高效灵活地发现PHP应用程序漏洞
摘要
今天的Web是一个不断增长的充满交互内容的页面和应用程序的世界。此类应用程序的安全性至关重要,因为漏洞利用可能会对个人和经济水平产生毁灭性影响。Web应用程序中排名第一的编程语言是PHP,它为前1000万个网站中的80%以上提供了支持。Y et它在设计时没有考虑到安全性,而今天,它的修补程序和设计不一致的功能拼凑在一起,通常会出现意外和难以预测的行为,通常会产生较大的攻击面。因此,它容易出现不同类型的漏洞,如SQL注入或跨站点脚本。在本文中,我们提出了一种基于代码属性图的PHP应用程序过程间分析技术,该技术可以很好地扩展到大量代码,并且在本质上具有很强的适应性。我们使用PHP 7的最新功能实现我们的原型,利用高效的图形数据库存储PHP的代码属性图,然后通过可编程的图形遍历来识别不同类型的Web应用程序漏洞。我们通过对1854个流行开源项目的分析来展示我们的方法的有效性和可扩展性,这些项目包括近8000万行代码。
1、简介
毫无疑问,最流行和部署最广泛的Web应用程序语言是PHP,它为前1000万个网站中的80%以上提供了支持,包括Facebook、Wikipedia、Flickr或Wordpress等广泛使用的平台,并为GitHub上的近140000个开源项目做出了贡献。然而,从安全的角度来看,这种语言设计得很糟糕:它通常会产生很大的攻击面(例如,服务器上的每个PHP脚本都可能被攻击者用作入口点),并且具有设计不一致的函数,往往会产生令人惊讶的副作用【22】,所有这些都是程序员在开发PHP应用程序时必须注意并牢记的。
由于其混淆和不一致的API,PHP特别容易出现编程错误,这些错误可能导致Web应用程序漏洞,如SQL注入和跨站点脚本。结合其在因此,PHP是自动化安全分析的主要目标,以帮助开发人员避免重大错误,从而提高Web应用程序的整体安全性。事实上,大量研究致力于以机器辅助的方式识别脆弱的信息流[15、16、4、5]。所有这些方法都成功地识别了Web应用程序中不同类型的PHP漏洞。然而,所有这些方法仅在大约六个项目的受控环境中进行了评估。因此,目前尚不清楚它们的可伸缩性以及它们在非常大的任意PHP项目集的控制较少的环境中的性能。(详见第7节相关工作)。此外,这些方法很难定制,因为它们无法配置为查找各种不同类型的漏洞。
如何高效地大规模检测PHP应用程序漏洞,同时保持可接受的精度和根据需要定制检测过程的能力,这一研究问题迄今为止受到的关注明显较少。然而,考虑到Web应用程序数量的快速增长,这是一个至关重要的问题。
我们的贡献我们提出了一种高度可扩展且灵活的方法来分析可能由数百万行代码组成的PHP应用程序。为此,我们利用了最近提出的代码属性图的概念【35】:这些图构成了代码的规范化表示,将程序的语法、控制流和数据依赖性合并到一个单一的图结构中,我们通过调用边进一步丰富了这些图,以允许进行过程间分析。然后,这些图形存储在一个图形数据库中,该数据库为高效且易于编程的图形遍历奠定了基础,可以识别程序代码中的缺陷。正如我们在本文中所展示的,这种方法非常适合于大规模发现PHP等高级动态脚本语言中的漏洞。此外,它非常灵活:生成代码属性图并将其导入数据库的大量工作是以完全自动化的方式完成的。随后,分析员可以根据需要编写遍历来查询数据库,以便找到各种漏洞:例如,人们可能会检测常见的代码模式,或者寻找从给定类型的攻击者控制器源到未经适当清理的给定securitycritical函数调用的特定流;可以根据需要轻松指定和调整要考虑的源、汇和消毒剂。
我们展示了如何使用这种可以由数据库后端高效运行的图遍历来建模典型的Web应用程序漏洞。我们在GitHub上的一组1854个开源PHP项目上评估了我们的方法。我们的三大贡献如下:
PHP代码属性图介绍。我们是第一个将代码属性图的概念用于高级动态脚本语言(如PHP)的人。我们使用静态分析技术为PHP实现代码属性图,并使用调用边对其进行补充,以允许进行过程间分析。这些图形存储在图形数据库中,随后可用于复杂查询。这些图的生成是完全自动化的,也就是说,用户实现自己的过程间分析所要做的就是编写这样的查询。我们将我们的实现公开,以促进独立研究。
**建模Web应用程序漏洞。**我们表明,代码属性图可以通过对诸如图遍历之类的缺陷进行建模来发现典型的Web应用程序漏洞,即沿着图遍历以找到特定模式的完全可编程算法。这些模式是从AttackerControl输入到安全关键函数调用的不需要的流,没有适当的清理例程。我们详细介绍了针对服务器和客户端的攻击的这种模式,例如SQL注入、命令注入、代码注入、任意文件访问、跨站点脚本和会话固定。虽然这些图遍历证明了我们的技术的可行性,但我们强调,PHP应用程序开发人员和分析人员可能很容易编写更多的遍历,以检测程序代码中的其他类型的漏洞或模式。
**大规模评估。**为了评估我们的方法的有效性,我们报告了对GitHub上1854个流行PHP项目的大规模分析,共有近8000万行代码。在我们的分析中,我们发现我们的方法可以很好地扩展到所分析代码的大小。我们总共发现了78个SQL注入漏洞、6个命令注入漏洞、105个代码注入漏洞、6个允许攻击者访问服务器上任意文件的漏洞以及一个会话固定漏洞。XSS漏洞非常常见,我们的工具在对此类攻击的大规模评估中生成了大量报告。我们只检查了这些报告中的一小部分(低于2%),发现了26个XSS漏洞。
**论文大纲。**本文的其余部分组织如下:在第2节中,我们讨论了我们工作的技术背景,涵盖了ASTs等核心概念,CFG、PDG和调用图。在第3节中,我们从概念上概述了我们的方法,接着介绍了在图形数据库中表示和查询PHP代码属性图的必要技术,并讨论了如何使用遍历对典型的漏洞类进行建模。随后,第4节介绍了我们方法的实施,而第5节介绍了我们大规模研究的评估。接下来,第6节讨论我们的技术,第7节介绍相关工作,第8节总结。
2、代码属性图
我们的工作建立在代码属性图的概念上,这是一种程序语法、控制流和数据流的联合表示,Yamaguchi等人首先引入了这一概念,以发现C代码中的漏洞。这种方法的关键思想是将经典的程序表示合并到所谓的代码属性图中,这使得通过图遍历挖掘模式代码成为可能。特别是,代码的语法属性来自抽象语法树、来自控制流图的控制流,以及来自程序依赖图的数据流。此外,我们还使用调用图来丰富结果结构,以便实现过程间分析。在本节中,我们将简要回顾这些概念,为读者提供本文其余部分所需的技术背景。
我们将图1所示的PHP代码列表视为一个运行示例。为了便于说明,它存在一个微不足道的SQL注入漏洞。使用本文介绍的技术,可以很容易地发现此漏洞。

2.1. 抽象语法树(AST)
抽象语法树是编译器前端通常生成的程序语法的表示。这些树将代码分层分解为语法元素。这些树是抽象的,因为它们不能解释具体程序公式的所有细微差别,而只表示如何嵌套编程构造以形成最终程序。例如,变量是作为声明列表的一部分声明,还是作为连续的声明链声明,这是公式中的一个细节,不会导致不同的抽象语法树。
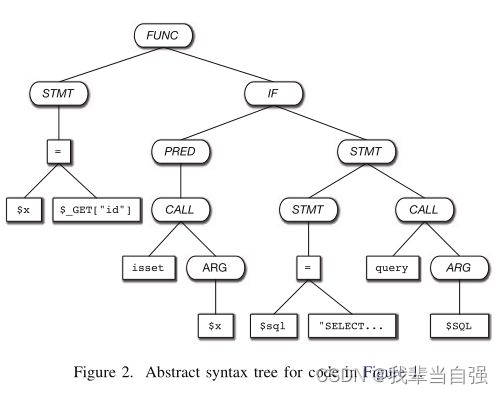
抽象语法树的节点分为两类。内部节点表示赋值或函数调用等运算符,而叶节点是常量或标识符等操作数。作为一个示例,图2显示了图1运行示例的抽象语法树。正如Yamaguchi等人[35]所示,抽象语法树非常适合根据函数或源文件中是否存在编程构造来建模漏洞,但它们不包含程序控制或数据流等语义信息。特别是,这意味着它们不能用来解释程序中由攻击者控制的数据流,因此需要额外的结构。
2.2. 控制流图(CFG)
抽象语法树明确说明了编程构造是如何嵌套的,但不允许对语句之间的相互作用进行推理,尤其是语句执行的可能顺序。控制流图通过显式表示程序的控制流来解决这个问题,即语句的执行顺序和产生流的谓词的值。
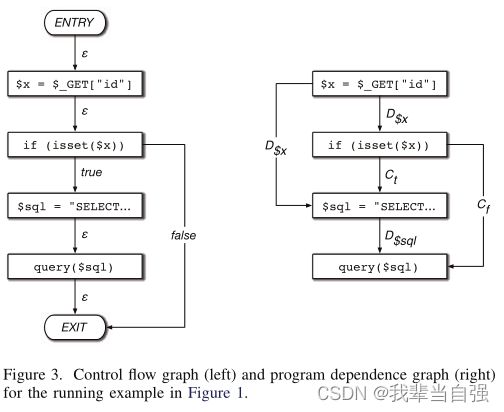
函数的控制流图包含指定的入口节点、指定的出口节点以及函数中包含的每个语句和谓词的节点。节点通过标记的有向边连接,以指示控制流。来自语句的边是否带有标签?为了指示无条件控制流,来自谓词的边被标记为true或false,以表示谓词必须计算的值,以便将控制传输到目标节点。图3(左)展示了图1运行示例的控制流图:除了源自谓词isset($x)的两条边之外,控制流基本上是线性的。根据该谓词的计算结果是true还是false,可以将控制权转移到ifbody中的第一条语句,也可以终止函数的执行,这是由出口节点的边缘建模的。
2.3. 程序依赖图(PDG)
Ferrante等人首次引入程序依赖图来执行程序切片[32]。这种表示公开了语句和谓词之间的依赖关系。这些依赖关系使得静态分析程序中的数据流,尤其是攻击者控制的数据的传播成为可能。
与控制流图一样,程序依赖图的节点是函数的语句和谓词。图中的边属于以下两种类型之一:创建数据依赖边是为了指示在源语句中定义的变量随后在目标语句中使用。这些边可以通过求解到达定义来计算,这是一个规范的数据流分析问题[1]。控制依赖边表示语句的执行依赖于谓词,可以通过首先将控制流图转换为后支配树来计算。作为一个示例,图3(右)显示了我们运行示例的程序依赖关系图,其中用D标记的边表示数据依赖边,用C标记的边表示控制依赖边。
2.4. 调用图(CG)
虽然将抽象语法树、控制流图和程序依赖图组合到代码属性图中可以生成一个强大的结构,用于分析程序的控制流和数据流,但CFG和PDG都只在功能级别定义,因此,生成的代码属性图只允许进行过程内分析。为了解决这个问题,我们扩展了Yamaguchi等人[35]的工作,将调用图合并到最终的组合结构中,称为代码属性图。顾名思义,调用图是连接调用节点的有向图,即表示调用站点的节点(如图2中的查询调用( s q l ) ) 到 如 果 匹 配 的 函 数 定 义 已 知 , 则 对 应 的 函 数 定 义 ( 一 些 函 数 定 义 , 例 如 对 i s s e t 的 调 用 ( sql)) 到如果匹配的函数定义已知,则对应的函数定义 (一些函数定义, 例如对isset的调用( sql))到如果匹配的函数定义已知,则对应的函数定义(一些函数定义,例如对isset的调用(x),
可能是PHP的组成部分,在这种情况下,我们不需要构建调用边缘)。这使我们能够在过程间水平上对控制和数据流进行推理。
3、方法
在本节中,我们将介绍我们的工作方法。我们首先从概念上概述了我们的方法,讨论了PHP代码的代码属性图的表示和生成。随后,我们讨论了代码属性图的可行性,以发现Web应用程序漏洞,并引入了图遍历的概念。然后,我们将详细介绍如何对不同类型的Web应用程序漏洞进行建模。
3.1. 概念概述
属性图是许多流行的图形数据库(如Neo4J、OrientDB或Titan)的常见图形结构。属性图(V,E)是由一组V顶点(等价节点)和一组E边组成的有向图。每个节点和边都有一个唯一标识符和一组由键到值的映射定义的属性(可能为空)。此外,节点和边可以有一个或多个标签,表示节点或关系的类型。
第2节中介绍的每个结构都捕获了底层代码的独特视图。通过将它们组合到一个单一的图结构中,我们获得了一个包含描述此代码的信息的单一全局视图,称为代码属性图。在本节中,我们将更详细地描述代码属性图的生成过程。
**3.1.1. 抽象语法树。**AST是图形生成过程的第一步。为了用语法树对整个PHP项目的代码进行建模,我们首先递归地扫描目录中的任何PHP文件。对于每个已识别的文件,PHP自己的内部解析器1用于生成表示文件PHP代码的AST。此类AST的每个节点都是我们要生成的属性图的节点:它被标记为AST节点,并具有一组属性。这些属性中的第一个是特定的AST节点类型:例如,有一种类型用于表示赋值、函数调用表达式、函数声明等。总共有105种不同的节点类型。另一个属性是一组标志,例如,用于指定方法声明节点的修饰符。进一步的属性包括一个表示相应代码位置的行号,以及在叶节点的情况下,一个表示特定节点的常量值的属性(例如硬编码字符串的内容),以及为了简单起见我们在这里省略的一些其他技术属性。
此外,将为已解析的文件创建一个文件节点,并将其连接到AST的根节点,创建目录节点,并将其彼此连接以及连接到文件节点,从而生成的图形反映项目的文件系统层次结构。文件和目录节点标记为文件系统节点。
最后,请注意,我们下一步要生成的CFG和PDG仅为每个函数定义[1]。然而,PHP是一种脚本语言,通常包含顶级代码,也就是说,PHP文件中可能有一些代码没有封装在函数中,但在加载文件时由PHP解释器直接执行。为了能够为该代码构建CFG和PDG,我们在生成AST期间为每个文件创建一个人工顶级函数AST节点,保存该文件的顶级代码。此顶级功能节点构成任何PHP文件语法树的根节点。
3.1.2. 控制流图。生成CFG之前的下一步是从AST中提取各个函数子树。这些AST中的函数子树可能并排存在,也可能相互嵌套:例如,文件的人工顶级函数可能包含特定的函数声明,而该声明又可能包含闭包声明等。因此,我们构建了一个函数提取器,它可以为CFG和PDG生成提取适当的子树,并能够处理嵌套函数。然后,这些子树分别由CFG和PDG生成例程处理。
为了从函数的抽象语法树生成CFG,我们首先识别那些也是CFG节点的AST节点,即表示语句或谓词的节点(见图3)。然后,通过提供所有程序语句的语义信息,可以从AST计算控制流图,这些语句允许程序员更改控制流。这些语句分为两类:结构化控制流语句(例如for、while、if)和非结构化控制流语句(例如goto、break、continue)。计算通过定义从基本抽象语法树到相应控制流图的转换规则来执行,并应用这些规则来构建函数的初步控制流图。随后对该初步控制流图进行修正,以说明非结构化控制流语句。
**3.1.3. 程序依赖关系图。**PDG可以在CFG和标准迭代数据流分析算法(例如,[1])的帮助下生成。为此,我们对各个CFG节点执行use /def分析,这意味着我们使用递归算法来确定每个语句或谓词使用了哪些变量以及(重新)定义了哪些变量。一旦我们获得了每个CFG节点的该信息,该信息将沿着控制流边缘向后传播,以解决到达定义问题,如第2.3节所述。
3.1.4. 调用图。图生成过程的最后一步是调用图的生成。在生成AST的过程中,我们跟踪遇到的所有调用节点,以及所有函数声明节点。一旦我们完成了对特定项目的所有文件的解析过程(因此我们可以确信我们已经收集了所有函数声明节点),这些调用节点将通过调用边连接到相应的函数声明节点。我们解析名称空间(名称空间X)、导入(使用X)和别名(u s e X a s Y)。函数名是在给定项目的范围内解析的,也就是说,我们不需要分析include或require语句,它们通常只在运行时确定;相反,在调用图生成期间,项目范围内声明的所有函数都是已知的。请注意,PHP中有四种类型的调用:函数调用(foo())、静态方法调用(A::foo())、构造函数调用(new A())和动态方法调用($A->foo())。前三种类型的映射是明确的。对于最后一种类型,如果被调用方法的名称在项目中是唯一的,我们只将调用节点连接到相应的方法声明;如果从不同的类中知道几个同名的方法,我们就不会构造调用边缘,因为这将需要一个高度复杂的PHP类型推断过程,这超出了本文的范围(事实上,由于PHP是一种动态类型语言,而且由于其反射能力,甚至不可能静态推断每个对象的类型)。然而,看看我们在第5节中介绍的1854个项目上进行的实证研究,我们可以报告,这种方法允许我们正确映射78.9%的动态方法调用节点。此外,在总共13720545个调用节点中,函数调用占30.6%,动态方法调用占54.2%,构造函数调用占6.4%,静态方法调用占8.8%。这意味着总共有88.6%的调用节点成功映射。
**3.1.5. 组合代码属性图。**最后的图表示整个代码库,包括项目的结构、语法、控制流、数据依赖关系以及过程间调用。它由两种类型的节点组成:文件系统节点和AST节点。一些AST节点(即那些表示语句或谓词的AST节点)同时是CFG和PDG节点。此外,它还有五种类型的边:文件系统边、AST边、CFG边、PDG边和调用边。这张图是我们分析的基础。
3.2. 图形遍历
代码属性图可以以多种方式用于识别应用程序中的漏洞。例如,它们可用于识别已知包含语法级别漏洞的常见代码模式,同时从格式细节或变量名称中提取;识别控制流类型的漏洞,如未能释放锁;或者识别污染类型的漏洞,例如流入安全关键函数调用的由攻击者控制的输入等。
图形数据库经过优化,以包含以图形形式存在的高度连接的数据,并高效地处理与图形相关的查询。因此,他们是包含我们的代码属性图。然后,发现漏洞只需编写有意义的数据库查询,以识别特定模式并控制分析师感兴趣的数据流。这种数据库查询被编写为图遍历,即完全可编程的算法,它沿着图遍历,以收集、计算和输出分析员指定的所需信息。通过提供专门的图形遍历API,图形数据库可以轻松实现此类遍历。
除了逻辑错误之外,Web应用程序中出现的大多数漏洞都可以抽象为违反应用程序机密性或完整性的信息流问题。当机密信息(例如数据库凭据)泄漏到公共通道,进而泄漏到攻击者时,就会发生违反机密性的情况。相反,对完整性的攻击是从不受信任、可攻击的源(如HTTP请求)到securitycritical接收器的数据流。为了说明如何使用代码属性图来识别漏洞,本文重点讨论了威胁应用程序完整性的信息流漏洞。给定一个特定的应用程序,我们可以确定哪些数据应该保密,使用此技术可以发现违反保密性的情况。然而,要大规模地这样做,核心问题是很难或甚至不可能一般地定义应用程序的哪些数据应被视为机密数据,因此必须加以保护。因此,要发现违反保密性的信息流漏洞,需要我们仔细查看每个应用程序并识别机密数据。相反,正如我们在第3.3节中所讨论的,通常更容易确定哪些数据来自不受信任的源,并确定几种类型的一般安全关键接收器。由于我们对执行大规模分析感兴趣,因此我们将重点放在针对应用程序完整性的威胁上。
在我们继续进行更复杂的遍历以查找信息流之前,我们实现了实用程序遍历,这些实用程序遍历可以了解特定的图结构及其包含的信息,并定义了这种类型图中经常出现的典型旅行路径。这些实用程序遍历被用作更复杂遍历的基础。例如,我们定义了从AST节点到其封闭语句、封闭函数或封闭文件的实用程序遍历,以及沿着控件或数据流来回遍历,等等。我们请读者参考Yamaguchi等人[35]对效用遍历进行更详细的讨论。
3.3. 建模漏洞
如前所述,虽然我们的方法可以用于检测机密性违规,但由于固有的缺乏机密数据的概念,我们无法对大规模分析进行检测。因此,我们关注对应用程序完整性的威胁。尽管我们正在对服务器端PHP代码进行分析,但我们并不局限于发现导致针对服务器端的攻击的漏洞(例如SQL注入或命令注入)。例如,跨站点脚本和会话固定可以可能是由不安全的服务器端代码引起的,但显然是针对客户端的。我们的分析使我们能够检测两种攻击,即针对服务器的攻击和针对客户端的攻击。在本节的其余部分中,我们首先讨论攻击者可以直接控制的源。随后,我们继续讨论针对服务器的攻击和针对客户端的攻击。最后,我们描述了检测非法流量的过程。
3.3.1. 攻击者可控制的输入。在Web应用程序的上下文中,攻击者可以直接控制的所有数据都必须在HTTP请求中传输。对于PHP的更具体情况,此数据包含在多个全局关联数组中。其中,最重要的是:
$\u GET:此数组包含所有GET参数,即URL中传递的参数的键/值表示。尽管名称可能会暗示其他情况,但此数组也存在于POST请求中,包含URL参数。
KaTeX parse error: Can't use function '\u' in math mode at position 1: \̲u̲ ̲POST:POST请求正文中发…\u GET类似,此数组包含解码的键/值对,这些键/值对在POST正文中发送。
$\u COOKIE:在这里,PHP存储请求中包含的已解析COOKIE数据。此数据在Cookie标头中发送到服务器。
KaTeX parse error: Can't use function '\u' in math mode at position 1: \̲u̲请求:此数组包含以上所有内容的…\u GET优先于$\u COOKIE。
$\u服务器:此数组包含与服务器相关的不同值,例如服务器的IP地址。更有趣的是,客户端传输的所有头都可以通过这个数组访问,例如,用户代理。在我们的分析中,我们考虑对该数组的访问,其中键以HTTP\u开头,因为这是已解析HTTP请求头的默认前缀,以及键等于QUERY\u STRING的访问,QUERY\u STRING包含用于访问页面的查询字符串。
$\u文件:由于PHP是一种Web编程语言,它自然会接受文件上传。此数组包含上载文件的信息和内容。例如,由于MIME类型和文件名是攻击者可以控制的,因此我们也将其作为分析的来源。
攻击者可以控制或至少影响所有这些变量的值。在GET和POST参数的情况下,攻击者甚至可能导致无害的受害者使用自己选择的输入调用PHP应用程序(例如,使用伪造链接),而攻击者通常只能修改自己的cookie。然而,攻击者可以使用所有这些漏洞调用具有意外输入的应用程序,从而触发包含的漏洞。
**3.3.2. 针对服务器的攻击。**对于服务器端攻击,必须考虑多种漏洞类别。在下面,我们将这些类中的每一个列为以及一些特定的消毒剂,这些消毒剂可确保(正确使用时)水流不会被利用。
SQL注入是攻击者利用应用程序中的漏洞注入其选择的SQL命令的漏洞。虽然根据数据库的不同,确切的语法略有不同,但所有数据库引擎的一般概念都是相同的。在我们的工作中,我们寻找三个主要的接收器,即mysql\u查询、pg\u查询和sqlite\u查询。对于其中的每一个,PHP中都有特定的净化剂,例如mysql\u real\u escape\u string、pg\u escape\u string或sqlite\u escape\u string。
命令注入是一种攻击,其目标是在shell上执行命令。更具体地说,PHP提供了运行外部程序的不同方式:程序员可以使用popen执行程序并向其传递参数,也可以使用shell\u exec、passthru、o或backtick操作符调用shell命令。PHP提供了函数escapeshellcmd和escapeshellarg,可分别用于清理命令和参数。
当对手能够迫使应用程序执行其选择的PHP代码时,就会发生代码注入攻击。由于其动态特性,PHP允许在运行时使用语言构造eval对代码进行评估。在调用eval时以不受信任的方式使用用户输入的情况下,可以利用此漏洞执行任意PHP代码。由于必要的有效载荷取决于有缺陷代码的确切性质,因此没有通用的消毒剂可用于阻止所有这些攻击。
此外,PHP应用程序可能容易受到文件包含攻击。在这些文件中,如果攻击者可以控制传递的值以包含或要求,从而读取和解释传递的文件,那么也可以执行他们选择的PHP代码。如果相应地配置了PHP解释器,甚至可以将远程URL用作参数,从而可以加载和执行远程代码。然而,即使将PHP解释器配置为仅评估本地文件,也可能会出现漏洞:例如,如果一台服务器由多个用户共享,恶意用户可能会创建一个包含恶意内容的本地PHP文件,使其具有全球可读性,并利用其他用户的应用程序读取和执行该文件。另一种情况是,PHP文件已经存在,如果包含在错误的环境中,则会导致漏洞。
当一些未经检查、攻击者可控制的输入流到fopen调用时,可能会导致任意文件读写。根据此调用中使用的应用程序和访问模式,攻击者可以读取或写入任意文件。尤其是,攻击者可以使用。。在其输入中向上遍历目录树,以读取或写入开发人员意外的文件。这些漏洞通常通过使用正则表达式来防御,正则表达式的目的是从输入中删除点。
3.3.3. 针对客户端的攻击。除了前面讨论的针对服务器的攻击之外,还有两类影响客户端的其他缺陷。更具体地说,这些是跨站点脚本和会话固定,我们将在下面概述。
对于这些类型的漏洞,Cookie不是一个重要的来源。这是因为攻击者无法修改受害者的cookie(如果没有首先利用XSS)。相反,他们可以伪造HTML文档,迫使受害者的浏览器向有缺陷的应用程序发送GET或POST请求。
跨站点脚本(XSS)是一种攻击者能够在应用程序中注入JavaScript代码的攻击。更准确地说,目标是让此JavaScript代码在所需受害者的浏览器中执行。由于JavaScript可以完全访问当前呈现的文档,因此攻击者可以在易受攻击的应用程序上下文中控制受害者的浏览器。除了针对会话cookie盗窃的众所周知的攻击之外,这甚至可能导致密码被提取。在PHP的特定情况下,当来自客户端的输入反映回响应中时,可能会发生反射的跨站点脚本攻击。对于这些攻击,PHP还提供内置的消毒剂。在我们的分析中,我们认为这些,如htmlspecialchars、htmlentities、o或strip\u标记,是有效的消毒剂。
会话固定是我们考虑的最后一个漏洞。与前面讨论的攻击相比,这里的攻击稍微简单一些。首先,攻击者浏览易受攻击的网站以获取有效的会话标识符。为了接管受害者的会话,她需要确保对手和受害者共享同一会话。默认情况下,PHP使用Cookie管理会话。因此,如果存在允许覆盖受害者浏览器中会话cookie的漏洞,则对手可以利用该漏洞。为了成功模拟受害者,攻击者强制将受害者的会话cookie设置为自己的会话cookie。如果受害者现在登录到应用程序,攻击者也会获得相同的权限。为了发现此类漏洞,我们分析了所有进入setcookie的数据流。
3.3.4. 检测过程。在讨论了我们考虑的各种类型的缺陷之后,我们现在概述了用于在应用程序中查找缺陷的图遍历。为了优化效率,我们实际上会对我们感兴趣的每类漏洞执行两个连续的查询。
索引关键函数调用。第一个查询返回与给定安全关键函数调用相对应的所有AST节点的标识符列表。例如,它查找与函数mysql\u query的调用表达式相对应的所有节点。这样做的原因是,我们可以使用此索引进行下一次更复杂的遍历,该遍历尝试从攻击者可控制的输入中查找到这些节点的流,而不必接触图中的每个节点。作为一个示例,图4显示了Cypher查询(请参见第4节),我们使用它来标识表示echo和print语句的所有节点。(这很简单,因为echo和print是PHP中的语言构造,即它们有一个指定的节点类型)。如果操作正确,可以通过图形生成这样的索引如我们将在第5节中看到的,以高效的方式使用数据库后端。

识别关键数据流。第二个查询更复杂。其主要思想如图5所示。它的目的是找到在与安全关键函数调用相对应的节点中结束的关键数据流。
对于上一次遍历生成的索引中的每个节点,都会调用函数init,这是一个递归函数,其目的是找到甚至跨函数边界的数据流。它首先调用函数visit,该函数从给定节点开始,使用实用程序遍历源沿着PDG定义的数据依赖边向后移动;对于给定语句中未适当清理的变量,它只向后移动这些数据依赖边。它在循环中执行此操作,直到找到低源,即攻击者可控制的输入或函数参数。显然,可能有许多路径满足这些条件;它们都是并行处理的,因为函数访问中使用的每个实用程序遍历都可以看作是一个管道,它将一组节点作为输入并输出另一组节点。循环仅发射对应于低源或函数参数的节点。最后,对于从循环发射的每个节点,步骤路径输出导致这些节点发射的路径。这些路径中的每一条都对应于从参数或低源到作为函数参数给定的节点的流。请注意,由于我们向后移动,每条路径的头部实际上是作为参数给定的节点,而每条路径的最后一个元素是参数或低源。
返回函数init,检查返回路径的列表。最后一个元素不是参数(而是低源)的路径将添加到报告流的最终列表中。对于最后一个元素确实是参数的路径,我们在函数jumpToCallSiteArgs中执行过程间跳转:我们沿着定义此参数的函数的所有调用边返回到相应的调用表达式节点,将参数映射到该调用表达式中的相应参数,然后递归地应用整体遍历,继续沿着该参数的数据依赖边返回到我们在递归之后访问的每个调用表达式,返回的路径连接到被调用函数中找到的路径。为了便于演示,图5中的简化代码掩盖了一些技术细节,例如确保在循环数据依赖项或递归函数调用的上下文中终止,或者处理一些特殊情况,例如securitycritical函数调用中直接使用的清理器,但传达了一般思想。
路径查找遍历的最终结果输出是一组过程间数据依赖路径(即节点列表)从依赖于AttackerControl源的节点开始,以安全关键函数调用结束,没有使用适当的消毒液。这些流对应于潜在的漏洞,然后可由人类专家进行调查,以确认存在漏洞,或确定实际无法利用该流。

以图6中的PHP代码为例。从echo语句开始,遍历将数据相关边向后移动到 c 的 赋 值 和 函 数 栏 的 参 数 c的赋值和函数栏的参数 c的赋值和函数栏的参数a。 c 的 分 配 使 用 了 低 源 , 没 有 适 当 的 消 毒 剂 , 因 此 报 告 了 此 流 量 。 在 参 数 c的分配使用了低源,没有适当的消毒剂,因此报告了此流量。在参数 c的分配使用了低源,没有适当的消毒剂,因此报告了此流量。在参数a的情况下,遍历移动到function foo中function bar的调用表达式,并从那里移动到参数 a , 然 后 从 该 参 数 开 始 递 归 调 用 自 身 。 由 于 a,然后从该参数开始递归调用自身。由于 a,然后从该参数开始递归调用自身。由于a同样来源于低来源,未经消毒,因此也报告了此流量。请注意,即使变量 b 也 源 自 低 源 , 并 作 为 参 数 传 递 给 函 数 栏 , 参 数 b也源自低源,并作为参数传递给函数栏,参数 b也源自低源,并作为参数传递给函数栏,参数b不会流入echo语句,因此在这种情况下不会报告流。

4、实施
为了为PHP代码生成AST,我们利用PHP扩展2,将PHP 7解释器内部生成的PHP AST作为编译过程的一部分公开给PHP用户。我们的解析器实用程序为PHP文件生成AST,然后将这些AST导出为CSV格式。如第3.1节所述,它还扫描目录中的PHP文件,并生成反映项目结构的文件和目录节点。使用PHP自己的内部解析器来生成AST,而不是自己编写ANTLR语法,这意味着AST生成经过了良好的测试且可靠。此外,我们固有地支持新的PHP 7版本,包括所有语言功能。同时,解析用旧PHP版本编写的PHP代码也很有效。随着时间的推移,一些PHP功能已经被删除,使用新的解释器执行旧的PHP代码可能会导致运行时错误。但是,这些代码仍然可以被解析,并且在较新的PHP版本中不存在给定函数(例如)不会妨碍我们的分析。
对于我们的数据库后端,我们利用了Neo4J,这是一种流行的用Java编写的开源图形数据库。我们的解析器实用程序输出的CSV格式可以使用Neo4J附带的大型数据集的快速批量导入器直接导入Neo4J数据库。这使我们能够高效地访问和遍历图形,并利用服务器的高级缓存功能来提高性能。
为了生成CFG、PDG和调用边,我们实现了Joern分支[35],它为C构建了类似的代码属性图。我们扩展了Joern,能够导入PHP解析器输出的CSV文件,并将它们描述的AST映射到AST的内部Joern表示,在必要时扩展或修改该表示。然后,我们扩展了CFG和PDG生成代码,以便处理PHP AST。接下来,我们在Joern中实现了生成调用图的功能。最后,我们添加了导出功能,以CSV格式输出生成的CFG、PDG和调用边。这些边可以因此,可以与解析器输出的CSV文件同时导入Neo4J数据库。
第3.3.4节中描述的流查找图遍历是用图遍历语言Gremlin编写的,Gremlin构建在JVM语言Groovy之上。除了Gremlin之外,Neo4J还支持Cypher,这是一种用于图形数据库的类sqlquery语言,它面向更简单的查询,但对于此类简单查询也更高效。我们使用Cypher对上一节中描述的安全关键函数调用进行索引查询。Gremlin和Cypher脚本都被发送到Neo4J服务器的restapi端点,查询结果使用一个精简的Python包装器进行处理。
我们的工具是免费的开源软件,并已集成到Joern框架中,可从以下网址获得:https://github.com/octopus-platform/joern
5、评估
在本节中,我们将评估我们实现的方法。我们首先介绍使用的数据集,然后讨论针对服务器和客户端的发现。
5.1. 数据集
我们的目的是以完全自动化的方式评估我们的方法在大型项目集上的有效性,即不需要人工进行任何预选。我们使用GitHub API随机抓取用PHP编写的项目,这些项目的评级至少为100颗星,以确保我们分析的项目受到社区一定程度的关注。
因此,我们获得了一组由1854个项目组成的项目。我们确保其中没有克隆(即相同的代码基)。然后,我们应用我们的工具为这些项目中的每一个构建代码属性图,并将所有这些代码属性图导入到一个单独的图形数据库中,然后我们对该数据库进行分析。
作为实际分析之前的最后一步,我们继续在图形数据库中创建AST节点类型的索引。索引是数据库中信息的冗余副本,目的是提高信息检索的效率。具体地说,这意味着我们指示数据库后端创建一个索引,将105种不同的AST节点类型中的每一种映射到具有给定类型的所有节点标识符的列表。因此,我们可以有效地检索任何给定类型的所有AST节点。这种方法使识别与安全关键函数调用(即第3.3.4节中解释的第一个查询)相对应的节点的效率提高了几个数量级。
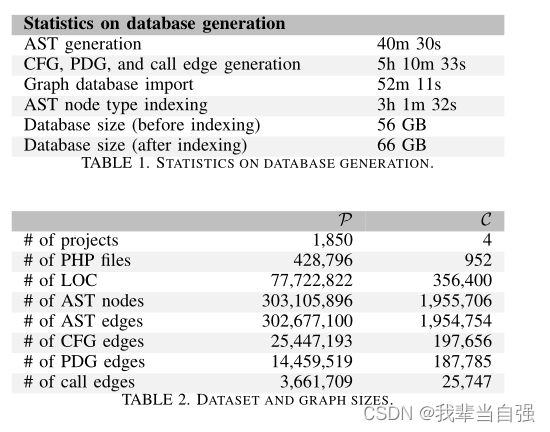
在如此大规模的情况下,很有意思的是,我们的实现在空间和时间方面表现得如何。我们在一台具有32个物理2.60 GHz Intel Xeon CPU、超线程和768 GB RAM的机器上执行了整个分析。表1给出了图形生成的时间度量和数据库的最终大小。
在检查爬网数据集后,我们判断,在我们的分析中区分两个项目子集是明智的:
C: 在已爬网的1854个项目中,我们发现有4个是明显易受攻击的教育软件,即web shell。在这个集合中,我们期望有大量未初始化的流,因为这些项目故意包含这样的流。因此,这组项目可以被视为我们查找未初始化流的方法的健全性检查:如果它运行良好,我们应该看到大量的报告。我们表明,情况确实如此。
P: 这是剩余1850个项目的集合。在这里,我们期望有一组比例较小的未初始化流,因为这些流可能对应于实际可利用的漏洞。
在表2中,我们给出了两组P和C中的项目大小和生成的代码属性图的统计数据。总之,我们分析的代码行总数接近8000万行,其中最小的项目仅包含22行代码,最大的项目包含2985451行代码。据我们所知,这是在单个研究中扫描漏洞的最大PHP代码集合。
生成的代码属性图由超过3亿个节点组成,其中约有2600万个CFG边、1500万个PDG边和400万个调用边。AST边的数量加上文件的数量等于AST节点的数量,因为每个文件的AST都是一棵树。显然,AST边比CFG或PDG边多得多,因为控制流和数据依赖边只连接与语句或谓词相对应的AST节点。
关于本节其余部分中报告的各种遍历所需的时间,我们注意到,一方面,大量的CPU不一定有多大帮助,因为对于图形数据库服务器来说,遍历很难自动并行化。另一方面,大内存的存在使整个图形数据库能够生存内存中;虽然我们没有直接的时间度量来比较,但我们希望这会带来巨大的性能提高,因为我们没有使用一个故意较小的堆来再次运行所有遍历,而只是为了强制执行I /O操作。
5.2. 调查结果
在本节中,我们将介绍我们的分析结果。如第3.3节所述,我们的方法旨在发现可用于攻击服务器或客户端的漏洞,我们将分别在第5.2.1节和第5.2.2节中讨论这些漏洞。对于每种类型的安全关键函数调用,我们都认为不同的清理器集是有效的(请参见第3.3节)。然而,对于所有这些函数,我们认为PHP函数crypt、md5和sha1是AttackerControl输入的充分转换,可以安全地将其嵌入到安全关键的函数调用中。此外,我们接受preg\u replace作为消毒剂;这是相当慷慨的,但由于我们在一个非常大的数据集上评估了我们的方法,所以我们希望将重点放在非常一般的流类型上。(相比之下,在将我们的框架用于特定项目时,可以对其进行微调,以找到非常特定的流,例如,我们可以将preg\u replace视为仅与给定的正则表达式集结合使用的消毒剂)。
5.2.1. 针对服务器的攻击。
SQL注入。对于SQL注入,我们分别对安全关键函数mysql\u query、pg\u query和sqlite\u query进行了分析。我们的大多数发现都与调用mysql\U查询有关。表3和表4总结了我们对mysql\u查询和pg\u查询的发现。在sqlite\u查询的情况下,我们的工具总共发现了202个调用,但这些调用都不依赖于攻击者可控制的输入,因此我们省略了对该函数的更详细讨论。
表3和表4分别显示了索引查询查找mysql\u query和pg\u query的所有函数调用所需的时间,以及遍历查找攻击者可控输入到这些调用的流所需的时间。此外,它们显示集合P和C中找到的函数调用的总数。然后,它们显示汇的总数,即这些函数调用子集的大小,这些函数调用确实依赖于攻击者可控制的输入,而无需使用适当的清理例程。括号中的数字表示流的总数,即以其中一个汇作为端点的报告路径数。最后,表格显示了漏洞的数量:我们调查了工具中的所有报告,并统计了实际可利用漏洞的数量。此处,漏洞定义为至少存在一个可利用流的接收器。因此,应将漏洞的数量与报告的接收器的数量进行比较,因为进入同一接收器的多个可利用流仅被视为单个漏洞。我们不报告C中的漏洞,因为这些项目是故意易受攻击的。然而,我们分析了这些报告,并确认它们确实指向大多数情况下可利用的流量。在流不可利用的情况下,将根据白名单或正则表达式检查输入,或使用自定义例程进行清理。
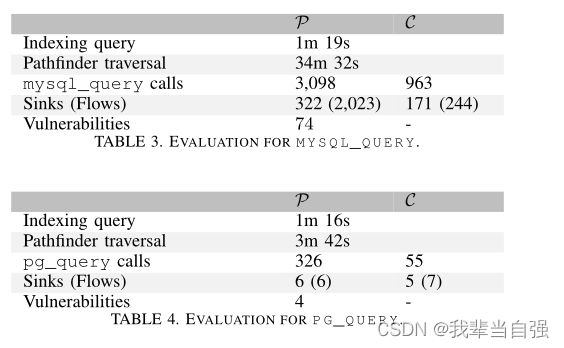
通过手动检查,我们发现mysql\u查询的322个接收器中有74个确实可被攻击者利用,命中率高达22.9%。对于PGU查询,我们的表现甚至更好:我们发现6个接收器中有4个确实易受攻击。
在我们认为不重要的流中,我们发现许多流可归因于web应用程序的受信任区域,即只有经过身份验证的受信任用户(如管理员或版主)才能首先访问的区域。例如,如果攻击者设法让登录的管理员单击某个伪造链接,则此类流仍可能导致可利用的漏洞。然而,出于我们的目的,我们假设该区域无法进入,因此,我们将重点放在剩余流量上。
在安装、迁移或更新脚本中发现了我们认为不重要的一小部分流,这些脚本通常在相关流程完成后删除(或以其他方式无法访问)。然而,如果用户应该手动采取这些措施,但忘记了这样做,那么这些流也可能会导致可利用的漏洞。然而,我们的兴趣更多地在于易于利用的缺陷,因此这些缺陷不在我们的范围之内。
最后,由于各种原因,有几个流量不重要。例如,程序员在使用KaTeX parse error: Can't use function '\u' in math mode at position 1: \̲u̲ ̲GET或\u POST等数组的值之前对其进行全局清理。我们还观察到,许多程序员通过使用特殊的清理器来清理输入,例如将其与白名单进行匹配,或将其转换为整数。对于对特定项目感兴趣的分析师来说,将此类消毒剂添加到可接受的消毒剂列表中以改善结果是很容易的。
命令注入。表5总结了我们查找命令注入的遍历结果。
这里可以很好地观察到,集合C中的接收器与调用总数的比率(即64 /270=0.24)远高于集合P(19 /1598=0.012)。
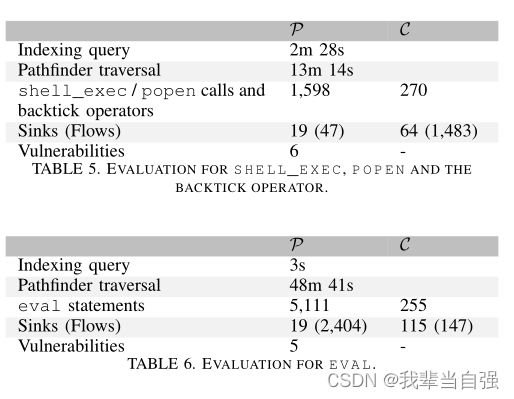
实际上,特别是对于web shell,可以预期从输入到shell命令的未初始化流。这一观察结果证实,我们的方法可以很好地找到此类流。在P中,我们只剩下19个汇(来自47个流),其中6个汇易受攻击,命中率为6 /19=0.32,即32%。对于其他流,我们发现这些流将低输入用作shell命令的一部分,并将其转换为整数,或者在执行命令之前检查它是否为整数,或者对照白名单进行检查。
代码注入。一大类漏洞是代码注入。由于这可以通过控制传递给eval的字符串或传递给include或require的URL来实现,因此我们在分析中重点关注这两个类。我们在表6和表7中总结了我们的发现。我们首先讨论eval的结果,然后讨论include和require。
对于eval,就像命令注入一样,再次观察到C中的汇与语句总数的比率(115 /255=0.6)明显高于P(19 /5111=0.004)。正如所料,代码注入在web shell或故意易受攻击的软件中比在其他项目中更为常见,这再次证实了我们的方法能够很好地找到此类流。在这种情况下,索引查询非常有效(3秒),这可以解释为eval实际上是一个PHP构造,对应于可分辨的AST节点类型:因此,数据库只需要返回该特定类型的所有节点,而在mysql\u查询的情况下,数据库需要检查星座以识别对此函数的调用。

eval构造没有通用消毒剂。当评估来自低来源的输入时,允许的输入在很大程度上取决于上下文。经过检查,我们发现许多流都不易受攻击,因为AttackerControl源首先流入数据库请求,然后将该数据库请求的结果传递到eval。在其他情况下,会使用白名单或强制转换到INT。然而,我们确实发现了5个攻击者可以注入代码的接收器,即可利用的代码注入缺陷。这将产生5 /19=0.26的命中率。
最后,我们还研究了eval中存在如此多的流和如此少的汇的原因:在其中一个项目中,经常对多个数据库请求的不同处理部分的结果执行eval。这些数据库查询通常使用来自低来源(经过适当清理)的多个变量。不同来源、不同数据库请求和结果的处理部分的各种组合导致了大量流,最终只流入少数汇。
对于PHP语言构造include /require,也没有关于如何清理输入变量的通用标准。因此,我们确实发现了100个漏洞,攻击者确实能够将自己选择的字符串注入包含在include或require语句中的文件名中。然而,在绝大多数情况下,攻击者只能控制字符串的一部分。固定前缀几乎不会伤害攻击者,因为他们可能会使用字符串。。导航目录层次结构,但很难绕过固定后缀:它要求允许远程文件包含,或者服务器上已经存在具有特定结尾的可利用文件,或者攻击者可以在服务器上创建自己的本地文件并将其标记为世界可读文件。这是对攻击类型本身的限制,而不是对我们的方法的限制。
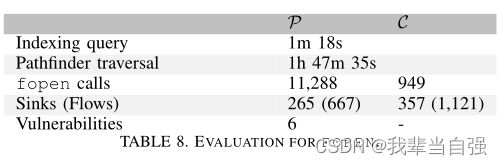
任意文件读/写。对于可能导致文件内容泄漏或损坏的漏洞,我们查看用于访问文件的函数调用fopen。我们在表8中报告了我们的调查结果。
正如所料,我们再次观察到C中的接收器与调用的比率(357 /949=0.38)大于集合P中的比率(265 /11288=0.023):在C中,任意文件通常是从低输入故意打开的。
与include /require的情况一样,这种情况下没有标准的消毒剂。在检查流之后,我们再次发现白名单、数据库请求或对整数的强制转换阻止我们利用流。即使攻击者确实对打开的文件有一定影响-程序员无意中,这并不一定会导致漏洞:在许多情况下,文件仅在内部打开和处理,不会泄漏,也不会对程序造成伤害。这解释了为什么我们在总共265个接收器中只发现了6个漏洞。
5.2.2. 针对客户端的攻击。
跨站点脚本(XSS)。在讨论了针对服务器的攻击之后,我们现在转向允许对客户端进行攻击的缺陷。跨站点脚本的结果如表9所示。
乍一看,我们的图表中有这么多echo和print节点的实例,这似乎令人震惊。然而,如果我们考虑到PHP的本质,这是可以预料到的:PHP是一种基于web的语言,专注于生成HTML输出。我们还注意到,当HTML代码与PHP代码混合时,也就是说,在<?php…?>标记,它被PHP AST解析器视为echo语句的参数。此外,内联echo标记<?=$变量;?>还可以在AST中生成echo节点。最后,将几个参数传递给echo,如echo exrp1、expr2;为每个参数生成不同的回显节点。探路者遍历所花费的时间相当长。实际上,这种遍历的运行时间随着它必须处理的节点数呈线性增长。1854个项目的平均时间为4分9秒。
由于响应用户输入是PHP中常见的场景,因此存在几种标准的清理程序:我们考虑htmlspecialchars、htmlentities和strip\u标记。尽管如此,我们仍然可以在这里观察到P中剩余流量的数量非常高(45298)。然而,还必须注意的是,它们来自一组1850个项目,因此每个项目的平均流量只有约24个。因此,在分析单个项目时检查流程似乎完全可行;很明显,流的数量随着项目的数量呈线性增长。然而,在我们的大规模研究中,我们无法在合理的时间内检查所有报告。因此,我们随机抽取了1000个流量,其中852个流入P组,最终形成了分布在116个不同项目中的726个不同汇。
在检查样本后,我们发现许多非关键路径以白名单或强制转换为整数的形式使用净化剂。在其他情况下,即使可以注入HTML和JavaScript代码,PHP脚本也会显式地将响应的内容类型设置为application /json。这样,浏览器被迫禁用其内容嗅探,并将结果解释为JSON[37]。在这种情况下不会调用HTML解析器和JavaScript引擎;因此,无法利用这种流。

尽管如此,我们还是在16个不同的项目中发现了26个可利用的XSS漏洞,例如在流行的软件LimeSurvey中。4通过预测16个易受攻击项目与报告的116个项目(13.7%)的比率,我们预计1850个项目中约有255个易受XSS攻击,这验证了XSS漏洞是Web上最常见的应用程序级漏洞这一事实【33】。因此,我们获得大量流量的事实也必须归因于我们分析了大量项目,并且这种漏洞确实非常常见。在考虑大量报告流量时,应牢记这些事实。
会话固定。正如我们在第3.3节中所讨论的,当攻击者可以任意为受害者设置cookie时,就可以进行会话固定攻击。因此,为了发现此类漏洞,我们重点关注对setcookie的函数调用,其结果如表10所示。
setcookie没有标准的消毒剂。在检查流量时,我们发现158个汇中只有一个漏洞。这主要是由于以下事实:在许多情况下,攻击者确实能够控制cookie的值。然而,对于可利用的会话固定漏洞,攻击者需要同时控制cookie的名称和值(或者cookie的名称必须已经是会话标识符cookie的名称),这是一种不常见的机会。
6、讨论
我们评估的主要目的是评估我们的方法对大量PHP项目的有效性和适用性,而无需首先手动选择这些项目,即。,以完全自动化的方式(整个项目爬行、解析、生成代码属性图、将其导入图形数据库以及运行遍历的过程都需要很少的人工交互)。报告流量的最终检查无法自动化;它需要上下文信息和人类智能来决定某些流是否确实会导致实际中的可利用漏洞。
然而,如此大规模的评估需要做出妥协。特别是,我们只能关注一般类型的流量;如果我们把重点放在一小部分选定的项目上,我们就可以更精确地对我们所寻找的流程进行建模。例如,我们会能够对特定项目中实施的自定义清理操作进行建模,以提高报告的质量,或者通过确定给定应用程序的哪些数据需要保密来查找违反应用程序保密性的信息流(请参见第3节)。然而,我们选择了大规模评估,因为据我们所知,这之前没有做过,因此我们认为这是一个有趣的研究途径。
最后,我们的方法对某些类型的漏洞的性能优于其他类型的漏洞。在代码注入的情况下,我们获得了大约25%的良好命中率,而在跨站点脚本的情况下,只有大约4%的报告数据流确实是可利用的。考虑到大规模评估是以降低命中率为代价的,我们认为这些数字仍然是合理的。就效率而言,1854个项目的综合计算时间不到一周。然而,大部分时间(超过5天)被用于遍历寻找跨站点脚本漏洞。这可以通过以下事实来解释:从低源到echo语句的流在PHP中非常常见。总而言之,我们的方法似乎具有很好的可扩展性,可以通过并行遍历进一步改进。
由于代码属性图提供了关于底层代码的丰富信息以及遍历的可编程性,我们的方法是灵活的,可以用于我们在这里没有考虑的其他类型的漏洞。例如,可以查找隐式流,即由if(attacker\u var>0){sink(0);}等代码导致的漏洞else{接收器(1);}。这样的分析需要检查代码属性图中包含的控制流,而不是数据依赖关系。同样,我们设想我们的工具可以用来发现更具体类型的缺陷,例如,魔术哈希。这些是以字符串0e开头的哈希(通常是密码)。如果PHP程序天真地使用运算符来比较两个哈希,则此类哈希将被解释为数字0,从而使攻击者很容易找到冲突。5为了使用我们的框架发现此类漏洞,所有代码都匹配哈希函数结果的语法属性(哈希,md5,…)使用运算符与另一个值进行比较,可以很容易地从代码属性图数据库中查询,并结合其他条件,例如,使用与本工作中介绍的类似技术,哈希值取决于公共输入。图形遍历的表达能力允许轻松地建模许多不同类型的漏洞。
显然,也有使用静态分析无法发现的流。例如,我们无法重建在eval构造中评估的PHP代码生成的控件或数据流。另一个有趣的例子是PHP的反射功能。例如,考虑代码段 a = s o u r c e ( ) a=source() a=source()b=$ a ; 水 槽 ( b 美 元 ) ; : 这 里 , 传 入 接 收 器 的 变 量 是 名 称 与 变 量 a;水槽(b美元);:这里,传入接收器的变量是名称与变量 a;水槽(b美元);:这里,传入接收器的变量是名称与变量a的值相同的变量$a的值不能静态确定,但取决于运行时输入,这种情况只能通过动态分析来解决。为了用静态分析来处理这种情况,我们有两种选择:我们可以过度近似或欠近似,也就是说,我们可以假设当前上下文中存在的任何变量都可能流入接收器,或者假设没有其他变量是由对手编写的。一方面,过度近似将导致更多的误报,即检测到的流在实践中不会有害。另一方面,欠近似将导致更多的误报,这意味着一些易受攻击的流仍将无法被检测到。在这里,我们决定低估,以减少误报。
全局变量也代表了一个难题:如果在分析过程中,安全关键函数的输入可以追溯到全局变量,那么不清楚该全局变量是否应被视为污染,因为这取决于操作同一变量的其他函数之前可能执行过什么,或者操作此变量的哪些文件可能包含包含当前分析的代码的文件,但此信息通常仅在运行时可用,即静态未知。
虽然在本文中,我们对大量GitHub项目进行了一次简单的爬网,但我们认为它在其他场景中可能有用。特别是,对于代码库规模大、发展快的公司来说,它在反复运行时可能非常有用,以便快速发现新引入的安全漏洞。显然,这种用例对于Wordpress平台或在线商店来说可能很有趣。在这里,我们工具的灵活性和可定制性尤其有效。
7、相关工作
我们回顾了之前研究中最密切相关的两个领域,即PHP代码中漏洞的发现和基于查询语言和图形的缺陷检测。
7.1. 发现PHP代码中的漏洞
十多年来,PHP代码中安全漏洞的检测一直是研究的重点。Huang et.al【11】提出了一种基于类型系统和类型状态的晶格算法来传播污染信息,这是解决PHP环境中静态分析问题的首批作品之一。随后,他们提出了另一种基于有界模型检查的技术[12],并将其与第一种技术进行了比较。由于应用了解析器,很大一部分PHP文件被拒绝(在他们的实验中约为8%)。相反,通过使用PHP自己的内部解析器,我们天生就能够解析任何有效的PHP文件,甚至在将来添加新的语言特性时,我们也能够解析PHP文件。如果这样的语言特性改变了控制流或重新定义了变量,我们将能够对其进行解析,但我们必须稍微更正控制流图和/或程序依赖图的生成,以避免引入不精确性。
2006年,Xie和Aiken【34】解决了静态识别PHP应用程序中SQL注入漏洞的问题。与此同时,Jovanovic等人提出了Pixy[15],这是一种PHP静态污染分析工具。他们特别关注PHP应用程序中的跨站点脚本错误。他们总共分析了六个不同的开源PHP项目。在这些测试中,他们重新发现了36个已知漏洞(27个误报),以及另外15个以前未知的缺陷(16个误报)。Wasserman和Su介绍了两项专注于静态查找SQL注入和跨站点脚本的工作【30,31】。这方面的其他工作已经在卫生处理程序的正确性方面进行了[3,36]。作为Pixy工作的后续,Jovanovic等人将其方法扩展到了SQL注入。虽然所有这些工具都是PHP应用程序漏洞自动发现领域的先驱,但它们只关注非常特定的缺陷类型,即跨站点脚本和SQL注入。在这项工作中,我们涵盖了更广泛的各种漏洞。
最近,Dahse和Holz【4】提出了RIP,它涵盖了与我们在这项工作中所做的相似的漏洞范围。RIPS构建控制流图,然后通过模拟每个基本块的数据流来创建块和功能摘要,从而可以进行精确的污染分析。在此过程中,作者发现了osCommerce、HotCRP和phpBB2中以前未知的缺陷。与我们的工作相比,他们只在少数选定的应用程序上评估了他们的工具,但没有进行大规模分析。由于RIPS使用一种类型的符号执行来构建块和函数摘要,因此尚不清楚它是否能够扩展到大量代码。代替符号执行,我们高效地构建程序依赖图来进行污染分析;据我们所知,我们是第一个真正为PHP构建程序依赖图的人。此外,RIPS缺乏图形遍历的灵活性和可编程性:它能够检测硬编码的预定义漏洞集。相反,我们的工具是一个允许开发人员编写自己的遍历的框架。它可以用于以通用的方式(正如我们在本工作中所演示的那样)或针对特定的应用程序,对各种类型的漏洞进行建模。当用于特定应用程序时,它甚至可以用于检测机密类型属性。
Dahse和Holz通过检测二阶漏洞(例如,持久性跨站点脚本)继续他们的工作,在六个不同的应用程序中识别了150多个漏洞【5】。2015年,Olivo等人【23】讨论了二阶拒绝服务漏洞的静态分析,并提出了受其启发的后续工作。他们分析了六个应用程序,这些应用程序与之前工作中分析的应用程序部分重叠,并发现了37个漏洞,以及18个误报。这些作品可视为与我们的作品正交。
总之,虽然在PHP静态分析这一主题上已经有了大量的研究,但这些工作集中在一小部分(相同的)应用程序上。相比之下,我们的工作不是为了分析单个应用程序非常详细。相反,我们的目标是实现一种方法,该方法可以很好地扩展到扫描大量代码,并具有足够的灵活性,以尽可能少的努力添加对其他漏洞类型的支持。不幸的是,由于一方面我们通常无法访问已实现的原型,另一方面报告的细节有限,因此很难直接比较我们的工具和其他工具之间的结果。其他作者也注意到了这一困难【16,4】。通常,只报告检测到的漏洞数量,而不报告漏洞本身。即使是比较这些数字也不容易,因为在如何计算脆弱性方面,还没有普遍商定的标准。例如,当存在多个易受攻击的数据流进入同一个安全关键函数调用时,不清楚是否应将每个流计算为漏洞,或是否应将其计算为单个漏洞,或介于两者之间的任何漏洞(例如,取决于不同流的相似性)。在这项工作中,我们精确地解释了如何计算漏洞,并打算在GitHub上为研究人员和开发人员公开我们的工具。
7.2. 使用查询语言和图形进行缺陷检测
我们的工作使用对图形数据库的查询来描述易受攻击的程序路径,这是一种与通过查询语言进行缺陷检测密切相关的方法,以及使用基于图形的程序表示进行静态程序分析。一些研究人员过去曾考虑过使用查询语言检测安全性和其他bug的概念[例如,7、9、19、21、24]。特别是,Martin等人[21]提出了程序查询语言(PQL),它是程序的中间表示形式。通过这种表示,他们能够识别违反设计规则的行为,发现程序中的功能缺陷和安全漏洞。Livshits和Lam【20】使用PQL描述了Java程序中SQL注入和跨站点脚本的典型实例,并成功识别了九种流行开源应用程序中的29个缺陷。基于图的程序分析有着悠久的历史,可以追溯到Reps【25】关于通过图可达性进行程序分析的开创性工作,以及Ferrante等人【6】引入的程序依赖图。沿着这条研究路线,Kinloch和Munro【17】提出了组合C图,这是一种专门设计用于帮助基于图的缺陷发现的数据结构,而Yamaguchi等人【35】提出了用于漏洞发现的代码属性图。他们的工作启发了我们的论文,他们首先使用代码属性的图形表示来检测C代码中的漏洞。我们的工作显著地扩展了他们的工作,首先证明可以使用类似的技术来识别高级动态脚本语言中的漏洞,使其适用于识别Web应用程序中的漏洞,其次,通过添加调用图,允许进行过程间分析。
Alrabaee等人采纳了他们的想法,他们使用图形表示来检测代码重用。他们在这方面的具体目标是简化逆向工程师在分析未知二进制文件时的任务。Johnson等人[14]也使用了使用程序依赖图的概念,他们为Java构建了PIDGIN工具。具体来说,他们创建图形并对其运行查询,以便检查程序的安全保证,在开发过程中加强安全性,并基于已知缺陷创建策略。除了在发现缺陷方面有更具体的用途外,有几项工作还研究了PDG的信息流控制,如[10、8、26]。
8、结论
鉴于PHP作为一种Web编程语言的普遍存在,我们的目标是开发一种灵活且可扩展的分析工具,以检测和报告大型Web应用程序中的潜在漏洞。为此,我们构建了代码属性图,即PHP的语法树、控制流图、程序依赖图和调用图的组合,并证明它们可以很好地识别高级动态脚本语言中的漏洞。我们将PHP应用程序中可利用流产生的几种典型漏洞建模为这些图上的遍历。我们在GitHub上爬行了1854个流行的PHP项目,构建了代表这些项目的代码属性图,并通过在这个大型数据集上运行流查找遍历来展示我们的方法的有效性和可伸缩性。我们能够观察到,在这些项目的一小部分中,由故意易受攻击的软件组成的报告流的数量远远高于其他项目,从而证实了我们的方法能够很好地检测此类流。此外,我们还在其他项目中发现了100多个意外漏洞。我们证明,可以在合理的时间内大规模发现PHP应用程序中的漏洞。我们的代码属性图为构建更多复杂的遍历奠定了基础,通过编写适当的图遍历,可以发现其他类别的漏洞,无论它们是通用的还是特定于应用程序的。我们公开了我们的工具,为研究人员和开发人员提供了这种可能性。