网络优化(一)——学习率调整
文章目录
- 1. 非凸优化
-
- 1.1 鞍点
- 1.2 最小值
- 2. 学习率调整介绍
- 3. 学习率衰减
- 4. 学习率预热
- 5. 周期性学习率调整
-
- 5.1 循环学习率
- 5.2 带热重启的随机梯度下降
1. 非凸优化
1.1 鞍点
在高维空间中,非凸优化的难点并不在于如何逃离局部最优点,而是如何逃离鞍点。鞍点的梯度是0,但是在一些维度上是最高点,在另一些维度上是最低点。
在高维空间中,局部最小值要求在每一维度上都是最低点,这种概率非常低.假设网络有10000 维参数,梯度为0 的点(即驻点)在某一维上局部最小值的概率为 p p p,在一般的非凸问题中,那么在整个参数空间中,驻点是局部最优点的概率为 p 10000 p^{10000} p10000,这种可能性非常小.也就是说,在高维空间中大部分驻点都是鞍点。
基于梯度下降的优化方法会在鞍点附近接近于停滞,很难从这些鞍点中逃离。因此,随机梯度下降对于高维空间中的非凸优化问题十分重要,通过在梯度方向上引入随机性,可以有效地逃离鞍点。
在非常大的神经网络中,大部分的局部最小解是等价的,它们在测试集上性能都比较相似。此外,局部最小解对应的训练损失都可能非常接近于全局最小解对应的训练损失。虽然神经网络有一定概率收敛于比较差的局部最小值,但随着网络规模增加,网络陷入比较差的局部最小值的概率会大大降低。在训练神经网络时,我们通常没有必要找全局最小值,这反而可能导致过拟合。
1.2 最小值
深度神经网络的参数非常多,并且有一定的冗余性,这使得每单个参数对最终损失的影响都比较小,因此会导致损失函数在局部最小解附近通常是一个平坦的区域,称为平坦最小值。平坦最小值和尖锐最小值如下所示。
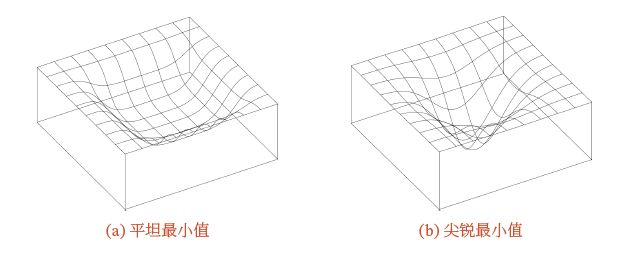
在一个平坦最小值的邻域内,所有点对应的训练损失都比较接近,表明我们在训练神经网络时,不需要精确地找到一个局部最小解,只要在一个局部最小解的邻域内就足够了。平坦最小值通常被认为和模型泛化能力有一定的关系。一般而言,当一个模型收敛到一个平坦的局部最小值时,其鲁棒性会更好,即微小的参数变动不会剧烈影响模型能力;而当一个模型收敛到一个尖锐的局部最小值时,其鲁棒性也会比较差。具备良好泛化能力的模型通常应该是鲁棒的,因此理想的局部最小值应该是平坦的。
2. 学习率调整介绍
学习率是神经网络优化时的重要超参数.在梯度下降法中,学习率 的取值非常关键,如果过大就不会收敛,如果过小则收敛速度太慢.常用的学习率调整方法包括学习率衰减、学习率预热、周期性学习率调整以及一些自适应调整学习率的方法,比如 A d a G r a d 、 R M S p r o p 、 A d a D e l t a AdaGrad、RMSprop、AdaDelta AdaGrad、RMSprop、AdaDelta 等.自适应学习率方法可以针对每个参数设置不同的学习率。
下面这些学习率算法的代码在pytorch中的实现可以参照这篇文章。
3. 学习率衰减
从经验上看,学习率在一开始要保持大些来保证收敛速度,在收敛到最优点附近时要小些以避免来回振荡.比较简单的学习率调整可以通过学习率衰减。
分段常数衰减
每经过 T 1 , T 2 , ⋯ , T m T_1, T_2, ⋯ , T_m T1,T2,⋯,Tm 次迭代将学习率衰减为原来的 β 1 , β 2 , ⋯ , β \beta_1, \beta_2, ⋯ , \beta_ β1,β2,⋯,βm 倍,其中 T m T_m Tm 和 β m < 1 \beta_m<1 βm<1 为根据经验设置分段常数衰减也称为阶梯衰减。
逆时衰减
逆时衰减的学习率更新如下所示:
α t = α 0 1 1 + β t \alpha_t=\alpha_0\frac{1}{1+\beta t} αt=α01+βt1其中, α 0 \alpha_0 α0 为初始学习率, β \beta β 为学习率的更新倍率, t t t 为学习率更新的周期。
指数衰减
指数衰减的学习率更新如下所示:
α t = α 0 β t \alpha_t=\alpha_0 \beta^t αt=α0βt其中, α 0 \alpha_0 α0 为初始学习率, β < 1 \beta<1 β<1 为衰减率, t t t 为学习率更新的周期。
余弦衰减
余弦衰减的学习率更新如下所示:
α t = 1 2 α 0 ( 1 + c o s ( t π T ) ) \alpha_t=\frac{1}{2}\alpha_0(1+cos(\frac{t \pi}{T})) αt=21α0(1+cos(Ttπ))其中, α 0 \alpha_0 α0 为初始学习率, β < 1 \beta<1 β<1 为衰减率, t t t 为学习率更新的周期。
4. 学习率预热
在小批量梯度下降法中,当批量大小的设置比较大时,通常需要比较大的学习率.但在刚开始训练时,由于参数是随机初始化的,梯度往往也比较大,再加上比较大的初始学习率,会使得训练不稳定。
为了提高训练稳定性,我们可以在最初几轮迭代时,采用比较小的学习率,等梯度下降到一定程度后再恢复到初始的学习率,这种方法称为学习率预热。
一个常用的学习率预热方法是逐渐预热,假设预热的迭代次数为 T ′ T' T′,初始学习率为 α 0 \alpha_0 α0,在预热过程中,每次更新的学习率为
α t ′ = t T ′ α 0 , 1 ≤ t ≤ T ′ \alpha'_t= \frac{t}{T'}\alpha_0,1 \le t \le T' αt′=T′tα0,1≤t≤T′当预热过程结束,再选择一种学习率衰减方法来逐渐降低学习率。
5. 周期性学习率调整
为了使得梯度下降法能够逃离鞍点或尖锐最小值,一种经验性的方式是在训练过程中周期性地增大学习率.当参数处于尖锐最小值附近时,增大学习率有助于逃离尖锐最小值;当参数处于平坦最小值附近时,增大学习率依然有可能在该平坦最小值的吸引域内.因此,周期性地增大学习率虽然可能短期内损害优化过程,使得网络收敛的稳定性变差,但从长期来看有助于找到更好的局部最优解。
5.1 循环学习率
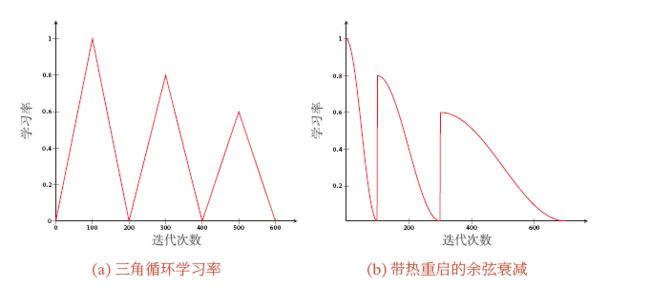
一种简单的方法是使用循环学习率,即让学习率在一个区间内周期性地增大和缩小.通常可以使用线性缩放来调整学习率,称为三角循环学习率。假设每个循环周期的长度相等都为 2 Δ 2\Delta 2ΔT,其中前 Δ T \Delta T ΔT 步为学习率线性增大阶段,后 Δ T \Delta T ΔT 步为学习率线性缩小阶段.在第 t t t 次迭代时,其所在的循环周期数 m m m 为
m = ⌊ 1 + t 1 + 2 Δ T ⌋ m=\lfloor 1+\frac{t}{1+2\Delta T} \rfloor m=⌊1+1+2ΔTt⌋其中符号 ⌊ ⋅ ⌋ \lfloor \cdot \rfloor ⌊⋅⌋ 表示向下取整,第 t t t 次迭代的学习率为
α t = α m i n m + ( α m a x m − α m i n m ) ( 1 − b ) \alpha_t=\alpha_{min}^m+(\alpha_{max}^m-\alpha_{min}^m)(1-b) αt=αminm+(αmaxm−αminm)(1−b)其中 α m a x m , α m i n m \alpha_{max}^m,\alpha_{min}^m αmaxm,αminm 分别为第 m m m 个周期中学习率的上界和下界,可以随着 m m m 的增大而逐渐降低, b ∈ [ 0 , 1 ] b \in [0,1] b∈[0,1] 的计算公式为
b = ∣ t Δ T − 2 m + 1 ∣ b=\vert \frac{t}{\Delta T}-2m+1 \vert b=∣ΔTt−2m+1∣
5.2 带热重启的随机梯度下降
带热重启的随机梯度下降是用热重启方式来替代学习率衰减的方法.学习率每间隔一定周期后重新初始化为某个预先设定值,然后逐渐衰减.每次重启后模型参数不是从头开始优化,而是从重启前的参数基础上继续优化。
假设在梯度下降过程中重启 M M M 次,第 m m m 次重启在上次重启开始第 T m T_m Tm 个回合后进行, T m T_m Tm 称为重启周期。在第 m m m 次重启之前,采用余弦衰减来降低学习率。第 t t t 次迭代的学习率为
α t = α m i n m + 1 2 ( α m a x m − α m i n m ) ( 1 + c o s ( T c u r T m π ) ) \alpha_t=\alpha_{min}^m+\frac{1}{2}(\alpha_{max}^m-\alpha_{min}^m)(1+cos(\frac{T_{cur}}{T_m}\pi)) αt=αminm+21(αmaxm−αminm)(1+cos(TmTcurπ))其中 α m a x m , α m i n m \alpha_{max}^m,\alpha_{min}^m αmaxm,αminm 分别为第 m m m 个周期中学习率的上界和下界, T c u r T_cur Tcur 为上次重启后的 e p o c h epoch epoch 数,可以取小数,重启周期 T m T_m Tm 可以随着重启次数逐渐增加,比如 T m = k T m − 1 T_m=kT_{m-1} Tm=kTm−1, k ≥ 1 k \ge 1 k≥1 为放大因子。
两种循环学习率的学习率大小随着迭代次数的变化图像如下所示。
参考文章
邱锡鹏,《神经网络与深度学习》,机械工业出版社,https://nndl.github.io/, 2020.