深度学习算法与深度神经网络
Introduction to Neural Networks
神经网络导论
● Neural network is a functional unit of deep learning.
●神经网络是深度学习的功能单元。
● Deep Learning uses neural networks to mimic human brain activity to solve complex data-driven problems.
●深度学习使用神经网络来模仿人的大脑活动,以解决复杂的数据驱动问题。
● A Neural Network functions when some input data is fed to it.This data is then processed via layers of Perceptions to produce a desired output.
●当输入一些输入数据时,神经网络就会起作用。然后,通过感知层对该数据进行处理,以产生所需的输出。
● There are three layers.
●三层。
○ Input Layer
○输入层
■ Input layer brings the initial data into the system for further processing by subsequent layers of artificial neurons.
■输入层将初始数据带入系统,以供后续人工神经元层进一步处理。
○ Hidden Layers
○隐藏层
■ Hidden layer is the layer between input and output layer,where artificial neurons take in a set of weighted inputs and produce an output through an activation function.
■隐藏层是输入和输出层之间的层,人造神经元在其中吸收一组加权输入并通过激活函数产生输出。
○ Output Layer
○输出层
■ Output layer is the last layer of neurons that produces given outputs for program.
■输出层是产生给定程序输出的神经元的最后一层。
● Let’s understand neural networks with example.
●让我们以示例了解神经网络。
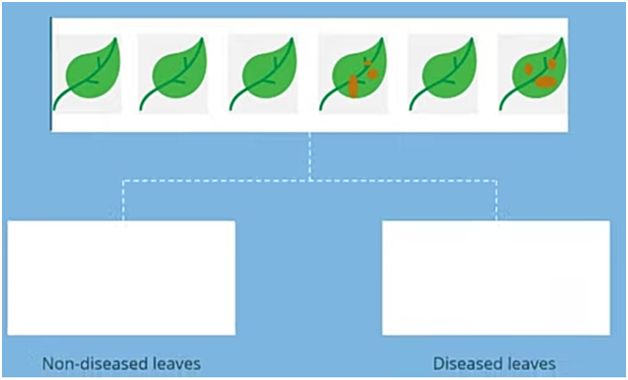
● Suppose we have to classify the leaf images as either diseased or no — diseased.
●假设我们必须将叶片图像分类为有病或无病。
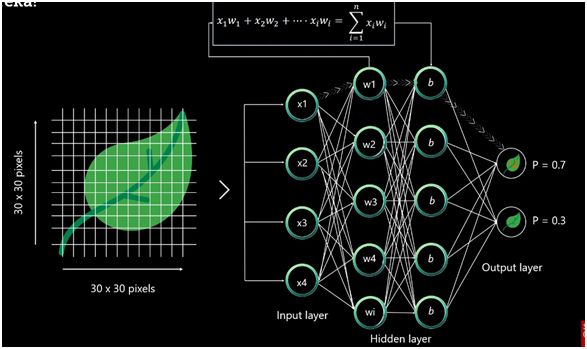
● Then each leaf image will be broken down into pixels depending on the dimencial of the image.For example if images compose 30 * 30 pixels then the total number of pixels will be 900.
●然后,根据图像的尺寸,将每个叶子图像分解为像素。例如,如果图像组成30 * 30像素,则像素总数将为900。
● These pixels are later represented as matrices which are then fed into the input layer of the neural network.
●这些像素随后被表示为矩阵,然后被馈送到神经网络的输入层。
● A perceptron is a neural network unit (an artificial neuron) that does certain computations to detect features or business intelligence in the input data.
●感知器是神经网络单元(人工神经元),它进行某些计算以检测输入数据中的功能或商业智能。
● Our brains have neurons for building and connecting the thoughts just like that artificial neural network has perceptrons that accept inputs and process them by passing them on from the input to the hidden layer and finally to the output layer.
●我们的大脑具有神经元,用于建立和连接思想,就像人工神经网络具有感知器一样,它们接受输入并通过将其从输入传递到隐藏层并最终传递到输出层来对其进行处理。
● As the input is passed to the from input layer to the hidden layer an initial random rate is assigned to each input.
●当输入从输入层传递到隐藏层时,会为每个输入分配初始随机速率。
● The inputs are then multiplied with their corresponding weights and then the sum is further processed to the network.
●然后将输入乘以其相应的权重,然后将总和进一步处理到网络。
● Then assign an additional value called bias to each perceptron.
●然后为每个感知器分配一个称为“ bias”的附加值。
● After the perceptron is passed through the activation function or we can say that transformation function that determines whether a particular perceptron gets activated or not.
●感知器通过激活函数传递后,或者可以说该转换函数确定特定感知器是否被激活。
● The activated perceptron is used to transfer data to the next layer.In this way the data is propagated forward through the neural network until the perceptron reaches the output layer.
●激活的感知器用于将数据传输到下一层。这样,数据将通过神经网络向前传播,直到感知器到达输出层。
● The probability is decided at the output layer which determines whether the data belongs to class A or class B.
●在输出层确定概率,该输出层确定数据属于A类还是B类。
● Let’s assume a case where the predicted output is wrong.In such case,we train the neural network by using the backpropagation method.
●假设预测输出错误。在这种情况下,我们使用反向传播方法训练神经网络。
● Initially while designing the neural networks we initialize the weights to each input with some random values.
●最初,在设计神经网络时,我们使用一些随机值初始化每个输入的权重。
● The importance of each input variable denoted by weights
●以权重表示的每个输入变量的重要性
● So in the backpropagation method we propagate backward to the neural network and compare the actual output with the predicted output then readjust the weights.of each input in such a way that error is minimized.
●因此,在反向传播方法中,我们向后传播到神经网络,将实际输出与预测输出进行比较,然后重新调整每个输入的权重,以使误差最小化。
● Some Real world Application of Neural network in real world
●神经网络在现实世界中的一些实际应用
○ With the help of deep learning techniques google can instantly translate between more than 100 different human languages.
○借助深度学习技术,Google可以立即在100多种不同的人类语言之间进行翻译。
○ With the help of Neural Networks, self-driving cars are being perfected from Tesla to Google owned by WAYMO. Virtual assistants are exclusively based on technologies such as deep learning, machine learning and natural language processing.
○在神经网络的帮助下,从特斯拉到WAYMO拥有的Google,无人驾驶汽车正在得到完善。 虚拟助手完全基于深度学习,机器学习和自然语言处理等技术。
● Activation and Loss functions
●激活和丢失功能
● Activation Function
●激活功能
○ Non linearity is also called activation function in machine learning.
○非线性在机器学习中也称为激活函数。
○ Activation function determines whether or not to activate a neuron by measuring weighted total and applying bias with it.
○激活功能通过测量加权总数并对其施加偏倚来确定是否激活神经元。
○ The purpose of the activation function is to introduce non-linearity into the output of a neuron.
○激活功能的目的是将非线性引入神经元的输出。
○ The activation function of a neuron defines the output of that neuron given set of inputs.
○神经元的激活功能在给定输入集的情况下定义该神经元的输出。
○ There are seven types of activation functions that we can use when building a neural network.
○构建神经网络时,可以使用七种类型的激活函数。
○ Activation functions:
○激活功能:
■ Binary step function
■二进制步进功能
● Formula: f(x) = 1 if x > 0 else 0 if x < 0
●公式:如果x> 0,则f(x)= 1;如果x <0,则f(x)= 0

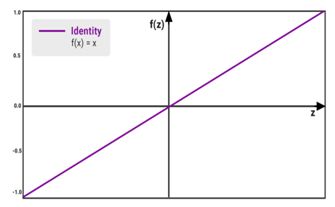
■ The linear or identity function
■线性或恒等函数
● Formula: Y = mZ
●公式:Y = mZ
■ Sigmoid or logistic function
■sigmod或后勤功能
● Formula:f(x) = 1/(1+e(-x) )
●公式:f(x)= 1 /(1 + e(-x))
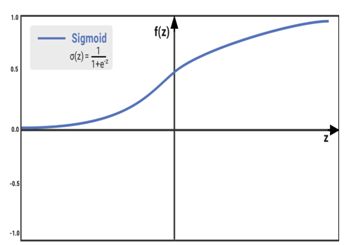
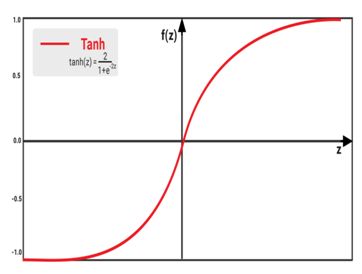
■ Hyperbolic tangent or tanh function
■双曲正切或正切函数
● Formula:tanh(z)=2/(1+e-2x)
●公式:tanh(z)= 2 /(1 + e-2x)
■ Hyperbolic tangent or tanh function
■双曲正切或正切函数
● Formula:tanh(z)=2/(1+e-2x)
●公式:tanh(z)= 2 /(1 + e-2x)
■ The rectified linear unit(ReLU) function
■整流线性单元(ReLU)功能
● Formula:f(z)=max(0,z)
●公式:f(z)= max(0,z)

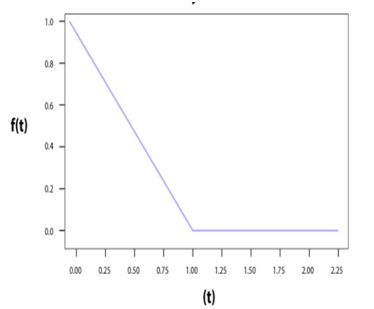
■ The leaky ReLU function
■泄漏的ReLU功能
■ The softmax function
■softmax功能
Formula-
式-
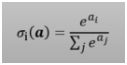
● It’s graph is different every time .
●每次的图都不一样。
● Loss Function
●损失函数
○ The loss function is one of the essential components of Neural Networks.
○损失函数是神经网络的重要组成部分之一。
○ Loss is nothing but a predictive error of Neural Net. And the process to measure the loss is called Loss Function.
○损失不过是神经网络的预测误差。 测量损失的过程称为损失函数。
○ The Loss is used to measure the gradients. And gradients are used to adjust the weights of the neural net. There are several common loss functions given by theanets.
○损耗用于测量梯度。 并且使用梯度来调整神经网络的权重。 前言给出了几种常见的损失函数。
○ The theanets package provides tools for defining and optimizing several common types of neural network models
○theanets软件包提供了用于定义和优化几种常见类型的神经网络模型的工具
○ These losses often measure the squared or absolute error between a network’s output and some target or desired output. Other loss functions are designed specifically for classification models; the cross-entropy is a common loss designed to minimize the distance between the network’s distribution over class labels and the distribution that the dataset defines.
○这些损耗通常衡量网络输出与某些目标或所需输出之间的平方误差或绝对误差。 其他损失函数是专门为分类模型设计的; 交叉熵是一种常见的损失,旨在使网络在类标签上的分布与数据集定义的分布之间的距离最小。
○ Models in theanets have at least one loss to optimize during trainingThere are default losses for the built-in model types, but we can also override such defaults only by providing a non-default value for the loss keyword argument. when creating your model. For example, to create a regression model with a mean absolute error loss:
○训练中,模型中的模型至少有一个损失需要优化。内置模型类型存在默认损失,但是我们也可以仅通过为loss关键字参数提供非默认值来覆盖此类默认值。 在创建模型时。 例如,要创建具有平均绝对误差损失的回归模型:

● There are some loss functions available for neural network models.
●神经网络模型有一些损失函数。

● Gradient Descent
●梯度下降
○ Gradient descent makes our network to learn.
○梯度下降使我们的网络得以学习。
○ Basically gradient descent calculates by how much our weights and biases should be updated to so that our cost reaches 0.This is done using partial derivatives.
○基本上,梯度下降是通过将我们的权重和偏差更新为多少才能使我们的费用达到0来计算的,这是使用偏导数完成的。
○ Gradient descent is based on the fact that the minimum value of a function ,its partial derivative will equal to zero.
○梯度下降基于以下事实:函数的最小值,其偏导数将等于零。
○ Cost depends on the weights and bias values in our layer. This derivative of cost with respect to weights and biases.
○成本取决于图层中的权重和偏差值。 权重和偏差的成本导数。
○ The equation used to make this update is called the learning equation.
○用于进行此更新的方程式称为学习方程式。
● Batch Normalization
●批量归一化
● Normalization and standardization have the same goal of transforming the data to put all the data points on the same scale.
●标准化和标准化具有转换数据以使所有数据点处于相同比例的相同目标。
● A typical normalization process consists of scaling numerical data down to be on a scale from zero to one, and a typical standardization process involves of subtracting the mean of the dataset from each data point, and then dividing that difference by the data set’s standard deviation.
●典型的标准化过程包括将数值数据按比例缩小到从零到1的比例,典型的标准化过程包括从每个数据点减去数据集的平均值,然后将该差除以数据集的标准偏差。 。
● By normalizing our inputs ,we put all our data into the same scale that increases training speed.
●通过归一化我们的输入,我们将所有数据放入相同的标度,以提高训练速度。
● But in a neural network one other problem arises with normalized data.
●但是在神经网络中,归一化数据会引起另一个问题。
● In the neural network, the weights in the model become updated over each epoch during training via the process of stochastic gradient descent.
●在神经网络中,模型中的权重在训练过程中通过随机梯度下降过程在每个时期更新。
● The problem occurs when during training, one of the weights ends up becoming drastically larger than the other weights.
●在训练过程中,其中一个重物变得比其他重物大得多时,就会出现问题。
● This large weight will then cause the output from its corresponding neuron to be extremely large, and this imbalance will, again, continue to cascade through the network, causing instability, So that we have to use Batch normalization.
●如此大的权重将导致其相应神经元的输出变得非常大,并且这种不平衡将再次通过网络继续级联,从而导致不稳定,因此我们必须使用批处理归一化。
● Process Of Batch Normalization
●批次归一化的过程
○ Normalize the output from the activation function.
○归一化激活功能的输出。
■ z=(x-mean)/std
■z =(x均值)/ std
○ Multiply normalized output z by arbitrary parameter g.
○归一化输出z乘以任意参数g。
■ z * g
■z * g
○ Add arbitrary parameter b to resulting product (z * g)
○将任意参数b添加到结果乘积(z * g)
Tensorflow and Keras For neural Network
Tensorflow和Keras用于神经网络
Introduction To Tensorflow
Tensorflow简介
● The official definition of tensorflow is “TensorFlow is an open source software library for numerical computation using dataflow graphs. Nodes in the graph represents mathematical operations, while graph edges represent multidimensional data arrays (aka tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API.”
●张量流的正式定义是“ TensorFlow是一个开源软件库,用于使用数据流图进行数值计算。 图中的节点表示数学运算,而图的边缘表示在它们之间通信的多维数据数组(即张量)。 灵活的体系结构允许您使用单个API将计算部署到台式机,服务器或移动设备中的一个或多个CPU或GPU。
● Installation Of Tensorflow:
●Tensorflow的安装:
○ We can install tensorflow using the following command: “ pip install tensorflow”
○我们可以使用以下命令安装tensorflow:“ pip install tensorflow”
● Basic Components:
●基本组成:
○ Tensor:
○张量:
■ Tensors are the basic data structure in TensorFlow which store data in any number of dimensions, like to multi dimensional arrays in NumPy. There are three main types of tensors: constants, variables, and placeholders
■Tensor是TensorFlow中的基本数据结构,可存储任意数量的维度的数据,例如NumPy中的多维数组。 张量主要有三种类型:常量,变量和占位符
■ Constants are immutable types of tensors. They may be seen as nodes without inputs, outputting a single value they store internally.
■常数是张量的不变类型。 它们可能被视为没有输入的节点,输出的是它们在内部存储的单个值。
■ Variables are mutable types of tenors whose value can alter during a run of a graph. In ML applications, the variables typically store the parameters which need to be optimized (eg. the weights between nodes in a neural network). Variables need to be initialized before running the graph by explicitly calling a special operation.
■变量是可变的期限,其值可以在图形运行期间改变。 在ML应用中,变量通常存储需要优化的参数(例如,神经网络中节点之间的权重)。 在运行图形之前,需要通过显式调用特殊操作来初始化变量。
■ Placeholders are tensors which store data from external sources. They represent a “promise” that a value will be given when the graph is run. In ML applications, placeholders are usually used for inputting data to the learning model.
■占位符是张量,用于存储来自外部源的数据。 它们表示一个“承诺”,即在运行图形时将给出一个值。 在ML应用程序中,占位符通常用于将数据输入到学习模型中。

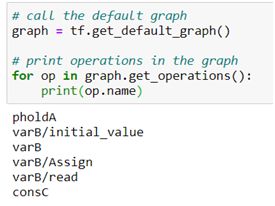
● Graph:
●图表:
○ A graph is basically an arrangement of nodes that represent the operations in our model
○图基本上是表示我们模型中的操作的节点排列
○ The graph is composed of a series of nodes connected to each other by edges . Each node in the graph is called operation. So we’ll have one node for each operation; either for operations on tensors (like math operations) or generating tensors (like variables and constants).
○该图由通过边彼此连接的一系列节点组成。 图中的每个节点称为操作。 因此,每个操作只有一个节点; 用于张量运算(如数学运算)或生成张量(如变量和常量)。
● Sessions
●会议
○ Our graph should be run inside a session. Variables are initialized beforehand, while the placeholder tensor receives concrete values through the feed_dict attribute.
○我们的图形应在会话内运行。 变量是预先初始化的,而占位符张量则通过feed_dict属性接收具体值。

Sample Code for create and train a tensorflow model of a neural network.
用于创建和训练神经网络的张量流模型的示例代码。
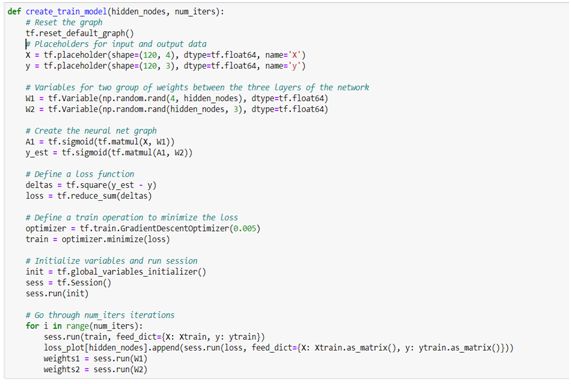
● Introduction To Keras:
● Keras简介:
○ Keras is a simple-to-use but powerful deep learning library for Python.
○Keras是一个简单易用但功能强大的Python深度学习库。
○ Keras is high level API building deep learning models.
○Keras是构建深度学习模型的高级API。
○ Building a complex deep learning model can be achieved by keras with only a few lines of code.
○仅需几行代码即可由keras实现构建复杂的深度学习模型。
○ Keras normally runs tops of low level library such as tensorflow So we have to first install and import the tensorflow.
○Keras通常在tensorflow等底层库的顶部运行,因此我们必须首先安装并导入tensorflow。
○ Different types of model in keras:
○喀拉拉邦的不同类型的模型:
○ Sequential API:
○顺序API:
■ It’s basically like a linear stack of models.
■基本上就像线性的模型堆栈一样。
■ It is best for a simple stack of layers which have 1 input tensor and 1 output tensor.
■最好是具有1个输入张量和1个输出张量的简单图层堆栈。
■ It is more useful for building simple models like
■它对于构建诸如
● Simple classification network
●简单的分类网络
● Encoder-decoder model
●编解码器型号
■ This model is not suited when any of the layers in the stack has multiple inputs or outputs. If we want non-linear topology,then also it is not suited.
■当堆栈中的任何层具有多个输入或输出时,此模型不适用。 如果我们想要非线性拓扑,那么它也不适合。

○ Functional API:
○功能性API:
■ It provides more flexibility to define a model and add layers in keras. Functional API lets us to build models with multiple input or output. It also allows us to share these layers. In other words. We can make graphs of layers using Keras functional API.
■它提供了更大的灵活性来定义模型和在keras中添加图层。 通过功能API,我们可以构建具有多个输入或输出的模型。 它还允许我们共享这些层。 换一种说法。 我们可以使用Keras功能API制作图层图。
As a functional API is a data structure, it is easy to save it as a single file that helps in recreating the exact model without having the original code. Also it’s easy to model the graph here and access its nodes as well.
由于功能性API是数据结构,因此很容易将其保存为单个文件,从而无需原始代码即可帮助重新创建精确的模型。 同样,在此处对图进行建模并访问其节点也很容易。

○ Steps For implementing neural network with keras
○使用keras实现神经网络的步骤
■ Prepare input:
■准备输入:
● Preparing the input an specify the input dimensional(size)
●准备输入并指定输入尺寸(尺寸)
● Images,videos,text and audio
●图片,视频,文字和音频
■ Define the ANN model
■定义ANN模型
● In this we have to define the model architecture and build the computational graph
●在此,我们必须定义模型架构并构建计算图
● Sequential or Functional Style
●顺序样式或功能样式
● MLP,CNN,RNN
●MLP,CNN,RNN
■ Optimizers
■优化器
● Specify the optimizer and configure the learning process
●指定优化器并配置学习过程
● SGD,RMSprop,Adam
●SGD,RMSprop,亚当
■ Loss Function
■损失函数
● Specify the inputs.Outputs of the computational graph (model) and the Loss function
●指定输入。计算图(模型)和损失函数的输出
● MSE,Cross Entropy,Hinge
●MSE,交叉熵,铰链
■ Train and Evaluate Model
■训练和评估模型
● Train the model based on the training data
●根据训练数据训练模型
● And test the model on the dataset with the testing data.
●并使用测试数据在数据集上测试模型。
○ Sample Code
○样本代码

Hyper Parameter Tuning
超参数调整
● Hyperparameters are types of parameters that can not be run directly from a regular training process.
●超参数是不能直接在常规训练过程中运行的参数类型。
● Generally they are set before starting the actual training phase.
●通常在开始实际培训阶段之前就已设置好它们。
● These parameters express important properties of the model such as its complexity or how fast it should learn.
●这些参数表示模型的重要属性,例如模型的复杂性或学习的速度。
● Examples of Hyperparameters are:
●超参数的示例包括:
○ The penalty in Logistic Regression Classifier i.e. L1 or L2 regularization
○Logistic回归分类器中的惩罚,即L1或L2正则化
○ The learning rate for training a neural network.
○训练神经网络的学习率。
○ Hyperparameters for support vector machines are C and sigma.
○支持向量机的超参数是C和sigma。
○ The k in k-nearest neighbors.
○k个近邻中的k。
● There are two best hyperparameter tuning techniques.
●有两种最佳的超参数调整技术。
○ GridSearchCV
○GridSearchCV
■ In the GridSearchCV approach, machine learning models are evaluated for a range of hyperparameter values. This approach is called GridSearchCV, because it searches for the best set of hyperparameters from a grid of hyperparameter values.
■在GridSearchCV方法中,针对一系列超参数值评估了机器学习模型。 这种方法称为GridSearchCV,因为它从超参数值的网格中搜索最佳的超参数集。
■ For example, if we want to set two hyperparameters C and Alpha of Logistic Regression Classifier model, with different sets of values.
■例如,如果要设置两个Logistic回归分类器模型的超参数C和Alpha,并使用不同的值集。
The grid search technique constructs many versions of the model with all possible hyperparameter combinations, and returns the best one. For C = [0.1, 0.2 , 0.3 , 0.4, 0.5] and for Alpha = [0.1, 0.2 , 0.3 , 0.4], as shown in the picture. For a combination C=0.3 and Alpha=0.2, the output score is 0.726(Highest), thus it is chosen.
网格搜索技术使用所有可能的超参数组合构造模型的许多版本,并返回最佳版本。 如图所示,对于C = [0.1,0.2,0.3,0.4,0.5],对于Alpha = [0.1,0.2,0.3,0.4]。 对于C = 0.3和Alpha = 0.2的组合,输出得分为0.726(最高),因此选择该得分。

○ RandomizedSearchCV
○RandomizedSearchCV
■ RandomizedSearchCV solves GridSearchCV’s disadvantages, since it only passes a fixed number of hyperparameter settings. In random fashion it travels inside the grid to find the best set of hyperparameters.. This approach reduces unnecessary computation.
■RandomizedSearchCV解决了GridSearchCV的缺点,因为它仅传递固定数量的超参数设置。 它以随机方式在网格内移动以找到最佳的超参数集。此方法减少了不必要的计算。

If you liked the story and want to appreciate us you can clap as much as you can. Appreciate our work by your constructive comment and also you can connect to us on….
如果您喜欢这个故事并想欣赏我们,您可以尽可能多地鼓掌。 通过您的建设性评论赞赏我们的工作,也可以在...上与我们联系。
Youtube: https://www.youtube.com/channel/SocietyOFAI
YouTube: https : //www.youtube.com/channel/SocietyOFAI
LinkedIn : https://www.linkedin.com/company/society-of-ai
领英: https : //www.linkedin.com/company/society-of-ai
Facebook: https://www.facebook.com/societyofai/
面子书: https : //www.facebook.com/societyofai/
Website : https://www.societyofai.in/
网址: https : //www.societyofai.in/
翻译自: https://medium.com/@societyofai/introduction-to-neural-networks-and-deep-learning-6da681f14e6
深度学习算法与深度神经网络