Pod网络
让Pod直接共享Node节点网络Namespace,只要请求消息到达该节点,就能直达Pod
集群内容器间关系
亲密关系
- 此类容器放在同一个Pod之中,使之能够同进同退,共享三个Namespace(网络、IPC、UTS)
而且还共享同一组存储卷,因此Sidecar容器可以收集到统一的日志 - 注:若没有lo接口或共享存储卷就无法良好协同工作的容器,才被认为是关系亲密的容器
- Container to Container
非亲密关系
- Pod to Pod(无论是否跨节点)
- Pod to Service to Pod
1.4.2 三种网络层级
⭐集群网络结构⭐
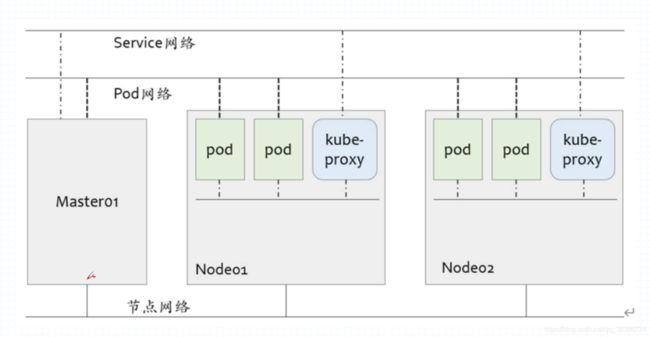
- 节点网络:所有主机自身所处的网络(Master、Node、ETCD)
- Pod网络:(常用
flannel插件实现)- 是虚拟网络(在创建集群时指定)
- 用于为各个Pod对象设定IP地址,即为PodIP!!!!!!
- 配置于Pod内部的容器的网络接口上
- 需要借助
kubelet插件或CNI插件实现 - 插件可部署在集群之外,也可托管于集群之上
- Service网络:由集群指定
- 是虚拟网络(在创建集群时指定)
注意:创建集群时指定Service网络,创建Service对象时动态分配Service地址,即为ClusterIP!!!!! - 用于为集群中的Service对象设定IP地址
- 此地址并不会配置于任何接口之上,而是通过Node上的
kube-proxy配置为iptables或ipvs规则,
从而将发往此地址的流量调度到后端各个Pod之上
- 是虚拟网络(在创建集群时指定)
⭐集群内部存在三类IP
# Node IP
宿主机的IP地址
# Pod IP
# 由网络插件配置指定,比如 flannel 的 10.244.0.0/16
假设有3个Node:
则可分配 Node1= 10.244.1.0/24
Node2= 10.244.2.0/24
Node3= 10.244.3.0/24
此时每个节点上可运行 256 个容器
'Pod网络配置在 Pod内部的容器的网卡之上!!!!!!!
# Cluster IP:虚拟IP,通过iptables规则访问服务
# 在使用 flannel 的 10.244.0.0/16 的情况下
一般 Service网络是 10.96.0.0/12 (则可使用网段为 96~112)
`注意:Service网络不会出现在某个网卡上!!!
'出现在 iptables/ipvs规则 之中,作为访问的入口或端点
'也会出现在DNS解析记录中,将Service的名称解析为其对应的IP地址
=
1.4.3 网络插件
Kubernetes本身并不提供网络功能,只是把网络接口开放出来,通过插件的形式实现(CNI)
Kubernetes管理的是集群
Kubernetes中的网络要解决的核心问题就是每台主机的IP地址网段划分,以及单个容器的IP地址分配
概括为:
- 保证每个Pod拥有一个集群内唯一的IP地址
- 保证不同节点的IP地址划分不会重复
- 保证跨节点的Pod可以互相通信
- 保证不同节点的Pod可以与跨节点的主机互相通信
插件遵循原则
- 所有Pod之间都可不经过NAT而直接通信
- 所有Pod都位于同一平面网络中,而且可以使用Pod自身的地址直接通信
- 所有节点都可不经过NAT而直接与所有容器通信
当前最常用的两种CNI解决方案为:flannel、Project calico
flannel:仅实现了网络(简单易用易理解)Project calico:实现了网络和网络策略(生产环境使用居多)
flannel 插件
flannel的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址,而且它还能在这些IP地址之间建立一个覆盖网络(Overlay Network),通过这个覆盖网络,将数据包原封不动地传递到目标容器内
Flannel是作为一个二进制文件的方式部署在每个node上,主要实现两个功能:
- 为每个node分配subnet,容器将自动从该子网中获取IP地址
- 当有node加入到网络中时,为每个node增加路由配置
# flannel网络架构
- 节点网络:对应各个主机的IP(自定义)
- Pod网络:对应CNI的网段,配置在Pod内部容器的网卡上(如flannel的`10.244.0.0/16`)
- service网络:只出现在`iptables`或`ipvs`规则之中,作为访问入口使用(由`kube-proxy`管理)
calico 插件
Calico创建和管理一个扁平的三层网络(不需要overlay),每个容器会分配一个可路由的IP。由于通信时不需要解包和封包,因此网络性能损耗小,易于排查,且易于水平扩展
客户端分类
-
目标为API-Server
- 通过
API-Server访问集群,完成管理任务 - 需借助命令行
kubectl或者图形工具Dashboard,或者通过API接口
- 通过
-
目标为应用程序提供的服务
- 访问内部服务(包括本节点集群外的独立容器)
- 访问方式取决于具体的服务(如nginx服务使用浏览器访问)
总结⚡
- 同一节点的Pod之间能够之间通信(通过
localhost) - 跨节点的Pod之间通信,理论上可以直接叠加承载通信,或者通过
kube-proxy通信
但是集群中的节点是很多的、而且是动态消亡的,因此必须使用kube-proxy通过service网卡通信(通过注册中心) - 因此Service能够提供一个固定的访问入口,保证各种Pod通信的稳定性
- 同时,Service网络不是直接使用IP,因此还需要CoreDNS进行解析
1.4.4 外部流量引入
⭐NodePort
借助 Service 的调度算法将流量调度到Pod
⭐Ingress
由 Ingress 调度直接到达Pod(但是Ingress会先借助Service识别一个服务后的所有Pod资源)
1.5 开放接口
Kubernetes 作为云原生应用的基础调度平台,相当于云原生的操作系统,为了便于系统的扩展,Kubernetes中开放的以下接口,可以分别对接不同的后端,来实现自己的业务逻辑:
- CNI(容器网络接口)Network( 提供网络资源 )
- CSI(容器存储接口) Volume ( 提供存储资源 )
- CRI(容器运行时接口)Runtime,使之可以支持不同的容器引擎( 提供计算资源 )
以上三种资源相当于一个分布式操作系统的最基础的几种资源类型,而Kuberentes是将他们结合在一起的纽带

CRI
CRI中定义了容器和镜像的服务的接口,因为容器运行时与镜像的生命周期是彼此隔离的,因此需要定义两个服务。该接口使用Protocol Buffer,基于gRPC
Container Runtime实现了CRI gRPC Server,包括RuntimeService和ImageService。该gRPC Server需要监听本地的Unix socket,而kubelet则作为gRPC Client运行
Kubernetes 1.9中的CRI接口定义中 包含了两个gRPC服务:
- RuntimeService:容器和Sandbox运行时管理
- ImageService:提供了从镜像仓库拉取、查看、和移除镜像的RPC
通过CRI接口可以指定使用其它容器运行时作为Pod的后端 ,而不一定是使用 docker
cri-o:cri-o是Kubernetes的CRI标准的实现,并且允许Kubernetes间接使用OCI兼容的容器运行时
可以把cri-o看成Kubernetes使用OCI兼容的容器运行时的中间层cri-containerd:基于Containerd的Kubernetes CRI 实现rkt:由CoreOS主推的用来跟docker抗衡的容器运行时frakti:基于hypervisor的CRIdocker:kuberentes最初就开始支持的容器运行时,目前还没完全从kubelet中解耦,docker公司同时推广了OCI标准
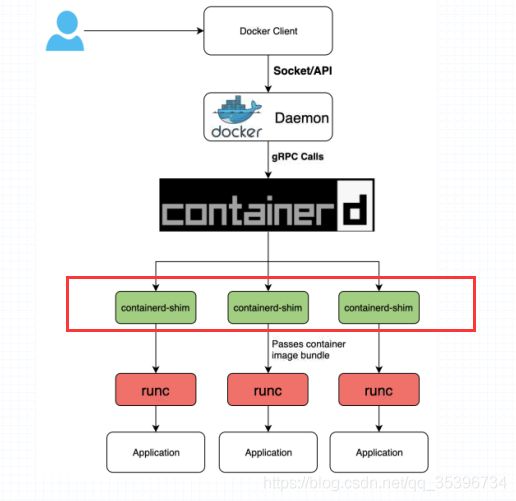
注:K8s与docker交互,接入点在container-shim处,在此之上的部分与集群无关(包括Daemon)
因此 Podman作为一个无守护进程的容器引擎,也能实现与K8s协同工作!!!
CNI
CNI(Container Network Interface)是 CNCF 旗下的一个项目,由一组用于配置 Linux 容器的网络接口的规范和库组成,同时还包含了一些插件。CNI 仅关心容器创建时的网络分配,和当容器被删除时释放网络资源
Kubernetes 源码的 vendor/github.com/containernetworking/cni/libcni 目录中已经包含了 CNI 的代码,也就是说 kubernetes 中已经内置了 CNI
CNI 插件负责将网络接口插入容器网络命名空间(例如,veth 对的一端),并在主机上进行任何必要的改变(例如将 veth 的另一端连接到网桥)。然后将 IP 分配给接口,并通过调用适当的 IPAM 插件来设置与 “IP 地址管理” 部分一致的路由
相关要点:
- 容器运行时必须在调用任何插件之前为容器创建一个新的网络命名空间 , 必须确定这个容器应属于哪个网络,并为每个网络确定哪些插件必须被执行
- 网络配置采用 JSON 格式,可以很容易地存储在文件中
网络配置允许字段在调用之间改变值 - 容器运行时必须按顺序为每个网络执行相应的插件,将容器添加到每个网络中
- 在完成容器生命周期后,运行时必须以相反的顺序执行插件以将容器与网络断开连接
- 容器运行时不能为同一容器调用并行操作,但可以为不同的容器调用并行操作
- 容器必须由 ContainerID 唯一标识
IP 分配:
作为容器网络管理的一部分,CNI 插件需要为接口分配(并维护)IP 地址,并安装与该接口相关的所有必要路由。这给了 CNI 插件很大的灵活性,但也给它带来了很大的负担。众多的 CNI 插件需要编写相同的代码来支持用户需要的多种 IP 管理方案
为了减轻负担,使 IP 管理策略与 CNI 插件类型解耦,我们定义了 IP 地址管理插件(IPAM 插件)。CNI 插件的职责是在执行时恰当地调用 IPAM 插件。 IPAM 插件必须确定接口 IP/subnet,网关和路由,并将此信息返回到 “主” 插件来应用配置。 IPAM 插件可以通过协议(例如 dhcp)、存储在本地文件系统上的数据、网络配置文件的 “ipam” 部分或上述的组合来获得信息
可用插件举例:
- flannel:根据 flannel 的配置文件创建接口
- tuning:调整现有接口的 sysctl 参数
- portmap:一个基于 iptables 的 portmapping 插件。将端口从主机的地址空间映射到容器
CSI
CSI 代表容器存储接口,CSI 试图建立一个行业标准接口的规范,借助 CSI 容器编排系统(CO)可以将任意存储系统暴露给自己的容器工作负载
CSI 持久化卷支持是在 Kubernetes v1.9 中引入的,作为一个 alpha 特性,必须由集群管理员明确启用