npm和yarn安装机制及缓存
npm
npm安装机制
作为一个前端工程师,npm install可以说是最常用的命令之一。但是npm install是怎么work的呢,安装机制是什么样的呢?我们不光要会用,还要知道其原理。
npm的核心目标:
Bring the best of open source to you, your team and your company.> 给你和你的团队、你的公司带来最好的开源库和依赖。
npm安装流程如下: 
执行npm install之后,检查并获取npm配置,优先级为:
项目级.npmrc文件 > 用户级.npmrc文件 > 全局级.npmrc文件 > npm内置.npmrc文件
然后检查是否有package-lock.json文件:
如果有:则检查是否和package.json中声明的依赖版本一致。
- 如果一致,直接使用package-lock.json中的信息
- 如果不一致,按上图所示的处理。
如果没有package-lock.json文件,则根据package.json递归构建依赖树,然后按照构建好的依赖树下载依赖资源,下载时会查找是否有缓存:
如果有缓存,则直接将缓存内容解压到node_modules中。
如果没有缓存,则从npm远程仓库下载依赖,然后会检查包的完整性,放到缓存中,再解压到node_modules下。 最后生成package-lock.json。
构建依赖树时,不管是当前项目的直接依赖还是子依赖,都会按照扁平化的原则将其直接放在当前项目的node_modules下。在这个过程中,遇到相同模块就判断已在依赖树中的模块是否符合新模块的版本范围,如果符合则不会再次安装,直接跳过。不符合则会在当前包的node_modules再次安装。
npm缓存
查看npm缓存命令:npm config get cache。执行得到以下结果:

可以看到缓存在\tools\node12\node_cache目录下,我们进到此目录:
可以看到有三个目录: _cache、_locks、_logs。再进到_cache目录中:
其中有三个目录:content-v2、index-v5、tmp。
其中content-v2里面基本是一些二进制文件。为使这些文件可读,我们可以把文件做解压缩处理,得到的结果就是npm包资源。

而在index-v5中,我们采用同样的操作就可以获得一些描述性的文件,事实上这些内容就是content-v2里文件的索引。
那么这些缓存是如何被存储并被利用呢?
这就和npm install机制联系在了一起。当执行npm install时,通过pacote把相应的包解压到项目的node_modules下。npm下载依赖时,先下载到缓存中,再解压到node_modules中。pacote依赖npm-registry-fetch来下载包,npm-registry-fetch可以通过设置cache属性,在给定的路径下根据IETF RFC 7234生成缓存数据。
yarn
yarn安装机制
yarn的安装过程主要有5步,如下图:

检测包
这一步主要是检测项目中是否存在一些npm相关文件,比如package-lock.json等。如果有,会提示用户注意:这些文件的存在可能会导致冲突,在这一步中,也会检查系统OS、cpu等相关信息。
解析包
这一步会解析依赖树中每一个包的版本信息。
首先获取当前项目package.json中的dependencies、devDependencies、optionalDependencies中声明的依赖,这属于首层依赖。接着采用遍历依赖的方式获取依赖包的版本信息,以及递归查找每个依赖下子依赖的版本信息,并将解析过和正在解析的包用一个set数据结构来存储,这样就能保证同一个版本范围的包不会被重复解析。
对于没有解析过的包A,首次尝试从yarn.lock中获取版本信息,并标记为已解析。如果在yarn.lock中没有找到包A,则向registry发起请求获取满足版本范围的已知最高版本的包信息,获取后将当钱包标记为已解析。
在经过解析包这一步后,我们就获取到了所有包的具体版本信息及下载地址。
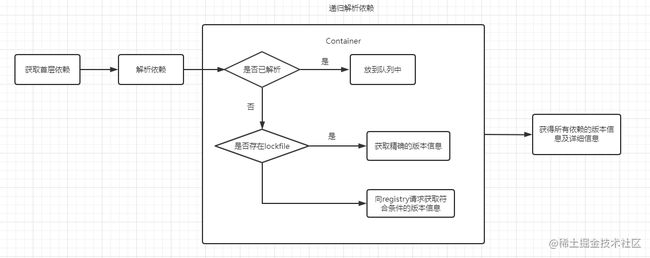
获取包
这一步首先要检查缓存中是否存在当前的依赖包,同时将缓存中不存在的包下载到缓存目录。说起来简单,但是还是有些问题值得思考。
比如:如何判断缓存中是否存在当前的依赖包?其实 Yarn 会根据 cacheFolder+slug+node_modules+pkg.name 生成一个 path,判断系统中是否存在该 path,如果存在证明已经有缓存,不用重新下载。这个 path 也就是依赖包缓存的具体路径。
对于没有命中缓存的包,Yarn 会维护一个 fetch 队列,按照规则进行网络请求(这也是yarn诞生之初解决npm v3安装缓慢的点,支持并行下载)。如果下载包地址是一个 file 协议,或者是相对路径,就说明其指向一个本地目录,此时调用 Fetch From Local 从离线缓存中获取包;否则调用 Fetch From External 获取包。最终获取结果使用 fs.createWriteStream 写入到缓存目录下。
链接包
上一步是将依赖下载到缓存目录,这一步是将所需依赖复制到项目node_modules下,同时遵循扁平化的原则。在复制依赖前,yarn会先解析peerDependencies,如果找不到符合peerDependencies的包,则进行warn提示,并最终拷贝依赖到项目中。
构建包
如果依赖包中存在二进制包需要编译,会在这一步进行。
yarn缓存
运行yarn cache dir查看yarn缓存目录:
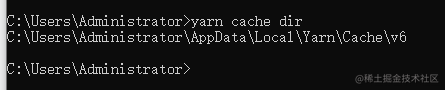
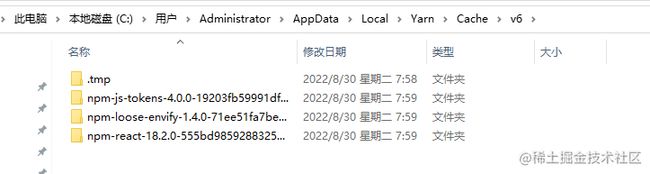
最后
整理了75个JS高频面试题,并给出了答案和解析,基本上可以保证你能应付面试官关于JS的提问。




有需要的小伙伴,可以点击下方卡片领取,无偿分享