Linux虚拟机(Centos)安装及配置分布式Hadoop安装部署使用
目录
一、虚拟机节点的搭建与配置
1.1主节点的搭建和配置
1.1.1准备工作
1.1.2主节点虚拟机基本配置
1.1.3安装CentOS6.5虚拟机
1.1.4主节点虚拟机网络配置
2.1.5安装Java和Hadoop
1.2从节点的搭建与配置
1.2.1准备工作
1.2.2从节点网络配置
二、Hadoop主、从节点的配置
2.1修改hosts文件,将名称和IP建立联系(图9)
2.2设置三个节点互相ssh免密登陆
2.3主节点参数设置
2.3.1增加从节点,修改从节点列表(图11)
2.3.2修改JAVA_HOME位置,更新Hadoop环境设置
2.3.3修改Hadoop核心配置文件
2.3.4修改Hdfs配置文件
2.3.5修改Yarn配置文件
2.3.6修改 mapreduce配置文件
2.4将主节点设置同步到从节点
2.5格式化namenode,删除缓存
2.7启动与关闭命令
2.8访问Hdfs页面验证是否安装成功
三、Hadoop的使用
3.1Hadoop计算PI值
3.2Hadoop单词计数
3.2.1建立待计数的文本
3.2.2将文章上传到Hdfs(图22,23)
3.2.3运行单词计数
3.2.4查看结果
-
一、虚拟机节点的搭建与配置
1.1主节点的搭建和配置
1.1.1准备工作
安装VMware软件,下载CentOS6.5镜像文件,Hadoop2.7包,Java1.8包。
注:由于hadoop分布式运行需要同时运行三个虚拟机(一个主节点,两个从节点),需要对电脑的虚拟内存重新设置或使用VMware16及以上版本,否则在开启第三个虚拟机时,会因为虚拟内存不足蓝屏。经过尝试,为电脑物理内存两倍为佳。
1.1.2主节点虚拟机基本配置
本组采用的主节点虚拟机配置如下(图1):
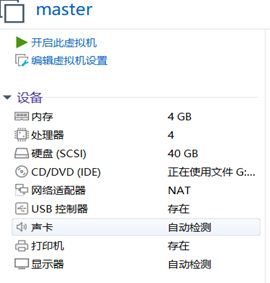
图1 基本配置
1.1.3安装CentOS6.5虚拟机
按上述配置建立虚拟机和虚拟硬盘后,将准备好的镜像挂载,通过镜像文件安装CentOS6.5。
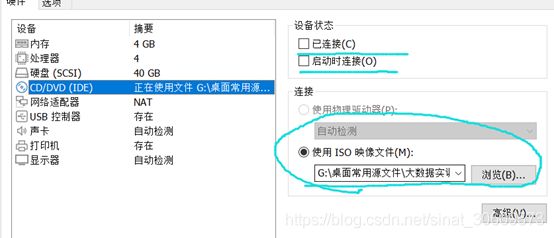
图2 挂载镜像
注:在系统安装完成后及时关闭CD硬件的连接,避免重启后仍启动镜像。
1.1.4主节点虚拟机网络配置
1、在虚拟网络编辑器中查看网关信息(图3、4)。
图3
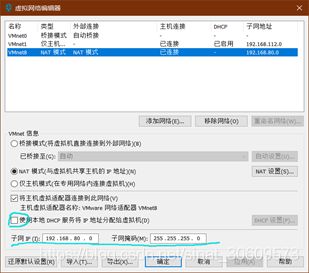
图4 虚拟网络编辑器
2、设置虚拟网卡对应IP和子网掩码(图5)。

图5
3、对虚拟机内网络参数进行修改(图6、7)
nano /etc/sysconfig/network-scripts/ifcfg-eth0

图6
DEVICE=eth0
HWADDR=00:0C:29:31:20:7F
TYPE=Ethernet
UUID=722e3a7a-5279-4bca-ab17-c05b973677e7
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.80.40
NETMASK=255.255.255.0
GATEWAY=192.168.80.2
DNS1=192.168.80.2
##修改IP和网关,并设置为静态
此时可使用xshell和xftp链接虚拟机进行更方便操作。
nano /etc/sysconfig/network
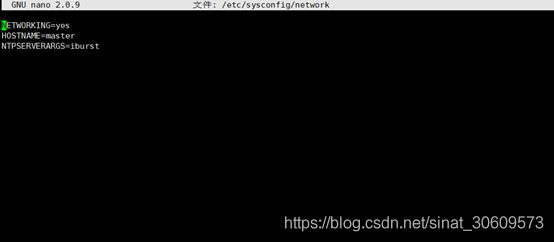
图7 设置主机名
3、关闭防火墙
终端中运行以下命令:
service iptables stop 关闭防火墙
chkconfig iptables off 关闭防火墙开机自启动
2.1.5安装Java和Hadoop
将Java包和Hadoop包分别使用 Xftp 传入master中,解压到合适的目录,将二者解压,并在 /etc/profile中添加环境变量。
nano /etc/profile
本组使用的路径和配置如下
##JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
##MAIL_OFF
unset MAILCHECK
##HADOOP_HOME
export HADOOP_HOME=/usr/local/soft/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export JAVA_LIBRARY_PATH=/usr/local/lib/hadoop-native
1.2从节点的搭建与配置
1.2.1准备工作
利用VMware的克隆功能将虚拟机master克隆2个,分别命名为node1,node2。受电脑性能限制,在可能后对虚拟机配置进行调整,如下(图7)

图8从节点配置
1.2.2从节点网络配置
分别对node1,node2作如下配置
1、修改链接设置(图8),记录ATTR地址(图9)
nano /etc/udev/rules.d/70-persistent-net.rules
将名为eth0的配置删除,将eth1改为eth0,记录下ATTR地址

图9修改链接设置
2、重设网络链接
nano /etc/sysconfig/network-scripts/ifcfg-eth0
#以下为本组从节点node1的设置
DEVICE=eth0
HWADDR=00:0c:29:4e:20:e9
TYPE=Ethernet
UUID=722e3a7a-5279-4bca-ab17-c05b973677e7
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.80.48
NETMASK=255.255.255.0
GATEWAY=192.168.80.2
DNS1=192.168.80.2
#以下为本组从节点node2的设置
DEVICE=eth0
HWADDR=00:0c:29:26:f3:45
TYPE=Ethernet
UUID=722e3a7a-5279-4bca-ab17-c05b973677e7
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.80.56
NETMASK=255.255.255.0
GATEWAY=192.168.80.2
DNS1=192.168.80.2
3、修改主机名
仿照2.2.4中的方法将从节点的hostname分别改为node1,node2
-
二、Hadoop主、从节点的配置
2.1修改hosts文件,将名称和IP建立联系(图9)
此设置需要在每一个节点虚拟机上设置
nano /etc/hosts
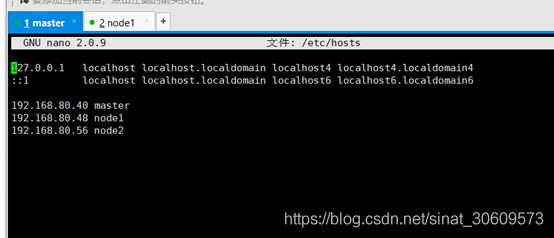
图10修改hosts文件
2.2设置三个节点互相ssh免密登陆
分别在三个节点执行以下命令
ssh-keygen -t rsa
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
2.3主节点参数设置
先进入到目录下
cd /usr/local/soft/hadoop-2.7.2/etc/Hadoop
2.3.1增加从节点,修改从节点列表(图11)

图11增加从节点
2.3.2修改JAVA_HOME位置,更新Hadoop环境设置
nano hadoop-env.sh
增加语句(根据java实际安装位置)(图12)
export JAVA_HOME=/usr/local/java/jdk1.8.0_171

图12更改环境
2.3.3修改Hadoop核心配置文件
nano core-site.xml
在configuration中间增加以下内容
2.3.4修改Hdfs配置文件
Hdfs是Hadoop所使用的分布式文件管理系统。
nano hdfs-site.xml
在configuration中间增加以下内容
2.3.5修改Yarn配置文件
nano yarn-site.xml
在configuration中间增加以下内容
2.3.6修改 mapreduce配置文件
重命名
mv mapred-site.xml.template mapred-site.xml
nano mapred-site.xml
在configuration中间增加以下内容
2.4将主节点设置同步到从节点
scp -r /usr/local/soft/hadoop-2.7.2/ node1:/usr/local/soft/
scp -r /usr/local/soft/hadoop-2.7.2/ node2:/usr/local/soft/
scp:远程拷贝命令
2.5格式化namenode,删除缓存
每次开始运行Hadoop时,都要运行以下指令
格式化namenode
hdfs namenode -format
需要手动将每个节点的tmp目录删除,在所有节点都要执行
rm -rf /usr/local/soft/hadoop-2.7.2/tmp
2.7启动与关闭命令
start-all.sh 启动Hadoop
stop-all.sh 关闭Hadoop
2.8访问Hdfs页面验证是否安装成功
start-all.sh 启动Hadoop(图13)
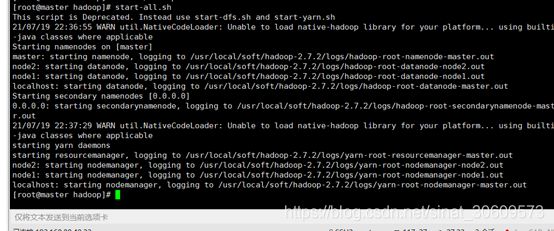
图13启动Hadoop
根据本小组分配的master主节点的IP,访问相应网址(图14)
http://192.168.80.40:50070/
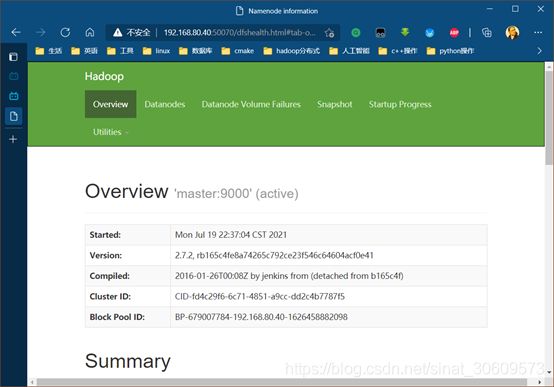
图14 Hadoop网页端控制台
-
三、Hadoop的使用
在Windows下使用Hadoop前,需要先将虚拟机的几个节点加入到hosts列表中(图15),使得Windows识别到虚拟机主机。
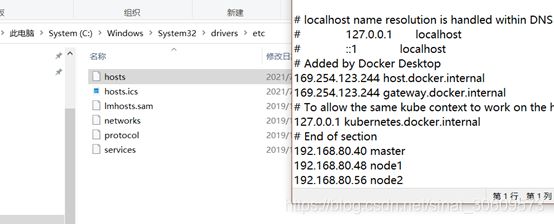
图15 在hosts中加入虚拟机地址和hostname
在使用例子前,先cd到以下目录,Hadoop的MapReduce例子均在此文件夹下。
cd /usr/local/soft/hadoop-2.7.2/share/hadoop/mapreduce
3.1Hadoop计算PI值
在当前目录下,执行此命令(图16)
hadoop jar hadoop-mapreduce-examples-2.7.2.jar pi 20 20
两个20 分别表示20个map任务和20个reduce任务,值越高,pi值越准。
![]()
图16 算圆周率的实例测试
可以访问192.168.80.40:8088,查看运行情况(图17)
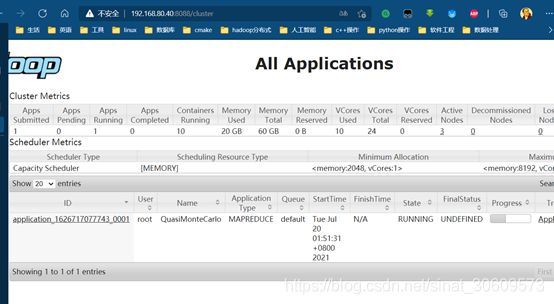
图17 运行情况
运行结果如下(图18,19):

图18
![]()
图19
此结果被保存至缓存目录中(图20)
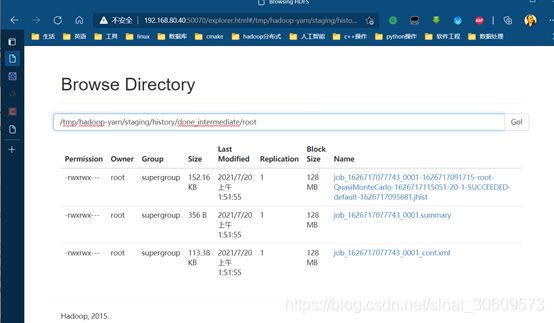
图20
3.2Hadoop单词计数
统计文章文本中,每个单词出现的次数。
3.2.1建立待计数的文本
随机找一篇文章,在master下新建文件a.txt,将文章粘贴进去(图21)。
图21 建立文章
3.2.2将文章上传到Hdfs(图22,23)
hadoop fs -put a.txt /

图22 上传文章到Hdfs根目录
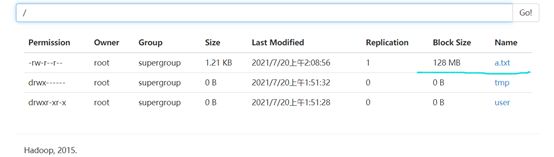
图23
3.2.3运行单词计数
执行下列命令(图24)
hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /a.txt /a
/a指将结果放入,目录a

图24 开始运行
等待一段时间,可以看到任务已经完成(图25)

图25 任务完成
3.2.4查看结果
可以看到,自动生成了目录a,并将结果放入了a(图26,27)

图26

图27
通过命令行查看结果文件(图28)
hadoop fs -cat /a/part-r-00000

图28 查看结果(部分)