自动泊车停车位检测算法
转自:https://zhuanlan.zhihu.com/p/522630354
一、背景介绍
自动泊车大体可分为4个等级:
-
第1级,
APA 自动泊车:驾驶员在车内,随时准备制动,分为雷达感知和雷达+视觉感知两种方式。 -
第2级,
RPA 远程泊车:驾驶员在车外,通过手机APP的方式控制泊车。 -
第3级,
HPA 记忆泊车:泊车之前先通过 SLAM对场景建模,记忆常用的路线。泊车时,从固定的起点出发,车辆自行泊入记忆的停车位。 -
第4级,
AVP 自主泊车:泊车之前先通过 SLAM对场景建模,记忆常用的路线。泊车的起点不再固定,可以在停车场的任意位置开始,需要室内定位技术做支撑。
本文分享第1级相关的车位检测算法。
1.1 自动泊车

自动泊车,在21世纪20年代的今天,是智能出行、辅助驾驶的强有力的一环。自动泊车就鲁棒性和安全性而言,需要分为视觉和测距同时发生作用。其中视觉当然是用深度学习,而测距一般采用雷达。视觉在寻找车位阶段作为主力,而倒车入库时,测距(雷达)发生作用。
1.2 车位检测
车位检测的场景一般在车库、户外,而自动泊车这一应用在都市商场车库和都市户外车位实用性比较高,这样可节省时间方便出行。车位检测需要汽车进入到有车位的区域后,汽车慢速行驶的过程中,开始检测。

1.3 鱼眼相机
车身周围一般有4路鱼眼相机:前、后、左、右共四个。用来拍摄车周围的画面。如下图所示为车右边的鱼眼相机拍摄的画面。鱼眼相机拍摄的图一般不用来做车位检测,但可以用来后续做障碍物检测。


1.4 AVM
4幅鱼眼相机拍摄的画面会经过Around View Monitor(AVM)处理,生成一个拼接后的鸟瞰图,车位检测就是在AVM处理后的照片上进行的。4幅畸变的图,先要去畸变再做融合,这里是一块相当有意思的部分,甚至我觉得上限远高于车位检测,车位检测的质量也由上游的AVM决定,可谓自动泊车中得AVM者得天下。另外,有效的做法可以采取在4幅拍摄的画面去畸变后,单独采用4幅独立的图送入车位检测网络中进行处理,而不是一张整个大图。如下的鸟瞰图的宽长是经过我们实际工程处理中,采取的宽高像素比例,大小需要根据硬件条件和实际够用范围进行调整。

1.5 工程化
车位检测算法搭出来以后,工程化的道路才刚刚开始,好戏还在后面,需要团队配合了。本文就不涉及这一范畴了。
二、车位检测算法的相关工作
车位检测算法,从21世纪开始说起,那一定是由传统的视觉过渡到深度视觉。
2.1 传统视觉的车位检测
传统视觉的介绍,这里用一些示意图来展示:

en… 如上两图所示,利用一些算子和图像处理的手段,先提特征,再后处理。接下来,再介绍一个比较复杂,但是比较典型的方法(2012年的):Fully-automatic recognition of various parking slot markings in Around View Monitor (AVM) image sequences 利用AVM图,它是先检测车位角点,再后处理配对,一些过滤和纠正操作,最终从图中抓出车位。图如下:


接下来介绍一个DBSCAN的方法(2016年),DBSCAN是什么,以下来自维基百科: 英文全写为Density-based spatial clustering of applications with noise ,是在 1996 年由Martin Ester, Hans-Peter Kriegel, Jörg Sander 及 Xiaowei Xu 提出的聚类分析算法, 这个算法是以密度为本的:给定某空间里的一个点集合,这算法能把附近的点分成一组(有很多相邻点的点),并标记出位于低密度区域的局外点(最接近它的点也十分远),DBSCAN 是其中一个最常用的聚类分析算法,也是其中一个科学文章中最常引用的。在 2014 年,这个算法在领头数据挖掘会议 KDD 上获颁发了 Test of Time award,该奖项是颁发给一些于理论及实际层面均获得持续性的关注的算法。
一看到这个解释就头大,看看图吧,非深度方法的处理确实很费神。这个方法,采取了线段检测,可利用的特征更多了,感觉好像也更复杂了。


看到上图的线段检测结果,各位观众大佬爷想来一波后处理吗(滑稽…) 反正我是不会 。
传统视觉的车位检测介绍就到这儿,方法还有很多,其实不必太关心。
但是可供深度学习借鉴的有:(1)角点检测;(2)线段检测;(3)后处理过滤、平滑、配对;(4)帧与帧直接的预测,即通过推算当前帧得出下一帧的车位位置;(5)在AVM成像的鸟瞰图上进行处理,降低难度;(6)车位类型的分类;(7)车位角点和线段的分类;(8)穷举。
2.2 深度时代的车位检测
我们可以在传统视觉处理的基础上,直接替换传统视觉算子,用深度学习的网络提特征,来一波传统向深度过渡的过程。犹如 RCNN(提特征+SVM分类) -> Fast RCNN(端到端+ROI) -> Faster RCNN (RPN+性能强劲+快);这样的流程一点一点,拿掉传统的处理,一点一点进行深度学习模块的设计和整合;然后再由两阶段到单阶段的过渡(Faster RCNN -> SSD -> RetinaNet -> yolo serials)。最后用完全体的深度学习网络,确定车位检测的最终解决方案。

来个效果视频吧,前面的介绍看着都看累了,看看我们做的,这个是一版还很粗糙的实测测试,无任何后处理(可以无NMS),网络直出。整个网络41FLOPS,0.28M参数,(python版本量化前): backbone14MFLOPs,head26MFLOPs。这里采用的单路鱼眼相机去畸变图,并把输入处理到384和128分辨率。单阶段。视频中有闪,AVM图的处理受限于各种状况,工程难度高。后续解决的,这里就不放了。我们主要介绍车位检测这一通用的方法。然后运算量和参数量怎么设计就怎么设计。

先介绍以往的工作。我们分三种大类来概述(1)目标检测;(2)语义分割;它们的结合;(3)Transformer查询;
目标检测的处理,一般是通过检测车位角点、车位整个bounding box和检测线段(一般不会这样做)。
检测车位角点的paper比较多,取3个方法来图示说明。
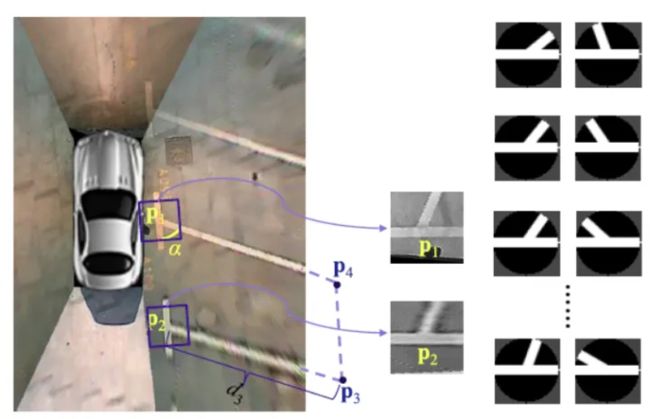


论文:DMPR-PS: A Novel Approach for Parking-Slot Detection Using Directional Marking-Point Regression
角点检测一般会带上分类信息和角度信息,传统的模板匹配到深度学习的分类,进化可见一斑。
用检测框的方法居多,因为,这样是直接利用目标检测的bounding_box框来框停车位,简直不要太好用。
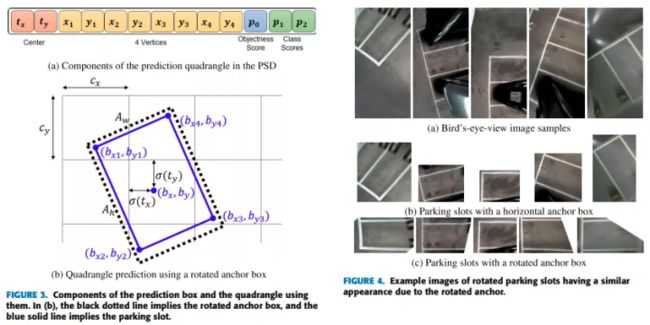
论文2:Context-Based Parking Slot Detection With a Realistic Dataset
上图是回归一个bounding_box框的做法,带有角度信息,这个框的处理是可以是四边形的,不一定非得矩形,可以有不同的夹角(小于90度),有点意思,不过需要做些限制处理,轻微的后处理。
回归框的做法很典型,只取上述图一篇Context-Based Parking Slot Detection With a Realistic Dataset,细微差异的方法确实会有很多,不一一介绍了。


看哇,很多。21年的没整理成案,就不贴了。
接下来贴一下,语义分割方法的示意图:

论文:VH-HFCN based Parking Slot and Lane Markings Segmentation on Panoramic Surround View
语义分割,采用这种方法的童鞋可能纠结于后处理吧。


图23和图24是2021年的一篇文章:
论文:End-to-End Trainable One-Stage Parking Slot Detection Integrating Global and Local Information
如果端到端单阶段的算法,需要以这种看起来复杂的后处理为代价,还是挺佩服作者的。

这里介绍个2021年的别出心裁的方法:
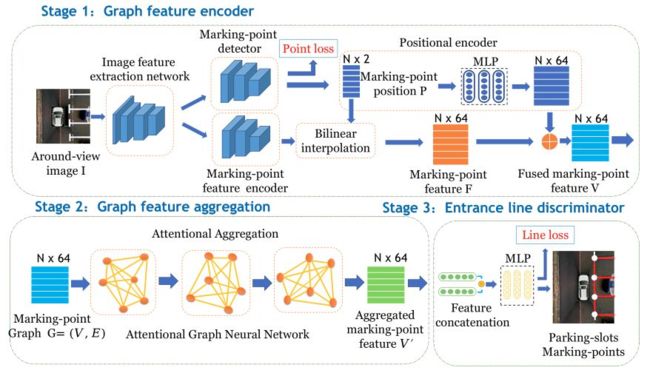
github源码:https://link.zhihu.com/?target=https%3A//github.com/Jiaolong/gcn-parking-slot
Transformer来一波:
2021年,Order-independent Matching with Shape Similarity for Parking Slot Detection
用Transformer(DETR)来做,实在没必要
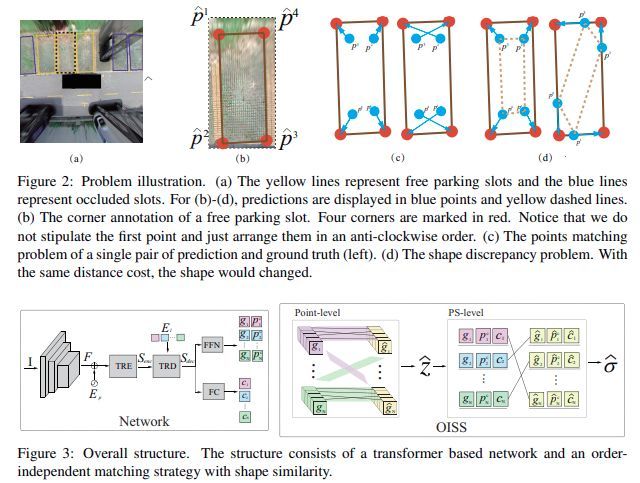

效果也没见到好到哪里去,难度车位图也没贴。此条路,工程化不容易的。
三、我们的方法
花了大量篇幅介绍前人的工作,无外乎是为了引出我们的工作。
先贴下图吧:

再来个视频:

我们的方法,我们把它命名为通用停车位检测,简称为GPSD。
在正式介绍之前,先解释为什么要做这一件事。
3.1 为什么还要重复造轮子?
可能是因为前人的方法不够好,可能是自己复现不了,可能是吃数据集,可能是不够简单粗暴稳准狠,也可能是泛化性能不强,总之,有各种各样的原因。
理性的说:车位数据集越来越复杂的情况下,一旦沾有分类和利用车位标线(就是车位最常见的白色的线),这就注定了算法吃数据集。一家车企要hold住每年上百万的销量如果还带有优质的自动泊车,那么它的自动泊车算法(或工程)得有多鲁棒啊,但一般来说,只给正确结果,要出错难度车位它不检就是:)。AVM的成像质量也影响着车位检测算法的准确度上限,但AVM成像受制于鱼眼相机的拍摄,畸变矫正的插值本就是难为了AVM了,是系统误差!试想,在商场车库中(比较常见吧)这个场景,鱼眼相机远处拍到了一堆,给你来一堆立体停车位,整个一块钢板,还上下层,灯光有偏暗,地面还反光,去畸变插值拼接后,这个要去抽取角点特征?要去抽取车位标线?可能用bounding_box加数据train来得痛快吧。
感性的说:实际中的情况是,车位会受各种现实情况的影响。如磨损,各种花哨的样式,遮挡(AVM成像本身就有临近车身畸变遮挡车位),甚至没有标线。反正就是非理想的车位,非理想的停车环境。这时,做好这些车位检测,或者说是工程应对,才能使车使自动泊车开得更远,应用场景更广。
理性感性也分不清了。在自己拿到采集的数据集时,要去做检测,发现不是调个YOLO系列就能搞定的事。网上公开的数据集可用同济的ps2.0,首尔的PIL_park,这两个数据集可以用来练兵,再去应对现实场景。
实际上,就嫌之前的方法看起来麻烦,还不容易在短时间内上手,在做工程的时候,当然是又快又好,抄作业难以抄到好的情况下,考虑造一个好用又泛化的算法。这就是通用停车位检测算法GPSD的由来。
3.2 怎么来定义一个停车位?
要放一些图
其实原理也很简单,但想泛化,需要考虑的还是有一些
汽车长这样,占地区域是方方正正。就一个矩形

再看看鱼眼相机

车位只要能放得下一辆汽车即可,线段是直的。
来看看鸟瞰图:



鸟瞰图里,一个停车位人眼看起来是放不下一个车位的,哈哈
这是AVM成像带来的,不可避免的,畸变。但是深度学习就强大在这个地方,我们人眼认为他是一个车位,不要被图像而蒙蔽,深度学习从图片中学习特征,这里还要再深层次一点,从图像中去学习高级的人为推断的抽象特征,而这种特征不是显性的不是显式的不是正确的,甚至是错误图像带来的错误信息,需要让深度学习去学到,这个时候,目标检测、语义分割、角点检测、线段检测分割,种种,从CV里拿来就用的拿来主义,似乎受到了一点挑战。如果只是就图检图的化,畸变的车位,和车库里畸变的柱子,就已经可以横跨好几个车位把车位遮挡完了,我们必须警醒:从实际物理的角度而不是成像的像素分布去看待一个车位。

我们这样来看一个车位:

让深度学习去理解,我们要学习这样一个车位。汽车什么的遮挡无关紧要,深度学习真的可以办到。
再抽像点:

停车位的概念,来源于车。先有车,再有停车位。如此简单。车位一定必定是抽象出来四四方方像车一样,是方的,最多的变化占地是平行四边形而已:

3.2 车位几何抽象
还是以图示来进行说明。

车位可以如上图的简单几何表示。如果只是这么简单就好了。实际上,车位是挨个连排的,车位周围干扰线也比较多。而车位分布,总结为如下三种情况

如上图,车位1,2为连续的车位分布;车位3,4为间隔的车位分布;车位5,6为错开的车位分布。矩形可换成平行四边形表示。车位1,2这种情况最常见。车位3,4这种也常见,比如车库中有柱子,车位需要隔开.
空车位好做检测,而车位上有汽车的时候,画面大部分是畸变的汽车,给车位检测带来了一定的难度。
这时候,用anchor_based的方法bounding_box总觉得很怪,另外,车位在AVM中,成像不一定是完整的,比如:

如上图,人为的对图像中的车位进行各种处理,为什么要这样做呢?因为车在行驶过程中,各种转向,和离车位开得近开得远,AVM成像出来的画面都是不一样的。这时,车位抽象出来不一定就是实际的方的了,完整的方形,被AVM成像给截断了。这时采用锚点框做bounding_box检测,又遇到点麻烦。

不采用bounding_box或许是最好的选择。
此时,需要对车位的几何抽象做数学上的表征,使它代表一个车位,并且不受AVM成像和汽车行驶所影响,且完美避开汽车畸变带来的影响。见如下:
我尽量用白话文说清楚。
老规矩,先上图:
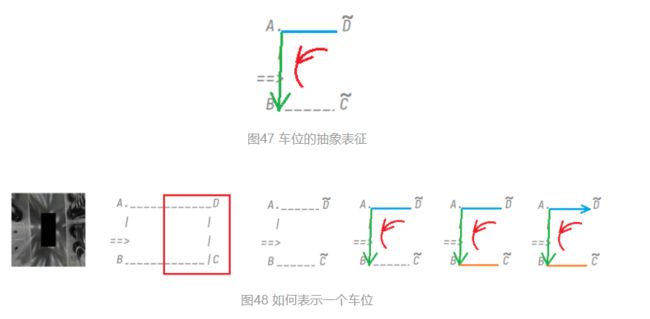


3.2 车位几何抽象

车位抽象出来后,我们只需预测车位的几何表征信息,而无需纠结于车位具体是哪种类型,角点具体用哪种模板,复杂抽象的几何表征,恰恰是对复杂的现实环境的一种数学表示。

图53中的红色曲线箭头,代表车位的几何方向,进入线是AB,分隔线是AD,车位角点是A,红色方向为分隔线->车位角点->进入线。AD->A->AB
3.3 数据集的制作



在制作数据集时,可以在AVM图上进行标注,也可以在单路图像上进行标注。
整张AVM图标注时,遵循图53的右子图标注原则:即在AVM整图的右边,找到车位,对车位角点A打标;再标注进入线AB,AB应尽可能准确;标注AD时,可任意选择AD的长度,因为AD的预测有两种方法,再上篇的图49公式里,是计算方式。此时整个车位就是逆时针顺序。相对而言,AVM图左边的标注也是按照逆时针原则,但要注意标注进入线和分隔线。
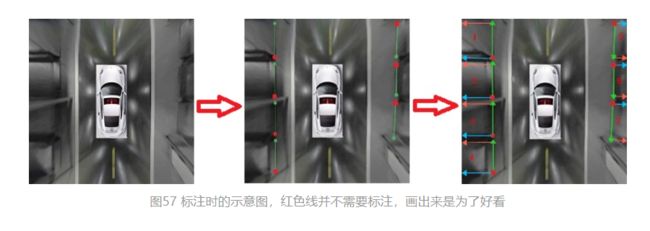
另外,还可以给车位上是否占用,即是否可用打上标签。
标注的图像通过裁剪和放缩,处理到W=128,H=384,W/H=1/3,送入网络。这个比例和大小自己定,这里职位为了除以下采样32的倍数,选128的倍数更方便。

公开数据中,我们采用了ps2.0和PIL_park,并进行数据集的改造。以符合我们的几何抽象定义。另外还自行采取和制作了商场停车场的数据集(就不贴上来了)。
ps2.0: Vision-based parking-slot detection: A DCNN-based approach and a large-scale benchmark dataset
PIL_park: Context-based parking slot detection with a realistic dataset
3.4 车位预测
在feature map上,一个feature_map像素,回归一个车位。输入的分辨率是128*384,吐出的特征图分辨率是4*12,输入的通道是3(RGB)或者1(Gray灰度图),输出的通道根据需要而定,我们采用的8个输出通道,具体为:confidence置信度,车位角点A_x/A_y,进入线delta_x/delta_y,分隔线delta_x/delta_y或者分隔线cos/sin,是否占用标志isOccupied(或者是否可用标志available)。
这里的车位角点,并不是真正意义上的图像中一定存在的车位角点,进入线和分隔线也不是真正意义上图像中存在的线、实线、虚线、各种线,我们回归的是一种抽象的数学几何表示。


是不是有点像CenterNet?或者YOLO系列,YOLO1/2/3/X,Anchor Free,但是这里最大的区别在于,没有利用图像中的具体像素,利用实例的形状和位置来确定实例,这里就解释不通,因为汽车有畸变,它挡住了车位,并不是真正的实际成像,我们回归可以说是一个二维平面(地面)的车位,而3维空间中的汽车被AVM压到了二维成像中,像素分布并不可靠了,学习图像具体的像素不可行,必须让网络学习抽象的几何表征。有点难以解释,让整个车位的信息,压缩到车位角点,即便车位角点实际并不存在,或者车位角点难以区分,如图58所示。车位角点只是一个承载的载体,也可换到图像中任何其他位置,如进入线AB中点,(没试过),设计的时候考虑到了这一点。
3.5 网络架构
这个就很随意了,backbone和detection head,任选,只是输出特征图的大小要特别注意,拿feature_map的分辨率4x12来说,一张128x384的图最多给48个车位预测,实际上没有这么多,只是为了适应车位在图中的分布,需要4x12去适应车位出现在图中的不同位置。我们选择了单阶段的网络设计,直出,就用单分辨率特征图,发现已经把公开数据集ps2.0和PIL_park的AP快刷满了。
3.6 公开数据集上的测试结果

ps2.0数据集是同济在2018年发布的,在车位检测极具影响力,但比较简单。PIL_park发布得更晚,文章引用少,但难度足够。

再贴下效果图
3.7 设计实验
为了模仿实际泊车的AVM成像,比较关键的增强手段就是旋转ratote,然后就是平移shift。
上篇有说,就是汽车在行驶过程中,前行、转向和靠近车位的距离。
输入采用RGB和灰度图均可,灰度图只是为了实际工程应用,但RGB的AP更高。
实验参照一些影响广泛的检测网络设计即可,不是本篇讨论的范围。
但是在设计loss的时候,因为confidence、角点坐标、进入线、分隔线、是否占用,它们的loss量级有差,于是乎,做了对比实验,发现需要给上述的每个单项加系数,使网络更关注角点坐标和进入线,而对是否占用的影响降低。采用了L2-norm。
不采用任何增强手段的粗糙网络在PIL_park的test上也能达到超过90的mAP。方法很重要