机器学习读书笔记:样本降维
文章目录
- k近邻算法
- PCA主成分分析
-
- PCA代码
- 核化线性降维(KPCA)
- 低维嵌入(MDS)
- 流形学习
-
- 等度量映射(Isomap)
- 局部线性嵌入(LLE)
- 度量学习
k近邻算法
在《机器学习》这本书中,讲降维方法之前首先介绍了这个k近邻算法。开始不知道是为什么,仔细看完之后还是了解了作者的思路。
k近邻算法是一个不需要训练的分类算法,它的分类过程如下:
-
针对新样本 x i x_i xi,在已有的训练样本集 D D D中计算与自己最近的 k k k个最近距离的样本,距离计算可以参照聚类算法里面的介绍。
-
根据找到的这 k k k个样本的标记,根据某种决策方法(简单的投票,加权投票等,可以参考集成学习中的介绍:
)来进行输出,这个输出就是新样本 x i x_i xi的类别。
-
样本基于独立采样且同部分的前提。
-
不需要训练过程,而且可以慢慢的将所有样本累计成训练集,这种方式被称为“懒惰学习”。
这个算法介绍完之后,分析了这个算法中的特例,最近邻算法,也就是 k = 1 k=1 k=1的情况下的性能。 k = 1 k=1 k=1的话,那么新样本 x i x_i xi的类别就是依赖于训练样本集中最近的那个样本,那么分类错误的情况就是新样本的实际类别与最近的不一致。用贝叶斯分类器的逻辑来分析的话, x i x_i xi样本为类别 c c c的计算方式为 P ( c ∣ x ) P(c|x) P(c∣x)。那么不一致的概率为 1 − P ( c ∣ x ) P ( c ∣ z ) 1-P(c|x)P(c|z) 1−P(c∣x)P(c∣z), z z z为训练样本集中离 x i x_i xi最近的那个样本。
经过一堆的推导,这个简单的分类算法的错误率是不高于最优贝叶斯分类器错误率的两倍的。
但是,这个有一个重要的前提,就是需要样本 x i x_i xi和这个最近距离的样本 z z z,是可以在一个非常小的距离内,比如正数 ϵ = 0.001 \epsilon = 0.001 ϵ=0.001,也就是 ∣ ∣ x i − z ∣ ∣ = 0.001 ||x_i-z||=0.001 ∣∣xi−z∣∣=0.001。
如果只有一个属性,需要有1000个样本才能达到如此的采样密度,两个属性就是1000*1000,也就是一百万个样本。在真实场景下,样本的属性数是远远大于这个数的,所以需要进行降维处理,才引出了后面这一截的内容,至于上面为什么要在一个非常小的距离内才能推导出来,咱也不懂,也不想搞懂了,估计也搞不懂了,咱知道这个结果就好。
PCA主成分分析
主成分分析是通过一系列的计算,分析得到样本 d d d个属性的重要度排序,然后就可以选择性的进行降维了,降到多少维( d ′ d^{\prime} d′),就取top d ′ d^{\prime} d′的属性就好了。作为一个数学不怎么好的码农,这里记录一下这个过程,至于为什么要这么计算,就不是我能说明白的了,有兴趣的朋友可以自行研究。
这里需要了解另外两个概念:协方差与特征值分解。我把这些记录在这里,便于自己后续查资料。
直接对着书上给出的过程进行简单的分析。

-
假设有样本集 D = { x 1 , x 2 . . . x m } D=\lbrace x_1, x_2... x_m \rbrace D={x1,x2...xm},每个样本 x x x有 d d d个属性。
-
协方差矩阵 X X T XX^T XXT是这么计算得到的:
X = { x 11 x 12 … x 1 d x 21 x 22 … x 2 d … … … … x m 1 x m 2 … x m d } X=\begin{Bmatrix} x_{11} & x_{12} &\dots & x_{1d} \\ x_{21} & x_{22} &\dots & x_{2d} \\ \dots & \dots & \dots & \dots \\ x_{m1} & x_{m2} &\dots & x_{md} \\ \end{Bmatrix} X=⎩⎪⎪⎨⎪⎪⎧x11x21…xm1x12x22…xm2…………x1dx2d…xmd⎭⎪⎪⎬⎪⎪⎫每一行为一个样本,所以总共是 d d d列。
那么 X T X^T XT为 X X X的转置矩阵, X T X^T XT为一个 d d d行, m m m列的矩阵:
X T = { x 11 x 21 … x m 1 x 12 x 22 … x m 2 … … … … x 1 d x 2 d … x m d } X^T=\begin{Bmatrix} x_{11} & x_{21} &\dots & x_{m1} \\ x_{12} & x_{22} &\dots & x_{m2} \\ \dots & \dots & \dots & \dots \\ x_{1d} & x_{2d} &\dots & x_{md} \\ \end{Bmatrix} XT=⎩⎪⎪⎨⎪⎪⎧x11x12…x1dx21x22…x2d…………xm1xm2…xmd⎭⎪⎪⎬⎪⎪⎫
所以 X X T XX^T XXT就是一个矩阵乘法:其中新的矩阵的第i行第j列:
X X i j T = x i 1 ∗ x j 1 + x i 2 ∗ x j 2 + ⋯ + x i d ∗ x j d XX^T_{ij} = x_{i1}*x_{j1}+x_{i2}*x_{j2}+ \dots +x_{id}*x_{jd} XXijT=xi1∗xj1+xi2∗xj2+⋯+xid∗xjd
所有的 x i x_i xi都是经过了第一步中心化之后的值。 -
所有的样本 x i x_i xi都在第一步中做了中心化,而且,所有的样本都是基于独立采样获得的,也就是样本之间是无关的。所以可以得到:
X X i j T = 0 ; i ≠ j X X i j T = ∑ k = 0 d x i k 2 ; i = j XX^T_{ij} = 0; i\neq j \\ XX^T_{ij} = \sum_{k=0}^d x_{ik}^2; i=j XXijT=0;i=jXXijT=k=0∑dxik2;i=j
也就是说 X X T XX^T XXT是一个 d ∗ d d*d d∗d对角矩阵,对角线上以外的值均为0。所以可以对其做特征值分解。 -
书上描述是经过**“最近重构性”和“最大可分性”**两个角度去做推导可以得出(推导过程看不太懂,有兴趣的朋友自己去理解):
X X T W = λ W XX^TW=\lambda W XXTW=λW
这就是针对 X X T XX^T XXT做特征值分解,得到特征值 λ \lambda λ和特征向量 W W W,特征值分解也不说了,大家百度一下就知道了。可以直接用numpy包提供的函数就行求解。 -
根据特征值分解的情况, X X T XX^T XXT是一个 d ∗ d d*d d∗d的矩阵,所以会有 d d d个 λ \lambda λ特征值和对应的 d d d个特征向量 W W W, w i w_i wi为列向量,每个特征向量有 d d d个分量。
-
将 d d d个 λ \lambda λ进行排序获得 ( λ 1 , λ 2 … λ d ) (\lambda_1,\lambda_2 \dots \lambda_d) (λ1,λ2…λd),取其前面的 d ′ d^{\prime} d′个特征值和特征向量 ( w 1 , w 2 … w d ′ ) (w_1,w_2 \dots w_{d^{\prime}}) (w1,w2…wd′)。
-
d ′ d^\prime d′个特征向量形成了一个转换矩阵( d ∗ d ′ d*d^{\prime} d∗d′):
W = ( w 1 , w 2 … w d ′ ) W = { w 11 w 21 … w d ′ 1 w 12 w 22 … w d ′ 2 … … … … w 1 d w 2 d … w d ′ d } W=(w_1,w_2 \dots w_{d^{\prime}}) \\ W=\begin{Bmatrix} w_{11} & w_{21} & \dots & w_{d^{\prime}1} \\ w_{12} & w_{22} & \dots & w_{d^{\prime}2} \\ \dots & \dots & \dots & \dots \\ w_{1d} & w_{2d} & \dots & w_{d^{\prime}d} \\ \end{Bmatrix} W=(w1,w2…wd′)W=⎩⎪⎪⎨⎪⎪⎧w11w12…w1dw21w22…w2d…………wd′1wd′2…wd′d⎭⎪⎪⎬⎪⎪⎫ -
所以用一个 d d d维样本 x i x_i xi,来乘以这个转换矩阵 W W W,根据矩阵乘法: 1 ∗ d 1*d 1∗d的向量乘以一个 d ∗ d ′ d*d^{\prime} d∗d′的矩阵,可以获得一个 1 ∗ d ′ 1*d^{\prime} 1∗d′的向量,从而起到了降维的效果。
PCA代码
def pca(dataMat, topNfeat=9999999):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #remove mean
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
eigValInd = argsort(eigVals) #sort, sort goes smallest to largest
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
lowDDataMat = meanRemoved * redEigVects#transform data into new dimensions
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat
核化线性降维(KPCA)
这一节在书中是另外的一章节,但是我不怎么看的明白,大概理解的意思是使用一个核函数将一个 n n n维的样本先升维到 k , k > d k, k>d k,k>d维,使得可以线性可分之后,然后再在 k k k维的基础上进行PCA分析。
至于核函数,在支持向量机那一章写过:
低维嵌入(MDS)
PCA主成分分析方法是基于样本的“最近重构性”和“最大可分性”两个角度进行分析得到的推导过程。而低维嵌入方法是基于如下思路:如果样本集 D D D在 d d d个属性中的距离 d i s t i j dist_{ij} distij能在缩放成 d ′ d^{\prime} d′后保持不变,那么就可以将 d ′ d^{\prime} d′个属性作为 d d d个属性的低维嵌入,这个过程是可以求得一个 d ∗ d ′ d*d^{\prime} d∗d′的转换矩阵 W W W对样本进行转换,成为“多维缩放”。
MDS算法的过程描述,实际上就是描述了这个矩阵的生成过程:

-
首先要获得基于样本集的距离(基于某种距离计算方法)矩阵 D D D:
D i j = d i s t i j D = { d i s t 11 d i s t 12 … d i s t 1 m d i s t 21 d i s t 22 … d i s t 2 m … … … … d i s t m 1 d i s t m 2 … d i s t m m } D_{ij}=dist_{ij}\\ D=\begin{Bmatrix} dist_{11} & dist_{12} & \dots & dist_{1m} \\ dist_{21} & dist_{22} & \dots & dist_{2m} \\ \dots & \dots & \dots & \dots \\ dist_{m1} & dist_{m2} & \dots & dist_{mm} \\ \end{Bmatrix} Dij=distijD=⎩⎪⎪⎨⎪⎪⎧dist11dist21…distm1dist12dist22…distm2…………dist1mdist2m…distmm⎭⎪⎪⎬⎪⎪⎫ -
通过这个距离矩阵计算一个内积矩阵 B B B,这个矩阵的定义是 Z T Z Z^TZ ZTZ, Z Z Z是降维之后样本的表达,也就是从样本空间 X X X中砍掉一些属性,此时 Z Z Z是未知数,需要通过先计算 B B B来得出。
-
经过一通骚气的推导,照旧不解释,大致的概念就是因为多维缩放的思路是距离保持不变,所以在样本空间中的距离 ∣ ∣ x i − x j ∣ ∣ ||x_i-x_j|| ∣∣xi−xj∣∣是等于在低维样本空间 Z Z Z下的 ∣ ∣ z i − z j ∣ ∣ ||z_i-z_j|| ∣∣zi−zj∣∣的。可以得到矩阵 B B B每个元素的计算方法:
b i j = − 1 2 ( d i s t i j 2 − d i s t i ⋅ 2 − d i s t ⋅ j 2 + d i s t ⋅ ⋅ 2 ) b_{ij} = -\frac{1}{2}(dist_{ij}^2-dist_{i·}^2-dist_{·j}^2+dist_{··}^2) bij=−21(distij2−disti⋅2−dist⋅j2+dist⋅⋅2)
其中:
d i s t i ⋅ 2 = 1 m ∑ j = 1 m d i s t i j 2 ; 第 i 行 的 平 方 和 的 均 值 d i s t ⋅ j 2 = 1 m ∑ i = 1 m d i s t i j 2 ; 第 j 列 的 平 方 和 的 均 值 d i s t ⋅ ⋅ 2 = 1 m 2 ∑ i = 1 m ∑ j = 1 m d i s t i j 2 ; 距 离 矩 阵 D 的 平 方 和 的 均 值 dist_{i·}^2=\frac{1}{m}\sum_{j=1}^mdist_{ij}^2; 第i行的平方和的均值 \\ dist_{·j}^2=\frac{1}{m}\sum_{i=1}^mdist_{ij}^2; 第j列的平方和的均值 \\ dist_{··}^2=\frac{1}{m^2}\sum_{i=1}^m\sum_{j=1}^mdist_{ij}^2; 距离矩阵D的平方和的均值 \\ disti⋅2=m1j=1∑mdistij2;第i行的平方和的均值dist⋅j2=m1i=1∑mdistij2;第j列的平方和的均值dist⋅⋅2=m21i=1∑mj=1∑mdistij2;距离矩阵D的平方和的均值 -
矩阵 B B B计算出来之后,对 B B B做特征值分解:$ B=V\Lambda VT$,V为特征向量组成的矩阵,$\Lambda$为特征值组成的对角阵。又因为$B=ZTZ , 所 以 ,所以 ,所以Z^TZ=V\Lambda VT$,所以可以得到$Z=\Lambda{1/2}VT$,这个怎么算出来的不知道,只知道反过来验证一下:$ZT=\Lambda{1/2}V$,因为$\Lambda$是对角阵,求个转置还是本身,$VT 的 转 置 就 是 的转置就是 的转置就是V , 然 后 再 乘 一 下 就 是 ,然后再乘一下就是 ,然后再乘一下就是V\Lambda V^T 。 也 就 是 说 把 矩 阵 。也就是说把矩阵 。也就是说把矩阵B 做 完 特 征 值 分 解 之 后 就 可 以 直 接 计 算 得 到 降 维 之 后 样 本 空 间 做完特征值分解之后就可以直接计算得到降维之后样本空间 做完特征值分解之后就可以直接计算得到降维之后样本空间Z$了。
-
在特征值分解中,如果 Λ \Lambda Λ包含了 d ∗ d^* d∗个非零的特征值, d ∗ < d d^*
d∗<d ,那么 Λ \Lambda Λ就是一个 d ∗ ∗ d ∗ d^**d^* d∗∗d∗的对角阵, Z Z Z的样本空间就是一个 m ∗ d ∗ m*d^* m∗d∗的矩阵。达到降维的目的。但是如果 d ∗ = d d^*=d d∗=d,我想应该就是无法进行降维计算。
流形学习
等度量映射(Isomap)
Isomap算法实际上就是将MDS中的dist距离计算增加了一种新的定义:

两个样本之间的距离计算不是通过闵可夫斯基距离或者欧式距离进行计算。而是通过下面几个步骤去计算 x i x_i xi与 x j x_j xj两个样本点之间的距离。
- 对所有样本点 x i x_i xi,找到样本点的k近邻,这个近邻寻找还是通过欧式距离进行计算,这就是所谓的局部的概念吧。
- 所有的样本点与k近邻之间的距离形成了一张无向图,然后再通过迪杰斯特拉算法找到 x i x_i xi和 x j x_j xj之间的最短距离,用这个距离作为MDS算法中矩阵D的值。
我自己对这个东西的理解是这样的,借用书上的图:
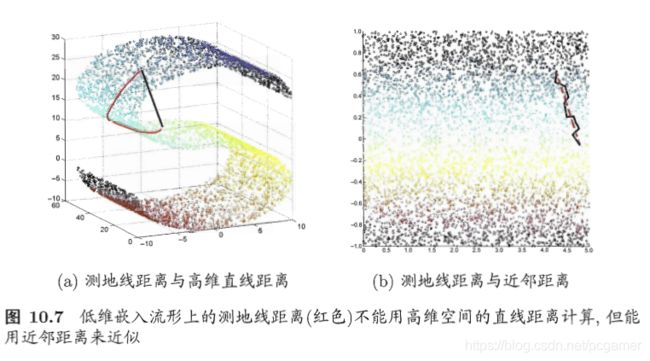
从某种意义上讲,高维的欧式距离,也就是图中的黑线距离是不可达的,也就是没有什么业务含义的。所以只能顺着这个分布图形的曲面去进行计算距离。而局部的欧式距离又是可以的(什么流形在局部与欧式距离同胚大概就是这个意思吧)。
局部线性嵌入(LLE)
对这个算法我是这么理解的,和MDS类似。MDS是想在降维后保证样本之间的距离不变。而LLE(Locally Linear Embedding)是试图保持样本 x i x_i xi与周边的近邻的线性关系。
- 比如 x i x_i xi的近邻参数 k = 3 k=3 k=3,那么近邻关系为:
x i = w i j x j + w i k x k + w i l x l x_i = w_{ij}x_j+w_{ik}x_k+w_{il}x_l xi=wijxj+wikxk+wilxl
或者说 x i x_i xi可以通过他的近邻来进行表示。
- 然后算法试图找到一组 w w w,使得:
min w ∑ i = 1 m ∣ ∣ x i − ∑ j ∈ Q i w i j x j ∣ ∣ 2 2 s . t . ∑ j ∈ Q i w i j = 1 \min_{w}\sum_{i=1}^m{||x_i-\sum_{j\in Q_i}{w_{ij}x_j}||_2^2} \\ s.t. \sum_{j\in Q_i}{w_{ij}=1} wmini=1∑m∣∣xi−j∈Qi∑wijxj∣∣22s.t.j∈Qi∑wij=1
其中 Q i Q_i Qi是样本 x i x_i xi的近邻的下标集合。我理解这是要找到一组w,使得样本 x i x_i xi与其线性表示的差距最小。
-
然后可以求解出:
w i j = ∑ k ∈ Q i C j k − 1 ∑ l , s ∈ Q i C l s − 1 C j k = ( x i − x j ) T ( x i − x k ) w_{ij} = \frac{\sum_{k\in Q_i}C_{jk}^{-1}}{\sum_{l,s\in Q_i}C_{ls}^{-1}} \\ C_{jk}=(x_i-x_j)^T(x_i-x_k) wij=∑l,s∈QiCls−1∑k∈QiCjk−1Cjk=(xi−xj)T(xi−xk) -
w w w求出来之后,因为降维后与降维前的线性关系需要保持不变,所以对于降维后的样本表示 z i z_i zi必须满足:
min z ∑ i = 1 m ∣ ∣ z i − ∑ j ∈ Q i w i j z j ∣ ∣ \min_z\sum_{i=1}^m{||z_i-\sum_{j\in Q_i}{w_{ij}z_j}||} zmini=1∑m∣∣zi−j∈Qi∑wijzj∣∣
上次是通过 x x x求解 w w w,这次是通过 w w w求解 z z z。 -
令 M = ( I − W ) T ( 1 − W ) M=(I-W)^T(1-W) M=(I−W)T(1−W),将上面的公式可以改写为:
min Z t r ( Z M Z T ) s . t . Z Z T = I \min_Ztr(ZMZ^T) \\s.t. ZZ^T=I Zmintr(ZMZT)s.t.ZZT=I -
老套路,对M特征值分解,M分解完之后的 d ′ d^{\prime} d′个最小的特征值对应的特征向量组成的矩阵即为 Z T Z^T ZT。

度量学习
上述的几种降维方法,基本上都是基于某种距离度量(PCA的最近重构性,最大可分性,MDS的距离矩阵,流形学习的测地距离,最小路径计算等),都是基于距离的某种度量。这些度量方法中都是确定的方法和参数进行计算,而度量学习是想将这些参数通过样本训练、学习来确定。
大概的过程如下:
-
在计算欧式距离的基础上增加属性的权重值 W = ( w 1 , w 2 … w d ) W=(w_1,w_2 \dots w_d) W=(w1,w2…wd),是的计算距离公式变成:
d i s t i j = w 1 d i s t i j , 1 + w 2 d i s t i j , 2 + ⋯ + w d d i s t i j , d dist_{ij}=w_1dist_{ij,1}+w_2dist_{ij,2}+\dots+w_ddist_{ij,d} distij=w1distij,1+w2distij,2+⋯+wddistij,d -
公式可以写成:
( x i − x j ) T W ( x i − x j ) W = d i a g ( w ) (x_i-x_j)^TW(x_i-x_j) \\ W=diag(w) (xi−xj)TW(xi−xj)W=diag(w)
其中的 W W W就是一个 d ∗ d d*d d∗d对角矩阵, W i i = w i W_{ii} = w_i Wii=wi。 -
上面的 W W W中的非对角元素为0,是因为所有的属性全部独立,无关联。如果有关联的话,对角元素就是非0的。然后这个矩阵就写成 M M M,成为度量矩阵。距离公式也成为马氏距离:
( x i − x j ) T M ( x i − x j ) (x_i-x_j)^TM(x_i-x_j) (xi−xj)TM(xi−xj) -
学习的目标就是训练这个M。训练M的话就需要确认一个优化目标,需要根据某种学习方法来确定,书中给出的是按照近邻分类器这种学习方法来制定这个优化目标。一通推导之后优化目标是:

- 后面就是各种推导和学习计算了,书中没有,我也不想继续研究这个了。大概就是通过这个优化目标,通过训练集样本进行计算可以得到这个M的最优值。从而达到学习的效果。