【深度学习】计算机视觉(二)——认识和基础(下)
文章目录
- step4:深度学习和计算机视觉基础
-
- 图像表示
- 图像分类——得分函数
- 分类评价——损失函数
- 结果概率——Softmax分类器
- 反向传播——梯度下降法
-
- 梯度下降法
- 链式法则
- 分类器【核函数待补充】
- step5:神经网络部分详解
-
- 神经网络基础
- 激活函数
-
- 常用的激活函数
- 激活函数与反向传播
- 过拟合问题
-
- 惩罚力度对结果的影响
- 损失函数(成本函数)
- step6:深度学习与神经网络概念
step4:深度学习和计算机视觉基础
对深度学习有了一个基本的了解,通过学习python库也掌握了很多矩阵的处理方法,但还是无法将计算机处理图片的过程理解清楚。图片和矩阵有什么关系?具体怎么处理图片呢?
图像表示
在计算机中,一张图片被表示成三维数组的形式,每个像素的值从0到255,从0到255值越高图像越明亮。
若有一张图片格式为300*100*3,表示图片的高为300,宽为100,通道为3(最常见的jpg图像的RGB就是三个通道,可以从图片调色的角度去理解通道)。就以RGB通道的图像为例,这是我理解的图片数组的存储形式:

图像分类——得分函数
对图像分类用到得分函数,它是一个线性函数f(x) = W * x + b,函数的输入x是图片存储在计算机中的数组(以下简称图片),输出是该图片对应每个标签的得分,W表示标签的权重,b是偏移量。
文字有些抽象,举个例子,例如对一个32*32*3的图像作5分类(5个类别的标签分别为:小狗、小猫、小兔、小鸡、小猪)。

我们知道32x32x5的矩阵有5120个元素,将三维矩阵展开为1x5120的列矩阵,作为x。对于每个像素块,它对于图片分类的影响是不一样的,例如背景部分的像素块权重应该很小,而物体部分的像素块对图像分类的影响很大,因此,每个像素块都有对应的权重,也就是说需要5120个权重值,我们把它展开为5120x1的行矩阵,作为W。由矩阵的乘法得到:

注意,“得分”理解为图片被分为某一类的分值,总共有多少类别,就要进行多少次乘法。可以直接放在一个矩阵里一次性计算:

这样就得到了该图片每个类别的得分。但是由于某些影响,结果可能不是w*x这么简单,需要通过偏移量b来调整,所以每个标签的最终得分需要再加上bi:
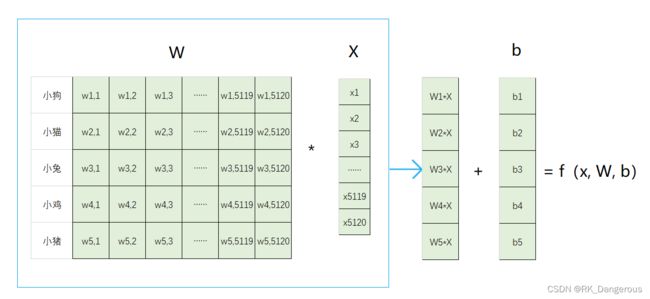
对于W中的值,如果是正数表示对分为该类别具有积极影响,是负数表示对分为该类别具有抑制作用;若数值越大表示影响越大,若数值越小(近似于0)表示该像素对图片的分类不起作用。
这些数据从何而来?
x是经过预处理之后得到的,没什么疑问。而W和b最初可以是任意的,可能得到很离谱的结果,我们需要通过不断地学习去更新W和b的值,从而使结果越来越精确。
分类评价——损失函数
对于不断更新W和b得到方案,如何去评价分类的好坏,衡量分类的结果?根据数学思维,单纯的"好"与"不好"去评价显然是不太严谨和服众的,我们需要数值去直观地评价——利用损失函数。一般不同的分类任务损失函数是不同的。
举个例子:这是三分类得到的某次结果

定义损失函数为:

对于图片i,我们已知它的实际标签(人为确认的),那么yi就是这个图片这个标签对应的结果,j表示该图片其他标签的结果。例如对于第一个小鸡图片,那么yi就是"小鸡"的结果3.2,sj有两个,分别是5.1和-1.7。损失函数的值越大,表示我们的错误越离谱。 我们观察这个式子,如果sy大于sj,即正确类别的得分比错误类别的得分高,那么sj-sy小于0(先忽略后面的+1),max取0表示这里暂时没有发生错误,然后每一个错误类别都计算后加和。加1是防止当错误分类的得分只比正确分类小一点点,此时认为是正确分类,有一定的巧合性在,相当于容忍程度,+1使得sj和sy必须相差较大才满足条件。
计算结果如下:
# 图1:
"""
L1
= max(0, 5.1-3.2+1) + max(0, -1.7-3.2+1)
= max(0, 2.9) + max(0, -3.9)
= 2.9 + 0
= 2.9
"""
# 图2:
"""
L2
= max(0, 1.3-4.9+1) + max(0, 2.0-4.9+1)
= max(0, -2.6) + max(0, -1.9)
= 0 + 0
= 0
"""
# 图3:
"""
L3
= max(0, 2.2-(-3.1)+1) + max(0, 2.5-(-3.1)+1)
= max(0, 5.3) + max(0, 5.6)
= 5.3 + 5.6
= 10.9
"""
注意损失函数的设置不能过于关注局部,否则会产生"过拟合"。类似于上式中+1的作用,我们一般会在损失函数中再添加一项"正则化惩罚项"λR(W),只考虑权重参数对模型的影响,而与数据无关。即损失函数=数据损失+正则化惩罚项。其中,R(W)为所有w的平方和:

λ是一个比例系数,越大表示越不希望过拟合(过拟合就是某几个权重特别特别大,会对结果有决定性的影响作用,我们一般不希望模型太复杂,希望权重分配地比较平均。神经网络是十分强大的,所以我们往往不需要考虑如何让它变得更强)。
算出测试集的每个损失函数求平均值即为该模型的总损失函数。
结果概率——Softmax分类器
之前使用得分函数可以得到每个图片对应每个标签的得分,不够直观,我们希望得到它可能被正确分类的概率。
以小鸡图片的某次结果为例,先使用exp(x)函数将得分进行转化:

exp(x)能在保持偏序关系下放大差距,且是一一映射。
这样得到的数值可以之间根据比例得到它对应的概率。例如被分为小鸡的概率是24.5 / (24.5 + 164.0 + 0.18) = 0.13。
注意在编程时防止exp(x)溢出,可以在x后面加一个常数控制。
归一化之后,我们再去求它的损失就更公平了。由于我们只关心被正确分类的概率,即被分类为小鸡的概率肯定是越高越好,即越接近1越好。用log(p)表示损失,p在0-1之间,当p越来越接近1,损失越接近0;p越小损失越大(底数的选取不影响模型的比较)。为什么选取这个函数?可以理解为我们用指数函数进行一系列的变化,再用对数函数变回去(它们是反函数)。

因为log(p)的值是负数,所以在计算损失时还需要加上负号把损失的数值变为正数。
反向传播——梯度下降法
以上就是识别和分类的主要过程(前向传播),之前说过W和b是要更新的,如何更新就用到了反向传播。
梯度下降法

先以f(x)=x²为例:
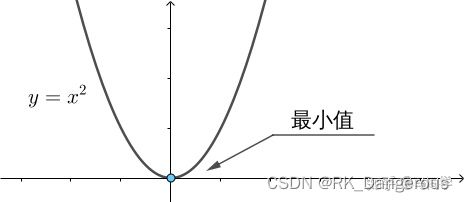
我们很容易通过求导或者图像得到函数的最小值。如何使用梯度下降法找到函数的最小值呢?
梯度下降法是用来计算函数最小值的。它的思路很简单,想象在山顶放了一个球,一松手它就会顺着山坡最陡峭的地方滚落到谷底。如果运用梯度下降法的话,就可以通过一步步地滚动最终来到谷底,也就是找到了函数的最小值。
为了方便后面的学习,我找到了高数书上关于梯度的解释。

我的理解:梯度是一个向量,以曲面为例,在空间坐标系xyz中,梯度被分解到x和y上,合成的向量的方向就是曲面变化最快的那个方向,而值就是变化率。
还是以f(x)=x²为例,假设起点在x0 = 10处,也就是将球放在这里。
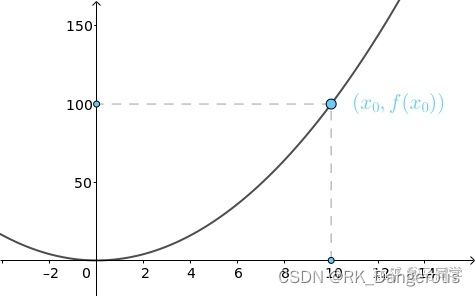
它的梯度是一维向量,在x轴方向:
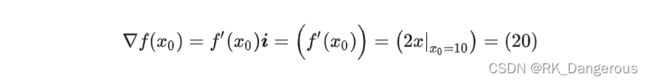
正数表示它指向函数值增长最快的方向(那我们可以给梯度加一个负号得到的向量指向函数值减小最快的方向):
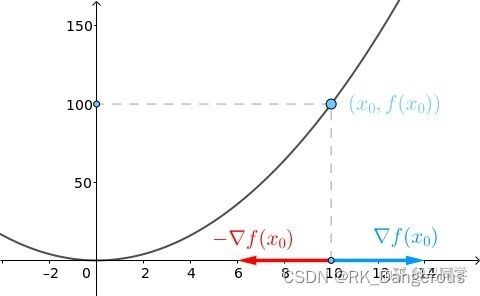
将x0也看成向量,就可以进行向量的运算啦。通过和-∇f(x0)相加,得到新的向量x1,表示移动了一段距离。
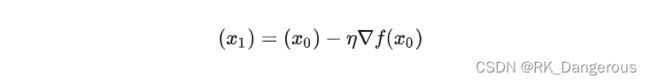
其中,ɳ称为步长,通过它可以控制移的动距离。这里设置ɳ=0.2,则:

表示小球走到了x1 = 6的位置。看下图红色标注部分更容易理解梯度的概念,它这里是在x轴上的方向,梯度的维度是图像在坐标轴的投影,黄色虚线是小球在函数曲线上梯度下降的结果,不要混淆。

接下来再计算x1的梯度为12,仍以步长0.2向梯度的反方向走到x2 = 3.6处。以此类推,小球不断下落,横坐标(沿着梯度的方向)逐渐靠近最低点。

观察每一次梯度下降的模长||∇f(x)||是逐渐减小的,因此称这种方法叫做梯度下降法。由于最终梯度趋于0,那么解出的就是接近于最小值。
之前说到了步长用来控制每次移动的距离,不同的步长对结果也有很大的影响。我们设置的0.2是比较合适的,经过大概10次迭代就可以接近最小值。
如果设置步长太小,如ɳ=0.01,迭代 20 次后离谷底还很远,实际上 100 次后都无法到达谷底:
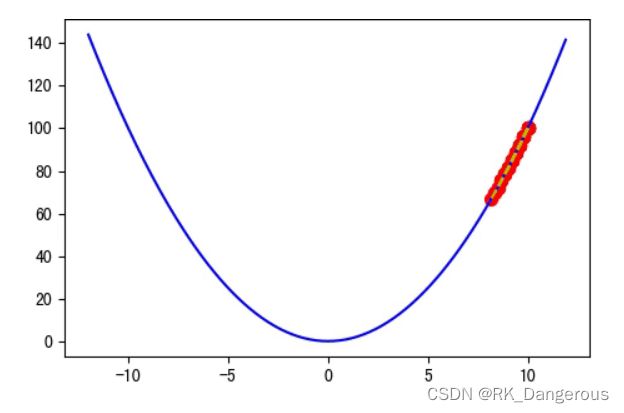
如果设置步长太大,如ɳ=1,这个时候会在两个点来回震荡:

继续加大步长,如ɳ=1.1,反而会越过谷底,不断上升:
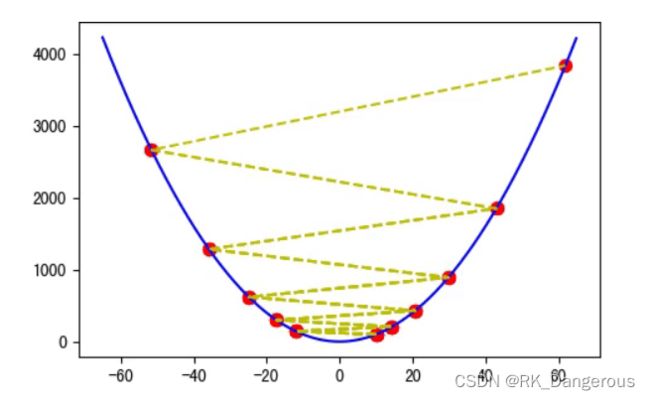
类比三维图像,以下面的函数为例:

设初始点p0=(-3.5, -3.5),步长为0.1,则梯度为(-7, -14),朝梯度的反方向走下一个点p1为(-2.8, -2.1)。经过20次迭代基本上到达最低点。(附函数等高线示意图,中心点为曲面最低点)

至此,我对于梯度下降基本理解透彻了。但是我一直有一个疑问,就是对于复杂函数有多个极值点时,我们怎么确认它就是最小值呢?根据我查询资料发现,这正是梯度下降的痛点之一。
梯度下降有两大痛点:
基于梯度下降训练神经网络时,我们将冒网络落入局部极小值的风险,网络在误差平面上停止的位置并非整个平面的最低点。这是因为误差平面不是内凸的,平面可能包含众多不同于全局最小值的局部极小值。
此外,尽管在训练数据上,网络可能到达全局最小值,并收敛于所需点,我们无法保证网络所学的概括性有多好。这意味着它们倾向于过拟合训练数据。
如何解决和优化?毕竟这只是学习的开始,对梯度下降法有清晰的了解已经足够了,关于局部最小值和过拟合的处理我在后面进行进一步学习。
链式法则
反向传播是逐层进行的,梯度是一步步传的。就是在神经网络当中,由于W非常复杂,我们可能先聚焦某一部分特征,再一步一步添加条件,形如[(x*W1)W2]W3···。我们不能直接将W合并,需要一层一层解决。
这里用到一个复合函数求偏导的知识,称为链式法则。
链式法则是微积分中的求导法则,用于求一个复合函数的导数,是在微积分的求导运算中一种常用的方法。复合函数的导数将是构成复合这有限个函数在相应点的导数的乘积,就像锁链一样一环套一环,故称链式法则。
比如在函数f(x,y,z)=(x+y)z中,由于x和y在函数中较为复杂,不直接构成f,所以可以添加一个中间变量p=x+y,则函数变为f=p·z。此时再求偏导,使用链式法则,以x为例:

具体怎么传后续再继续学习。
分类器【核函数待补充】
通过得分函数,我们可以得到物体对应每个标签的得分。例如下图是由三张图片得到的分别对应三个标签的得分:

1. Softmax分类器
我们如何确定该物体属于哪一类?这就要使用分类器。前面已经讲过,可以利用Softmax分类器计算出物体对应每个标签的概率,选择最大概率(最大得分)作为物体的分类,同时还可以得到物体属于某一类别的概率。softmax可以直接端到端地训练分类,比较常用,但是注意类别数太多会崩。
2. SVM分类器
支持向量机(Support Vector Machine, SVM),主要用于解决模式识别领域中的数据分类问题,属于有监督学习的一种。注意:SVM需要训练。
- 线性核SVM: 一般应用于多分类。
- 非线性核SVM: 一般应用于二分类问题。
支持向量机是从两类线性可分情况下的最优分类超平面中提出的,所谓最优分类超平面是指分类超平面不但能将两类数据样本无错误地分开,而且要使两类数据样本的分类间隔最大。这样可以保证获得的分类器既能很好地区分训练集中的数据样本,也能对未知类标号的数据样本有很好的泛化能力。
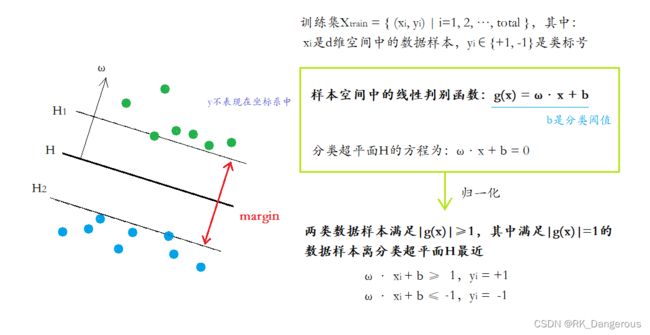
所谓分类间隔(margin)如图,假设分类超平面为H,H1和H2分别为通过两类数据样本中离分类超平面最近的点并且平行于分类超平面的平面,则H1和H2之间的距离叫做分类间隔,ω称为分类超平面H的法向量。
每个分类超平面(决策面)对应了一个线性分类器。我们可以把多分类问题化成多个二分类问题,对于每一个二分类问题都设置一个决策面。例如“小鸡、小兔、小狗”的三分类问题,我们可以分成3个二分类问题:“是/否属于小鸡”、“是/否属于小兔”、“是/否属于小狗”。
我们要找到一个最优分类超平面,即分类间隔最大,如何求出分类间隔以及最大的分类间隔?以二维空间举例,x1和x2是在超平面H1和H2上的两个向量,如图:
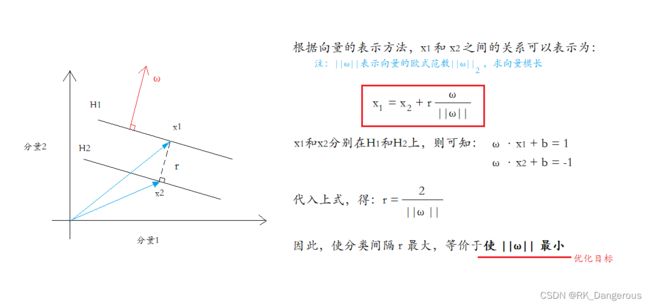
我们根据优化目标——使分类间隔最大,训练分类器参数,使得ω最小,等价为使得1/2 * ||ω||² 最小。
上述是训练集线性可分的理想情况,若训练集线性不可分,即无法完全恰好地用线性平面分类,则引入松弛变量ε:

松弛变量的作用是在数据集线性不可分时,使分类超平面更加鲁棒。惩罚参数C是某个指定的常数,实现控制错分样本的比例与算法复杂度之间的折中,C越大时对误分类的惩罚越大。
对于上述最小化的约束优化问题,可以通过构造Lagrange函数转化为它的对偶问题(最大化的约束优化问题),约束条件、优化目标、Lagrange构造过程、最优分类函数等暂略(公式详见我的书P126-P127)。
若原始特征空间中的分类问题是非线性的,可以通过某种非线性变换将原始特征空间中的非线性分类问题转换为一个高维空间中的线性分类问题,从而在新的空间中求取最优分类超平面。通过定义核函数 K(xi, xj) = φ(xi) · φ(xj)来实现,影射函数φ将训练样本影射到新的空间。常用的核函数以及核函数的原理暂略。
step5:神经网络部分详解
神经网络基础
首先需要了解以下五个概念:
- 神经元(Neuron)
就像形成我们大脑基本元素的神经元一样,神经元形成神经网络的基本结构。想象一下,当我们得到新信息时我们该怎么做。当我们获取信息时,我们一般会处理它,然后生成一个输出。类似地,在神经网络的情况下,神经元接收输入,处理它并产生输出,而这个输出被发送到其他神经元用于进一步处理,或者作为最终输出进行输出。

- 权重(Weights)
当输入进入神经元时,它会乘以一个权重。例如,如果一个神经元有两个输入,则每个输入将具有分配给它的一个关联权重。我们随机初始化权重,并在模型训练过程中更新这些权重。为零的权重则表示特定的特征是微不足道的。
- 偏差(Bias)
偏差是除了权重之外,另一个被应用于输入的线性分量被称为偏差。它被加到权重与输入相乘的结果中。基本上添加偏差的目的是来改变权重与输入相乘所得结果的范围的。这是输入变换的最终线性分量。
- 激活函数(Activation Function)
一旦将线性分量应用于输入,将会需要应用一个非线性函数。这通过将激活函数应用于线性组合来完成。激活函数将输入信号转换为输出信号。应用激活函数后的输出为
f(a * W1 + b),其中f()就是激活函数。
- 神经网络(Neural Network)
神经网络的目标是找到一个未知函数的近似值。
以上就是神经网络的五个重要概念。因为神经网络是一种仿生模型,我们可以从生物的角度去更好地理解:

一个神经元,是一个可以发射、接收脉冲信号的细胞。在细胞体有树突和轴突,树突接收其他神经元的脉冲信号,轴突将神经元的输出脉冲传递给其他神经元。一个神经元传递给不同神经元的输出是相同的,并且在突触部分发生信息的交换传递。无数个生物神经元的组合就形成了生物神经网络。
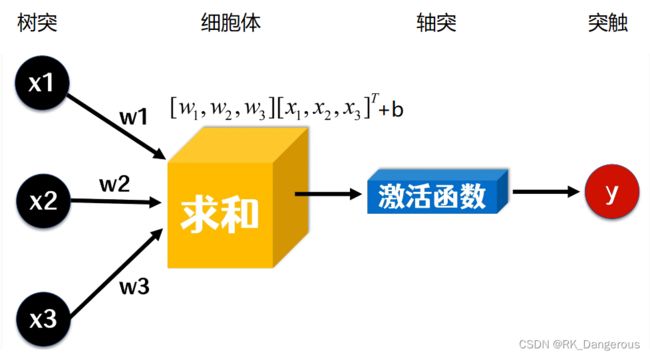
这样就比较好地将之前学的知识很好地串联起来。
宏观地看,神经网络还需要了解以下概念:
- 输入/输出/隐藏层(Input / Output / Hidden Layer)
输入层是接收输入那一层,本质上是网络的第一层。而输出层是生成输出的那一层,也可以说是网络的最终层。处理层是网络中的隐藏层。这些隐藏层是对传入数据执行特定任务并将其生成的输出传递到下一层的那些层。输入和输出层是我们可见的,而中间层则是隐藏的。

- MLP(多层感知器)
单个神经元将无法执行高度复杂的任务。因此,我们使用堆栈的神经元来生成我们所需要的输出。在最简单的网络中,我们将有一个输入层、一个隐藏层和一个输出层。每个层都有多个神经元,并且每个层中的所有神经元都连接到下一层的所有神经元。这些网络也可以被称为完全连接的网络。
- 正向传播(Forward Propagation)
正向传播是指输入通过隐藏层到输出层的运动。在正向传播中,信息沿着一个单一方向前进。输入层将输入提供给隐藏层,然后生成输出。这过程中是没有反向运动的。
- 成本(损失)函数(Cost Function)
当我们建立一个网络时,网络试图将输出预测得尽可能靠近实际值。我们使用成本/损失函数来衡量网络的准确性。在运行网络时的目标是提高我们的预测精度并减少误差,从而最大限度地降低成本。最优化的输出是那些成本或损失函数值最小的输出。而成本或损失函数会在发生错误时尝试惩罚网络。
- 梯度下降(Gradient Descent)
梯度下降是一种最小化成本的优化算法。我们从一个点x开始,我们向下移动一点,即Δh,并将我们的位置更新为x-Δh,并且继续保持一致,直到达到底部。

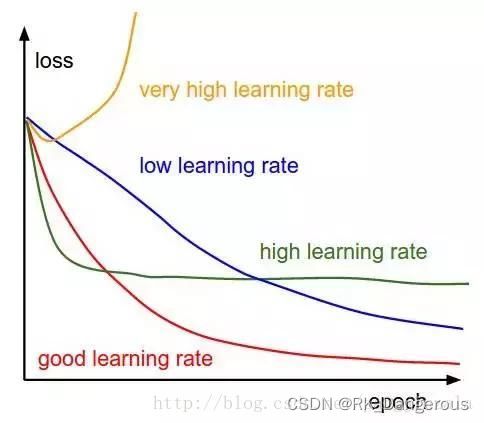
- 学习率(Learning Rate)
学习率我理解就是梯度下降法中说的步长。
学习率作为监督学习以及深度学习中重要的超参数,其决定着目标函数是否能收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。它指导我们在梯度下降法中,如何使用损失函数的梯度调整网络权重的超参数。
简单来说,我们下降到成本函数的最小值的速率是学习率。我们应该非常仔细地选择学习率,因为它不应该是非常大的,以至于最佳解决方案被错过,也不应该非常低,以至于网络需要融合。
- 反向传播(Backpropagation)
当我们定义神经网络时,我们为节点分配随机权重和偏差值。一旦我们收到单次迭代的输出,我们就可以计算出网络的错误。然后将该错误与成本函数的梯度一起反馈给网络以更新网络的权重。最后更新这些权重,以便减少后续迭代中的错误。
是否可以理解为,神经网络宏观是正向传播的,但是在训练的过程中,需要无数个反向传播来实现。也可以理解为正向传播 + 反向传播 = 一个周期。
- 批次(Batches)
在训练神经网络的同时,不用一次发送整个输入,我们将输入分成几个随机大小相等的块。与整个数据集一次性馈送到网络时建立的模型相比,批量训练数据使得模型更加广义化。
- 周期(Epochs)
周期被定义为向前和向后传播中所有批次的单次训练迭代。这意味着1个周期是整个输入数据的单次向前和向后传递。
你可以选择你用来训练网络的周期数量,更多的周期将显示出更高的网络准确性,然而,网络融合也需要更长的时间。另外,你必须注意,如果周期数太高,网络可能会过度拟合。
- 丢弃(Dropout)
Dropout是一种正则化技术,可防止网络过度拟合套。顾名思义,在训练期间,隐藏层中的一定数量的神经元被随机地丢弃。这意味着训练发生在神经网络的不同组合的神经网络的几个架构上。你可以将Dropout视为一种综合技术,然后将多个网络的输出用于产生最终输出。
- 批量归一化(Batch Normalization)
就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
在学习以上的知识时,我有非常大的困惑,我觉得学的东西都很散,组装不起来。对我来说基础知识没有打好,我是没有心情和信息去进行更近一步地学习的,我需要知其然并且知其所以然。所以下面就是细节的学习和解惑,详细地学习每一个模块在整体中的作用。
激活函数
还是这张图片,细胞体的工作应该就是【得分函数】,那么已经算出来得分了,激活函数又是什么东西?在学习前先了解一下感知机:
感知机是一个有监督的学习算法。
感知机是一个二分类的线性模型,其输入是实例的特征向量,输出的是实例的类别,属于判别模型。
感知机相当于轴突,当细胞体计算出的得分函数大于某一阈值,会产生一个输出,详见下图,例如我们设置阈值为0,若得分大于0将y赋值为1,否则赋值为0,实现了以得分为依据的分类。

大致了解感知机之后,我们看激活函数。仍以上面感知机为例,激活函数可以理解为将感知机写成如下形式:

其中h(x)就是激活函数,将输入信号的总和转换为输出信号。我可以这样理解,激活函数的作用就是评价得分,将其格式化成后续需要的值。
激活函数的作用:在于决定如何来激活输入信号的总和
上面说到的感知机的激活函数就是一个阶跃函数,它以阈值为界,一旦输入超过阈值,就切换输出。
特别要注意神经网络的激活函数必须使用非线性函数。为什么呢?我们之前说过W不是一步到位的,我们把神经网络分为很多层,形如[(x*W1)W2]W3···,这些都是隐藏层。
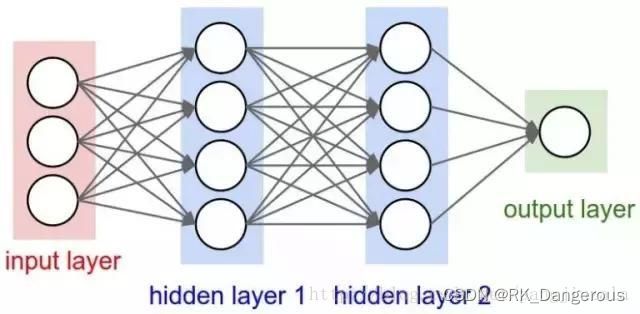
如果激活函数为线性函数,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。比如激活函数h(x)=cx+t,我们有一个三层的神经网络y=h(h(h(x))),计算得到y=c³x+c²t+ct+t,本质上这个函数还是y=ax+b的形式。
学完了激活函数之后,我们就知道神经网络的结构其实是这样的:

每一层隐藏层中都有激活函数起作用。
真实世界中的大多数系统是非线性的,若要模拟复杂系统,则必须借助非线性的激活函数。
根据通用近似定理(universal approximation theorem),神经网络至少需要一层隐藏层和足够的神经元,利用非线性的激活函数,便可以模拟任何复杂的连续函数。
常用的激活函数
最常用的激活函数就是Sigmoid,ReLU和softmax
- Sigmoid
Sigmoid是最常用的激活函数之一,它被定义为:

观察函数图像,我们与阶跃函数对比:

Sigmoid变换产生一个值为0到1之间更平滑的范围。我们可能需要观察在输入值略有变化时输出值中发生的变化。光滑的曲线使我们能够做到这一点,因此优于阶跃函数。
另外要注意,sigmoid函数会产生一种梯度消失现象。在函数值趋近于0时,即梯度为0,梯度不再进行传播和更新。 - ReLU(整流线性单位)
最近的网络更喜欢使用ReLu激活函数来处理隐藏层。该函数定义为:

当X>0时,函数的输出值为X;当X<=0时,输出值为0。函数图如下图所示:

使用ReLU函数的最主要的好处是对于大于0的所有输入来说,它都有一个不变的导数值。常数导数值有助于网络训练进行得更快。此外,在使用sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练,但ReLU不存在饱和问题,它在x>0的时候能够保持梯度不衰减,从而缓解梯度消失问题。随着训练的推进,部分输入小于0会导致权重无法更新(这种现象被称为“神经元死亡”),这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
-
Softmax
Softmax激活函数通常用于输出层,用于分类问题,在之前【结果概率——Softmax分类器】部分讲过它的原理。它与sigmoid函数是很类似的,唯一的区别就是输出被归一化为总和为1。
假设你正在尝试识别一个可能看起来像8的6。该函数将为每个数字分配值如下。我们可以很容易地看出,最高概率被分配给6,而下一个最高概率分配给8,依此类推…… -
Tanh
该函数定义为:
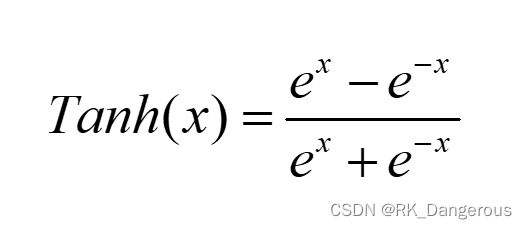
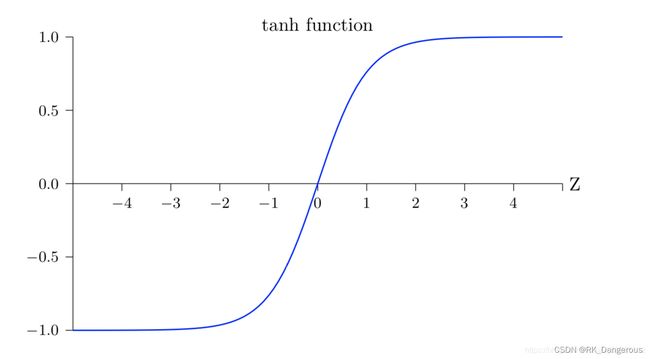
它的输出值落于-1到1的连续区间,一定程度上缓解了梯度消失,但是当输入较大或较小时,输出几乎是平滑的并且梯度较小,不利于权重更新。因为执行指数运算,所以存在计算量大的问题。
在一般的二元分类问题中,tanh激活函数函数常用于隐藏层,sigmoid用于输出层,但这并不是固定的,需要根据特定问题进行调整。 -
Leaky-ReLU
该函数定义为:

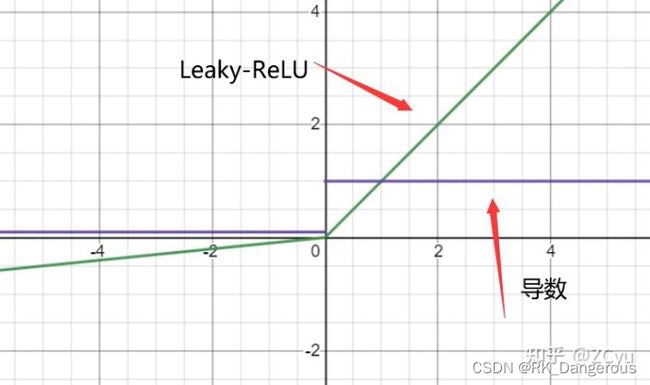
它在ReLU的基础上,给负数区间添加一个较小斜率的线性部分,使负数区间也能产生梯度调整值。 -
ELU
该函数定义为:

例如当α=1时,函数图像为:
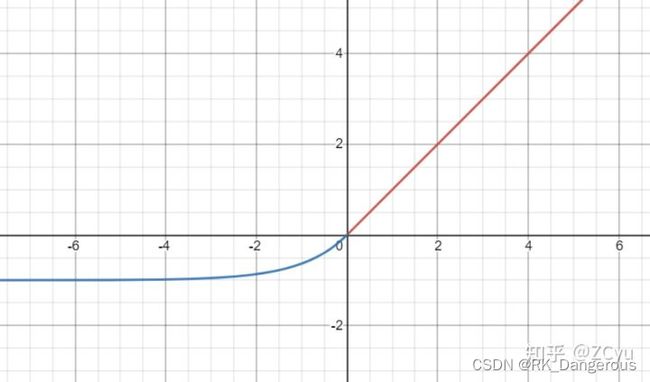
ELU满足两个条件:一是输出的分布是零均值的,可以加快训练速度;二是激活函数是单侧饱和(一端无限接近0)的,可以更好的收敛。但是ELU的速度会慢一些。
————————————————————————————————————————————————————————————
注释:
零均值就是数据分布的均值约等于0。零均值化就是将一组数据,其中每一个都减去这组的平均值。例如,对[1、2、3、4、5]零均值化,先算出其均值为3,然后每一个数都减去3,得到[-2、-1、0、1、2],就实现了零均值化。
这样做的优点是为了 在反向传播中加快网络中每一层权重参数的收敛。可以避免Z型更新的情况,这样可以加快神经网络的收敛速度。
再详细解释一下Z型更新。以sigmoid函数为例:

假设我们的权重W是由W1和W2组成的。根据链式法则,在反向传播时,有:

其中f(x)是激活函数(这里是sigmoid)。我们接下来需要看这个公式的符号。损失函数对于f(x)的导数与W1和W2无关,这里仔细想想,也就是说在某一组Wi构成的f(Wx+b)中,∂L/∂f可能是正数也可能是负数,因为是W1和W2共同构成的,所以∂L/∂W1和∂L/∂W2中的∂L/∂f一定是同号的。然后我们再看∂f/∂W,(这里别人的推导我没看懂,因为涉及到矩阵的计算,我的思路可能不太对,欢迎指正)根据链式法则,∂f/∂W=∂f/∂(Wx+b) * ∂(Wx+b)/∂W,结合上面的导数图像可知∂f/∂(Wx+b)恒为正,而∂(Wx+b)/∂W的符号又取决于x,x恒为正(第一层的输入恒为正是因为像素取值范围在0-255,后面隐藏层的输入恒为正是因为激活函数sigmoid使输出恒为正)。也就是说∂L/∂W1和∂L/∂W2一定是同号的,要么都是正数要么都是负数,这取决于∂L/∂f的符号。

这就是Z型更新的现象。你可以发现它在趋近最优解的过程中,W1和W2的每次更新方向都是一致的,要么同时增加,要么同时减小。在同时增加的过程中,轨迹上扬,横坐标解近最优解但是竖坐标却距离最优解更远;在同时减小的过程中,竖坐标解近最优解但是横坐标却距离最优解更远。因此我们认为它是走了弯路的,所以更新的慢。如果我们零均值化后,W1和W2可能一正一负,从而能够一起朝着距离最优解更近的方向前进。至于它是怎么做到的,我认为暂时还没有必要去研究(因为真的找不到比较深入的教程,学起来耗时耗力,现阶段最重要的是初步学习,但如果有好心人愿意教一下我就更好了)。
————————————————————————————————————————————————————————————
总结——激活函数的选择
- 在隐藏层使用一般情况推荐的顺序:
ReLU/Leaky-ReLU > ELU > Tanh > Sigmoid - 输出层激活函数的选择————以业务要求为导向:
①二分类问题(例如判断物体是否是猫猫):使用sigmoid函数返回概率。
②多分类问题(返回物体是每个类别的概率):使用softmax函数,概率总和为1。
③线性回归问题(预测绝对数值,例如身高、GDP):直接使用线性函数。
激活函数与反向传播
在我的理解中,反向传播肯定是对一个损失函数去使用梯度下降的方法处理,找到损失函数的最小值。上面关于激活函数的学习中,很多次说到了激活函数会存在“梯度消失”的情况。激活函数是如何影响到反向传播的?
之前在讲反向传播的学习到了链式法则,给了我很大的启发。

在损失函数L(x)中,得到的输出是y6,所以我们计算得到损失为L(y6),其中自变量是W和b。那么我们要得到函数图像L(y6)的最低点,可以使用梯度下降法对它求偏导。根据链式法则,我们可以把损失函数对W求偏导分解得到一个y6对W求偏导,而y6又可以向下概括……最终每一个激活函数h(x)都对求梯度起到了作用。学到这里,我更深刻地认识到神经网络真的是一层一层的。
过拟合问题
一直在说的"过拟合"究竟是什么?大概来说,过拟合是由于过分拟合了训练样本,而导致模型的泛化能力较差。有几个弹幕发言特别好理解:“我理解过拟合就是把训练集背下来了,而忽略了样本之间的内在关联。就跟平时背题会做,考试时换一道题就不会了”,还有"学的钻牛角尖了,然后就不会触类旁通了。"
惩罚力度对结果的影响
之前在损失函数部分说过,我们一般会在损失函数中再添加一项"正则化惩罚项"λR(W),λ是一个比例系数,越大表示越不希望过拟合。

惩罚力度越小,训练出来的W可能更不均衡,会出现过拟合的现象。对于较大的λ边界更光滑,虽然在训练集中也存在一些错误,但是能够很好地应用。(不太清楚上图中这些数据点代表什么,可能是以特征值为坐标描出来的点。)
损失函数(成本函数)
之前了解到了损失函数的作用和在整个神经网络中的位置,那我就好奇,我们是必须选择市场上已有的损失函数吗?或是可以自己设计?那么如何设计呢?
-
最小二乘法
最小二乘法是比较简单的一种。将神经网络判断的结果,与标签标记的真实结果比较,把所有的差值都加起来。

由于计算梯度要对损失函数求导,绝对值求导很不方便,所以可以给它加一个平方。既然已经做了一些改变,那就干脆变得更简单,加一个系数1/2这样就可以在求导的时候把2约掉。得到以下损失函数:
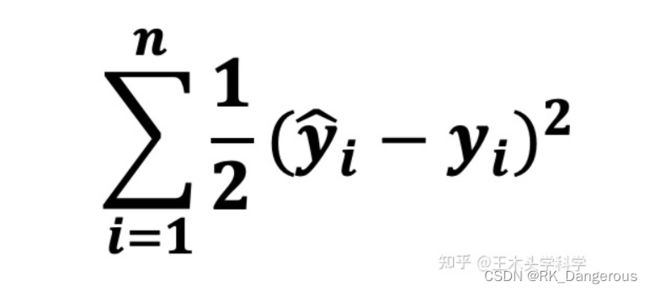
同上,我们可以将成本函数定义为均方误差,写为:C= 1/m ∑(y–a)^2,其中m是训练输入的数量,a是预测值,y是该特定示例的实际值。 -
极大似然估计法
极大似然估计法(也称最大似然估计法),要求的就是似然函数的最大值。似然函数表示为:

其中C表示可能出现的结果,θ表示某一前提条件(决定了结果概率的属性)。当θ是一个固定值的时候,把所有C的可能取值都考虑进来,把它们对应的概率值加起来,最后的结果是归一的(但是注意θ不是归一的)。
例如有一枚质地不均匀的硬币,我们抛了10次,出现的结果为3次反面朝上、7次正面朝上。我们已知结果如何计算硬币质地的分布?即我们如何判断下一次抛硬币得到正反面的可能性?经验告诉我们,下一次抛硬币70%的可能性是正面朝上,30%的可能性是反面朝上,但是毕竟是经验,不具有说服性。我们接下来要验证一下。将问题化简,我们假设硬币质地正反面比例可能为9种情况:θ1=(1, 9), θ2=(2, 8), θ3=(3, 7), θ4=(4, 6), θ5=(5, 5), θ6=(6, 4), θ7=(7, 3), θ8=(8, 2), θ9=(9, 1),抛10次硬币正反面次数可能出现11种情况:c1=(0, 10), c2=(1, 9), c3=(2, 8), c4=(3, 7), c5=(4, 6), c6=(5, 5), c7=(6, 4), c8=(7, 3), c9=(8, 2), c10=(9, 1), c11=(10, 0),我们需要计算出在每种θ下得到c8=(7, 3)即“抛了10次,出现的结果为3次反面朝上、7次正面朝上”的可能性。
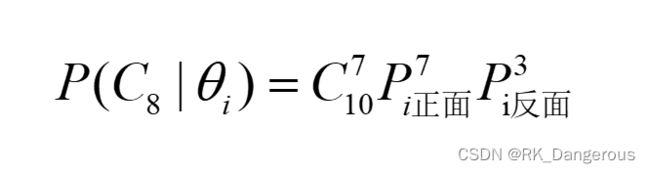
计算得到:

为了直观一点我绘制了一个折线图,可以看到,在θ7=(7, 3)处的值最大,也就是说已知结果为(7,3)时,最有可能的情况就是似然函数最大的位置。
学习完最大似然估计法的概念,如何运用到神经网络中?还是抛硬币的例子,可以把问题理解为我们已知抛了10次的结果C8,要求一个最可能的θ,那么在神经网络中,10次抛硬币的结果就对应数据集, θ对应W和b,我们要求的就是似然函数最大值时W和b的结果。我参考的文章是解析吴恩达视频中的似然函数,但是似然函数的表达式推导我没有看懂。
在似然函数中用对数能够简便计算,为什么要用对数运算呢?因为log函数是单调递增的,对原函数的值取对数,当原函数取到最大值时,值的对数函数也相应取到了最大值,不会影响我们求自变量。例如:

在这个式子中,我们抛了100次硬币,有60次都是正面,你会发现计算概率时的系数不见了,因为它不影响函数的图像,所以可以不把它写出来。对函数两边同时取对数:

我们要求最大值,就是求导数为0的情况:

利用对数函数,我们求导时不必再面对庞大的指数。
都说了我们这个叫做损失函数,往往都是求最小值,这个怎么求最大值?我的疑惑很好解决,其实面对最优化问题求最值时,确实更习惯求最小值,所以可以在函数前面加一个负号。
step6:深度学习与神经网络概念
此处作为后续学习的铺垫,有一些比较杂的知识总结在这里,可能会存在一些学习顺序的先后问题,可以在后面学习遇到问题时查阅。
1. backbone:
主干网络(大多时候指的是提取特征的网络),其作用就是提取图片中的信息,共后面的网络使用。这些网络经常使用的是resnet、VGG等,而不是我们自己设计的网络,因为这些网络已经证明了在分类等问题上的特征提取能力是很强的。在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。
2. head:
head是获取网络输出内容的网络,利用之前提取的特征,head利用这些特征,做出预测。
3. neck:
neck是放在backbone和head之间的,是为了更好的利用backbone提取的特征。
4. bottleneck:
瓶颈的意思,通常指的是网络输入的数据维度和输出的维度不同,输出的维度比输入的小了许多,就像脖子一样变细了。经常设置的参数 bottle_num=256,指的是网络输出的数据的维度是256 。
5. Warm up:
Warm up指的是用一个小的学习率先训练几个epoch,这是因为网络的参数是随机初始化的,一开始就采用较大的学习率容易数值不稳定。
参考来源:
我居然3小时学懂了深度学习神经网络入门到实战,多亏了这个课程,看不懂你打我!!
什么是梯度下降法?
3.深度学习灵魂-神经网络之激活函数
06.激活函数relu
28.前向传播,反向传播和链式法则
激活函数及其选择
激活函数Tanh
什么是零均值?什么是零均值化?
归一化、标准化、零均值化作用及区别
“损失函数”是如何设计出来的?直观理解“最小二乘法”和“极大似然估计法”
如何通俗的理解最大似然估计法
监督学习与无监督学习
深度学习中backbone、head、neck等术语解释
关于深度学习中的分类器汇总,模型对类别概率计算输出代码。
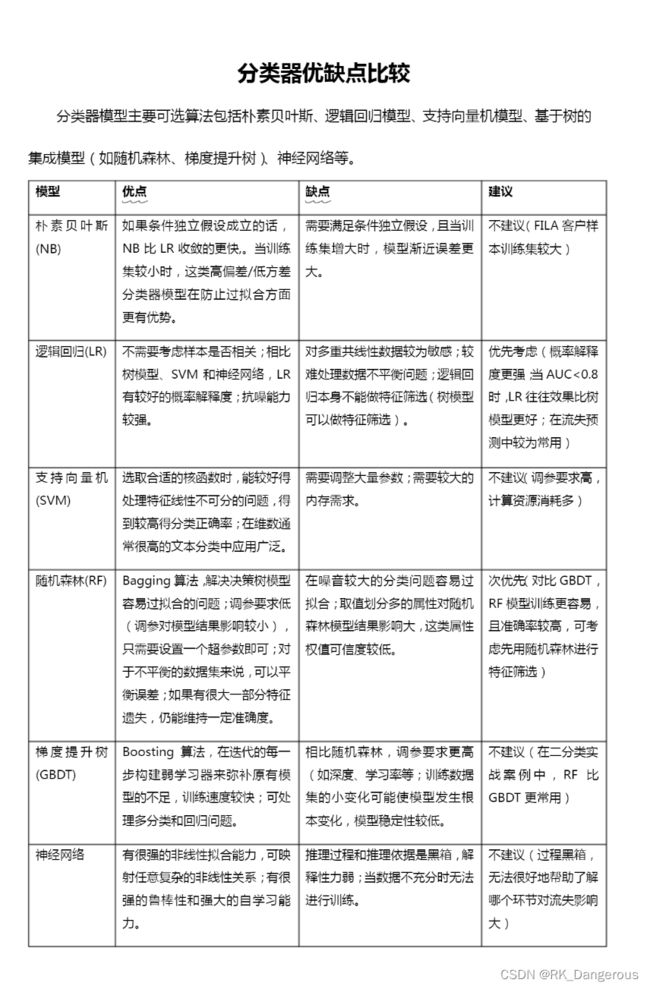
分类器优缺点比较
【欢迎指正】