【pytorch】optimizer(优化器)的使用详解
目录
- 1 创建一个 Optimizer
-
- 一个简单的例子:求目标函数的最小值
- Per-parameter 的优化器
- 2 Taking an optimization step 开始优化
-
- optimizer.step(closure)
- 常见的几种优化器
- 如何调整 lr?
- 优化器的保存和读取
本文介绍 torch.optim 包常见的使用方法和使用技巧。
1 创建一个 Optimizer
要构造一个Optimizer,你必须给它一个包含参数(所有参数都应该是 Variable s)的可迭代对象来优化。然后,您可以指定特定于优化器的选项,如学习率、权值衰减等。
from torch.autograd import Variable
import torch.optim as optim
# Variable 的创建
tensor = torch.FloatTensor([[1,2],[3,4]]) # build a tensor
var1 = Variable(tensor, requires_grad=True) # build a variable, usually for compute gradients
var2 = Variable(tensor+1, requires_grad=True)
model = model()
# 构造 Optimizer
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001) # 还可以对 Variable 进行优化哦~
一个简单的例子:求目标函数的最小值
假设 x = 4 为起点,求 y = (x-5)^2 的最小值:
from torch.autograd import Variable
import torch.optim as optim
# Variable 的创建
tensor = torch.FloatTensor([[4]]) # build a tensor
x = Variable(tensor, requires_grad=True) # build a variable, usually for compute gradients
optimizer = optim.Adam([x], lr=0.1) # 还可以对 Variable 进行优化哦~
for i in range(100):
optimizer.zero_grad()
y = (x - 5)*(x - 5) # 因为 x 的值不断在优化,所以 y 的定义式要放在这里
y.backward()
optimizer.step()
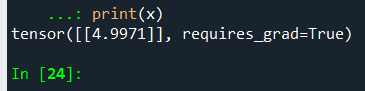
print(x)
Per-parameter 的优化器
有时候,我们会使用例如 pre-trained model 这样的模型,用其特征提取模块并连接自己设计的 classifier 层。这时候需要对不同的层使用不同的 lr,具体操作如下:
首先,模型的设计可以采用这样的结构,*layers是一个列表。

optim.SGD([ {'params': model.features.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9) # model.features 的lr 是 1e-2, model.classifier 是 1e-3,momentum=0.9针对所有层都有效。
2 Taking an optimization step 开始优化
所有优化器都实现一个step()方法,该方法更新参数。它有两种用法:
optimizer.step()
这是大多数优化器支持的简化版本。该函数可以在梯度计算完成后调用,例如使用 backward()。
for input, target in dataset:
optimizer.zero_grad() # 这一步很重要
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
optimizer.step(closure)
一些优化算法,如共轭梯度和LBFGS需要多次重新计算函数,所以您必须传入一个闭包,允许它们重新计算您的函数。闭包应该清除梯度,计算损失,并返回它。
常见的几种优化器

具体参数设定请参阅:https://pytorch.org/docs/stable/optim.html#algorithms
如何调整 lr?
torch.optim.lr_scheduler 提供几种方法,以调整学习速率的基础上的时间数。torch.optim.lr_scheduler.ReduceLROnPlateau允许根据评估指标,动态降低学习率(这里不做介绍)。
import torch.nn as nn
from torch.utils.data import DataLoader,TensorDataset
model = nn.Parameter(torch.randn(2, 1, requires_grad=True))
optimizer = optim.SGD([model], 0.1)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9) # 指数衰减,每一轮变为上一轮的 0.9
x = torch.randn(10,2)
y = torch.randn(10,1)
dataset = TensorDataset(x, y)
dataset = DataLoader(dataset)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = input * model
loss = (output - target).sqrt().mean()
loss.backward()
optimizer.step()
scheduler.step()
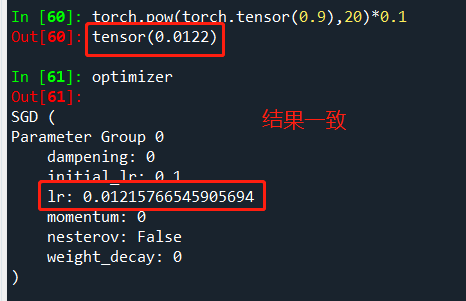
验证 lr 降低的效果:
当然,也可以手动地在每一轮中设置 lr 并创建新的优化器。
来看另一种 lr 衰减的方法,使用2个lr衰减方法的叠加。
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler1.step()
scheduler2.step()
优化器的保存和读取
有时候训练到一半,需要建立 checkpoint ,随时保存模型和优化器状态,和模型的读取、保存一样,优化器的使用方法如下:
para_dict = optimizer.state_dict()
optimizer.load_state_dict(para_dict)

参考:
https://pytorch.org/docs/stable/optim.html