分布式ID生成方案
分布式ID生成方案
在业务系统中很多场景下需要生成不重复的 ID,比如订单编号、支付流水单号、优惠券编号等都需要使用到。在我们业务数据量不大的时候,单库单表完全可以支撑现有业务,数据再大一点搞个MySQL主从同步读写分离也能对付。但随着数据日渐增长,主从同步也扛不住了,就需要对数据库进行分库分表,但分库分表后需要有一个唯一ID来标识一条数据,数据库的自增ID显然不能满足需求;特别一点的如订单、优惠券也都需要有
唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID。
一、mysql ID生成
1、基础版: 基于数据库的auto_increment自增ID完全可以充当分布式ID,具体实现:需要一个单独的MySQL实例用来生成ID,建表结构如下:
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (
id bigint(20) unsigned NOT NULL auto_increment,
value char(10) NOT NULL default '',
PRIMARY KEY (id),
) ENGINE=MyISAM;
insert into SEQUENCE_ID(value) VALUES ('values');
当我们需要一个ID的时候,向表中插入一条记录返回主键ID,但这种方式有一个比较致命的缺点,访问量激增时MySQL本身就是系统的瓶颈,用它来实现分布式服务风险比较大,不推荐!
优点:
- 实现简单,ID单调自增,数值类型查询速度快
缺点:
- 系统不能水平扩展,DB单点存在宕机风险
- 每次获取ID都需要获取数据库字段,加表锁,无法扛住高并发场景
2、改进版:号段模式
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(20) NOT NULL COMMENT '号段的布长',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
)
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
二、redis ID生成
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。redis incr操作最大支持在64位有符号的整型数字。提醒:这是一个string操作,因为Redis没有专用的数字类型。key对应的 string都被解释成10进制64位有符号的整型来执行这个操作。
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF
RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
缺点:
- redis 宕机后不可用,RDB重启数据丢失会重复ID
- 自增,数据量易暴露。
优点:
- 使用内存,并发性能好
三、UUID
UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。通常平台会提供生成的API。按照制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片ID码和随机数
UUID由以下几部分的组合:
- 当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同
- 时钟序列
- 全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得
- 在 hibernate(Java orm框架)中, 采用: IP-JVM启动时间-当前时间右移32位-当前时间-内部计数(8-8-4-8-4)来组成UUID
UUID的唯一缺陷在于生成的结果串会比较长。UUID具有以下涵义:
- 经由一定的算法机器生成
为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成UUID的算法。UUID的复杂特性在保证了其唯一性的同时,意味着只能由计算机生成
- 非人工指定,非人工识别
UUID是不能人工指定的,除非你冒着UUID重复的风险。UUID的复杂性决定了一般人不能直接从一个UUID知道哪个对象和它关联
- 在特定的范围内重复的可能性极小
UUID的生成规范定义的算法主要目的就是要保证其唯一性。但这个唯一性是有限的,只在特定的范围内才能得到保证,这和UUID的类型有关(参见UUID的版本)。
缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键或者索引的场景下,UUID就非常不适用
四、雪花算法
SnowFlake可以保证所有生成的ID按时间趋势递增整个分布式系统内不会产生重复ID
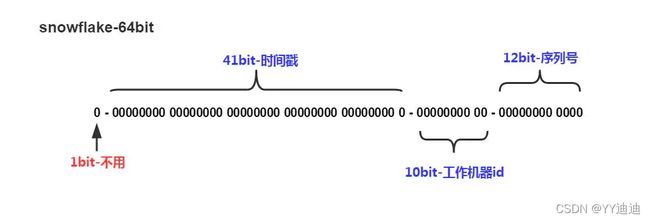
- 1.第一位 占用1bit,其值始终是0,确保ID是正数。
- 2.时间戳 占用41bit,精确到毫秒,总共可以容纳约69年的时间。
- 3.工作机器id 占用10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,做多可以容纳1024个节点。
- 4.序列号 占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。以表示的最大正整数是4095,即可以用0、1、2、3、…4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。用来表示在同一毫秒内产生ID的个数,最多产生4095个ID,多余的需要等到下一毫秒生成
雪花算法缺点:
1)依赖机器时钟,如果机器时钟回拨,会导致重复ID生成
2)在单机上是递增的,但是由于设计到分布式环境,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况(此缺点可以认为无所谓,一般分布式ID只要求趋势递增,并不会严格要求递增~90%的需求都只要求趋势递增)
时钟回拨解决方案:

- 算法中记录上一次生成的时间戳,发现有时间回退时,将时间回拨位加 1,继续生成 ID。这样虽然时间戳字段的值可能和之前的一样,但是回拨位的值不一样,生成的 ID 是不会重复的。如果系统的时间超过了上一次的回退时间后可以把回拨位归 0。一位回拨位可以允许系统时间回退一次,两位回拨位可以允许系统时间连续回退三次。一般设置一位回拨位就够用了。
- 算法记录上一次生成的时间戳,发现有时间回退时,降级为数据库形式获取。
五、ID缓冲环
为了提高 SnowflakeID 的并发性能和可用性,可以使用 ID 缓冲环(即 ID Buffer Ring)。提高并发性提现在通过使用缓冲环能够充分利用毫秒时间戳,提高可用性提现在可以相对缓解由时钟回拨导致的服务不可用。缓冲环是通过定长数组加游标哈希实现的,相比于链表会不需要频繁的内存分配。
- 在 ID 缓冲环初始化的时候会请求 ID 生成器将 ID 缓冲环填满。
- 当业务需要获取 ID 时,从缓冲环的头部依次获取 ID。
- 当 ID 缓冲环中剩余的 ID 数量少于设定的阈值百分比时,比如剩余 ID 数量少于整个 ID 缓冲环的 30% 时,触发异步 ID 填充加载。异步 ID 填充加载会将新生成的 ID 追加到 ID 缓冲环的队列末尾,然后按照哈希算法映射到 ID 缓冲环上。
- 另外有一个单独的定时器异步线程来定时填充 ID 缓冲环。