【Flink】Table API和Flink SQL
Table API和Flink SQL
- 简绍
- 基本程序结构
-
- TableEnvironmetnt
- 表(Table)
- 输出表
- 更新模式
- DataStream与表的相互转换
- 查看执行计划
- 时间
- 窗口
-
- Group Windows
- Tumbling Windows
- Sliding Windows
- Session Windows
- Over Windows
- SQL中的Over Windows
- 函数
-
- 标量函数(Scalar Functions)
- 表函数(Table Functions)
- 聚合函数(Aggregate Functions)
简绍
对于像DataFrame这样的关系型编程接口,因其强大且灵活的表达能力,能够让用户通过非常丰富的接口对数据进行处理,有效降低了用户的使用成本,近年来逐渐成为主流大数据处理框架主要接口形式之一。Flink也提供了关系型编程接口Table API以及基于TableAPI的SQL API,让用户能够通过使用结构化编程接口高效的构建Flink应用。同时Table API以及SQL能够统一处理批量和实时计算业务,无需切换到修改任何应用代码就能够基于同一套API编写流式应用和批量应用,从而达到真正意义的批流统一。
Apache Flink具有两个关系API - 表API和SQL- 用于统一流和批处理。Table API是Scala和Java的语言集成查询API,允许以非常直观的方式组合来自关系运算符的查询,Table API和SQL接口彼此紧密集成,以及Flink的DataStream和DataSet API。您可以轻松地在基于API构建的所有API和库之间切换。例如,您可以使用CEP库从DataStream中提取模式,然后使用Table API分析模式,或者可以在预处理上运行Gelly图算法之前使用SQL查询扫描,过滤和聚合批处理表数据。
Flink 的 SQL 支持基于实现了 SQL 标准的 Apache Calcite

依赖文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>FlinkTestartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka-0.11_2.12artifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.7version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.49version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-statebackend-rocksdb_2.12artifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner_2.12artifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_2.12artifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_2.12artifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-csvartifactId>
<version> 1.10.1version>
dependency>
dependencies>
project>
跳转顶部
基本程序结构
TableEnvironmetnt
和DataStream一样,Table API和SQL中具有相同的基本编程模型。首先需要构建对应的TableEnvironment创建关系型编程环境,才能够在程序中使用Table API和SQL来编写程序,另外Table API和SQL接口可以在应用中同时使用。Flink SQL基于Apache Cacite框架实现SQL协议,是构建在Table API之上的更高级接口。
创建表的执行环境,需要将Flink流处理的执行环境传入
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
TableEnvironment是Flink中集成 Table API和 SQL 的核心概念,所有对表的操作都基于 TableEnvironment,它主要负责:
- 注册
Catalog - 在
Catalog中注册表 - 执行
SQL查询 - 注册用户自定义函数
UDF
TableEnvironment注册对象
// 批处理环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 获取表操作环境对象
BatchTableEnvironment tableEnvironment = BatchTableEnvironment.create(env);
// 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取表操作环境对象
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);
配置老版本的planner流式查询
EnvironmentSettings oldStreamSettings = EnvironmentSettings.newInstance()
.useOldPlanner()//老版本
.inStreamingMode()//流处理
.build();
StreamTableEnvironment oldStreamTbaleEnv = StreamTableEnvironment.create(env, oldStreamSettings);
配置老版本的planner批式查询
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment oldBatchTableEnv = BatchTableEnvironment.create(batchEnv);
配置blink planner的流式查询
EnvironmentSettings BlinkStreamSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment blinkStreamTbaleEnv = StreamTableEnvironment.create(env, BlinkStreamSettings);
配置blink planner的批式查询
EnvironmentSettings blinkBatchSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inBatchMode()//批处理
.build();
TableEnvironment blinkBatchTbaleEnv = TableEnvironment.create(blinkBatchSettings);
跳转顶部
表(Table)
TableEnvironment可以注册目录 Catalog,并可以基于 Catalog 注册表
表(Table)是由一个“标识符”(identifier)来指定的,由3部分组成:Catalog名、数据库(database名和对象名
表可以是常规的,也可以是虚拟的(视图,View)
常规表(Table)一般可以用来描述外部数据,比如文件、数据库表或消息队列的数据,也可以直接从
DataStream转换而来
视图(View)可以从现有的表中创建,通常是 table API或者SQL 查询的一个结果集
创建表:TableEnvironment可以调用.connect()方法,连接外部系统,并调用 .createTemporaryTable()方法,在 Catalog中注册表

可以创建Table来描述文件数据,它可以从文件中读取,或者将数据写入文件
String filePath = "src/main/resources/sensor.txt";
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv())//表的文件格式
.withSchema(new Schema()//表的数据结构,属性名是可以变更的,但是顺序时不可以变换的
.field("id", DataTypes.STRING())
.field("timeStamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE()))
.createTemporaryTable("sensor");
Table inputTable = tableEnv.from("sensor");
表的查询(Table API)
-
Table API是集成在Scala和Java语言内的查询API -
Table API基于代表“表”的Table类,并提供一整套操作处理的方法API;这些方法会返回一个新的Table对象,表示对输入表应用转换操作的结果 -
有些关系型转换操作,可以由多个方法调用组成,构成链式调用结构
//3.1简单的转换
Table resultTable = inputTable.select("id,temperature")
.filter("id = 'sensor_1'");
//聚合统计
Table aggTable = inputTable.groupBy("id")
.select("id,id.count as cnt ,temperature.avg as avgTemp");
表的查询(SQL)
-
Flink的SQL集成,基于实现 了SQL标准的Apache Calcite -
在
Flink中,用常规字符串来定义SQL查询语句 -
SQL查询的结果,也是一个新的Table
Table sqlResulter = tableEnv.sqlQuery("select id,temperature from sensor where id = 'sensor_1'");
Table sqlAgg = tableEnv.sqlQuery("select id,count(id) as cnt ,avg(temperature) as avgTemp from sensor group by id");
输出表
表的输出,是通过将数据写入 TableSink 来实现的
TableSink 是一个通用接口,可以支持不同的文件格式、存储数据库和消息队列
输出表最直接的方法,就是通过 Table.insertInto()方法将一个 Table 写入注册过

输出到文件
String outputPath = "src/main/resources/sensor_result";
tableEnv.connect(new FileSystem().path(outputPath))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("temperature", DataTypes.DOUBLE()))
.createTemporaryTable("output");
跳转顶部
更新模式
对于流式查询,需要声明如何在表和外部连接器之间执行转换
与外部系统交换的消息类型,由更新模式(Update Mode)指定
追加(Append)模式
- 表只做插入操作,和外部连接器只交换插入(
Insert)消息,当涉及聚合操作时,不可使用此方式
撤回(Retract)模式
-
表和外部连接器交换添加(
Add)和撤回(Retract)消息 -
插入操作(
Insert)编码为Add消息;删除(Delete)编码为Retract消息;更新(Update)编码为上一条的Retract和下一条的Add消息
更新插入(Upsert)模式
- 更新和插入都被编码为
Upsert消息;删除编码为Delete消息
练习:读取Kafka的数据,将其进行处理之后再传输到Kafka中
package tableApi;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Csv;
import org.apache.flink.table.descriptors.Kafka;
import org.apache.flink.table.descriptors.Schema;
public class tableTest04_KafkaPipeLine {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.连接kafka,读取数据
tableEnv.connect(new Kafka()
.version("0.11")
.topic("sensor")
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("timeStamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE()))
.createTemporaryTable("input");
//3.查询转换
Table sensorTable = tableEnv.from("input");
//3.1简单的转换
Table resultTable = sensorTable.select("id,temperature")
.filter("id = 'sensor_1'");
//3.2聚合统计
Table aggTable = sensorTable.groupBy("id")
.select("id,id.count as cnt ,temperature.avg as avgTemp");
//4.建立Kafka连接,
tableEnv.connect(new Kafka()
.version("0.11")
.topic("sinkTest")
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
// .field("timeStamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE()))
.createTemporaryTable("output");
resultTable.insertInto("output");
env.execute();
}
}
跳转顶部
DataStream与表的相互转换
先从文件中读取表
String filePath = "src/main/resources/sensor.txt";
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv())//表的文件格式
.withSchema(new Schema()//表的数据结构,属性名是可以变更的,但是顺序时不可以变换的
.field("id", DataTypes.STRING())
.field("timeStamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE()))
.createTemporaryTable("sensor");
Table inputTable = tableEnv.from("sensor");
表转换成DataStream
DataStream<Row> resultStream = tableEnv.toAppendStream(inputTable, Row.class);
DataStream<Tuple2<Boolean, Row>> RetrackStream = tableEnv.toRetractStream(inputTable, Row.class);
DataStream转换成表,在转换的过程中,可以将列重命名
Table table = tableEnv.fromDataStream(resultStream);
Table table1 = tableEnv.fromDataStream(RetrackStream, "id timestamp as ts,temperature");
基于DataStream创建视图
tableEnv.createTemporaryView("ts", resultStream);
tableEnv.createTemporaryView("ts2", resultStream, "id ,temperature,timestamp as ts");
基于表创建视图
tableEnv.createTemporaryView("ts3", inputTable);
查看执行计划
Table API 提供了一种机制来解释计算表的逻辑和优化查询计划
查看执行计划,可以通过 TableEnvironment.explain(table)方法或TableEnvironment.explain() 方法完成,返回一个字符串,描述三个计划
-
优化的逻辑查询计划
-
优化后的逻辑查询计划
-
实际执行计划。
String explaination = tableEnv.explain(resultTable);
System.out.println(explaination);
流处理和关系代数的区别
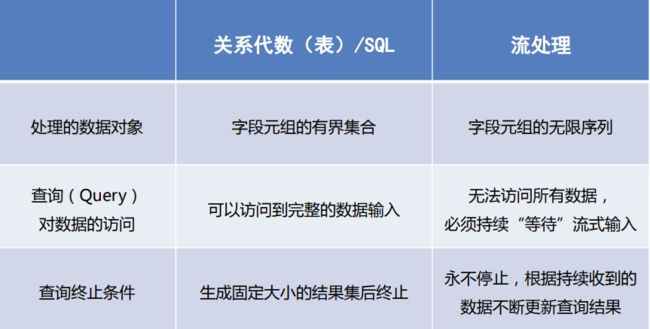
跳转顶部
时间
时间特性(Time Attributes)
-
基于时间的操作(比如 Table API 和 SQL 中窗口操作),需要定义相关的时间语义和时间数据来源的信息
-
Table 可以提供一个逻辑上的时间字段,用于在表处理程序中,指示时间和访问相应的时间戳
-
时间属性,可以是每个表schema的一部分。一旦定义了时间属性,它就可以作为一个字段引用,并且可以在基
于时间的操作中使用 -
时间属性的行为类似于常规时间戳,可以访问,并且进行计算
定义处理时间(Processing Time)
处理时间语义下,允许表处理程序根据机器的本地时间生成结果。它是时间的最简单概念。它既不需要提取时间戳,也不需要生成 watermark,由DataStream 转换成表时指定
在定义Schema期间,可以使用.proctime,指定字段名定义处理时间字段
这个proctime属性只能通过附加逻辑字段,来扩展物理schema。因此,只能在schema定义的末尾定义它
Table sensorTable = tableEnv.fromDataStream(dataStream, "id, temperature, timestamp, pt.proctime");
在Table Schema时指定
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv())//表的文件格式
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE())
.field("pt", DataTypes.TIMESTAMP(3))
.proctime())
.createTemporaryTable("input1");
在创建表的DDL定义
String sinkDDL =
"create table dataTable (" +
" id varchar(20) not null, " +
" ts bigint, " +
" temperature double, " +
" pt AS PROCTIME() " +
") with (" +
" 'connector.type' = 'filesystem', " +
" 'connector.path' = '/sensor.txt', " +
" 'format.type' = 'csv')";
tableEnv.sqlUpdate(sinkDDL);
定义事件时间(Event Time)
-
事件时间语义,允许表处理程序根据每个记录中包含的时间生成结果。这样即使在有乱序事件或者延迟事件时,也可以获得正确的结果。
-
为了处理无序事件,并区分流中的准时和迟到事件;Flink 需要从事件数据中,提取时间戳,并用来推进事件时间的进展
-
定义事件时间,同样有三种方法:
1️⃣:由 DataStream 转换成表时指定
2️⃣:定义 Table Schema 时指定
3️⃣:在创建表的 DDL 中定义
由DataStream转换成表指定
// 将 DataStream转换为 Table,并指定时间字段
Table sensorTable = tableEnv.fromDataStream(dataStream, "id, timestamp.rowtime, temperature");
// 或者,直接追加时间字段
Table sensorTable = tableEnv.fromDataStream(dataStream, " id, temperature, timestamp, rt.rowtime");
定义Table Schema时指定
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv())//表的文件格式
.withSchema(new Schema()//表的数据结构,属性名是可以变更的,但是顺序时不可以变换的
.field("id", DataTypes.STRING())
.field("timeStamp", DataTypes.BIGINT())
.rowtime(
new Rowtime()
.timestampsFromField("timeStamp")//从字段中提取时间戳
.watermarksPeriodicBounded(1000l)//watermark延迟1秒
)
.field("temperature", DataTypes.DOUBLE()))
.createTemporaryTable("input");
创建表的DDL定义
String sinkDDL=
"create table dataTable (" +
" id varchar(20) not null, " +
" ts bigint, " +
" temperature double, " +
" rt AS TO_TIMESTAMP( FROM_UNIXTIME(ts) ), " +
" watermark for rt as rt - interval '1' second" +
") with (" +
" 'connector.type' = 'filesystem', " +
" 'connector.path' = '/sensor.txt', " +
" 'format.type' = 'csv')";
tableEnv.sqlUpdate(sinkDDL);
跳转顶部
窗口
Group Windows
Group Windows是使用 window(w:GroupWindow)子句定义的,并且必须由as子句指定一个别名。
为了按窗口对表进行分组,窗口的别名必须在 group by 子句中,像常规的分组字段一样引用
Table table = input
.window([w: GroupWindow] as "w") // 定义窗口,别名为 w
.groupBy("w, a") // 按照字段 a和窗口 w分组
.select("a, b.sum"); // 聚合
在select语句中,我们除了可以获取到数据元素以外,还可以获取到窗口的元数据信息。
Table table = input
.window([w:Window] as "window") //
.groupBy("window" , "id") // 根据窗口聚合,窗口数据分配到每单个Task算子
.select("id" , "var1.sum","window.start","window.end","window.rowtime") // 指定val字段求和
跳转顶部
Tumbling Windows
前面提到滚动窗口的窗口长度是固定的,窗口之间的数据不会重合。滚动窗口可以基于Evenet Time、Process Time以及Row-Count来定义。如下实例:Table API中滚动窗口使用Tumble Class来创建,且分别基于Evenet Time、Process Time以及Row-Count来定义窗口。
// 通过scan方法在CataLog中查询Sensors表
tableEnv.scan("Sensors")
// 十分钟事件语义下的滚动窗口
.window(Tumble.over("10.minutes").on("rowtime").as("w"));
// 十分钟过程语义下的滚动窗口
.window(Tumble.over("10.minutes").on("proctime").as("w"));
// 十行过程语义下的滚动窗口
.window(Tumble.over("10.rows").on("proctime").as("w"));
-
over: 指定窗口的长度 -
on: 定义了窗口基于的时间概念类型为EventTime还是ProcessTime,EventTime对应着rowtime,
ProcessTime对应着proctime -
as: 将创建的窗口重命名,同时窗口名称需要在后续的孙子中使用
跳转顶部
Sliding Windows
滑动窗口的长度也是固定的,但窗口与窗口之间的数据能够重合。滑动窗口可以基于Evenet Time、Process Time以及Row-Count来定义。如下实例:Table API中滑动窗口使用Slide Class来创建,且分别基于Evenet Time、Process Time以及Row-Count来定义窗口。
// 通过scan方法在CataLog中查询Sensors表
tableEnv.scan("Sensors")
.window(Slide.over("10.minutes").every("5.minutes").on("rowtime").as("w"));
.window(Slide.over("10.minutes").every("5.minutes").on("proctime").as("w"));
.window(Slide.over("10.rows").every("5.rows").on("proctime").as("w"));
-
over: 定义窗口的长度,可以是时间或行计数间隔。 -
every: 定义滑动间隔,可以是时间间隔也可以是行数。滑动间隔必须与大小间隔的类型相同。 -
on: 定义了窗口基于的时间概念类型为EventTime还是ProcessTime,EventTime对应着rowtime,ProcessTime对应着proctime -
as: 将创建的窗口重命名,同时窗口名称需要在后续的孙子中使用。
跳转顶部
Session Windows
与Tumbling、Sliding窗口不同的是,Session窗口不需要指定固定的窗口时间,而是通过判断固定时间内数据的活跃性来切分窗口。例如 10 min内数据不接入则切分窗口并触发计算。Session窗口只能基于EventTime和ProcessTime时间概念来定义,通过withGrap操作符指定数据不活跃的时间Grap,表示超过该时间数据不接入,则切分窗口并触发计算。
tableEnv.scan("Sensors")
.window(Session.withGap("10.minutes").on("rowtime").as("w"));
.window(Session.withGap("10.minutes").on("proctime").as("w"));
跳转顶部
Over Windows
Over Window和标准SQL中提供的Over语法功能类似,也是一种数据聚合计算的方式,但和Group Window不同的是,Over Window不需要对输入数据按照窗口大小进行堆叠。Over Window是基于当前数据和其周围邻近范围内数据进行聚合统计的,例如基于当前记录前面的20条数据,然后基于这些数据统计某一指标的聚合结果。
在Table API中,Over Window也是在window方法中指定,但后面不需要和groupBy操作符绑定,后面直接接SELECT操作符,并在select操作符中指定需要查询字段和聚合指标。
Table table = input
.window([w: OverWindow] as "w")
.select("a, b.sum over w, c.min over w");
无界Over Windows
-
可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义
Over windows -
无界的
over window是使用常量指定的
// 无界的事件时间 over window
.window(Over.partitionBy("a").orderBy("rowtime").preceding(UNBOUNDED_RANGE).as("w"))
//无界的处理时间 over window
.window(Over.partitionBy("a").orderBy("proctime").preceding(UNBOUNDED_RANGE).as("w"))
// 无界的事件时间 Row-count over window
.window(Over.partitionBy("a").orderBy("rowtime").preceding(UNBOUNDED_ROW).as("w"))
//无界的处理时间 Row-count over window
.window(Over.partitionBy("a").orderBy("proctime").preceding(UNBOUNDED_ROW).as("w"))
有界Over Windows
- 有界的
over window是用间隔的大小指定的
// 有界的事件时间 over window
.window(Over.partitionBy("a").orderBy("rowtime").preceding("1.minutes").as("w"))
// 有界的处理时间 over window
.window(Over.partitionBy("a").orderBy("proctime").preceding("1.minutes").as("w"))
// 有界的事件时间 Row-count over window
.window(Over.partitionBy("a").orderBy("rowtime").preceding("10.rows").as("w"))
// 有界的处理时间 Row-count over window
.window(Over.partitionBy("a").orderBy("procime").preceding("10.rows").as("w"))
跳转顶部
SQL中的Over Windows
用Over做窗口聚合时,所有聚合必须在同一窗口上定义,也就是说必须是相同的分区、排序和范围
目前仅支持在当前行范围之前的窗口
ORDER BY必须在单一的时间属性上指定
SELECT COUNT(amount) OVER (
PARTITION BY user
ORDER BY proctime
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
FROM Orders
跳转顶部
函数
一些内置函数
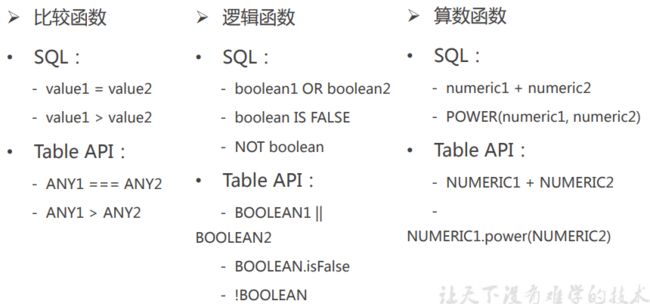

用户自定义函数
-
用户定义函数(
User-defined Functions,UDF)是一个重要的特性,它们显著地扩展了查询的表达能力 -
在大多数情况下,用户定义的函数必须先注册,然后才能在查询中使用
-
函数通过调用
registerFunction()方法在TableEnvironment中注册。当用户定义的函数被注册时,它被插入到TableEnvironment的函数目录中,这样Table API或SQL解析器就可以识别并正确地解释它
跳转顶部
标量函数(Scalar Functions)
用户定义的标量函数,可以将0、1或多个标量值,映射到新的标量值
为了定义标量函数,必须在 org.apache.flink.table.functions 中扩展基类Scalar Function,并实现(一个或多个)求值(eval)方法
标量函数的行为由求值方法决定,求值方法必须公开声明并命名为 eval
package udf;
import beans.SenSorReading;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.types.Row;
public class udfTest1_ScalaFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
String filePath = "src/main/resources/sensor.txt";
DataStreamSource<String> inputStream = env.readTextFile(filePath);
//转换成POJO
SingleOutputStreamOperator<SenSorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SenSorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
//将流转换成表
Table sensorTable = tableEnv.fromDataStream(dataStream, "id,timeStamp as ts,temperature as temp");
//自定义标量函数,求id的哈希值
//需要在环境中注册UDF
HashCode hashCode = new HashCode(20);
tableEnv.registerFunction("hashCode", hashCode);
//table API
Table resultTable = sensorTable.select("id, ts, hashCode(id)");
//SQL
tableEnv.createTemporaryView("sensor", sensorTable);
Table SQLResult = tableEnv.sqlQuery("select id,ts,hashCode(id) from sensor");
tableEnv.toAppendStream(resultTable, Row.class).print("table");
tableEnv.toAppendStream(SQLResult, Row.class).print("sql");
env.execute();
}
//实现自定义的ScalarFunction
public static class HashCode extends ScalarFunction {
//这个是一个种子,随便给不给
private int factor = 13;
public HashCode(int factor) {
this.factor = factor;
}
//输出的类型是按照自己的需求来自定义的,但是必须是public的,和方法名必须是eval
public int eval(String str) {
return str.hashCode() * factor;
}
}
}
跳转顶部
表函数(Table Functions)
用户定义的表函数,也可以将0、1或多个标量值作为输入参数;与标量函数不同的是,它可以返回任意数量的行作为输出,而不是单个值
为了定义一个表函数,必须扩展 org.apache.flink.table.functions 中的基类TableFunction并实现(一个或多个)求值方法
表函数的行为由其求值方法决定,求值方法必须是 public 的,并命名为 eval
package udf;
import beans.SenSorReading;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import scala.Tuple2;
public class udfTest2_TableFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1. 读取数据
DataStreamSource<String> inputStream = env.readTextFile("src/main/resources/sensor.txt");
// 2. 转换成POJO
DataStream<SenSorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SenSorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
// 3. 将流转换成表
Table sensorTable = tableEnv.fromDataStream(dataStream, "id, timeStamp as ts, temperature as temp");
// 4. 自定义表函数,实现将id拆分,并输出(word, length)
// 4.1 table API
Split split = new Split("_");
// 需要在环境中注册UDF
tableEnv.registerFunction("split", split);
Table resultTable = sensorTable
.joinLateral("split(id) as (word, length)")
.select("id, ts, word, length");
// 4.2 SQL
tableEnv.createTemporaryView("sensor", sensorTable);
Table resultSqlTable = tableEnv.sqlQuery("select s.id, s.ts, spl.word, spl.length " +
" from sensor s, lateral table(split(id)) as spl(word, length)");
// 打印输出
tableEnv.toAppendStream(resultTable, Row.class).print("result");
tableEnv.toAppendStream(resultSqlTable, Row.class).print("sql");
env.execute();
}
// 实现自定义TableFunction
public static class Split extends TableFunction<Row> {
// 定义属性,分隔符
private String separator = ",";
private Tuple2<String, Integer> tuple2;
public Split() {
}
public Split(String separator) {
this.separator = separator;
}
// 必须实现一个eval方法,没有返回值
public void eval(String str) {
for (String s : str.split(separator)) {
Row row = Row.of(s, s.length());
collect(row);
}
}
@Override
public TypeInformation<Row> getResultType() {
return Types.ROW(Types.STRING, Types.INT);
}
}
}
跳转顶部
聚合函数(Aggregate Functions)
用户自定义聚合函数(User-Defined Aggregate Functions,UDAGGs)可以把一个表中的数据,聚合成一个标量值
用户定义的聚合函数,是通过继承 AggregateFunction抽象类实现的
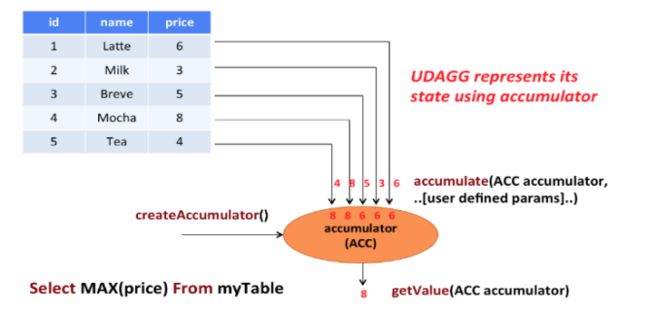
AggregationFunction要求必须实现的方法:
-
createAccumulator() -
accumulate() -
getValue()
AggregateFunction 的工作原理如下:
-
首先,它需要一个累加器(Accumulator),用来保存聚合中间结果的数据结构;可以通过调用createAccumulator() 方法创建空累加器
-
随后,对每个输入行调用函数的 accumulate() 方法来更新累加器
-
处理完所有行后,将调用函数的 getValue() 方法来计算并返回最终结果
package udf;
import beans.SenSorReading;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.table.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
public class udfTest_AggregateFunction {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1. 读取数据
DataStreamSource<String> inputStream = env.readTextFile("src/main/resources/sensor.txt");
// 2. 转换成POJO
DataStream<SenSorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SenSorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
// 3. 将流转换成表
Table sensorTable = tableEnv.fromDataStream(dataStream, "id, timeStamp as ts, temperature as temp");
// 4. 自定义聚合函数,求当前传感器的平均温度值
// 4.1 table API
AvgTemp avgTemp = new AvgTemp();
// 需要在环境中注册UDF
tableEnv.registerFunction("avgTemp", avgTemp);
Table resultTable = sensorTable
.groupBy("id")
.aggregate( "avgTemp(temp) as avgtemp" )
.select("id, avgtemp");
// 4.2 SQL
tableEnv.createTemporaryView("sensor", sensorTable);
Table resultSqlTable = tableEnv.sqlQuery("select id, avgTemp(temp) " +
" from sensor group by id");
// 打印输出
tableEnv.toRetractStream(resultTable, Row.class).print("result");
tableEnv.toRetractStream(resultSqlTable, Row.class).print("sql");
env.execute();
}
// 实现自定义的AggregateFunction
public static class AvgTemp extends AggregateFunction<Double, Tuple2<Double, Integer>>{
@Override
public Double getValue(Tuple2<Double, Integer> accumulator) {
return accumulator.f0 / accumulator.f1;
}
@Override
public Tuple2<Double, Integer> createAccumulator() {
return new Tuple2<>(0.0, 0);
}
// 必须实现一个accumulate方法,来数据之后更新状态
public void accumulate( Tuple2<Double, Integer> accumulator, Double temp ){
accumulator.f0 += temp;
accumulator.f1 += 1;
}
}
}
跳转顶部