计算机网络【IP协议与以太网】
计算机网络【IP协议与核心协议】
- 一.IP协议
-
- 1.1IPv4协议格式
- 1.2 IP协议地址
- 1.3IPv4协议的解决方案
- 1.4路由选择(了解)
- 二.以太网协议
-
- 2.1以太网协议格式
- 2.2认识MTU(了解)
- 三.DNS协议(应用层)
一.IP协议
1.1IPv4协议格式
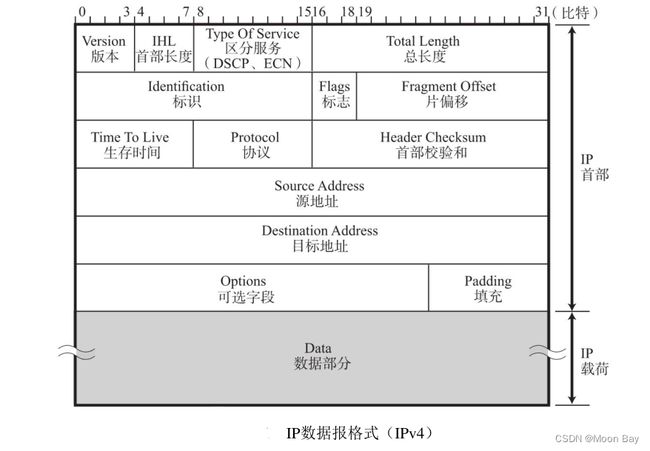
●4位版本号(version):指定IP协议的版本,对于IPv4来说,就是4
●4位头部长度(header length):IP头部的长度是多少个32bit,也就是 length * 4 的字节数。4bit表示最大的数字是15,因此IP头部最大长度是60字节
●8位服务类型(Type Of Service):3位优先权字段(已经弃用),4位TOS字段,和1位保留字段(必须置为0)。4位TOS分别表示:最小延时,最大吞吐量,最高可靠性,最小成本。这四者相互冲突,只能选择一个。对于ssh/telnet这样的应用程序,最小延时比较重要;对于ftp这样的程序,最大吞吐量比较重要
●16位总长度(total length):IP数据报整体占多少个字节
●16位标识(id):唯一的标识主机发送的报文。如果IP报文在数据链路层被分片了,那么每一个片里面的这个id都是相同的
●3位标志字段:第一位保留(保留的意思是现在不用,但是还没想好说不定以后要用到)。第二位置为1表示禁止分片,这时候如果报文长度超过MTU,IP模块就会丢弃报文。第三位表示"更多分片",如果分片了的话,最后一个分片置为1,其他是0。类似于一个结束标记
●13位分片偏移(framegament offset):是分片相对于原始IP报文开始处的偏移。其实就是在表示当前分片在原报文中处在哪个位置。实际偏移的字节数是这个值 * 8 得到的。因此,除了最后一个报文之外,其他报文的长度必须是8的整数倍(否则报文就不连续了)
●8位生存时间(Time To Live,TTL):数据报到达目的地的最大报文跳数。一般是64。每次经过一个路由,TTL -= 1,一直减到0还没到达,那么就丢弃了。这个字段主要是用来防止出现路由循环
●8位协议:表示上层协议的类型(类似于TCP,UDP)
●16位头部校验和:使用CRC进行校验,来鉴别头部是否损坏
●32位源地址和32位目标地址:表示发送端和接收端
●选项字段(不定长,最多40字节):略
如果整个IP协议数据太长超过了64k的大小,IP协议就会将数据分成多分进行传输(大小不超过64k),通过标识来标识判断来这个是那一份的IP协议里的数据报,通过片偏移来判断在这个IP报文里是那个层(进行排序),通过标志位来辨别出是否后面还有没有有需要传输的分层数据,如果是0就代表还有,如果是1就代表这个分层数据就已经传输完毕了


1.2 IP协议地址
IP地址是一个点分十进制构成的数据
IP地址分成两个部分分别是,网络号+主机号

上面说了那么多有关IP协议格式,但IP地址究竟是什么呢?对于IPv4,IP地址本质上就是一串32位的序号而已,以点分十进制的方式呈现出来,即平均将这32位平分为4份,每份8位,使用.分割,每份数据的范围为0-255,比如192.168.31.70就是一个IP地址。
IP地址分为两个部分,即网络号+主机号,网络号能够描述当前的网段信息(局域网标识),主机号区分了局域网中的主机。
要求在同一个局域网内,网络号必须相同,主机号不能相同,两个相邻的局域网(同一台路由器连接),网络号是不同的。
比如上面的192.168.31.70,192.168.31表示网络号,70表示主机号。但是网络号的位数与主机号的位数是固定的吗?当然不是,在计算机网络,有一个专有名词叫做子网掩码 ,它也是一个32位的数,对应IP地址的每一位,如果为1就表示这一位是网络号,为0就表示主机号,子网掩码不会混着排列,左边为1表示网络号,右边为0表示主机号。
打开电脑的命令行,输入ipconfig,就能获取到本机的IP地址:

●网络号:描述当前的网段信息(局域网的标识)
●主机号:用来区分局域网的主机
为什么这样设计,是因为在同一个局域网会采用同一个网络号,所以要辨别出 不用设备对别的设备进行访问,我们就需要来辨别出具体是那个设备进行的访问
同理不在同一个路由器里网络号也是不相同的,这就是我们之前学过的LAN口(局域网)与WAN口(广域网)

1.3IPv4协议的解决方案
当前我们使用的IP协议是IPv4协议(32位),也就是说我们可以使用链接的设备为42亿9千万,随着我们世界当今的飞速发张意味着终会有一天42亿9千万就不会满足我们来使用,所以我们应该怎样来解决未来将要面都的问题呢?
●动态分配IP地址:就是让每个设备链接到网络的时候,才会有IP,不联网的时候就没有IP,但是这个方案不能从根本上来解决
●.NAT机制:让多个设备公用一个IP,就像我们上面画的图演示时一样的,我们将内网(局域网)与外网(广域网)进行了区分,也就是只有在使用外网的时候才会占有IP地址,这个时候就有可能会带有成千上万个设备,这样就能解决IP数量不够的问题
NAT机制虽然将IP分成了外网和内网,但是也隐含了一个重要的结论:对于一个外网,可以在互联网任意一个位置来进行访问,但是对于一个内网,只能在当时局域网内部访问,局域网1不能访问局域网2的设备,所以就像QQ一样,QQ是带有外网的IP,我通过我的手机来访问QQ,你也通过QQ来访问QQ,我们来进行短息的交流,这样我们其实最终还是需要用到外网才可以进行访问,所以NAT机制也是有极限的,它的极限就是源端口号
●IPv6:IPv6是由16个字节来构成的比IPv4多了12个字节,IPv6可以带有2*128次幂的IP,也就是可以说将我们全球的沙子赋予他们属于自己的IP,之所以IPv6没有在当前世界流行,是因为IPv4与IPv6是不兼容的!
1.4路由选择(了解)
路由选择就是规划路径->问路
两个设备之间,要想找到一条通路能够完成传输的过程,找到的前提就是得先认识路
什么叫做路由器"认识"这个IP地址?
在路由器里有一个数据结构->路由表,路由表就在里面记录的一些网段信息~~(网络号),也就是我们从源IP到目的IP中就是要通过每个网络号对应的网络接口来找到目的IP地址
二.以太网协议
2.1以太网协议格式
数据经过网络层的封装后,会进入数据链路层进一步封装,数据链路层最常用的协议就是“以太网”,协议格式如下:

●目的地址,源地址(6字节):数据链路层的地址是MAC地址,表示物理层地址,每一个设备只有一个物理层地址,这在硬件出厂时就已经写死的(大部分),它的地址长度比IPv4长了6w多倍,如80-30-49-26-8E-D9就是一个物理地址,在命令行输入ipconfig /all就能够查看自己设备的物理地址
●帧尾(4字节):帧尾的功能一般是校验,它是一个叫做FCS(Frame Check Sequence,帧检验序列)或CRC算法实现的校验和
以太网数据帧的最大数据载荷称为MTU,这个范围一般取决于硬件设备,不同硬件设备的MTU也不同。数据链路层考虑的是相邻设备,或者说是直接连接设备的数据传输,考虑到这个细节的时候,就需要关注传输的硬件设备,不同的硬件,搭载的数据量也不同
除了MTU还有一个类似的概念,那就是MSS,表示在不分包的情况下,除去IP与TCP首部能够搭载的最大容量

ARP报文,并不是用来传输数据的,而是一个辅助信息,就是将IP地址与MAC地址一一对应起来,建立成一个类似哈希表的映射关系,MAC地址每传输一次都会发生改变。当设备启动的时候,就会在所处的局域网发起一个广播,获取局域网内设备的IP与MAC地址,根据各个设备响应的信息就能建立一个IP与MAC对应的映射表
2.2认识MTU(了解)
MTU相当于发快递时对包裹尺寸的限制。这个限制是不同的数据链路对应的物理层,产生的限制
●以太网帧中的数据长度规定最小46字节,最大1500字节,ARP数据包的长度不够46字节,要在后面补填充位;
●最大值1500称为以太网的最大传输单元(MTU),不同的网络类型有不同的MTU
●如果一个数据包从以太网路由到拨号链路上,数据包长度大于拨号链路的MTU了,则需要对数据包进行分片(fragmentation)
●不同的数据链路层标准的MTU是不同的
MTU对IP协议的影响
由于数据链路层MTU的限制,对于较大的IP数据包要进行分包
●将较大的IP包分成多个小包,并给每个小包打上标签
●每个小包IP协议头的 16位标识(id) 都是相同的
●每个小包的IP协议头的3位标志字段中,第2位置为0,表示允许分片,第3位来表示结束标记(当前是否是最后一个小包,是的话置为1,否则置为0)
●到达对端时再将这些小包,会按顺序重组,拼装到一起返回给传输层
●一旦这些小包中任意一个小包丢失,接收端的重组就会失败。但是IP层不会负责重新传输数据
三.DNS协议(应用层)
对于我们人类来书说,IP地址并不好记,为了方便人类的记忆,就将IP地址用一个域名(比如www.baidu.com)来指代,而DNS能够将IP与域名对应起来,形成映射关系
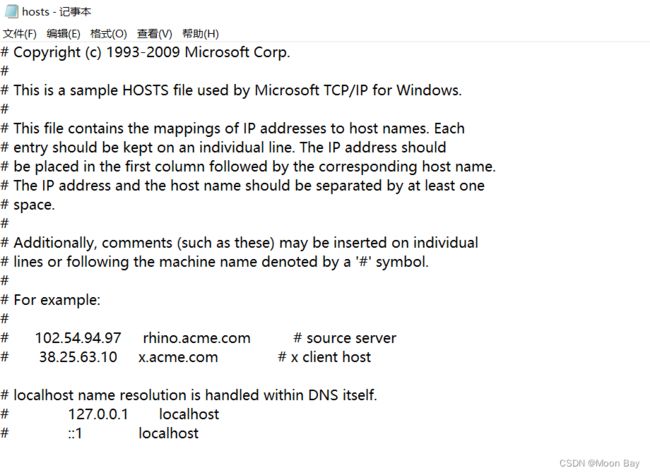
DNS最开始的时候就是一个hosts文件,不过随着发展,现在就有一个机构专门在服务器上维护hosts文件,如果你需要域名解析,就可以访问它们的网站获取

我们可以将文件拖到记事本来查看一些信息,例如IP地址
当然,就一个根服务器是满足不了全球用户的访问的,于是运营商就就近架设了镜像的服务器,镜像服务器会定时同步根服务器上的数据
