阿里云注册集群+Prometheus 解决多云容器集群运维痛点
作者:左知
容器集群可观测现状
随着 Kubernetes(K8s)容器编排工具已经成为事实上行业通用技术底座,容器集群监控经历多种方案实践后,Prometheus 最终成为容器集群监控的事实标准。
Promethues 监控服务可有效监控系统层指标、应用层指标、业务层指标等,采集监控指标后进行存储,搭配 Grafana 可实现监控指标的展示和告警等。
Prometheus + Grafana 方案可有效进行容器集群监控指标采集、存储、展示、告警等,有效帮助业务发现和定位问题,为云原生下的应用保驾护航,已经成为业内容器集群监控标准组合方案。
目前企业运维容器集群,有两种方案可以选择,第一种选择自建监控体系;第二种选择云厂商提供的监控产品。
第一种自建监控体系:Prometheus + Grafana 入门使用并不难,但基于此方案进行自建整套监控体系且达到生产可用水平绝非易事,不仅需要投入一定量研发和运维人员,而且需要关注监控体系中各部分的协作,例如指标采集配置、指标存储、指标展示、有效大盘配置、告警配置、无效告警过滤等等诸多事项,这让很多开发和运维人员头痛和头秃,甚至最终走上从入门到放弃之路,赔了夫人又折兵。
第二种使用云厂商提供的监控产品:其中阿里云提供的 Prometheus 监控产品,有包年包月和按量付费两种模式,可减少自行搭建告警体系的前期投入的成本,也提供后续的技术运维支持,可以极大地减少运维成本。
多云容器集群可观测挑战
随着企业云上业务的多样化和复杂化,不可避免地出现跨区跨云厂商容器集群混用的形态,进而从以往单一容器集群运维变成多云容器集群运维。
面对多云混合的容器集群监控,可采用自建 Prometheus + Grafana 监控体系,将面临如下挑战:
-
自建完备的监控体系,需要打通采集、存储、展示、告警等各个部分,且需要后续持续运维 SRE 人员投入,导致运维成本上升
-
开源 Prometheus 对应的 TSDB 采用 SSD 存储模式,数据单点分散存储,存在数据丢失风险
-
开源 Prometheus 采集能力存在一定的瓶颈,且为单点运行无法做到弹性伸缩,业务高峰时可能出现监控数据采集性能瓶颈
亦或采用云厂商提供的 Prometheus 监控产品,将面临如下挑战:
-
跨云厂商,不同云厂商提供的 Prometheus 监控产品能力和使用方式不尽相同,需要一定的学习成本
-
分散管理,不同云厂商监控产品混用情况下,无法进行统一管理,容易造成管理低效和混乱、运维上的重复、无法及时发现业务问题
无论使用上述哪种方案,都会面临一个共同的问题,即监控指标分散,无法做到统一查询、联合分析展示、统一告警等。为实现监控数据统一查询和告警,可采用开源 Prometheus 联邦模式,存在如下诸多问题:
-
容器集群内需部署 Prometheus 进行指标采集,不同容器集群内需进行重复配置
-
通过 Federate 方式将分散的监控数据进行中心化聚合,强依赖网络联通行,占用较多网络带宽资源
-
Federate 模式依赖网络的连通性和稳定性,当网络延迟出现时极易造成查询不到数据,告警不生效等
-
中心 Prometheus 存储单点存在宕机风险,若采用多活模式时,还需要解决数据一致性等问题

亦或采用 Thanos 方案实现数据统一查询,亦将面临如下困难:
-
运维负担重,需要将 Thanos Sidercar 做为单独进程与 Prometheus Server 一起部署和配置,并需提前规划容量,后续运维较繁琐
-
资源浪费,Sidercar 将本地数据同步到云端的对象存储时,依赖网络性能,占用一定的网络带宽资源
-
告警有效性难以保证,大跨度查询历史数据时,需要从云端对象存储中获取,若前期同步数据出现异常,会导致后期查询不到有效数据
-
统一查询数据时,需要进行实时聚合数据,并进行去重、计算等操作
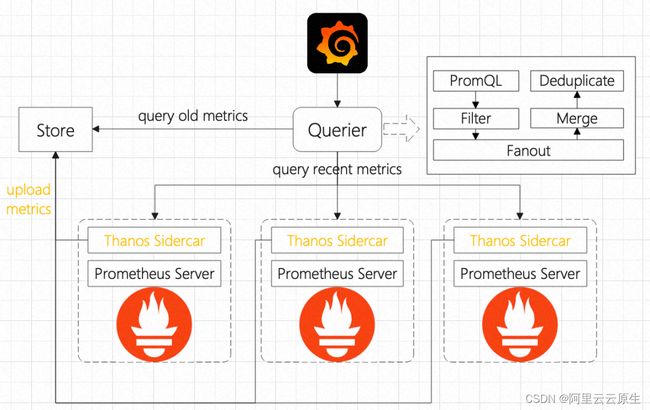
阿里云 Prometheus 监控优势
为了解决上述问题,阿里云注册集群提供纳管能力,即将非阿里云容器集群进行统一管理,可有效解决多云容器集群管理分散的问题。阿里云 Promethues 监控产品,提供包括指标采集、Grafana 展示、告警等整套的容器监控体系,支持按量计费和包年包月两种付费模式,可有效提升容器集群监控效率,极大地减少自建监控体系所面临的运维成本。阿里云注册集群+Promethues 监控产品组合,将多云容器集群监控变得简单且高效,诸多问题迎刃而解。
-
能力较强,可有效解决多云容器集群监控面临的管理分散、监控体系搭建困难、运维效率低下、指标无法联合查询、告警无法统一等诸多问题,将多云分散的容器集群监控进行统一管理、统一配置、统一查询、统一告警等,极大地提升多云容器集群监控的效率,节省 SRE 人员投入的成本,让 SRE 人员减少重复性劳动,更加聚焦于业务。
-
费用低廉,阿里云 Promethues 监控产品提供免费的基础指标采集,可覆盖容器集群的基础监控需求。小规模容器集群可采用按量计费模式,保证业务得到有效监控的同时,最大程度降低监控费用支出。大规模集群,可采用包年包月模式,相比于按量计费,包年包月模式可有效减少约 60%成本,将大规模集群监控成本极大地降低。
-
资源占用较少,阿里云 Prometheus 监控产品,仅在用户集群中轻量化部署 Agent,且具备自动弹性扩容能力,2C4G 资源申请量可采集 600 万指标。开源 Prometheus 的服务发现模块存在对集群内 APIServer 造成较大压力问题,而阿里云 Prometheus 进行了专项优化,有效减轻 APIServer 的压力。最终实现最小资源占用,最大化采集容器集群监控指标,为业务保驾护航。
优势一:性能提升

优势二:多集群 Prometheus 聚合查询
提供多个阿里云 Prometheus 实例或自建 Prometheus 集群的虚拟聚合实例,针对这个虚拟聚合实例可以实现 Prometheus 指标的统一查询,统一 Grafana 数据源和统一告警。
-
解决开源的 Prometheus 数据分散保存,Grafana 中需要配置多个数据源地址,不同的数据源无法高效地整合在一起,难以以整体的视角分析应用在全球各个地域的运行状况
-
用户无需在每个区域自行部署 Prometheus Server,只需要以 remote write 方式将数据上报至阿里云 Prometheus,也无需部署 Thanos 中的大量组件,无其他组件部署的依赖即可使用 GlobalView 的功能
-
全局查询基于分布式的查询,并进行了性能优化,针对大查询可以随时实现水平、纵向扩缩,查询性能、稳定性较好
-
开箱即用式方式,基于阿里云 Prometheus 监控产品,无需任何其他组件额外部署,运维成本极低
如下为跨可用区,聚合两个 Pormetheus 实例:
优势三:轻量化安装
对比开源安装方式,阿里云 Prometheus 监控产品,仅需在用户容器集群内安装轻量化探针,后端存储采用托管模式,可节省业务容器集群资源占用。

优势四:集成 Grafana 服务
阿里云 Grafana 服务是云原生的运维数据可视化平台,提供免运维和快速启动 Grafana 运行环境的能力,具备如下优势:
-
默认集成 Prometheus、SLS 等各类阿里云服务数据源,并支持第三方或自建数据源,快速建立一体化运维可视化看板
-
独享实例与高 SLA 保障,确保监控体系高可用与弹性,让运维监控更可靠,维护成本更低
-
打通阿里云账号 SSO 与自建账号体系,保障数据安全同时,实现数据源与大盘的精细化管理
-
能够解决数据汇总难:各类云服务监控数据难以汇总统一,增加运维难度运维监控困难:各类云服务核心指标监控图表需要重复配置告警管理难:各类云服务的告警规则相互分散,难以统一管理
-
能够提供默认集成:默认集成弹性计算、数据库等阿里云核心云服务统一大盘:建立跨数据源统一看板体系,让可视化运维更精细统一告警:轻松搭建一体化报警体系,提升报警管理效率
优势五:集成告警系统
阿里云 Prometheus 服务默认对接了阿里云上的统一告警系统,统一告警具有以下特点
-
全球化
-
- 告警规则模板全球化,一站式为全球事件配置告警
- 联系人、通知策略全球化,一次配置全球生效
-
集成事件后管理更高效
-
- 告警管理默认支持一键化集成阿里云常见的监控工具,并支持更多的监控工具手动接入,方便统一维护
- 事件接入模块稳定,能提供 7×24 小时的无间断事件处理服务
- 处理海量事件数据时可以保证低延时
-
及时准确地将告警通知给联系人
-
- 配置通知规则,对事件合并后再发送告警通知,减少运维人员出现通知疲劳的情况
- 根据告警的紧急程度选择邮件、短信、电话、钉钉等不同的通知方式,来提醒联系人处理告警
- 通过升级通知对长时间没有处理的告警进行多次提醒,保证告警及时解决
-
帮助您快速便捷地管理告警
-
- 联系人能通过钉钉随时处理告警
- 使用通用告警格式,联系人能更好地分析告警
- 多个联系人通过钉钉协同处理
-
告警事件再加工
-
- 通过事件处理流编排简单的处理流程,对任意告警源上报的告警事件进行再加工,以满足差异化的事件数据处理需求
- 事件管理支持对任意告警源上报的告警事件去重、压缩、降噪、静默,从而收敛告警,减少告警风暴的产生
-
告警配置管理
-
- 提供容器集群常见核心指标监控模版,同时提供告警模版功能可自行生成和下发告警模版,实现快速批量化配置告警
- 提供页面化告警配置引导和预览,可实时查看告警条件匹配事件,并进行精细化配置
-
统计告警数据,实时分析处理情况,改进告警处理效率,分析业务运行情况
多云容器集群接入阿里云 Prometheus 示例
纳管多云容器集群
前提条件
- 登录 RAM 管理控制台和弹性伸缩控制台开通相应的服务。
- 支持通过公网和内网接入
创建阿里云注册集群
- 登录容器服务管理控制台。
- 在控制台左侧导航栏中,单击集群。
- 在集群列表页面中,单击页面右上角的创建集群。
- 在注册集群页签,完成创建集群配置项。

- 完成上述选择后,在页面右侧单击创建集群,待集群创建成功后,可以在集群列表,看到创建的集群类型为注册集群且处于等待接入状态。

将多云集群纳管到阿里云注册集群
如下以腾讯云的 Kubernetes 为例,介绍如何将腾讯云的 Kubernetes 集群通过阿里云的注册集群进行统一纳管,进而使用阿里云Arms Prometheus监控进行指标抓取和展示。
1)在上步创建的注册集群registCluster为例子,右侧单击操作列下的详情

2)在集群信息页面单击连接信息页签,查看公网集群导入方式点击右侧复制

3)在腾讯云集群页面选择目标集群,点击右上角 YAML 创建资源,将上步复制的连接信息填入点击完成进行代理安装
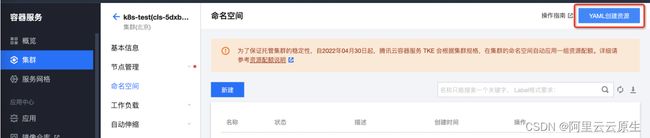

4)腾讯云集群页面查看 Deployment,ack-cluster-agent 处于正常运行状态代表代理安装成功

5)阿里云容器集群管理页面查看上述创建的注册集群处于运行中,代表纳管成功

安装 Prometheus 组件
1)登陆 容器服务管理控制台,运维管理 -> 组件管理 -> ack-arms-prometheus 组件,点击安装 ARMS Prometheus 组件

2)腾讯云容器集群页面,工作负载 -> Deployment -> 选择 arms-prom 命名空间,查看 arms-prometheus-ack-arms-prometheus 处于运行状态代表组件安装成功

3)登陆 应用实时监控服务 ARMS 页面,选择 Prometheus 监控 -> Prometheus 实例列表 -> 选择上述创建的 registCluster 注册集群
左侧服务发现,查看默认配置的 Targets 处于采集状态,代表 ARMS Prometheus 组件正在采集 Metrics 指标数据,点击可查看具体源数据。

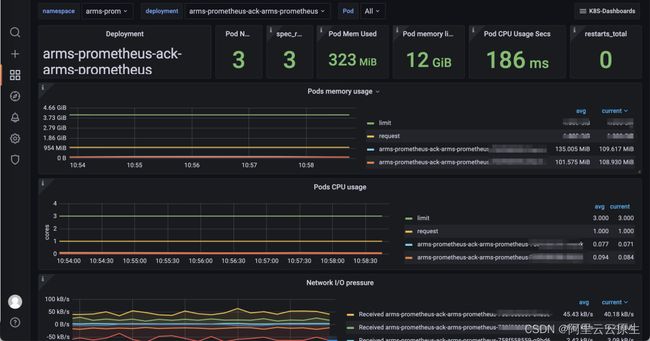
查看监控数据
默认集成常用 Grafana 大盘,包括 Deployment 大盘、Daemonst 大盘等

点击具体大盘可查看具体 Metrics 指标数据,例如点击查看 Deployment 大盘
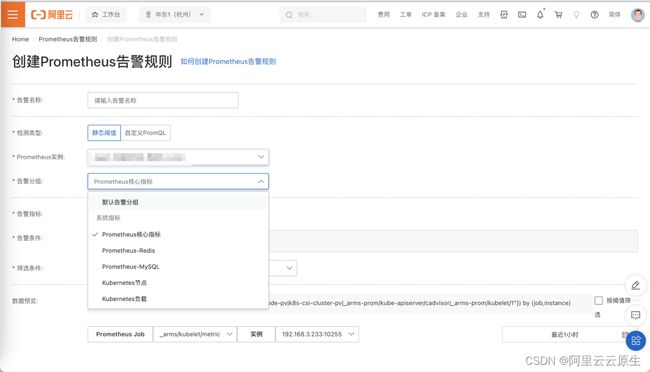
查看 ARMS 告警
默认开启众多容器集群核心指标监控,免去自行开启产生遗漏问题

默认集成众多核心指标告警模版,可根据自行需求进行开启,免去自行编写 PromQL 步骤。
关于阿里云 Prometheus 监控
阿里云 Prometheus 服务是基于云原生可观测事实标准 - Prometheus 开源项目构建的全托管观测服务。默认集成常见云服务,兼容主流开源组件,全面覆盖业务观测/应用层观测/˙中间件观测/系统层观测。通过开箱即用的 Grafana 看板与智能告警功能,并全面优化探针性能与系统可用性,帮助企业快速搭建一站式指标可观测体系。助业务快速发现和定位问题,减轻故障给业务带来的影响,并免去系统搭建与日常维护工作量,有效提升运维观测效率。

与此同时,阿里云 Prometheus 作为阿里云可观测套件的重要组成部分,与 Grafana 服务、链路追踪服务,形成指标存储分析、链路存储分析、异构构数据源集成的可观测数据层,同时通过标准的 PromQL 和 SQL,提供数据大盘展示,告警和数据探索能力。为 IT 成本管理、企业风险治理、智能运维、业务连续性保障等不同场景赋予数据价值,让可观测数据真正做到不止于观测。
联系我们
阿里云注册集群开通方式:
https://help.aliyun.com/document_detail/121053.html
阿里云 Prometheus 监控产品开通方式:
https://help.aliyun.com/product/122122.html
阿里云 Prometheus 全新推出包年包月模式,相比按量付费至少 节省 67%成本,更有首月免费的优惠,点击阅读原文查看。
相关链接
[1] RAM管理控制台
https://ram.console.aliyun.com/
[2] 弹性伸缩控制台
https://essnew.console.aliyun.com/
[3] 接入注册集群的目标集群对于网络连通性有什么要求?
https://help.aliyun.com/document_detail/128419.htm#section-uys-2f5-s9k
[4] 容器服务管理控制台
https://cs.console.aliyun.com/
[5] 应用实时监控服务ARMS页面
https://arms.console.aliyun.com/#/home