模型部署——CenterPoint转ONNX(自定义onnx算子)
CenterPoint基于OpenPcDet导出一个完整的ONNX,并用TensorRT推理,部署几个难点如下:
1.计算pillar中每个点相对几何中心的偏移,取下标方式进行计算是的整个计算图变得复杂,同时这种赋值方式导致运行在pytorch为浅拷贝,而在一些推理后端上表现为深拷贝
- 修改代码,使用矩阵切片代替原先的操作,使导出的模型在推理后端上的行为结果和
pytorch一致,并简化计算图,同时,计算网格坐标也需要修改,修改代码如下:
points_coords = torch.floor((points[:, [0,1,2]] - self.point_cloud_range[[0,1,2]]) / self.voxel_size[[0,1,2]]).int()
# onnx不支持all,这个部分不放在onnx里,放在预处理部分
# mask = ((points_coords >= 0) & (points_coords < self.grid_size[[0,1]])).all(dim=1)
# points = points[mask]
# points_coords = points_coords[mask]
unq_coords, unq_inv, unq_cnt = torch.unique(merge_coords, return_inverse=True, return_counts=True, dim=0)
# points_xyz = points[:, [0, 1, 2]].contiguous()
points_xyz = points[..., :3]
points_mean = torch_scatter.scatter_mean(points_xyz, unq_inv, dim=0)
points_mean = scatter_mean(points_xyz,unq_inv)
# # 每个点相对voxel质心的偏移
f_cluster = points_xyz - points_mean[unq_inv, :] # torch.Size([1067877, 3])
f_center = torch.zeros_like(points_xyz).to()
# 每个点相对几何中心的偏移
# f_center[:, 0] = points_xyz[:, 0] - (points_coords[:, 0].to(points_xyz.dtype) * self.voxel_x + self.x_offset)
# f_center[:, 1] = points_xyz[:, 1] - (points_coords[:, 1].to(points_xyz.dtype) * self.voxel_y + self.y_offset)
# f_center[:, 2] = points_xyz[:, 2] - self.z_offset
device = points_xyz.device
f_center = points_xyz - (points_coords * torch.tensor([self.voxel_x, self.voxel_y, self.voxel_z]).to(device) + torch.tensor([self.z_offset, self.y_offset, self.x_offset]).to(device))
2.torch_scatter的scatter_mean和scatter_max onnx不支持,需人为自定义onnx节点,后续并自定义tensorRT的ScatterMeanPlugin和ScatterMaxPlugin算子
自定义onnx ScatterMax 算子如下,这里ScatterMax算子没有具体实现,仅为了增加相应的onnx节点,好导出onnx计算图,方便后续自定义实现TensorRT算子,实际上导出onnx并不能用onnxruntime来推理,这样做好处:我们可以只需要自定义实现TensorRT算子,对onnx增加相应节点就行,而不需要管具体的onnx算子实现。
class ScatterMax(torch.autograd.Function):
@staticmethod
def forward(ctx,src,index):
# 调unique仅为了输出对应的维度信息
temp = torch.unique(src)
out = torch.zeros((temp.shape[0],src.shape[1]),dtype=torch.float32,device=src.device)
return out
@staticmethod
def symbolic(g,src,index):
return g.op("xiaohu::ScatterMaxPlugin",src,index)
ScatterMeanPlugin和ScatterBevPlugin节点和ScatterMaxPlugin节点定义方式是类似的
3.由于基于OpenPcDet的CenterPoint用了动态体素化,计算体素信息调用torch.unique,而torch.unique算子 TensorRT 不支持,也需要自定义相应的算子
4.torch.stack算子 onnx不支持,导出onnx计算图很乱,将torch.stack和后续PointPillarScatter操作合并,一起定义为ScatterBevPlugin算子,自定义onnx节点和TensorRT算子来实现,ScatterBevPlugin实现功能和以下代码功能一致:
voxel_coords = torch.stack((unq_coords // self.scale_xy, (unq_coords % self.scale_xy) // self.scale_y, unq_coords % self.scale_y,
torch.zeros(unq_coords.shape[0]).to(unq_coords.device).int()), dim=1)
# 将voxel_coords
voxel_coords = voxel_coords[:, [0, 3, 2, 1]] # index,z,y,x
pillars_feature = features.t() # float32[64,pillar_num]
spatial_feature = torch.zeros(64, 468 * 468,dtype=features.dtype, device=features.device)
indices = voxel_coords[:, 2] * 468 + voxel_coords[:, 3] #468 * y + x
# indices = indices.type(torch.long)
# tensors used as indices must be long, byte or bool tensors
indices = indices.long()
spatial_feature[:, indices] = pillars_feature
spatial_feature = spatial_feature.view(1,64, 468, 468) # 对应onnx resahap
下面看CenterPoint转换出的onnx计算图:自定义onnx节点有 ScatterMaxPlugin,ScatterMeanPlugin,ScatterBevPlugin,用tensorRT实现就需要自定义ScatterMaxPlugin,ScatterMeanPlugin,ScatterBevPlugin,Unique 4个算子,后续会写下tenorRT自定义算子,并用cuda实现CenterPoint预处理和后处理,从而完成整个CenterPoint部署
因onnx太小看不清,自定义onnx节点如下:
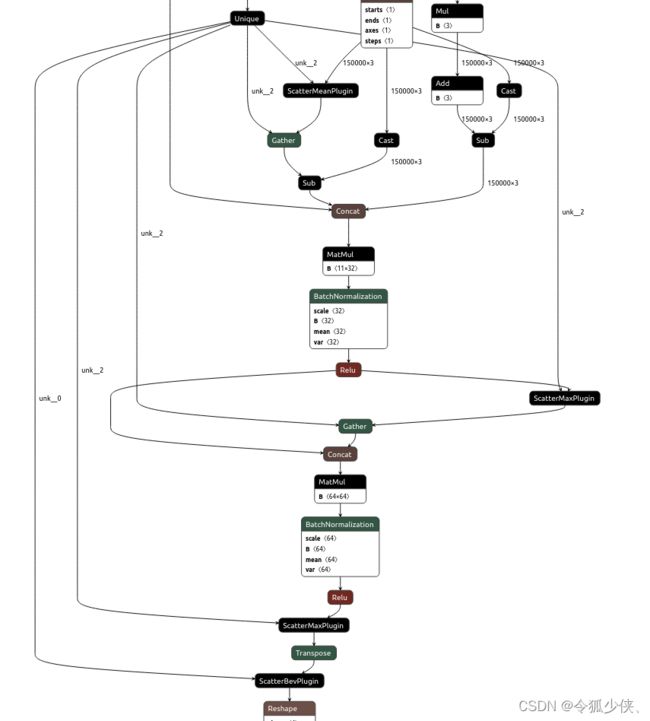
完整的onnx如下:
