用于视觉识别的深度卷积网络中的空间金字塔池化
引言
我们目睹了视觉领域的快速,革命性变化,主要是由深度卷积神经网络 (CNNs) [18] 和大规模训练数据的可用性 [6] 引起的。基于深度网络的方法最近在图像分类 [16、31、24],对象检测 [12、444、24],许多其他识别任务 [22、27、32、13],甚至非识别任务的现有技术上有了很大的改进。
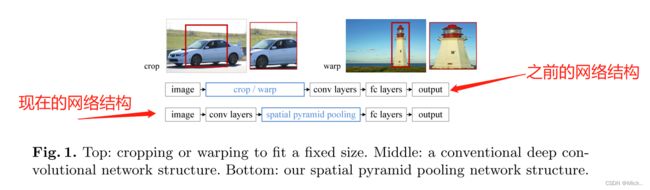
然而,在训练和测试cnn中存在一个技术问题: 普遍的cnn需要固定的输入图像尺寸 (例如,224 × 224),这限制了输入图像的纵横比和比例。当应用于任意大小的图像时,当前的方法大多通过裁剪 将输入图像拟合到固定大小,如图1 (上) 所示。但是裁剪的区域可能不包含整个对象,而扭曲的内容可能会导致不必要的几何失真。由于内容丢失或失真,识别准确性可能会受到损害。此外,当对象尺度变化时,预定义的尺度 (例如,224) 可能不适合。
那么为什么CNNs需要固定的输入大小呢?CNN主要由两部分组成: 卷积层和随后的全连接层。卷积层以滑动窗口方式操作,并输出表示激活的空间布置的特征图 (图2)。实际上,卷积层不需要固定的图像大小,并且可以生成任何大小的特征图。另一方面,全连接的层需要根据其定义具有固定的大小/长度输入。因此,固定大小的约束仅来自全连接的层,这些层存在于网络的更深层次。

在本文中,我们引入了空间金字塔池 (SPP) [14,17] 层,以消除网络的固定大小约束。具体来说,我们在最后一个卷积层的顶部添加一个SPP层。SPP层汇集特征并生成固定长度的输出,然后将其馈送到全连接的层 (或其他分类器) 中。换句话说,我们在网络层次结构的更深层次 (在卷积层和全连接层之间) 执行一些信息 “聚合”,以避免在开始时需要裁剪。图1 (底部) 通过引入SPP层显示了网络架构的变化。我们将新的网络结构称为SPP-net。
我们认为,在更深的阶段进行聚合更加合理,并且与我们大脑中的分层信息处理更加兼容。当一个物体进入我们的视野时,我们的大脑将其视为一个整体,而不是在开始时将其裁剪成几个 “视图”,这是更合理的。同样,我们的大脑不太可能将所有候选对象扭曲成固定大小的区域来检测/定位它们。我们的大脑更有可能通过聚合前一层已经被深度处理的信息来处理更深层次的任意形状的物体。
空间金字塔池 [14,17] (通常称为空间金字塔匹配或SPM [17]),作为单词袋 (BoW) 模型 [25] 的扩展,是计算机视觉中最成功的方法之一。它将图像划分为从更精细到更粗糙的级别,并在其中聚合局部特征。在最近的CNNs流行之前,SPP长期以来一直是关键组成部分,用于分类 (例如 [30,28,21]) 和检测 (例如 [23])。然而,在CNNs的背景下还没有考虑SPP。我们注意到SPP对于深度cnn具有几个显著的特性: 1) SPP能够生成固定长度的输出,而不管输入大小如何,而以前的深度网络 [16] 中使用的滑动窗口池不能; 2) SPP使用多尺度池化,而滑动窗口仅使用单个窗口大小。多级池化已被证明对对象变形具有鲁棒性 [17]; 3) 由于输入标度的灵活性,SPP可以在可变标度下提取的特征。通过实验,我们表明所有这些因素都提高了深度网络的识别精度。
具有空间金字塔池的深度网络
卷积层和特征图
这些由深卷积层生成的特征图类似于传统方法中的特征图 [2,4]。在这些方法中,SIFT矢量 [2] 或图像补丁 [4] 被密集提取,然后编码,例如,通过矢量量化 [25,17,11],稀疏编码 [30,28],或Fisher内核 [21]。这些编码的特征由特征图组成,然后由单词袋 (弓) [25] 或空间金字塔 [14,17] 汇集。类似地,深度卷积特征可以以类似的方式汇集。
空间金字塔池层
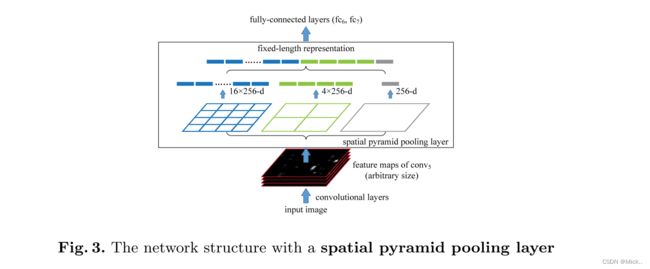
总结:spp_net是为了解决了多尺度的输入问题。
代码
from torch import nn
import torch
class SPP(nn.Module):
def __init__(self):
super(SPP, self).__init__()
self.pool1 = nn.MaxPool2d(kernel_size=5,stride=1,padding=5 // 2)
self.pool2 = nn.MaxPool2d(kernel_size=7, stride=1, padding=7 // 2)
self.pool3 = nn.MaxPool2d(kernel_size=13, stride=1, padding=13 // 2)
def forward(self,x):
x1 = self.pool1(x)
x2 = self.pool2(x)
x3 = self.pool3(x)
return torch.cat([x,x1,x2,x3],dim=1)
x = torch.rand((2,512,13,13))
f = SPP()
print(f(x).shape)import torch
import torch.nn as nn
import torch.nn.functional as F
import math
def spatial_pyramid_pool(previous_conv, num_sample, previous_conv_size, out_pool_size):
"""
previous_conv: a tensor vector of previous convolution layer
num_sample: an int number of image in the batch
previous_conv_size: an int vector [height, width] of the matrix features size of previous convolution layer
out_pool_size: a int vector of expected output size of max pooling layer
returns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling
"""
for i in range(len(out_pool_size)):
h, w = previous_conv_size
h_wid = math.ceil(h / out_pool_size[i])
w_wid = math.ceil(w / out_pool_size[i])
h_str = math.floor(h / out_pool_size[i])
w_str = math.floor(w / out_pool_size[i])
# print('(', h, w, ')')
# print('window:', h_wid, w_wid)
# print('stride:', h_str, w_str)
max_pool = nn.MaxPool2d(kernel_size=(h_wid, w_wid), stride=(h_str, w_str))
x = max_pool(previous_conv)
if i == 0:
spp = x.view(num_sample, -1)
else:
spp = torch.cat((spp, x.view(num_sample, -1)), 1)
return spp
class SPPNet(nn.Module):
"""
A CNN model which adds spp layer so that we can input single-size tensor
"""
def __init__(self, n_classes=102, init_weights=True):
super(SPPNet, self).__init__()
"""
'wc1',[3,96,11,11]
'wc2',[96,256,5,5]
'wc3',[256,384,3,3]
'wc4':[384,384,3,3]
'wc5':[384,256,3,3]
'fc6':[spatial_pool_dim*256,4096]
'fc7':[4096,4096]
'out',[4096,n_classes])
"""
self.output_num = [4, 2, 1]
self.conv1 = nn.Conv2d(3, 96, kernel_size=7, stride=2)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv2 = nn.Conv2d(96, 256, kernel_size=5, stride=2)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv3 = nn.Conv2d(256, 384, kernel_size=3)
self.conv4 = nn.Conv2d(384, 384, kernel_size=3)
self.conv5 = nn.Conv2d(384, 256, kernel_size=3)
self.fc1 = nn.Linear(sum([i * i for i in self.output_num]) * 256, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.out = nn.Linear(4096, n_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# torch.Size([N, C, H, W])
# print(x.size())
x = F.relu(self.conv1(x))
x = F.local_response_norm(x, size=4)
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = F.local_response_norm(x, size=4)
x = self.pool2(x)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
spp = spatial_pyramid_pool(x, x.size(0), [int(x.size(2)), int(x.size(3))], self.output_num)
fc1 = F.relu(self.fc1(spp))
fc2 = F.relu(self.fc2(fc1))
output = self.out(fc2)
return output
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)参考文献:
mmmmmmiracle/SPPNet: PyTorch for classification《 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》 (github.com)
空间金字塔池化改进 SPP / SPPF / SimSPPF / ASPP / RFB / SPPCSPC / SPPFCSPC_迪菲赫尔曼的博客-CSDN博客_空洞空间金字塔池化
SPP、ASPP与PPM_我不是薛定谔的猫的博客-CSDN博客_aspp和ppm