DL-Practise / OpenSitUp 训练自己的数据集(关键点检测)
源码
一、下载code
建立虚拟环境:conda create -n AI python = 3.8.5
激活虚拟环境:activate AI
切换路径:
e:
cd E:\xxxxxxx\OpenSitUp-main\OpenSitUp-main\Trainer
修改train.py:
1、保错与修改如下图所示:
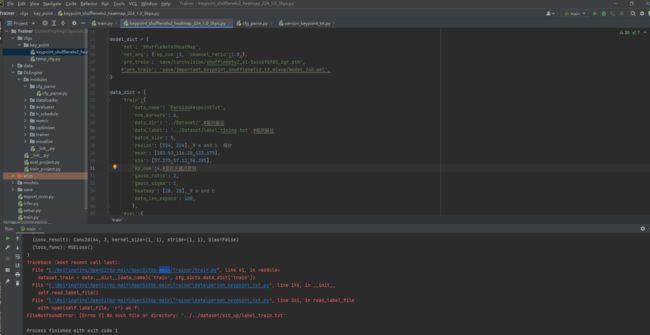
主要是路径和关键点数目的修改。batch_size我改为5了
2、再次debug train.py,报错如下:

修改方法如图中注释:
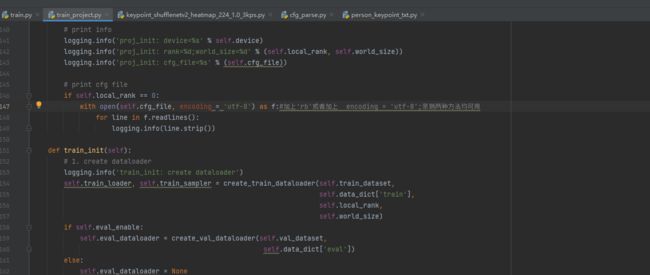
注:若报错:

则表明报错和cuda有关,若没有安装cuda则更改如下图注释所示:
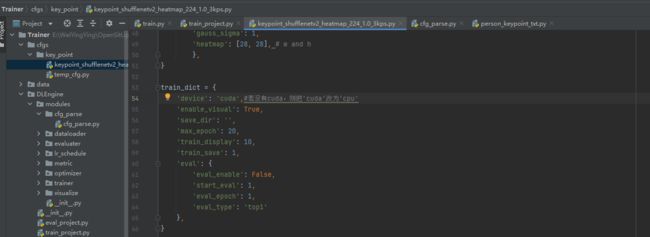
若安装了cuda 依旧报错,检测下载的torch版本是否是cuda系列,卸载重新安装cuda版本torch:
我的是:conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
3、新的报错:TypeError: a bytes-like object is required, not ‘str’
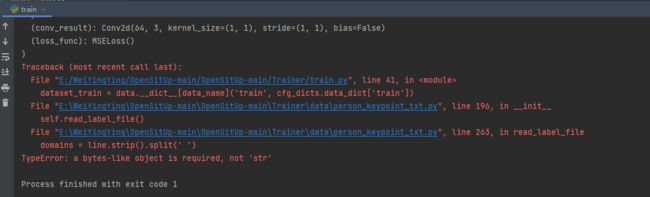
解决方法:
问题出在python3.5和Python2.7在套接字返回值解码上有区别:
python bytes和str两种类型可以通过函数encode()和decode()相互转换,
str→bytes:encode()方法。str通过encode()方法可以转换为bytes。
bytes→str:decode()方法。如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法。
将line.strip().split(“,”) 改为 line.decode().strip().split(“,”),大功告成!
正确写法:(字符串转16进制)
server_reply = binascii.hexlify(s.recv(1024)).decode()
print(server_reply)
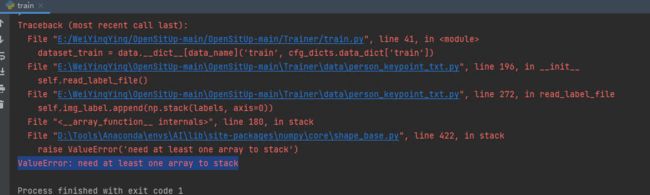
4、报错:ValueError: need at least one array to stack
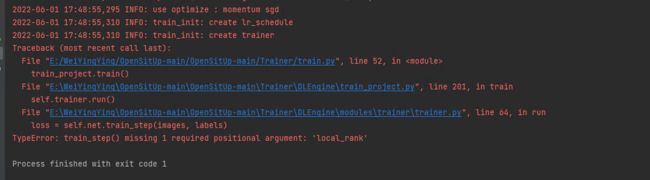
5、报错:TypeError: train_step() missing 1 required positional argument: ‘local_rank’
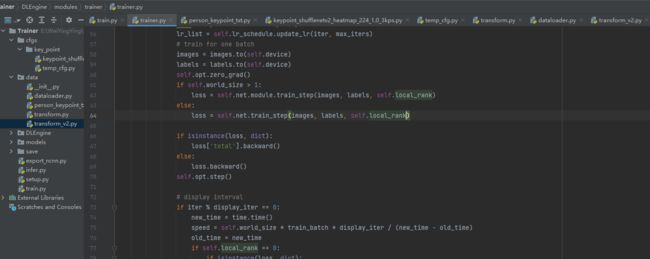
解决方法:将62行的self.local_rank复制到64行,如下图:
6、报错: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
解决方法:
在AI虚拟环境中搜索libiomp5md.dll
出现两个同名文件,其中第一个是torch路径下的,第二个是虚拟环境本身路径下的,转到第二个目录下把它剪切到其他路径下备份就好(最好把路径也备份一下)。
我是新建了一个文件夹放进去了,如下图,并记录地址:

然后就开始训练了

训练过程的结果会存储在save文件夹:

由图可知四个关键点都清楚地检测出来了。训练速度还能接受。
特别注意:以上记录的报错并不会全部出现,视具体情况而定,不需要全部修改上诉代码。其实安装环境正确的话可能只报三四个错误!!!
二、准备自己的数据集
切换到:cd E:\xxxxxxxx\OpenSitUp-main\OpenSitUp-main\LabelTool
安装库
pip install PyQt5
(注:删除原有的txt文件,标注一批ctrl+s一批,最后标注完保存后,点x号关闭标注界面会在图片文件夹中生成相应的txt文件。)运行作者准备的数据标注工具,在win10/python 3.8.5环境下,AI虚拟环境中,运行:
python main_widget.py
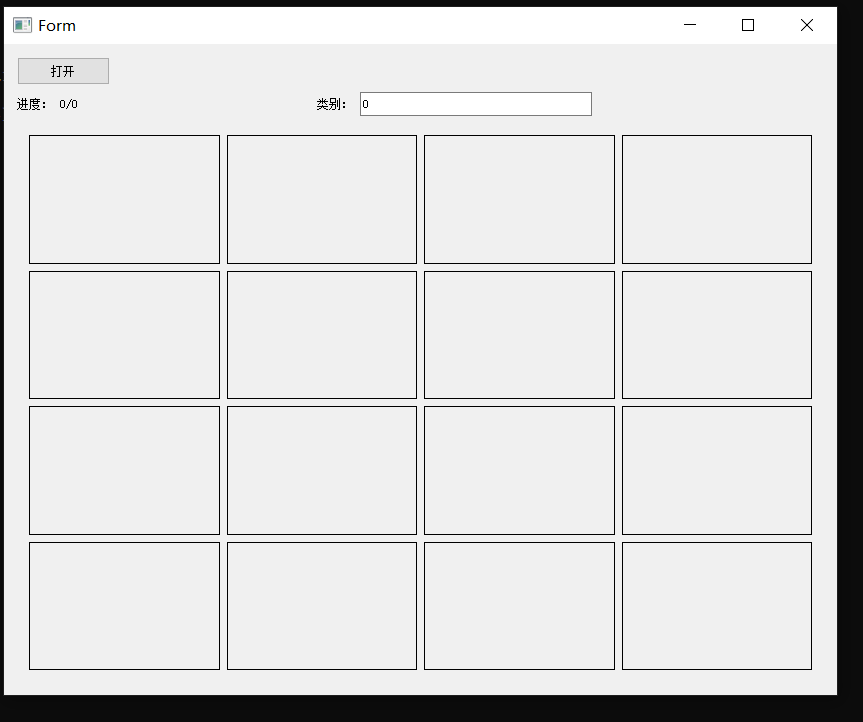
开始标注,单击鼠标左键进行标注,右键取消上一次标注。:如下图,共标记4个关键点,标签分别是0,1,2,3(批量标注,效率很高!)
标注完后生成的txt文件如下图:
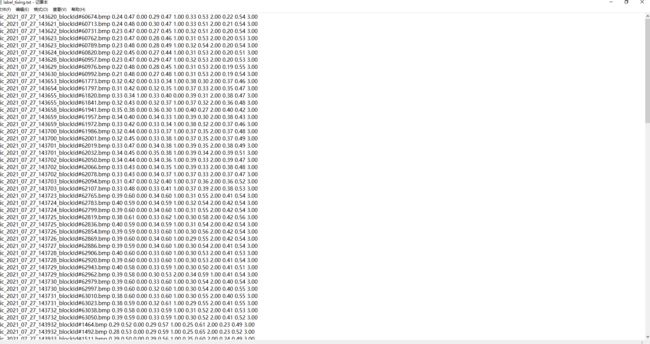
原模型用来训练计数仰卧起坐的,只需三个点,我的数据有四个点(没有截四个点的图),需要修改infer.py。
三、修改推理代码 ——infer.py
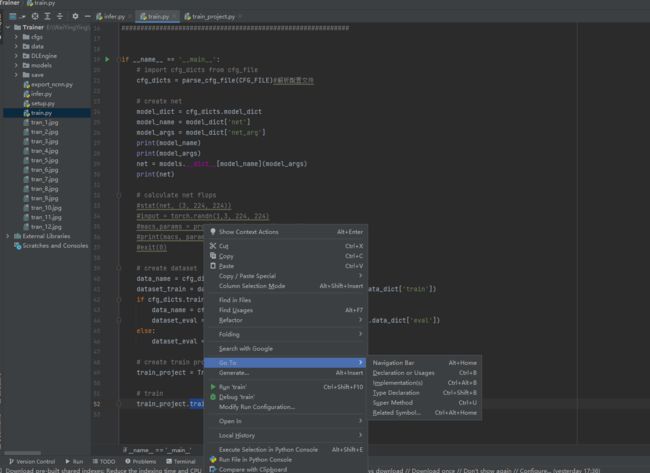
1、跳入引用的函数方法:
选中该函数,右键->Go To ->Declaration or Usages
即可跳到上一步该函数内容:
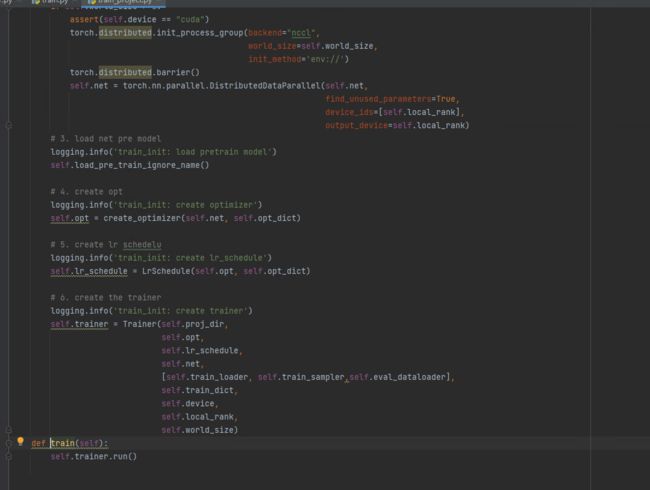
然后继续在新函数下Go To,深挖具体函数步骤,如图:

到达run()函数,如图:

2、修改如下图所示内容:
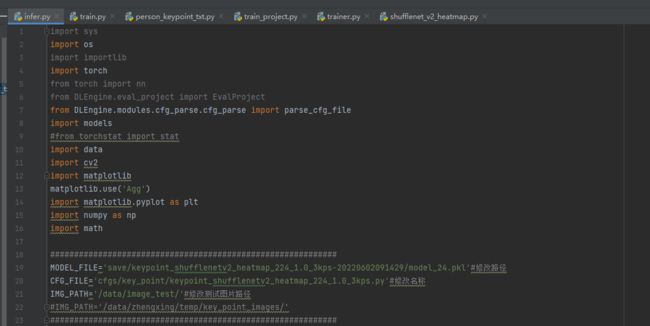
如下图代码,推理过程未报错,但是推理图片是空白:
import sys
import os
import importlib
import torch
from torch import nn
from DLEngine.eval_project import EvalProject
from DLEngine.modules.cfg_parse.cfg_parse import parse_cfg_file
import models
#from torchstat import stat
import data
import cv2
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import numpy as np
import math
############################################################
MODEL_FILE='save/keypoint_shufflenetv2_heatmap_224_1.0_3kps-20220602091429/model_24.pkl'#修改路径
CFG_FILE='cfgs/key_point/keypoint_shufflenetv2_heatmap_224_1.0_3kps.py'#修改名称
IMG_PATH='/data/image_test/'#修改测试图片路径
#IMG_PATH='/data/zhengxing/temp/key_point_images/'
############################################################
def load_pre_train_ignore_name(net, pre_train):
if pre_train == '':
print('the pre_train is null, skip')
return
else:
print('the pre_train is %s' % pre_train)
new_dict = {}
pretrained_model = torch.load(pre_train, map_location=torch.device('cpu'))
pre_keys = pretrained_model.keys()
net_keys = net.state_dict().keys()
print('net keys len:%d, pretrain keys len:%d' % (len(net_keys), len(pre_keys)))
if len(net_keys) != len(pre_keys):
print(
'key lens not same, maybe the pytorch version for pretrain and net are difficent; use name load')
for key_net in net_keys:
strip_key_net = key_net.replace('module.', '')
if strip_key_net not in pre_keys:
print('op: %s not exist in pretrain, ignore' % (key_net))
new_dict[key_net] = net.state_dict()[key_net]
continue
else:
net_shape = str(net.state_dict()[key_net].shape).replace('torch.Size', '')
pre_shape = str(pretrained_model[strip_key_net].shape).replace('torch.Size', '')
if net.state_dict()[key_net].shape != pretrained_model[strip_key_net].shape:
print('op: %s exist in pretrain but shape difficenet(%s:%s), ignore' % (
key_net, net_shape, pre_shape))
new_dict[key_net] = net.state_dict()[key_net]
else:
print(
'op: %s exist in pretrain and shape same(%s:%s), load' % (key_net, net_shape, pre_shape))
new_dict[key_net] = pretrained_model[strip_key_net]
else:
for key_pre, key_net in zip(pretrained_model.keys(), net.state_dict().keys()):
if net.state_dict()[key_net].shape == pretrained_model[key_pre].shape:
new_dict[key_net] = pretrained_model[key_pre]
print('op: %s shape same, load weights' % (key_net))
else:
new_dict[key_net] = net.state_dict()[key_net]
print('op: %s:%s shape diffient(%s:%s), ignore weights' %
(key_net, key_pre,
str(net.state_dict()[key_net].shape).replace('torch.Size', ''),
str(pretrained_model[key_pre].shape).replace('torch.Size', '')))
net.load_state_dict(new_dict, strict=False)
def get_need_test_images(the_path):
img_list = []
if os.path.isdir(the_path):
files = os.listdir(the_path)
for file in files:
if str(file).endswith('.jpg') or str(file).endswith('.bmp'):#这里我把png改为了bmp
img_list.append(the_path + '/' + str(file))
elif os.path.isfile(the_path):
img_list.append(the_path)
if len(img_list) > 16:
return img_list[0:16]
return img_list
def key_point_postproc(img_ori, net_out, thres, i, total):
def draw_line(pose_1, pose_2, img_size):
if pose_1[2] > 0 and pose_2[2] > 0:
plt.plot([pose_1[0]*img_size, pose_2[0]*img_size],[pose_1[1]*img_size, pose_2[1]*img_size,], color='red')
def draw_head(pose_1, pose_2, img_size):
if pose_1[2] > 0 and pose_2[2] > 0:
plt.plot([pose_1[0]*img_size, pose_2[0]*img_size],[pose_1[1]*img_size, pose_2[1]*img_size,], color='red')
side = math.ceil(math.sqrt(total))
plt.subplot(side, side, i+1)
plt.axis('off')
preds = net_out.squeeze().cpu().detach().numpy()
img_resize = cv2.resize(img_ori, (224, 224))[:,:,[2,1,0]]
results = []
for c in range(13):
info = preds[c]
max_score = info.max()
if max_score > thres:
max_pos_ = info.argmax()
max_pos = np.unravel_index(max_pos_, info.shape)
pos_y = max_pos[0] / 55.0
pos_x = max_pos[1] / 55.0
results.append([pos_x, pos_y, 1.0])
else:
results.append([-1.0, -1.0, 0.0])
plt.imshow(img_resize)
if results[1][2] > 0 and results[2][2] > 0 and results[0][2] > 0:
result_temp = [0.0, 0.0, 1.0]
result_temp[0] = (results[1][0] + results[2][0]) / 2.0
result_temp[1] = (results[1][1] + results[2][1]) / 2.0
draw_line(results[0], result_temp , 224)
draw_line(results[1], results[2], 224)
draw_line(results[1], results[3], 224)
draw_line(results[2], results[4], 224)
draw_line(results[3], results[4], 224)
draw_line(results[1], results[5], 224)
draw_line(results[5], results[7], 224)
draw_line(results[2], results[6], 224)
draw_line(results[6], results[8], 224)
draw_line(results[3], results[9], 224)
draw_line(results[9], results[11], 224)
draw_line(results[4], results[10], 224)
draw_line(results[10], results[12], 224)
def key_point_postproc_simple(img_ori, net_out, thres, i, total):
show_heatmap = False
show_scatter = True
preds = net_out.squeeze().cpu().detach().numpy()
kp_num = preds.shape[0]
img_resize = cv2.resize(img_ori, (224, 224))[:,:,[2,1,0]]
side = math.ceil(math.sqrt(total))
plt.subplot(side, side, i+1)
plt.axis('off')
if show_heatmap:
img_show = None
heatmap_show = None
for c in range(kp_num):
heatmap = cv2.resize(preds[c], (224, 224))
if img_show is None:
img_show = img_resize
else:
img_show = np.concatenate((img_show,img_resize),axis=1)
if heatmap_show is None:
heatmap_show = heatmap
else:
heatmap_show = np.concatenate((heatmap_show,heatmap),axis=1)
plt.imshow(img_show)
plt.imshow(heatmap_show, alpha=0.5)
if show_scatter:
plt.imshow(img_resize)
all_points_x = []
all_points_y = []
for c in range(kp_num):
max_score = preds[c].max()
if max_score > thres:
max_pos_ = preds[c].argmax()
max_pos = np.unravel_index(max_pos_, preds[c].shape)
pos_y = max_pos[0] * 224 / (preds[c].shape[0] - 1)
pos_x = max_pos[1] * 224 / (preds[c].shape[1] - 1)
all_points_x.append(pos_x)
all_points_y.append(pos_y)
if c == 0:
plt.scatter(pos_x, pos_y, s=80, c='r')
if c == 1:
plt.scatter(pos_x, pos_y, s=80, c='g')
if c == 2:
plt.scatter(pos_x, pos_y, s=80, c='b')
if len(all_points_x) == 3:
plt.plot([all_points_x[0],all_points_x[2],all_points_x[1]], [all_points_y[0],all_points_y[2],all_points_y[1]], c='b')
if __name__ == '__main__':
# import cfg_dicts from cfg_file
cfg_dicts = parse_cfg_file(CFG_FILE)
# create net
model_dict = cfg_dicts.model_dict
model_name = model_dict['net']
model_args = model_dict['net_arg']
print(model_name)
print(model_args)
net = models.__dict__[model_name](model_args)
print(net)
load_pre_train_ignore_name(net, MODEL_FILE)
net.eval()
net.cuda()
# create dataloader
data_name = cfg_dicts.data_dict['eval']['data_name']
dataset = data.__dict__[data_name]('eval', cfg_dicts.data_dict['eval'])
# get img lists and process
plt.figure(figsize=(20, 20), dpi=100)
img_list = get_need_test_images(IMG_PATH)
for i, img_path in enumerate(img_list):
img, img_ori, ori_w, ori_h = dataset.read_image(img_path)
img_t = torch.from_numpy(img).unsqueeze(0).cuda()
# the network inference
preds = net(img_t)
# keypoint postproc
key_point_postproc_simple(img_ori, preds, 0.1, i, len(img_list))
plt.savefig('./infer.jpg')
3、运行到如下图位置时,反复循环,无法执行下一句代码,于是,批量将bmp图片转为jpg图片
方法:
将.bmp转换为.jpg:
1)、在图片目录下新建一个TXT,写入ren *.bmp *.jpg
2)、将txt后缀改成.bat
3)、双击该bat文件即可
将.jpg转换为.bmp:
1)、在图片目录下新建一个TXT,写入ren *.jpg *.bmp
2)、将txt后缀改成.bat
3)、双击该bat文件即可
效果完美:
预测结果:(目前还是三个点)
4、报错warning:
UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.
warnings.warn(“nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.”)
解决方法: