hadoop2.8配置_Hadoop 2.8集群安装及配置记录
第一部分:环境配置(含操作系统、防火墙、SSH、JAVA安装等)
Hadoop 2.8集群安装模拟环境为:
主机:Hostname:Hadoop-host,IP:10.10.11.225
节点1:Hostname:Hadoopnode1,IP:10.10.11.254
两台机器均为Centos 7.*,64位版本。
主机操作系统安装时采用界面化形式,节点1采用最小化安装。安装完成后,首先设置机器名称并设置固定IP,方法如下:
1.修改主机名:
修改/etc/host、hostname文件,注意请在host文件中一并添加hadoopnode1机器的IP地址。
10.10.11.225 Hadoop-host10.10.11.254hadoopnode1
::1 localhost
2.修改IP为固定IP方法:
修改网络配置文件:/etc/sysconfig/network-scripts/ifcfg-eno16777736的内容,最终如下:
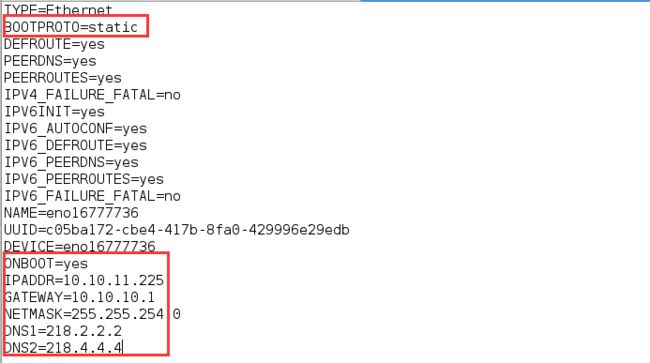
最难的是DNS的设置,刚开始在网上找了很多资料,都说是设置为虚拟机的网关即可,设置后发现主机与节点计算机之间可以Ping通,但是无法上网。几经周折,后发现网络配置页面里面明明写着DNS地址,于是抄过来,按其修改后保存后一切正常。
3.SSH面密码登录设置
首先生成rsa密匙与公匙,ssh-keygen -t rsa,一路回车后生成。然后利用命令:ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected],然后输入密码后搞定。
备注:如果执行以上命令时遇到以下错误:
The authenticity of host 192.168.***.*** can't be established.可运行命令:ssh -o StrictHostKeyChecking=no 192.168.***.***,然后输入密码解决。
4.升级java openjdk。
centos 7.*系统版本自带openjdk,因为懒得缘故,本人想利用openjdk,这样就不用安装java jdk了。在此,用命令:yum install java,升级openjdk。升级完后,通过查询得知,openjdk的安装路径默认为:usr/lib/jvm/,根据此路径,设置系统的全局变量JAVA_HOME。打开文件/etc/profile,并在文件最后添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-2.b11.el7_3.x86_64/jre
export PATH=$JAVA_HOME/bin:$PATH
注意,全局变量中的路径中是到bin文件夹上级目录位置,因此,路径最终必须为****/jre.
第二部分:安装并配置Hadoop 2.8
本人比较喜欢wget方式,找一个国内的Hadoop镜像站点,下载后,解压到指定目录(本示例解压到:/usr/hadoop),然后打开文件/etc/profile,并在文件最后添加:
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
保存并退出。
配置/usr/hadoop/etc/hadoop/文件夹下的各个配置文件,分别为:
core-site.xml

hdfs-site.xml
dfs.replication
2
dfs.name.dir
/usr/local/hadoop/hdfs/name
dfs.data.dir
/usr/local/hadoop/hdfs/data
dfs.namenode.secondary.http-address
hadoop-host:9001
dfs.webhdfs.enabled
true
dfs.permissions
false
mapred-site.xml
mapreduce.framework.name
yarn
yarn-site.xml
yarn.resourcemanager.address
hadoop-host:18040
yarn.resourcemanager.scheduler.address
hadoop-host:18030
yarn.resourcemanager.webapp.address
hadoop-host:18088
yarn.resourcemanager.resource-tracker.address
hadoop-host:18025
yarn.resourcemanager.admin.address
hadoop-host:18141
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-2.b11.el7_3.x86_64/jre
即与系统的环境变量JAVA_HOME保持一致。
设置关键的分布式IP地址配置:(补充:只配置slaves文件也可以)
masters文件:
10.10.11.225
slaves文件:
10.10.11.254
10.10.11.225
如果在slaves文件里面没有包含Hadoop主机IP,那么启动时会只有一个datanode.
至此Hadoop配置工作告一段落。
最后,利用命令:scp –r /usr/hadoop root@hadoopnode1 :/usr/,将hadoop配置分发至hadoopnode1节点计算机。
第三部分:运行及结果
首先使用命令:hadoop namenode -format,格式化namenode,否则会报:Call From ****/**** to ****:9000 failed on connection exception: java.net.ConnectException: 拒绝连接;错误。
然后运行Hadoop启动命令:
start-all.sh
然后通过命令:hadoop dfsadmin -report可以查看节点情况,本示例为2个datanode,因此结果为:

由上图可以看出,有2个活跃的datanode节点。
通过网址查看整体运行情况:
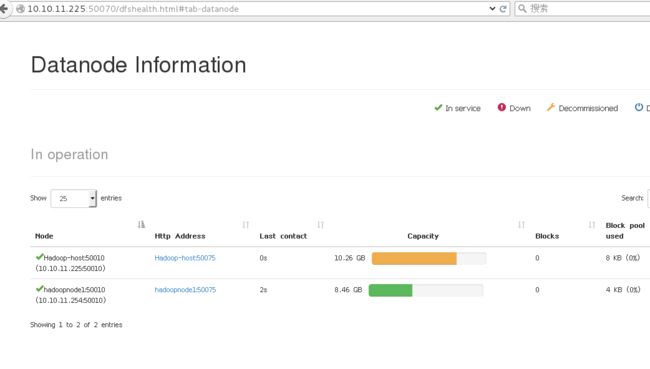
如果出现节点无法连接情况,很可能是防火墙忘记关了。可采用命令:systemctl stop firewalld.service来关闭,还可以通过命令:system disable firewalld.service来禁止防火墙随开机启动。
总结:Hadoop 2.8本身的配置不算复杂,重点在于Centos 7.*系统环境的各种配置。Centos 7的命令较以前的版本发生了变化,网上资料要么都是以前版本的,无法直接应用,要么就是针对7.*版本的资料很少。这时需要认真分析,仔细排查,找出问题,这样才能逐步掌握配置方法。另外,刚开始学习时,由于缺乏积累,出现几次配置失败是很稀松平常的,这时候千万要抵住压力与挫折,在学习过程中一定要保持足够的耐心,不能因为一点点的挫折而放弃学习新环境的机会。拿自己来说,自己经过几次的配置,满以为总算能成功了,没想到在运行时却发现结果不对,当时差点就放弃了,还好最终时刻通过排查防火墙,发现并解决了问题,出现了预期结果。总之,耐心与细心缺一不可。