【秋招面经】搬运深信服以及360前端面经
前言
本次主要搬运深信服和360公司面试的常问问题
文章目录
- 前言
-
-
-
- 本次主要搬运深信服和360公司面试的常问问题
-
-
- 问题总结
-
- 块级元素和行内元素有哪些?他们的区别是什么?button元素是行内元素还是块级?input?
- span水平垂直居中,怎么做?
- 浏览器的重排和重绘?
- 同源策略?对跨域的了解?
- webpack跨域的本质?
- JS遍历一个对象常用的方法?
- 说一说vue的nextTick()?
- 对称加密和非对称加密
- xss攻击?
- 拿到dom节点?
- 如何判断节点的类型?
- 如何改变节点中的文本值?
- innerHTML/innerText/textContent三者之间的区别是什么?
- 获取一个节点所有的属性?
- 获取节点的父级节点、子结点?
- 子节点
- 其他的一些节点操作?
- 三种动态创建元素的区别?
- 类数组对象转成数组?
- promise的特点?
- 代码输出?
- promise 怎么捕获异常?
- try-catch 能抛出 promise 的异常吗?
- 为什么try...catch不能够捕获promise异常,但是却能捕获async/await?
- async await有没有什么特点?
- try catch 为什么可以捕获async await 但是不能捕获promise?
- 异步的解决方案?
- 对于前端工程化的理解?
- isNaN 了解过吗,写一个判断数字的方法?
- 说说你对作用域的理解?
- 作用域链?
- 为什么需要设计块级作用域?(块级作用域:var缺陷以及为什么要引入let和const)?
- 对垃圾回收机制的理解?
- 构造一个循环引用?
- 怎么搭建一个vue项目?
- 代码题 是不是跨域?
- https的默认端口?http默认端口?
问题总结
块级元素和行内元素有哪些?他们的区别是什么?button元素是行内元素还是块级?input?
块级元素: 块元素都会在浏览器中独占一行。可设置宽高,如果不设置宽高那么它的宽度是100%(占满父级元素一整行)
块元素包括:div, h1-h6 , p ,ul,li,ol, dl,dt, hr,form,table ,tr,td
行内元素:内容决定所占空间的多少,内容多少就占多少空间。不能设置宽高(默认宽高是0)。margin垂直方向无效(margin-top,margin-bottom),如果设置垂直方向用line-height属性。
行内元素包括: span, a ,br, img,input, strong, textarea
行内块:共享一行,可设置宽高,多个行内元素排列在一起,他们之间会出席空格。可设置margin,padding属性。集合了块和行内的所有优点。
行内块元素包括:img,input
button是行内元素,input是行内元素
span水平垂直居中,怎么做?
第一种:水平居中
<span style="text-align: center;display:block;"> 没有数据显示 </span>
必须加display:block;否则不能居中显示
效果如下:

span中文字垂直居中
如果span 设置了 height,那么直接使用 line-height与设置的height 值相同即可以实现垂直居中.
<span> 你好啊 </span>
span {
/* 水平居中 */
text-align: center;
display: block;
/* 垂直居中 */
height: 40px;
line-height: 40px;
}

思考:那这里我们可不可以设置display:inline-block;
我们可以试一下:
<span> 你好啊 </span>
我们设置样式:
span {
/* 水平居中 */
text-align: center;
display: inline-block;
background-color: pink;
}
最后的结果发现并没有达到水平居中的效果;

再来看一下垂直居中;
span {
/* 水平居中 */
display: inline-block;
/* 垂直居中 */
height: 40px;
line-height: 40px;
background-color: pink;
}

说明变成了行内块元素的话,可以垂直居中,但是不能水平居中。
原因呢?
text-algin只能应用在块元素和行内块元素上,而且得给行内块元素设置宽度才能生效,不能应用在行内元素上。(原因:行内元素没位置给它左对齐,右对齐或居中,这就是为什么需要给行内块元素设置宽度)。块元素默认占整行所以在中间,行内块元素设置一个宽度,所以在这个宽度里面居中。
span {
/* 水平居中 */
width: 400px;
text-align: center;
display: inline-block;
/* 垂直居中 */
height: 40px;
line-height: 40px;
background-color: pink;
}
最后的结果为

第2种:
利用flex布局
<span> 没有数据显示</span>
<style>
span {
display: flex;
justify-content: center;
align-items: center;
}
</style>
第3种,利用绝对定位
<div class="father">
<span class="son"></span>
</div>
.father {
position: absolute;
width: 500px;
height: 500px;
border: 1px solid;
/* display: flex;
justify-content: center;
align-items: center; */
}
.son {
display: block;
position: relative;
top: 50%;
left: 50%;
width: 100px;
height: 100px;
border: 1px solid;
transform: translate(-50%, -50%)
}
浏览器的重排和重绘?
浏览器的回流与重绘 (Reflow & Repaint)
同源策略?对跨域的了解?
跨域问题
webpack跨域的本质?
webpack通过 proxy 解决跨域,是基于 webpack-dev-server,devServer 中是关于 proxy 代理的配置。它提供给我们target属性就可以把它转到我们的目标服务器下。
webpack之所以能做到跨域是本地写项目是写到localhost里,那webpack就会在本地起一个本地服务器,也就是这个服务器和我们前端这个localhost:8080是符合同源策略的,也就是发请求发到了中间层的代理服务器上面,然后这个webpack提供的中间层服务器和我们的后端服务器是不存在跨域的,然后由这个代理服务器去请求后端服务器,后端服务器把请求的数据返回给webpack,然后webpack返回给我们前端来渲染。
const devServer = {
proxy: {
'/poi': {
target: 'https://yapi.sankuai.com/mock/2072',
changeOrigin: true,
},
},
}
target: 表示代理到的目标地址
pathRewrite:默认情况下 poi 会被写到目标地址去,如果要删除,在这里设置
changeOrigin:更新代理后 http header 中 host 地址
原理: proxy 本质上利用了 http-proxy-middleware http 代理中间件,实现将请求转发给其他服务器。通过 proxy 实现代理请求后,会在浏览器与服务器之间添加一个代理服务器,本地发送请求时,中间代理服务器接收后转发给目标服务器,目标服务器返回数据,中间代理服务器将数据返回给浏览器。中间代理服务器与目标服务器之间不存在跨域资源问题。
JS遍历一个对象常用的方法?
方式一:for…in.
const obj = { name: 'zhangsan', age: 13 };
for (const i in obj) {
console.log(i, ':', obj[i]);
}
// name : zhangsan
// age : 13
方式二:Object.keys
用于获取对象自身所有的可枚举的属性值,但不包括原型中的属性,然后返回一个由属性名组成的数组。
Object.prototype.fun = () => {};
const str = 'helloworld';
console.log(Object.keys(str));
// ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
const arr = ['a', 'b', 'c'];
console.log(Object.keys(arr));
// ["0", "1", "2"]
const obj = { name: 'zhangsan', age: 13 };
console.log(Object.keys(obj));
// ["name", "age"]
方式三:Object.values
用于获取对象自身所有的可枚举的属性值,但不包括原型中的属性,然后返回一个由属性值组成的数组。
Object.prototype.fun = () => {};
const str = 'helloworld';
console.log(Object.values(str));
// ["h", "e", "l", "l", "o", "w", "o", "r", "l", "d"]
const arr = ['a', 'b', 'c'];
console.log(Object.values(arr));
// ["a", "b", "c"]
const obj = { name: 'zhangsan', age: 13 };
console.log(Object.values(obj));
// ["zhangsan", 13]
方式四:Object.entries
用于获取对象自身所有的可枚举的属性值,但不包括原型中的属性,然后返回二维数组。每一个子数组由对象的属性名、属性值组成。
是一种可以同时拿到属性名与属性值的方法。
const str = 'hello';
for (const [key, value] of Object.entries(str)) {
console.log(`${key}: ${value}`);
}
// 0: h
// 1: e
// 2: l
// 3: l
// 4: o
const arr = ['a', 'b', 'c'];
for (const [key, value] of Object.entries(arr)) {
console.log(`${key}: ${value}`);
}
// 0: a
// 1: b
// 2: c
const obj = { name: 'zhangsan', age: 13 };
for (const [key, value] of Object.entries(obj)) {
console.log(`${key}: ${value}`);
}
// name: zhangsan
// age: 13
方式五:Object.getOwnPropertyNames
方式六:Object.getOwnPropertySymbols()
方式七:Reflect.ownKeys()
说一说vue的nextTick()?
说说nextTick的使用和原理?
nextTick()内部传入的是一个函数,本质是将我们传入的函数包装成异步任务
对称加密和非对称加密
对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密。
加密过程如下:明文 + 加密算法 + 私钥 => 密文
解密过程如下:密文 + 解密算法 + 私钥 => 明文

对称加密中用到的密钥叫做私钥,私钥表示个人私有的密钥,即该密钥不能被泄露。 其加密过程中的私钥与解密过程中用到的私钥是同一个密钥,这也是称加密之所以称之为“对称”的原因。由于对称加密的算法是公开的,所以一旦私钥被泄露,那么密文就很容易被破解,所以对称加密的缺点是密钥安全管理困难。
优点:简单、速度快
缺点:相对于非对称加密来说不是很安全
非对称加密
非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。
优点:更安全
缺点:复杂、速度快
被公钥加密过的密文只能被私钥解密,过程如下:
明文 + 加密算法 + 公钥 => 密文, 密文 + 解密算法 + 私钥 => 明文
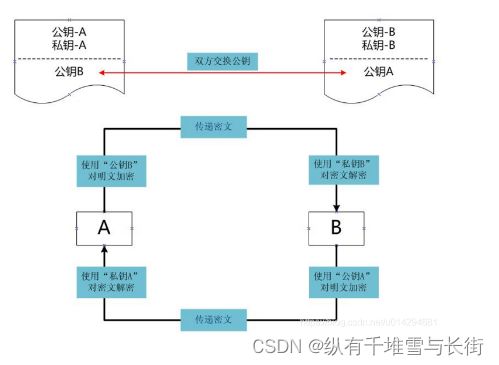
(1) A 要向 B 发送信息,A 和 B 都要产生一对用于加密和解密的公钥和私钥。
(2) A 的私钥保密,A 的公钥告诉 B;B 的私钥保密,B 的公钥告诉 A。
(3) A 要给 B 发送信息时,A 用 B 的公钥加密信息,因为 A 知道 B 的公钥。
(4) A 将这个消息发给 B (已经用 B 的公钥加密消息)。
(5) B 收到这个消息后,B 用自己的私钥解密 A 的消息。其他所有收到这个报文的人都无法解密,因为只有 B 才有 B 的私钥。
例子:
甲对乙说,我这里有A型号锁,对应钥匙A,我给你一大箱子A锁,但是钥匙A不给你,以后你给我发消息就用A锁锁在盒子里给我,然后我自己用钥匙A就能打开看。
乙对甲说,我这里有B型号锁,对应钥匙B,我给你一大箱子B锁,但是钥匙B不给你,以后你给我发消息就用B锁锁在盒子里给我,然后我自己用钥匙B就能打开看。
这样就一定安全了吗?
上述流程会有一个问题:Client端如何保证接受到的公钥就是目标Server端的?如果一个攻击者中途拦截Client的登录请求,向其发送自己的公钥,Client端用攻击者的公钥进行数据加密。攻击者接收到加密信息后再用自己的私钥进行解密,不就窃取了Client的登录信息了吗?这就是所谓的中间人攻击
SSH就可以解决这个问题。
SSH公钥原理(密钥,秘钥,私钥)
xss攻击?
xss攻击指的是跨站脚本攻击,是一种代码注入攻击。恶意攻击者往web页面中插入恶意代码,当用户浏览该页面的时候,嵌入其中的html代码会被执行,从而达到恶意攻击的目的,这就是xss攻击。
一般有三种攻击类型:存储型、反射型、DOM型。
其中反射型、DOM型的xss攻击不太严重,因为它没有动到数据,没有动到根。但是存储型xss攻击就很严重了,它篡改了数据,破坏了数据的结构。
xss是如何攻击的呢?我们以反射型的为例,
 如何解决?
如何解决?
- 过滤掉所有的非法字符,这个特别指的是用户的输入。
- 可以采用html转义(具有局限性)不可能所有的代码都转义
- 对于直接跳转,要进行内容检测
- 限制输入长度(嵌入代码的话可能就比较多)
- 数据加密
拿到dom节点?
< div id="app"></ div>
获取dom节点的五种方式:
- document.getElementById(“标签的id名”) 返回获取到的标签节点对象
- document.getElementsByTagName(“标签名”) 根据标签的名字获取多个 节点对象返回伪数组(伪数组 不能直接进行dom操作 必须取出其中元素才可以操作) 如如获取小li标签
- document.getElementsByClassName(“标签的class名字”);返回伪数组对象
- Html5 推出的document.querySelector(“选择器”) var firstBox = document.querySelector(‘.app’);
- Html5推出的document.querySelectorAll(“选择器”);
如何判断节点的类型?
- Node对象中的nodeName获取指定节点的节点名称
- Node对象中的nodeType获取指定节点的节点类型
- nodeType 属性返回以数字值返回指定节点的节点类型
- 如果节点是元素节点,则 nodeType 属性将返回 1
- 如果节点是属性节点,则 nodeType 属性将返回 2
- 如果节点是文本节点,则 nodeType 属性将返回 3
- nodeType 属性返回以数字值返回指定节点的节点类型
- Node对象中的nodeValue获取指定节点的值
在DOM树结构中,文本节点是元素节点的子节点,所以要先获取元素节点才能获取文本节点。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>判断节点类型</title>
</head>
<body>
<button id="btn" class="cls">按钮</button>
<script>
// 1. 元素节点
var btnElement = document.getElementById('btn');
// 元素节点的nodeName属性值为标签名称(大写)
console.log(btnElement.nodeName); // BUTTON
console.log(btnElement.nodeType); // 1
console.log(btnElement.nodeValue); // null
// 2. 文本节点
var textNode = btnElement.firstChild;
// 文本节点的nodeName属性值是固定值(#text)
console.log(textNode.nodeName); // #text
console.log(textNode.nodeType); // 3
// 文本节点的nodeValue属性值是文本内容
console.log(textNode.nodeValue); // 按钮
// 重新设置元素节点中的文本
textNode.nodeValue = "新按钮";
// 3. 属性节点
var attrNode = btnElement.getAttributeNode('class');
// 属性节点的nodeName属性值为当前元素的属性名称
console.log(attrNode.nodeName); // class
console.log(attrNode.nodeType); // 2
// 属性节点的nodeValue属性值为当前元素的属性名称对应的值
console.log(attrNode.nodeValue); // cls
</script>
</body>
</html>
如何改变节点中的文本值?
- innerHTML
<div id="app">我是一个div</div>
<script>
let app = document.getElementById('app')
app.innerHTML = '我是改变的值'
</script>
- innerText
<div id="app">我是一个div</div>
<script>
let app = document.getElementById('app')
app.innerText = '我是改变的值'
</script>
- textContent
<div id="app">我是一个div</div>
<script>
let app = document.getElementById('app')
app.textContent = '我是改变的值'
</script>
innerHTML/innerText/textContent三者之间的区别是什么?
innerHTML识别html标签,保留空格和换行
innerText 不识别html标签,去除空格和换行
innerText会触发回流,但是textContent可能不会触发回流,所以实际应用中,使用textContent性能更佳
innerTTML会返回HTML文本,textContent的内容不会解析成HTML文本,使用textContent可以防止XSS攻击
获取一个节点所有的属性?
1. 对象.属性名
2. 对象[属性名]
3. obj.getAttribute(pro)
<img src="images/1.jpg" alt="" id="pic" class="one">
<script type="text/javascript">
var txt=document.getElementById('pic');
console.log(txt.src);
console.log(txt['src']);
console.log(txt.getAttribute('src'));//三个输出值是一样的
</script>
节点属性的设置有三种方法
1. 对象.属性名=值;
2. 对象[属性名]=值;
3. obj.setAttribute(pro,value)
<script>
let app = document.getElementById('app')
console.log(app.attributes)
</script>
<img src="images/1.jpg" alt="" id="pic" class="one">
<script type="text/javascript">
var txt=document.getElementById('pic');
txt.className='two';
txt[className]='two';
txt.setAttribute('class','two');//三种写法的效果一样
</script>
获取节点的父级节点、子结点?
父级节点:
- parentNode属性可以返回某节点的父结点,注意是最近的一个父结点
- 如果指定的节点没有父结点则返回null
<div class="demo">
<div class="box">
<span class="erweima">×</span>
</div>
</div>
<script>
// 1. 父节点 parentNode
var erweima = document.querySelector('.erweima');
// 得到的是离元素最近的父级节点(亲爸爸) 如果找不到父节点就返回为 null
console.log(erweima.parentNode);
</script>
最后的结果

子节点
- parentNode.childNodes 返回包含指定节点的子节点的集合,该集合为即时更新的集合
- 返回值包含了所有的子结点,包括元素节点,文本节点等
- 如果只想要获得里面的元素节点,则需要专门处理。所以我们一般不提倡使用childNodes
parentNode.children(非标准)
- parentNode.children 是一个只读属性,返回所有的子元素节点
- 它只返回子元素节点,其余节点不返回 (这个是我们重点掌握的)
- 虽然 children 是一个非标准,但是得到了各个浏览器的支持,因此我们可以放心使用
<div id="app">
<p>这是一个p标签</p>
<p>这是二个p标签</p>
</div>
<script>
let app = document.getElementById('app')
console.log(app.childNodes)
console.log(app.children);
</script>

思考: 元素和节点的区别是什么?
元素一定是节点,节点不一定是元素
节点包括:整个文档是一个文档节点、每个 HTML 元素是元素节点、HTML 元素内的文本是文本节点、每个 HTML 属性是属性节点、注释是注释节点
其他的一些节点操作?
第一个子结点
parentNode.firstChild
最后一个子结点
parentNode.lastChild
<body>
<ol>
<li>我是li1</li>
<li>我是li2</li>
<li>我是li3</li>
<li>我是li4</li>
<li>我是li5</li>
</ol>
<script>
var ol = document.querySelector('ol');
// 1. firstChild 第一个子节点 不管是文本节点还是元素节点
console.log(ol.firstChild);
console.log(ol.lastChild);
// 2. firstElementChild 返回第一个子元素节点 ie9才支持
// 2. lastElementChild 返回最后一个子元素节点 ie9才支持
console.log(ol.firstElementChild);
console.log(ol.lastElementChild);
// 3. 实际开发的写法 既没有兼容性问题又返回第一个子元素
console.log(ol.children[0]); //第一个子元素节点
console.log(ol.children[ol.children.length - 1]);//最后一个子元素节点
</script>
</body>

下一个兄弟节点
node.nextSibling
上一个兄弟节点
node.previousSibling
下一个兄弟节点(兼容性)
node.nextElementSibling
上一个兄弟节点(兼容性)
node.previousElementSibling
<body>
<div>我是div</div>
<span>我是span</span>
<script>
var div = document.querySelector('div');
// 1.nextSibling 下一个兄弟节点 包含元素节点或者 文本节点等等
console.log(div.nextSibling); // #text
console.log(div.previousSibling); // #text
// 2. nextElementSibling 得到下一个兄弟元素节点
console.log(div.nextElementSibling); //我是span
console.log(div.previousElementSibling);//null
</script>
</body>
如何解决兼容性问题?
答:自己封装一个兼容性的函数
function getNextElementSibling(element) {
var el = element;
while(el = el.nextSibling) {
if(el.nodeType === 1){
return el;
}
}
return null;
}
创建节点
document.createElement('tagName');
- document.createElement() 方法创建由 tagName 指定的HTML 元素
- 因为这些元素原先不存在,是根据我们的需求动态生成的,所以我们也称为动态创建元素节点
添加节点
node.appendChild(child)
node.appendChild() 方法将一个节点添加到指定父节点的子节点列表末尾。类似于 CSS 里面的 after 伪元素。
node.insertBefore(child,指定元素)
node.insertBefore() 方法将一个节点添加到父节点的指定子节点前面。类似于 CSS 里面的 before 伪元素。
<body>
<ul>
<li>123</li>
</ul>
<script>
// 1. 创建节点元素节点
var li = document.createElement('li');
// 2. 添加节点 node.appendChild(child) node 父级 child 是子级 后面追加元素 类似于数组中的push
// 先获取父亲ul
var ul = document.querySelector('ul');
ul.appendChild(li);
// 3. 添加节点 node.insertBefore(child, 指定元素);
var lili = document.createElement('li');
ul.insertBefore(lili, ul.children[0]);
// 4. 我们想要页面添加一个新的元素分两步: 1. 创建元素 2. 添加元素
</script>
</body>
删除节点
node.removeChild(child)
node.removeChild()方法从 DOM 中删除一个子节点,返回删除的节点
复制节点(克隆节点)
node.cloneNode()
- node.cloneNode()方法返回调用该方法的节点的一个副本。 也称为克隆节点/拷贝节点
- 如果括号参数为空或者为 false ,则是浅拷贝,即只克隆复制节点本身,不克隆里面的子节点
- 如果括号参数为 true ,则是深度拷贝,会复制节点本身以及里面所有的子节点
<body>
<ul>
<li>1111</li>
<li>2</li>
<li>3</li>
</ul>
<script>
var ul = document.querySelector('ul');
// 1. node.cloneNode(); 括号为空或者里面是false 浅拷贝 只复制标签不复制里面的内容
// 2. node.cloneNode(true); 括号为true 深拷贝 复制标签复制里面的内容
var lili = ul.children[0].cloneNode(true);
ul.appendChild(lili);
</script>
</body>
三种动态创建元素的区别?
- doucument.write()
- element.innerHTML
- document.createElement()
区别:
- document.write() 是直接将内容写入页面的内容流,但是文档流执行完毕,则它会导致页面全部重绘
- innerHTML 是将内容写入某个 DOM 节点,不会导致页面全部重绘
- innerHTML 创建多个元素效率更高(不要拼接字符串,采取数组形式拼接),结构稍微复杂
<body>
<div class="innner"></div>
<div class="create"></div>
<script>
// 2. innerHTML 创建元素
var inner = document.querySelector('.inner');
// 2.1 innerHTML 用拼接字符串方法
for (var i = 0; i <= 100; i++) {
inner.innerHTML += '百度';
}
// 2.2 innerHTML 用数组形式拼接
var arr = [];
for (var i = 0; i <= 100; i++) {
arr.push('百度');
}
inner.innerHTML = arr.join('');
// 3.document.createElement() 创建元素
var create = document.querySelector('.create');
var a = document.createElement('a');
create.appendChild(a);
</script>
</body>
createElement()创建多个元素效率稍低一点点,但是结构更清晰
总结:不同浏览器下, innerHTML 效率要比 createElement 高
类数组对象转成数组?
第一种方法:使用for in 将类数组对象转换为数组
<script type="text/javascript">
var obj = {
0: 'a',
1: 'b',
2: 'c',
};
console.log(obj[0]);
console.log(typeof obj);
var arr = [];
for(var i in obj){
console.log(arr.push(obj[i]));
}
console.log(arr);
//把类数组对象放在一个名为arr的新数组里使得obj变成了数组
console.log(arr instanceof Array);//判断arr是否为数组
</script>
第二种方法:内置对象keys和valus
let obj = {
'1': 5,
'2': 8,
'3': 4,
'4': 6
};
//内置对象Object.keys:获取键
var arr = Object.keys(obj)
console.log(arr);
//内置对象Object.values获取值
var arr2 = Object.values(obj)
console.log(arr2);
第三种方法:Array.from()
let obj = {
'0': 5,
'1': 8,
'2': 4,
'3': 6,
'length':4
};
let arr = Array.from(obj)
console.log(arr);
Array.from()把对象转化为数组必须符合2个条件
1:键必须是数值
2:必须带有length的键值对
数组之类数组对象转成数组
promise的特点?
- (1)Promise对象的状态不受外界影响
Promise 有以上三种状态,只有异步操作的结果可以决定当前是哪一种状态,其他任何操作都无法改变这个状态 - (2)Promise的状态一旦改变,就不会再变
Promise的状态一旦改变,就不会再变,任何时候都可以得到这个结果,状态不可以逆,只能由 pending变成fulfilled或者由pending变成rejected
promise解决异步操作的优点:
- 链式操作减低了编码难度
- 代码可读性明显增强
Promise
例题:
let p = new Promise((resolve, reject) => {
console.log(3)
resolve(2)
resolve(1)
}).then(console.log)
输出 3 2, 因为resovle(2) 已经改变状态了,之后不会在执行了
let p = new Promise((resolve, reject) => {
console.log(3)
resolve(2)
console.log(4)
}).then(console.log)
输出 3 4 2 ,先执行同步任务,然后完成resolve的操作
注意❗❗:因为then里面只能执行函数,而console.log 是函数,到了这里,我产生了疑惑,我没有给 log 方法传递参数,它是怎么打印出结果呢?
原来,Promise库本身会给它带参调用,等价于:
这里的then(console.log)
等同于then((res)=>{
console.log(res);
})
代码输出?
new Promise((resolve) => {
console.log(1);
setTimeout(() => {
console.log(2);
}, 1000);
resolve()
}).then(() => {
console.log(3);
}).then(() => {
return new Promise(() => {
console.log(4);
}).then(() => {
console.log(5);
})
}).then(() => {
console.log(6);
})
console.log(7);
//1,7,3,4,2
promise 怎么捕获异常?
捕获错误方式
- rejected
- catch
- 全局捕获示例:unhandledrejection
window.addEventListener('unhandledrejection', function(event) {
// the event object has two special properties:
alert(event.promise); // [object Promise] - the promise that generated the error
alert(event.reason); // Error: Whoops! - the unhandled error object
});
new Promise(function() {
throw new Error("Whoops!");
}); // no catch to handle the error
rejected和catch捕获错误区别
1.网络异常(比如断网),会直接进入catch而不会进入then的第二个回调
2.reject 是 Promise 的方法,而 catch 是 Promise 实例的方法
3.onRejected 从不处理来自同一个.then(onFulfilled)回调的被拒绝的 promise,并且.catch两者都接受。
try-catch 能抛出 promise 的异常吗?
答案是不可以。
console.log(5)
try {
new Promise((_, reject) => {
console.log(3)
reject('err msg')
}).catch(err => {
console.log(2)
throw err
console.log(4)
})
} catch (err) {
console.log(8)
console.log(err)
} finally {
console.log(9)
}
console.log(10)
结束是输出5,3,9,10,2
原因是:promise抛出的异常不会被try catch 捕获
(我们先打印出来5,然后进入try…catch…,进入promise里面,打印输出3,此时遇到了catch,它是一个微任务,此时进入异步队列中先不执行。然后又因为promise抛出的异常不会被try catch 捕获,所以外面的catch不执行,然后进入finally中,打印输出9,10,然后再打印异步任务的2)
为什么try…catch不能够捕获promise异常,但是却能捕获async/await?
try-catch 主要用于捕获异常,注意,这里的异常,是指同步函数的异常,如果 try 里面的异步方法出现了异常,此时catch 是无法捕获到异常的。
原因:当异步函数抛出异常时,对于宏任务而言,执行函数时已经将该函数推入栈,此时并不在 try-catch 所在的栈,所以 try-catch 并不能捕获到错误。对于微任务而言,比如 promise,promise 的构造函数的异常只能被自带的 reject 也就是.catch 函数捕获到。
async await有没有什么特点?
- 特点:
一个函数如果加上async 那么其返回值是Promise,async 就是将函数返回值使用 Promise.resolve() 进行包裹,和then处理返回值一样
await只能配合async使用 不能单独使用 - 优点:
相比于Promise来说优势在于能够写出更加清晰的调用链,并且也能优雅的解决回调地狱的问题 - 缺点:
因为await将异步代码变成了同步代码,如果多个异步之间没有关系,会导致性能降低 - 原理:
await 就是 generator 加上 Promise 的语法糖,且内部实现了自动执行 generator
async function test() {
return 1
}
console.log(test());

try catch 为什么可以捕获async await 但是不能捕获promise?
try catch 执行在同步任务,但是promise的catch是微任务,try catch已经执行完成,才去执行微任务,try catch 执行在微任务之前,所以微任务抛错误try catch 一定捕获不到
异步的解决方案?
异步解决方案有哪些
对于前端工程化的理解?
模块化、组件化、规范化、自动化四个方面思考
简单来说,模块化就是将一个大文件拆分成相互依赖的小文件,再进行统一的拼装和加载。
从ui拆分下来的每个包含模板(html)+样式(css)+逻辑(js)功能完备的结构单元,我们称之为组件。
前端工程化的很多脏活累活都应该交给自动化工具来完成。
规范化:比如编码规范,目录结构的制订,组件管理等
isNaN 了解过吗,写一个判断数字的方法?
需要注意的是,isNaN() 函数其实并不能像它的描述中所写的那样,数字值返回 false,其他返回 true。
实际上,它是判断一个值能否被 Number() 合法地转化成数字。
这中间有什么区别呢,主要提现在一些特别的情况如下:
1、数字形式的字符串。例如 “123”、“-3.14”,虽然是字符串型,但被 isNaN() 判为数,返回 false。(“12,345,678”,“1.2.3” 这些返回 true)
2、空值。null、空字符串"“、空数组[],都可被Number()合法的转为0,于是被isNaN认为是数,返回false。(undefined、空对象{}、空函数等无法转数字,返回true)
3、布尔值。Number(true)=1,Number(false)=0,所以isNaN对布尔值也返回false。
4、长度为 1 的数组。结果取决于其中元素,即:isNaN([a])=isNaN(a),可递归。例如isNaN([[“1.5”]])=false。
5、数字特殊形式。例如"0xabc”、“2.5e+7”,这样的十六进制和科学计数法,即使是字符串也能转数字,所以也返回false。
总之,很多时候不能用单纯用 isNaN() 取判断。
比如一个空值或者数组,甚至是包含字母和符号的字符串,它都有可能告诉你这是数值。还是要结合具体情况使用。
可以先判断类型再用isNaN
function myIsNaN(value) {
return typeof value === 'number' && !isNaN(value);
}
利用typeof的返回值
验证方法:如果返回的值为Number,则为数字;如果返回值为String或其它,则不是数字。如下所示:
var a=123;
var b='123abc';
typeof(a) //Number
typeof(b) //String
说说你对作用域的理解?
浅显的理解: 作用域就是变量的可用范围(scope)
为什么要有作用域: 目的是防止不同范围的变量之间互相干扰。
我们一般将作用域分成:
- 全局作用域
任何不在函数中或是大括号中声明的变量,都是在全局作用域下,全局作用域下声明的变量可以在程序的任意位置访问 - 函数作用域
任何不在函数中或是大括号中声明的变量,都是在全局作用域下,全局作用域下声明的变量可以在程序的任意位置访问 - 块级作用域
ES6引入了let和const关键字,和var关键字不同,在大括号中使用let和const声明的变量存在于块级作用域中。在大括号之外不能访问这些变量
作用域链?
当使用一个变量的时候,Javascript引擎会循着作用域链一层一层往上找该变量,直到找到该变量为止。
var sex = '男';
function person() {
var name = '张三';
function student() {
var age = 18;
console.log(name); // 张三
console.log(sex); // 男
}
student();
console.log(age); // Uncaught ReferenceError: age is not defined
}
person();
为什么需要设计块级作用域?(块级作用域:var缺陷以及为什么要引入let和const)?
- 变量提升所带来的问题
- 变量容易在不被察觉的情况下被覆盖掉
var myname = "极客时间"
function showName(){
console.log(myname);
if(0){
var myname = "极客邦"
}
console.log(myname);
}
showName()
- 本应销毁的变量没有被销毁
function foo(){
for (var i = 0; i < 7; i++) {
}
console.log(i);
}
foo()
JavaScript代码中,i的值并未被销毁,所以最后打印出来的是7
总结:由于JavaScript的变量提升存在着变量覆盖、变量污染等设计缺陷,所以ES6引入了块级作用域关键字来解决这些问题。
对垃圾回收机制的理解?
不再使用的内存,如果没有及时清除,就会造成内存泄漏,所以就有了垃圾回收机制,也叫 gc 机制。垃圾回收期会定期或在适当的时间找到那些不再继续使用的变量,然后释放对应的内存空间。
js 中的垃圾回收机制主要有引用计数和标记清除两种。他们各有优劣,常用的方法是标记清除。还有一种方法叫做标记整理,是标记清除的改进版。
构造一个循环引用?
let obj1 = {}
let obj2 = {}
obj1.a = obj2
obj2.b = obj1
console.log(obj1)
怎么搭建一个vue项目?
如何搭建一个vue项目(完整步骤)
代码题 是不是跨域?
当然是,域名不一样
http:text1.360.com
http:text2.360.com
https的默认端口?http默认端口?
https的默认端口443 http默认端口 80
思考: 80 和8080 的区别?
80 浏览器HTTP访问IP或域名的80端口时,可以省略80端口号,即访问http://baidu.com:80跟访问http://baidu.com一样的,浏览器自动处理
8080 端口是被用于WWW代理服务的,可以实现网页浏览,经常在访问某个网站或使用代理服务器的时候,会加上":8080"端口号。