模拟退火算法深入学习
前面三篇文章详细介绍了遗传算法,本章开始介绍模拟退火算法,并对二者的优缺点、应用范围做更进一步的比较和探讨。
模拟退火算法与遗传算法是非常重要的多目标优化算法,因其对所优化的目标函数的解析性没有要求,所以被广泛的应用于工程问题的求解领域,如:
模拟退火算法可用于VLSI(Very Large Scale Integration超大规模集成电路)的最优设计,用模拟退火算法几乎可以很好地完成所有优化的VLSI设计工作。如全局布线、布板、布局和逻辑最小化等等。
模拟退火算法在神经网络中的应用,模拟退火算法具有跳出局部最优陷阱的能力。在Boltzmann机中,即使系统落入了局部最优的陷阱,经过一段时间后,它还能再跳出来,再系统最终将往全局最优值的方向收敛。
模拟退火算法在图像处理中的应用,模拟退火算法可用来进行图像恢复等工作,即把一幅被污染的图像重新恢复成清晰的原图,滤掉其中被畸变的部分。因此它在图像处理方面的应用前景是广阔的。
下面先介绍一下爬山算法:
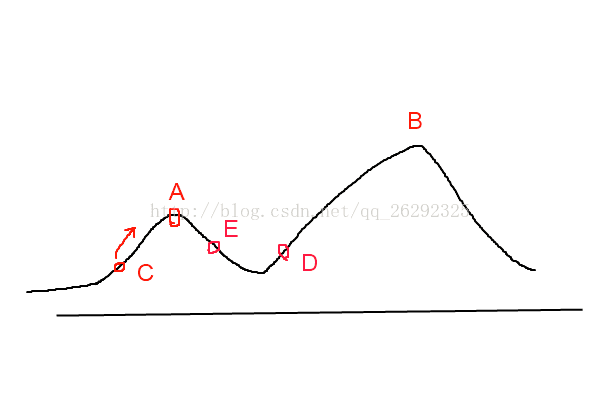
目标是要找到函数的最大值,若初始化时,初始点的位置在 C 处,则会寻找到附近的局部最大值 A 点处,由于 A 点出是一个局部最大值点,故对于爬山法来讲,该算法无法跳出局部最大值点。若初始点选择在 D 处,根据爬山法,则会找到全部最大值点 B 。这一点也说明了这样基于贪婪的爬山法是否能够取得全局最优解与初始值的选取由很大的关系。
模拟退火算法(Simulated Annealing, SA)的思想借鉴于固体的退火原理,当固体的温度很高的时候,内能比较大,固体的内部粒子处于快速无序运动,当温度慢慢降低的过程中,固体的内能减小,粒子的慢慢趋于有序,最终,当固体处于常温时,内能达到最小,此时,粒子最为稳定。模拟退火算法便是基于这样的原理设计而成。.

模拟退火算法的原理和爬山法类似, 刚开始的时候,由于温度T较高,所以能量比较大,每一步的跳跃间隔也大。如上二维图所示,假设初始化时起点位于A,跳第一步(跳跃间距较大),假设粒子调到了位置B,那么问题来了,我们是否接受呢?
答案是肯定的,模拟退火算法给我们的答案是以一定的概率接受,并且这个概率随温度的降低逐渐降低(注意:不是不接受,但为什么会接受呢?),如果不接受,那么这个粒子只能在A峰周围了,它永远也不可能到达比A峰更高的D峰,所以只有接受的可能,才有到达更高峰的希望,并且接受的概率越高,该粒子跳出A峰区域的概率就越高。所以,我们可以这样理解,起初,粒子能量比较大,它大概会在各个山峰之间跳动,但它待在高峰区域的概率比较高(即:起初在高能量时以高概率锁定全局最优值区域),随着能量的降低,粒子跳动的间距变小,由于之前以高概率锁定了全局最优区域,所以此时就是按照爬山算法爬到山顶(即:后期以利用爬山算法寻找局部最优值,因为这个局部是之前高能量时锁定的区域,他是全局最优区域的概率最大,所以这一步寻找到的局部最优值是全局最优值的概率也比较大)。
总结,根据以上结论,模拟退火算法并不一定能找到全局最优值,但它有比较大的概率会找到全区最优值,这个概率的大小就是需要我们根据实际问题来设定我们的各项参数,通过实验验证来寻找最优参数(PS:这里就又要强调我在建模与仿真(笔者在“遗传算法深入学习下”中有详细的介绍)的重要性了),下面是比较专业的模拟退火算法过程。
模拟退火算法使用过程中参数的整定会影响其全局搜索性能。初始温度T选择越高,则搜索到全局最优解的可能性也越大,但计算复杂度也显著增大。反之,能节省时间,但易于陷入局部最优。依据解的质量变化概率选择温度下降策略能增强算法性能。每次温度降低迭代次数及算法的终止可由给定迭代次数内获得更优解的概率而确定。
模拟退火算法过程
(1)随机挑选一个单元 k ,并给它一个随机的位移,求出系统因此而产生的能量变化 ΔEk 。
(2)若 ΔEk⩽0 ,该位移可采纳,而变化后的系统状态可作为下次变化的起点;
若 ΔEk>0 ,位移后的状态可采纳的概率为
式中 T 为温度,然后从 (0,1) 区间均匀分布的随机数中挑选一个数 R ,若 R<Pk ,则将变化后的状态作为下次的起点;否则,将变化前的状态作为下次的起点。
(3)转第(1)步继续执行,知道达到平衡状态为止
下面介绍遗传算法的核心代码:
//F(x):在状态x时的评价函数值
//f(i):当前的状态
//f(i+1):下一个新的状态
//delta:用来控制降温快慢的尺度参数
//T:系统的温度,可理解为初始化时的最高温度
//T_min:温度的下限,可理解为停止搜索时的温度
while(T>T_min)
{
dE = F(f(i+1) - f(i));
if(dE >= 0)//若下一状态的解更优,那么就接受这个更优解
f(i+1) = f(i);
else
{
if(exp(dE/T)) > random(0,1)//否则,就以概率exp(dE/T)) > random(0,1)接受这个较差的解
f(i+1) = f(i); //并且可以看出,温度越高时接受这个差解的概率就越大,这样
} //就有更高的概率锁定全局最优解所在的区域(山峰)
T *= delta;
i++;
}
好了,理论介绍完了,下面举个栗子实战一下:我们就以模拟退火算法求解函数f(x,y) = 5sin(xy) + x^2 + y^2的最小值
using System;
namespace SimulateAnnealing
{
class Class1
{
// 要求最优值的目标函数
static double ObjectFunction( double x, double y )
{
double z = 0.0;
z = 5.0 * Math.Sin(x*y) + x*x + y*y;
return z;
}
[STAThread]
static void Main(string[] args)
{
// 搜索的最大区间
const double XMAX = 4;
const double YMAX = 4;
// 冷却表参数
int MarkovLength = 10000; // 马可夫链长度
double DecayScale = 0.95; // 衰减参数
double StepFactor = 0.02; // 步长因子
double Temperature = 100; // 初始温度
double Tolerance = 1e-8; // 容差
double PreX,NextX; // prior and next value of x
double PreY,NextY; // prior and next value of y
double PreBestX, PreBestY; // 上一个最优解
double BestX,BestY; // 最终解
double AcceptPoints = 0.0; // Metropolis过程中总接受点
Random rnd = new Random();
// 随机选点
PreX = -XMAX * rnd.NextDouble() ;
PreY = -YMAX * rnd.NextDouble();
PreBestX = BestX = PreX;
PreBestY = BestY = PreY;
// 每迭代一次退火一次(降温), 直到满足迭代条件为止
do
{
Temperature *=DecayScale;
AcceptPoints = 0.0;
// 在当前温度T下迭代loop(即MARKOV链长度)次
for (int i=0;i {
// 1) 在此点附近随机选下一点
do
{
NextX = PreX + StepFactor*XMAX*(rnd.NextDouble()-0.5);
NextY = PreY + StepFactor*YMAX*(rnd.NextDouble()-0.5);
}
while ( !(NextX >= -XMAX && NextX = -YMAX && NextY
// 2) 是否全局最优解
if (ObjectFunction(BestX,BestY) > ObjectFunction(NextX,NextY))
{
// 保留上一个最优解
PreBestX =BestX;
PreBestY = BestY;
// 此为新的最优解
BestX=NextX;
BestY=NextY;
}
// 3) Metropolis过程
if( ObjectFunction(PreX,PreY) - ObjectFunction(NextX,NextY) > 0 )
{
// 接受, 此处lastPoint即下一个迭代的点以新接受的点开始
PreX=NextX;
PreY=NextY;
AcceptPoints++;
}
else
{
double change = -1 * ( ObjectFunction(NextX,NextY) - ObjectFunction(PreX,PreY) ) / Temperature ;
if( Math.Exp(change) > rnd.NextDouble() )
{
PreX=NextX;
PreY=NextY;
AcceptPoints++;
}
// 不接受, 保存原解
}
}
Console.WriteLine("{0},{1},{2},{3}",PreX, PreY, ObjectFunction ( PreX, PreY ), Temperature);
} while( Math.Abs( ObjectFunction( BestX,BestY) – ObjectFunction (PreBestX, PreBestY)) > Tolerance );
Console.WriteLine("最小值在点:{0},{1}",BestX, BestY);
Console.WriteLine( "最小值为:{0}",ObjectFunction(BestX, BestY) );
}
}
}由之前的几篇文章可以看出,遗传算法和模拟退火算法各有千秋,下面就简单对二者的特点进行一下分析:
两种算法原理简单利于程序化,实际应用范围广,求得全局最优解的概率大。其共同点是:两者都是概率搜索算法,搜索进程都具有非确定性。均需要平衡局部搜索与全局搜索,从而避免过早陷入局部搜索。算法的鲁棒性强,对目标函数及约束函数的形式没有严格要求,不需要其可导、连续等解析性质。两种算法均易于与其它启发式算法相融合。
模拟退火是采用单个个体进行优化,算法非常简单,可用于复杂的非线性问题的优化。采用较慢的退火过程,解的优化更不易陷入局部极小,然而较慢的退火过程会让收敛速度非常慢。模拟退火算法虽然能以一定概率接受较差解,从而具有跳出局部最优解的能力,但该算法对整个解空间的覆盖不够,最终解对初始参数的设置依赖性较大。模拟退火算法则具有较强的局部优化能力,但容易陷入局部极小值。
遗传算法是一种群体性算法,初始种群的好坏对解的收敛性及优化结果优劣有着重要影响。遗传算法全局搜索能力极强,能快速获得解空间的全体解集合;群体性算法具有内在的并行性,采用分布式并行计算非常方法。遗传算法的主要缺陷是局部搜索能力差,尤其是在优化后期搜索效率较低,增加了优化时间消耗。遗传算法存在的另一个问题是该算法需要对问题进行编码,求解结束时需要对问题解码,交叉率与变异率以及全体规模等参数的选择对算法性能影响很大,而合适值的选择通常对经验要求较高。对于结构复杂的组合优化问题,搜索空间大,不合适参数的选择会让优化陷入“早熟”。