Redis——实现优惠券秒杀
目录
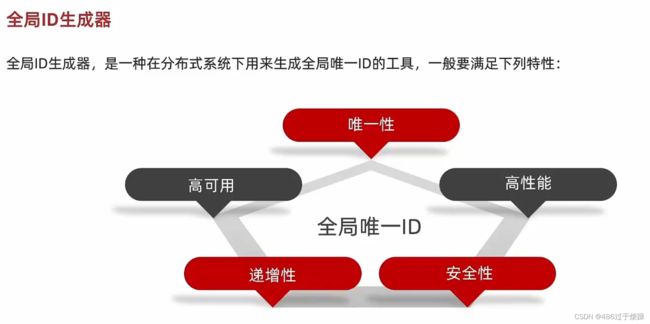
全局ID生成器
ID应该遵循的原则
Redis实现全局唯一id(采用上图第一种)
总结:
实现优惠券秒杀下单
大致流程
乐观锁的实现方法
总结
一人一单
模拟集群下的并发安全问题
后续链接:
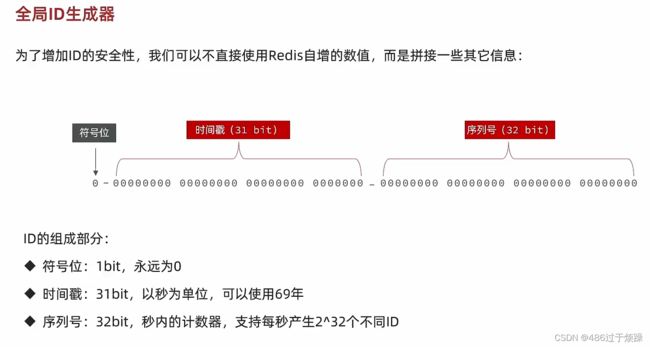
全局ID生成器
当数据规模达到一定量级的时候会影响到数据库的性能,那么这个时候我们一般会沿着AKF的Z轴使用分库分表的策略,以降低单表的数据量,从而提高数据库的性能。但是分库分表后,我们怎么保证ID的全局唯一性呢?这个时候ID生成器就登场了。

ID应该遵循的原则
1、ID应该是按时间有序的,因为在某些场景上可能会用到,比如获取商品的评论,一般需要按照评论的时间倒序显示,如果评论ID是无序的那边就需要添加额外的字段排序。另外ID如果是有序,可以提升数据库的性能,因为有序的ID,对于关系型数据库来说可以有效的实现插入数据的顺序写磁盘,如果ID是无序的,那么每次写入的位置都不一样是随机写,更严重的是可能需要移动数据与页分裂,从而导致页空洞,不能高效的利用磁盘空间;
2、从ID中应该能够反解出ID所属的业务,这样在排查问题的过程中可能有帮助;
3、ID占用内存应该足够小,最好能够用一个64bit的整数表示,从而能够提升数据库的性能,节约内存与磁盘空间。
基于如上的原因,UUID虽然很高效且唯一,但显然是不适合作为全局ID的,因为其不是有序的,没有业务含义,同时还需要占用比较多的空间。
为此我们一般用snowflake算法(雪花算法)或者通过数据库生成ID做为全局ID。
snowflake算法(雪花算法)
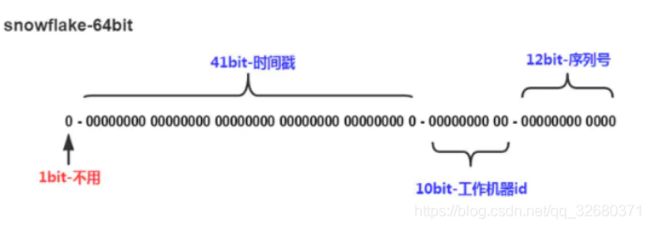
snowflake算法生成id的结果是一个64bit大小的整数,它的结构如下图:
第一种:
第二种:
下面简单介绍一下第二种的:
1位,不用。二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0;
41位,用来记录时间戳(毫秒)。41位可以表示2^41个数字,也就是说41位可以表示2^41个毫秒的值,转化成单位年则是2^41/(1000*60*60*24*365)约等于69年;
10位,用来记录工作机器id。可以部署在2^10=1024个节点,包括5位IDC Id和5位workerId,可以表示的最大正整数是2^5−1=31;
12位,序列号,用来记录同毫秒内产生的不同id。 12位(bit)可以表示的最大正整数是2^12−1=4095,即同一机器同一时间截(毫秒)内产生的4096个ID序号。
在实际使用过程中,我们一般会做如下的调整:
1、适当调整不同位数的含义:如时间戳字段可以以10ms为单位,可以用40bit;工作机器id可以做一些拆分把业务id也放进去或者IDC id与workerId的位数做一些调整;序列号的位数也可以适当做一些调整;
2、如果系统的规模不大,ID生成可以内嵌到业务代码中,这样ID生成就会非常的高效,也不会对系统的性能产生影响,但是系统主机的个数一般还是比较多的,这时就得引入第三方组件来管理主机id;
3、如果系统的规模比较大,我们可以在一个机房中部署2个或更多个ID生成服务,每个机房尽量调用本机房的ID生成服务。这样每次获取ID多增加的时间成本也很有限,如果还想省却这个时间,业务可以批量获取,不过一般不建议批量获取。
不过 snowflake算法也有如下的问题:
1、我们一般需要打开时钟同步功能,这样ID才能够最大化的保证按照时间有序,但是时钟同步打开后,就可能会时钟回拨了,如果时钟回拨了,那么生成的ID就会重复,为此我们一般打开时钟同步的同时关闭时钟回拨功能;
2、序列号的位数有限,能表示的ID个数有限,时钟同步的时候,如果某台服务器快了很多,虽然关闭了时钟回拨,但是在时间追赶上前,ID可能已经用完,当自增序列号用完了,我们可以做如下的工作:停止ID生成服务并告警、如果时钟回拨小于一定的阈值则等待、如大于一定的阈值则通过第三方组件如ZK重新生成一个workerid或者自增时间戳借用下一个时间戳的ID;
3、服务重启后,ID可能会重复,为此我们一般需要定期保存时间戳,重启后的时间戳必须大于保存的时间戳+几倍保存间隔时间(如3倍),为什么要几倍呢,主要是考虑到数据丢失的情况,但是如果保存到本地硬盘且每次保存都fsync,此时1倍即可。重启后如果小于可以像第二点那样类似处理;
4、如果请求ID的QPS不高,比如每毫秒一个,那么每次获取的ID的尾号都是0,那么基于ID做分库分表,可能数据分布就会不均,此时我们可以增加时间戳的时间间隔或者序列号每次从随机一个值开始自增。
更多方案介绍参见:
链接:https://tech.meituan.com/2017/04/21/mt-leaf.html
Redis实现全局唯一id(采用上图第一种)
@Component
public class RedisIdWorker {
/**
* 时间戳
*/
private static final long BEGIN_TIMESTAMP = 1640995200L;
/**
* 序列号的位置
*/
private static final int COUNUT_BITS = 32;
@Resource
private StringRedisTemplate stringRedisTemplate;
//keyPrefix区分业务逻辑
public long nextId(String keyPrefix){
//1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timeStamp = nowSecond - BEGIN_TIMESTAMP;
//2.生成序列号
//不能永远使用一个key,不然可能会超过上限(2^32),所以我们可以拼上时间戳
//2.1获取当前日期
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
//2.2自增长
Long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
//3.拼接并返回
return timeStamp<<32|count;
}
public static void main(String[] args) {
LocalDateTime time = LocalDateTime.of(2022, 1, 1, 0, 0, 0);
long second = time.toEpochSecond(ZoneOffset.UTC);
//看看开始的时间戳
System.out.println("Second = "+second);
}
}总结:
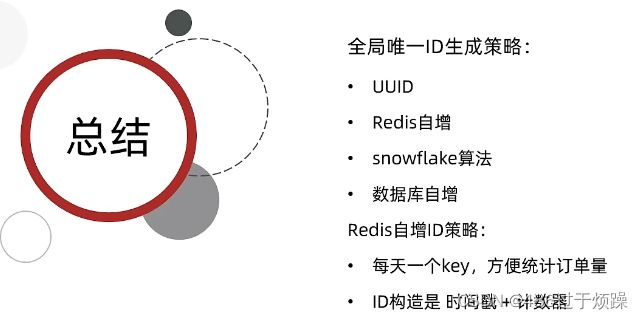
UUID是16进制的字符串结构,而且并不是单调递增,不满足上述全局Id特性,但并不友好
Redis自增实现较为简单
雪花算法,多了个机器Id,性能理论上会比Redis,但对时钟敏感
数据库自增,是指重新拿一张某一张特定的表代替自增
实现优惠券秒杀下单
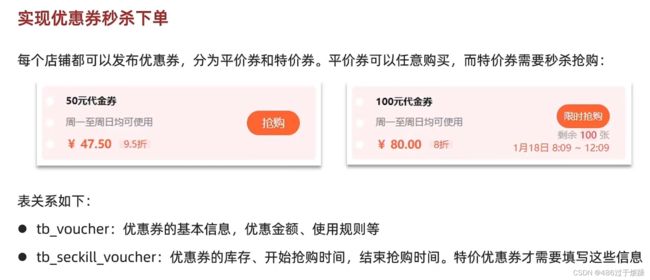
两个表的结构展示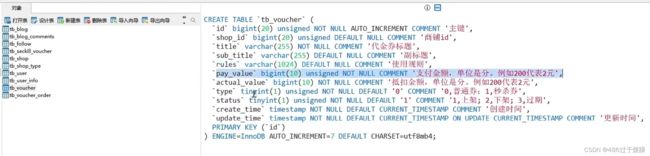

大致流程
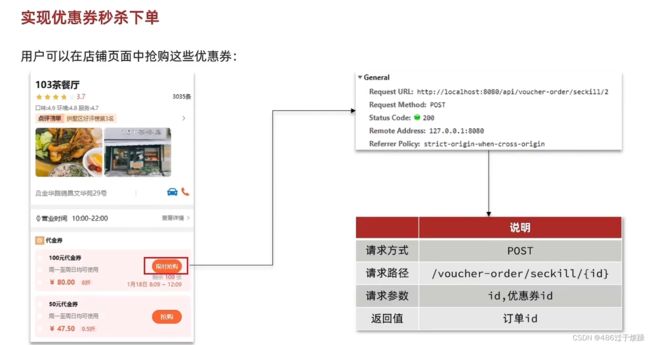
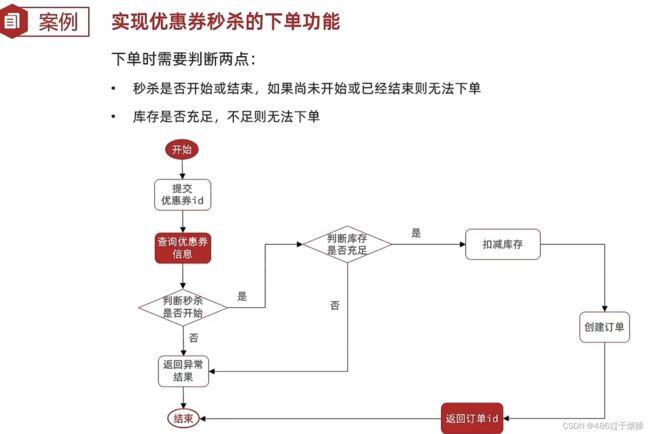
涉及多表之间的操作,一般需要加上事务(@Transactional)
实现代码:
@Override
@Transactional
public Result seckillVoucher(Long voucherId) {
//1.查询优惠券信息
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
//2.判断秒杀是否开始
if(voucher.getBeginTime().isAfter(LocalDateTime.now())){
return Result.fail("秒杀尚未开始");
}
if(voucher.getEndTime().isBefore(LocalDateTime.now())){
return Result.fail("秒杀尚未开始");
}
//3.判断库存是否足够
if(voucher.getStock()<1){
return Result.fail("已售空");
}
seckillVoucherService.update()
.eq("voucher_id",voucherId)
.setSql("stock = stock - 1")
.update();
//创建订单
VoucherOrder voucherOrder = new VoucherOrder();
//获取用户Id
UserDTO user = UserHolder.getUser();
Long userId = user.getId();
voucherOrder.setUserId(userId);
//设置优惠券Id
voucherOrder.setVoucherId(voucherId);
//设置订单Id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
save(voucherOrder);
//返回订单Id
return Result.ok(orderId);
}在高并发场景下,可能会出现“超卖“现象 ”
正常情况:
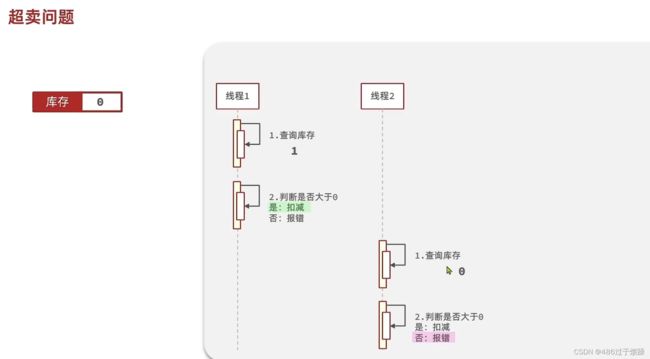
"超卖" 情况:

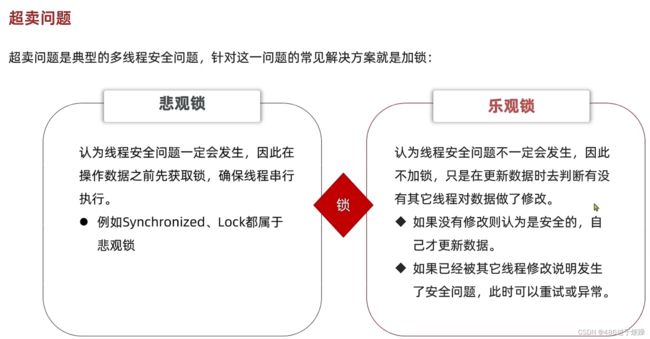
解决多线程安全问题:悲观锁与乐观锁
乐观锁的实现方法
版本号法:通过添加版本号,根据每次查询的版本号是否已经更新,来判断数据是否已经更新

CAS法:在版本号的基础上进行了优化,我们可以通过对之前查询得到的数据是否更新,来判断数据是否已经更新,充当了版本号的作用
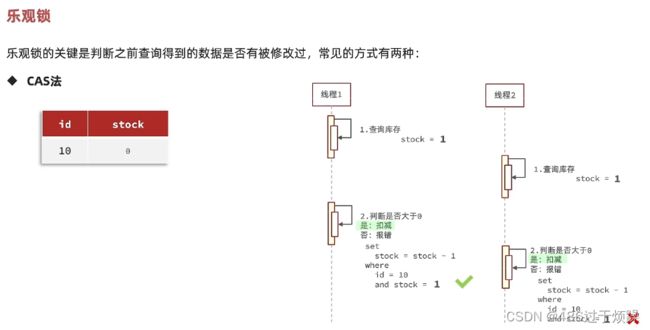
虽然保证了不会出现“超卖”现象,但是假设如果有100个线程在同一时间都购入该消费券,仅有第一个才能成功,所以我们需要对以上的乐观锁进行一定的修改,不一定要将之前查询的数据相等于现在的库存才可以进行购买,只需库存大于0的时候就可以通过
实现代码:
@Override
@Transactional
public Result seckillVoucher(Long voucherId) {
//1.查询优惠券信息
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
//2.判断秒杀是否开始
if(voucher.getBeginTime().isAfter(LocalDateTime.now())){
return Result.fail("秒杀尚未开始");
}
if(voucher.getEndTime().isBefore(LocalDateTime.now())){
return Result.fail("秒杀尚未开始");
}
//3.判断库存是否足够
if(voucher.getStock()<1){
return Result.fail("已售空");
}
seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id",voucherId).gt("stock",0)//仅在这里添加新的判断条件即可
.update();
//创建订单
VoucherOrder voucherOrder = new VoucherOrder();
//获取用户Id
UserDTO user = UserHolder.getUser();
Long userId = user.getId();
voucherOrder.setUserId(userId);
//设置优惠券Id
voucherOrder.setVoucherId(voucherId);
//设置订单Id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
save(voucherOrder);
//返回订单Id
return Result.ok(orderId);
}总结

一人一单
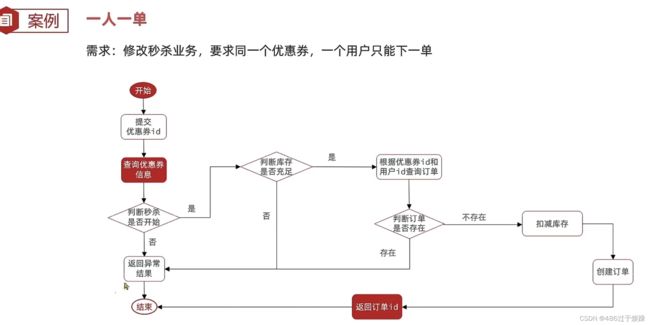
一人一单同时也要考虑高并发的情况,添加synchronized关键字上锁,不在方法上添加(因为这样锁的范围大,任何一个用户来都要加上锁,一人一单所以只需对该用户上锁,即Id上锁,把锁的范围缩小,提升效率)而是对userId上锁,同时也需要注意,每次请求的userId对象都是一个全新的Id对象,因此对象变了锁就变了,所以要求值一样,用了userId.toString(),但toString方法内是返回一个new出来的对象,还会在变,所以再后面添加intern()方法,返回字符串的规范表示(如果池中已经包含一个等于这个String对象(由equals(Object)方法确定的字符)则返回池中的字符串;否则将String添加到池内并返回该对象的引用)
@Override
public Result seckillVoucher(Long voucherId) {
//1.查询优惠券信息
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
//2.判断秒杀是否开始
if(voucher.getBeginTime().isAfter(LocalDateTime.now())){
return Result.fail("秒杀尚未开始");
}
if(voucher.getEndTime().isBefore(LocalDateTime.now())){
return Result.fail("秒杀尚未开始");
}
//3.判断库存是否足够
if(voucher.getStock()<1){
return Result.fail("已售空");
}
//创建订单
return createVoucherOrder(voucherId);
}
@Transactional
public Result createVoucherOrder(Long voucherId) {
//获取用户Id
UserDTO user = UserHolder.getUser();
Long userId = user.getId();
synchronized (userId.toString().intern()){
//一人一单
Integer count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if(count>0){
//说明用户之前买过了
return Result.fail("用户已经购买过一次");
}
VoucherOrder voucherOrder = new VoucherOrder();
//扣减库存
seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id",voucherId).gt("stock",0)
.update();
//设置订单Id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
//设置优惠券Id
voucherOrder.setVoucherId(voucherId);
//设置用户Id
voucherOrder.setUserId(userId);
save(voucherOrder);
//返回订单Id
return Result.ok(orderId);
}
}模拟集群下的并发安全问题
模拟集群
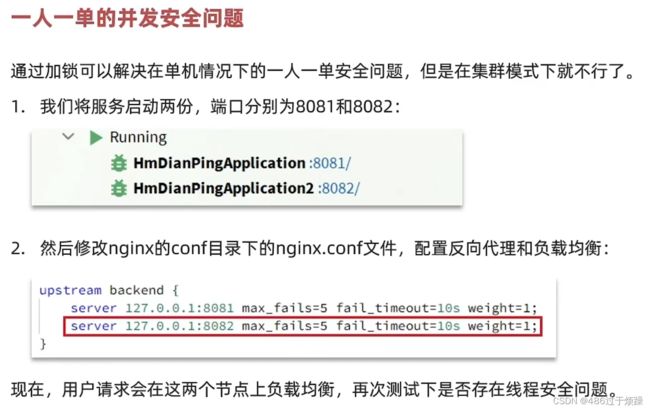
同一个用户,两个请求同时到达,锁没有锁住,有两个订单产生;原因是因为在集群模式下或在一些分布式系统下,有多个JVM的存在,每个JVM都有自己的锁,导致每一个锁都可以由一个线程获取,就出现了并行运行的状况,出现了问题,这就要求我们实现多个JVM的锁得是同一把锁

后续链接
基于Redis的分布式锁实现(秒杀优惠券的优化)_486过于烦躁的博客-CSDN博客