谷歌最新提出无需卷积、注意力,纯MLP构成的视觉架构!网友:MLP is All You Need?
2021-05-06 15:50:28

作者 | 耳洞打三金、琰琰
近日,谷歌大脑团队新出了一篇论文,题目为《MLP-Mixer: An all-MLP Architecture for Vision 》,这篇论文是原视觉Transformer(ViT)团队的一个纯MLP架构的尝试。
本文总结来说就是提出了一种仅仅需要多层感知机的框架——MLP-Mixer,无需卷积模块、注意力机制,即可达到与CNN、Transformer相媲美的图像分类性能。

下面是论文和链接:

论文链接:
https://arxiv.org/pdf/2105.01601.pdf
近一年来,Transformer可真是太火了,把Transformer用在视觉领域真是屡试不爽,先是分类后是检测,等等等等,每次都是吊打ResNet,对CV任务“降维打击”,说句实话,每次Transformer在CV领域新的论文出来,别说是对AI从业者,哪怕是对刚刚小学毕业的三金我,对神经来说都是一种挑战:这咋又双叒叕超越了?
众所周知,CV领域主流架构的演变过程是 MLP->CNN->Transformer 。
难道现在要变成 MLP->CNN->Transformer->MLP ?
都说时尚是个圈,没想到你学术圈真的有一天也变成了学术“圈”。
那就先来看一下MLP-Mixer这个新框架吧,它不使用卷积或自注意力机制。相反,Mixer体系架构完全基于在空间位置或特征通道上重复应用的多层感知器(MLP),它只依赖基础的矩阵乘法操作、数据排布变换(比如reshape、transposition)以及非线性层。
下图展示了MLP-Mixer的整体结构:
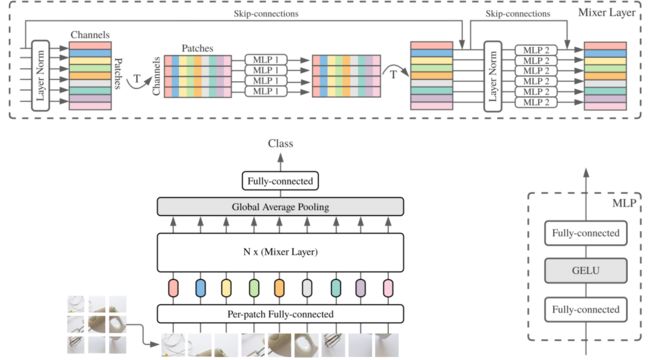
首先,它的输入是一系列图像块的线性投影(其形状为patches x channels),其次,Mixer使用两种类型的MLP层:
1、通道混合MLP(channel-mixing MLPs ):用于不同通道之间进行通信,允许对每个token独立操作,即采用每一行作为输入。
2、token混合MLP(The token-mixing MLPs ):用于不同空间位置(token)之间的通信;允许在每个通道上独立操作,即采用每一列作为输入。
以上两种类型的MLP层交替执行以实现两个输入维度的交互。
在极端情况下,MLP-Mixer架构可以看作一个特殊的CNN,它使用1×1通道混合的卷积,全感受域的单通道深度卷积以及token混合的参数共享。典型的CNN不是混合器的特例,卷积也比MLPs中的普通矩阵乘法更复杂(它需要额外的成本来减少矩阵乘法或专门实现)不过,尽管它很简单,MLP-Mixer还是取得了很不错的结果。
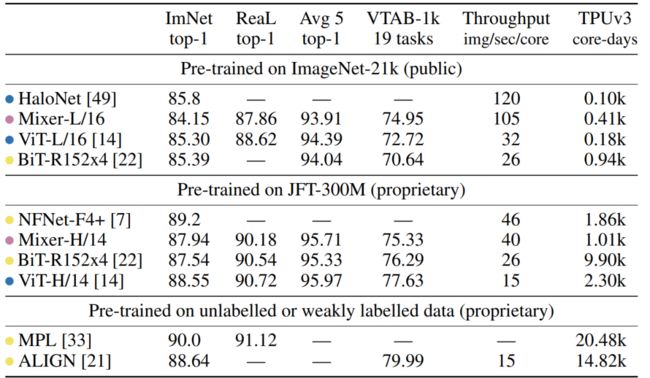
当对大型数据集进行预训练时(大约100万张图片),它达到了之前CNNs和Transformers在ImageNet上的最佳性能:87.94%的 top-1 验证准确率。当对1-10万张图片大小的数据集进行预训练时,结合现代正则化技术( regularization techniques),Mixer同样取得了强大的性能。
1 Mixer 混合器架构
一般来讲,当今深度视觉体系结构采用三种方式进行特征混合:
(i)在给定的空间位置;
(ii)不同的空间位置之间;
(iii)将上述两种方式组合。
在CNNs中,(ii)是采用N× N进行卷积和池化,其中N>1;(i)采用1×1卷积;较大的核则同时执行(i)和(ii)。通常更深层次的神经元有更大的感受野。
在Transformer和其他注意力架构中,自注意力层允许同时执行(i)和(ii),而MLP只执行(i)。Mixer架构背后的思想是:通过MLP实现每个通道混合操作(i)和 token混合操作(ii)的显著分离。
在上图体系架构中,Mixer将序列长度为S的非重叠的图像块作为输入,每个图像块都投影到所需的隐层维度C,并产生一个二维实值输入X∈ RS×C。如果原始图像的分辨率为(H x W),每个图像块的分辨率为(P x P),那么图像块的数量则为S=HW/P2。所有的块都采用相同的投影矩阵进行线性投影。
Mixer由等尺寸的多层组成,每层有两个MLP块。第一个是token mixing MLP块:它作用于X的列,从RS映射到R S,可在所有列中共享。第二个是Channel-mixing MLP块:它作用于X的行,从Rc映射到 R C,可在所有行中共享。每个MLP块包含两个全连接层和一个独立于输入的非线性层。其基本方程如下:

图中,Ds Dc分别代表token-mixing与channel-mixing MLP中隐层宽度。由于Ds的选择独立于输入图像块的数量,因此,网络的计算复杂度与输入块的数量成线性关系;此外,Dc独立于块尺寸,整体计算量与图像的像素数成线性关系,这类似于CNN。
如上文所说,相同的通道混合MLP(或令牌混合MLP)应用于X的每一行和列,在每一层内绑定通道混合MLP的参数都是一种自然选择,它提供了位置不变性,这是卷积的一个显著特征。
不过,跨通道绑定参数的情况在CNN中并不常见。例如CNN中可分离卷积,将不同的卷积核独立应用于每个通道。而Mixer中的token 混合MLP可以对所有通道共享相同的核(即获得完全感受野)。通常来讲,当增加隐层维数C或序列长度S时,这种参数绑定可以避免体系架构增长过快,并且节省内存。令人没想到的是,这种绑定机制并没有影响性能。
Mixer中的每个层(除了初始块投影层)接收相同大小的输入。这种“各向同性”设计最类似于使用固定宽度的Transformer和RNN。这与大多数CNN不同,CNN具有金字塔结构:越深的层具有更低的分辨率,更多的通道。需要注意的是,以上是典型的设计,除此之外也存在其他组合,例如各向同性网状结构和金字塔状VIT。除了MLP层之外,Mixer还使用了其他标准的体系结构组件:Skip 连接和层规范化。
此外,与ViTs不同,Mixer不使用位置嵌入,因为token混合mlp对输入token的顺序敏感,因此可以学习表示位置。最后,Mixer使用一个标准的分类head和一个线性分类器。
2 更多实验结果和代码


下图是原论文附带的代码,很简单,只有43行。

3 网友评价
知乎网友@小小将 表示:
FC is all you need, neither Conv nor Attention.
在数据和资源足够的情况下,或许inductive bias的模型反而成了束缚,还不如最simple的模型来的直接。

知乎网友@小赖sqLai 表示:
说白了就是patch内和patch间依次进行信息交换和整合,相比transformer其实缺了个动态的结构,也就是内容不可感知,有点过拟合的意思在里面。主观感觉,如果再补个patch内的attention和patch间的attention进去,差不多就能接近transformer了。


知乎网友@TniL 表示:
观察到两个趋势,不敢说是好还是坏:
1、以前的工作都努力在通用模型里加归纳偏置,用来减少参数优化需要的资源(数据、计算资源);近期的(一批)工作在反其道行之,逐渐去先验化,让这部分bias通过大量数据学习出来。
2、以前的模型都讲究兼容变长数据,CNN、RNN、Xformer都有处理变长数据的能力,这使得它们非常通用,现在的一些模型(包括问题讨论的这篇)都assume输入的大小是固定的,直观上看不能算太通用的框架(所以不敢苟同MLP is all you need这种观点)。
知乎网友@mathfinder对原文方法的总结:
总体而言相对遗憾,没有超过SOTA,仅仅是可比较。从实验结果来看跟ViT相比还是全面落后,但还是给人一些启发的,毕竟结构极致简单。
本文核心是设计了非常小巧的Mixer-Layer,通过MLP来交互每个patches的信息。实际上,经过一次mixer-layer,每个patch就能拿到全图的信息。
知乎网友@Rooftrellen表示:
感觉有点标题党,照这么说CNN也是MLP了,MLP本来就是现在大部分架构的building block,区别只是这些子MLP如何连接,如何共享权重等等。

知乎网友@大白杨表示:
谷歌还是不会取名字,要换成国内组的话,直接一个"MLP is All You Need"或者"Make MLP Great Again"。

三金我觉得倒是觉得发论文可以再大胆一些:
《震惊!无需卷积、注意力、MLP、神经网络,甚至无需计算机,只用人眼就能达到图像识别/检测/分割的SOTA水平》 。
。
最后,对于这篇论文和MLP的回归,您怎么看?
参考链接:
https://www.zhihu.com/question/457926000