常见的前端面经试题整理。持续更新中....
文章目录
- 阿里巴巴试题
-
- 1.元素居中的方式
- 2. XSS和CSRF(react天然对xss有防范)
-
- CSRF
- XSS
- 3.前端项目工程化
- 4.深克隆、浅克隆
-
- 浅克隆:
- 深克隆
-
- 采用json.parse()和json.stringify()实现深克隆
- 使用ES6的Array.from(arr)实现数组深克隆
- 使用ES6的扩展运算符...
- 暴力循环进行赋值
- 5.对微前端,微服务,大前端的理解。
-
- 微前端
-
- 什么是微前端?
- **Single-SPA**
- **qiankun**
- 大前端
- 6.正则表达式
- 7.设计模式
-
- 一. 创建型模式
-
- a. 构造器模式
- b.原型模式
- c.建造者模式
- d.单例模式
- e.工厂模式
- 二. 行为型模式
-
- 观察者模式
- 发布订阅模式
- 三. 结构型模式
-
- 代理模式
- 装饰模式
- 8.vue双向绑定。要求手撕简单版。(简易版demo,以后面试就手撕这个demo)
- 9.webpack 的工作流程?
-
- webpack概述
- webpack使用流程
- webpack配置打包的入口和出口
- 配置webpack自动打包功能
- 配置自动打包工具后的页面预览功能
- 配置自动打包相关的参数
- 使用loader打包非js文件
- 打包处理js文件中的高级语法比如ES6的class类(webpack低版本)
- 第一题:谈谈你对webpack的理解?
- 第二题:说说webpack与grunt、gulp的不同?
- 第三题:什么是bundle,什么是chunk,什么是module?
- 第四题:什么是Loader?什么是Plugin?
- 10.做项目的时候遇见的难点,如何解决的?从现在的角度来看,有没有更好的方法去实现?
- 11. 讲讲react和vue的不同
- 12.js垃圾回收
-
- 标记清理(常用):
- 引用计数(不常用):
- 13.vuex重点
-
- 一. state:
- 二. getters
- 三. mutations
- 四. actions
- 五. modules
- 六. mapState和mapSetters()辅助函数mapMutations()和mapActions()辅助函数
- 七. vuex的store中所有属性也可以支持拆分写法
- 14. typeScript了解
- 15.vue生命周期
-
- vue生命周期的整体流程:
- created和mounted声明周期的区别:
- 16. 你打算未来学什么
- 17. vue的两种路由模式
-
- hash模式
- history模式
- 18.手撕常见的排序算法
-
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序(时间复杂度较低到的一种排序算法)
- 19.vue的组件通信方式
-
- 父子组件通信方式一:通过props和$emit()通信
- 父子组件通信方式二:通过eventBus(事件总线,也就是一个vue实例)来通信
- 通信方式三:Vuex
- 20. 关于阿里的一些前端技术
- 21. 用js简单实现一个vue
- 22. CommonJs规范和ES6模块的区别
- 23. CommonJS、AMD、CMD、UMD、ES6模块
- 24. vue2和vue3的区别
- 25. 手写vue2时的注意点
- 26.什么是MVVM
- 27.谈一下对于vue指令的理解, 如何封装一个指令
-
- 内置指令的使用
- 封装指令
- 28. computed计算属性和watch监听的区别
-
- computed属性
- watch属性
- 29.vnode是什么,是如何渲染的
-
- VNode的作用
- Vnode优点:
- VNode如何生成
- Vnode存放哪些信息
- VNode存放
- 30.谈一下keep-alive缓存组件的实现原理
- 31.如何在在vue项目中应用权限
- 32.在vue项目中去做导航守卫
- 33.说一下闭包
- 34.grid布局
- 35.做一个的与vue-cli相仿的脚手架项目
- 36.网站项目部署
-
- (1)前言
- (2)服务器安装Nginx
- (3)启动nginx
- (4)修改nginx配置
- (5)新建网站文件夹
- (6)打包部署vue项目
-
- (1)打包网站
- (2)上传至服务器
- (7)解决刷新路由404问题
阿里巴巴试题
1.元素居中的方式
法一:
display:flex;
justify-content:center
法二:
margin:0 auto;
法三:
positon: absolute;
left:50%;
transform:translateX(-50%);
2. XSS和CSRF(react天然对xss有防范)
CSRF
((Cross-site request forgery):跨域请求伪造。)

XSS
(XSS(Cross Site Scripting):跨域脚本攻击)
XSS的攻击原理
XSS攻击的核心原理是:不需要你做任何的登录认证,它会通过合法的操作(比如在url中输入、在评论框中输入),向你的页面注入脚本(可能是js、hmtl代码块等)。
最后导致的结果可能是:
盗用Cookie破坏页面的正常结构,插入广告等恶意内容D-doss攻击
区别一:
CSRF:需要用户先登录网站A,获取 cookie。XSS:不需要登录。
区别二:(原理的区别)
CSRF:是利用网站A本身的漏洞,去请求网站A的api。XSS:是向网站 A 注入 JS代码,然后执行 JS 里的代码,篡改网站A的内容。
3.前端项目工程化
就是首先需要先写页面,复用性组件进行模块化,书写代码时要求规范化,然后页面功能完毕之后进行测试功能,实现完成之后就提交到远程git仓库。·
个人总结经验,认为前端工程化主要应该从模块化、组件化、规范化、自动化四个方面来思考。如何选型技术、如何定制规范、如何分治系统、如何优化性能、如何加载资源,当你从切图开始转变为思考这些问题的时候,我想说:你好,工程师!
4.深克隆、浅克隆
js有两种大类的类型:基本类型(undefined、Null、Boolean、Number和String)和引用类型(Object、Array和Function),基本类型的复制是不会产生深度复制和浅度复制问题,当使用引用类型进行复制的时候,其实复制的是指向内存值的指针,并没有真实复制其数据(浅复制)。
浅克隆:
也就是两个引用类型之间进行赋值,将一个引用类型赋值给另一个引用类型,事实上是赋的是引用类型的地址,而非数据。当赋值之后,两个引用类型占用共同的地址空间,其实就是两个引用类型是指向同一个堆地址空间,引用类型的数据也就自然一样了。
// 浅克隆
let obj = {
name: "wh",
age: 23
}
let objShallowClone = obj //此时就相当于浅克隆,他们只是指向同一个地址空间,所以数据也就自然一样了,并没有重新构建一个对象
console.log(objShallowClone == obj); //true
深克隆
相对于浅克隆,深克隆是重新构建了一个对象,开辟了一个新的地址空间,将原先对象的数据全都复制到新的对象上,新对象和原对象毫无关系,互不影响。而不是项浅克隆那样只是指向同一个地址空间,
采用json.parse()和json.stringify()实现深克隆
// 深克隆
// json.parse()和stringify实现
let obj = {
name: "wh",
age: 23
}
let objDeepClone = JSON.parse(JSON.stringify(obj));
console.log(objDeepClone == obj); //false
使用ES6的Array.from(arr)实现数组深克隆
// 第二种方式:使用Array.from(arr)深拷贝一个新的数组
let arr = [1, 2, 3]
let arr1 = Array.from(arr)
console.log(arr == arr1); //false
使用ES6的扩展运算符…
// 第三种方式,扩展运算符 ...
let arr3 = [...arr]
console.log(arr3 == arr); //false
暴力循环进行赋值
// 第四种方式,也就是最粗暴的方式,暴力循环进行赋值
let arr4 = new Array(arr.length)
for (const key in arr) {
arr4[key] = arr[key]
}
console.log(arr4 == arr); //false
5.对微前端,微服务,大前端的理解。
微前端
什么是微前端?
微前端就是将不同的功能按照不同的维度将一个应用拆分成多个子应用,通过主应用来加载这些子应用。微前端的核心在于拆、拆完后再合。
为什么要使用它?

我们可以将一个应用划分为若干个子应用,将子应用再进行打包成一个个的lib,然后在分别上线(打包上线)。当路径切换时加载不同的子应用,这样每个子应用都是独立的,技术栈也不用做限制了(每个子应用可以使用vue或者react再或者andular.js),从而解决了前端协同开发问题。
关于微前端的两个成熟的框架:Single-SPA,qiankun。
Single-SPA
Single-SPA是一个用于微前端服务化的js前端解决方案(本身没有处理样式冲突隔离(这是因为一个应用中包括的很多子应用可能会有样式冲突,他没有解决),也没有处理js冲突隔离),它仅仅做了一件事,就是实现了路由劫持和应用加载。
使用Single-spa框架的整个流程:
第一步:首先需要创建vue create一个子应用和父应用。
第二步:在子应用中,如果你是vue项目,就引入single-spa-vue库,然后导出这个库提供的3个方法(也称为singleSpa的生命周期函数:bootstrap、mount、unmount),然后再创建一个vue.config.js在里面配置一些webpack打包输出信息,打包此应用为一个lib。
其中vue.config.js是vue-cli3新增加的一个功能,就是如果要配置webpack的属性,就需要在项目根目录下创建一个vue.config.js。
第三步:在父应用中,需要引入single-spa库,引入这个库的注册方法(registerApplication方法)和启动方法(start()方法)
single-spa缺陷:不够灵活,不能动态加载js文件,并且样式不隔离;
没有解决沙箱的问题(就是让一个应用处于一个隔离的环境,不受其他外界应用造成影响)
qiankun
qiankun框架是基于Single-spa框架,他提供了开箱急用的API(single-spa + sandbox + import-html-entry),并且技术栈无关,并且接入简单(像iframe一样,但是iframe现在基本已经废弃了,因为如果只是使用iframe,iframe中的子应用在切换路由时用户刷新页面就不好了,一旦刷新那么url的状态就会丢失,就不能前进和后退了且页面会丢失)。
总结:子应用可以独立构建,运行时动态加载,主子应用完全解耦,各个子应用中技术栈可以不同,考的是协议接入(子应用必须导出bootstrap(启动方法)、mount、unmount方法),并且解决了样式隔离、js隔离等沙箱问题,
使用qiankun框架的步骤:
第一步:首先需要在子页面中设置子应用的协议,也就是导出的那三个生命周期函数bootstrap、mount、unmout。然后在vue.config.js中配置webpack,配置子应用的可跨域以及输出类型为umd类型(使得父应用可以得到子应用的生命周期函数)
//子应用的main.js
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
// 引入全局变量
import "./globle"
// import reportWebVitals from './reportWebVitals';
// 封装一个render方法
function render() {
ReactDOM.render(
<React.StrictMode>
<App />
</React.StrictMode>,
document.getElementById('root')
);
}
// 如果是父应用调用
if (window.__POWERED_BY_QIANKUN__) {
}
// 本项目独立运行调用
if (!window.__POWERED_BY_QIANKUN__) {
render();
}
async function bootstrap() { }
async function mount(props) {
render();
// 在这里面可以拿到父应用传递的props
// console.log(props.name1);
}
async function unmount() {
// ReactDOM.unmountComponentAtNode(document.getElementById('root'));
}
export {
bootstrap,
mount,
unmount
}
//子应用的webpack.config.js
module.exports = {
devServer: {
port: "8002",
headers: {
// 设置可跨域
'Access-Control-Allow-Origin': '*'
}
},
configureWebpack: {
//设置打包输出
output: {
// 打包名
library: "vueApp",
// 打包为什么类型,配置打包后的模块类型为umd模块,umd的特点就是使得父应用的window对象有singleVue.bootstrap、mount、unmount。
libraryTarget: "umd"
}
}
}
第二步:在父应用中安装qiankun库npm install qiankun;然后设置子应用挂载的位置,以及一些切换路由跳转到此子应用;再引入qiankun库的registerMicroApp()方法(用来注册子应用)、start(用来启动子应用);这样就完成了
// 引入qiankun
import {
registerMicroApps,
start,
initGlobalState,
MicroAppStateActions,
} from "qiankun";
// 注册的应用列表
const apps = [
// react子应用
{
name: "reactApp",
entry: "http://localhost:8002",
container: "#childReact",
activeRule: "/login",
// 通过props实现通信传递值
props: {
callback: function (res) {
this.res = res;
console.log(res);
},
},
},
// 子应用react应用
{
name: "reactApp",
// 默认请求的url,并解析这个文件里面的script标签,因为此时父应用请求了子应用里面的资源,所以子应用必须支持跨域
entry: "http://localhost:8002",
// 子应用挂载到哪个元素
container: "#react",
//激活规则,当路由切换到“/react”时,就会把本地端口为20000的子应用挂载到"#react"元素上
activeRule: '/react'
}
]
// 注册子应用
registerMicroApps(apps,
// 可以设置一下加载逻辑,也可不用
{
beforeMount() {
console.log(1);
}
})
// 启动子应用
start({
prefetch: false //取消预加载,即当不点击触发子应用加载时,不会去启动这些子应用
})
采用微前端,各个子应用之间如何通信。
- 最简单的方式是通过url来进行数据的传递,但是传递消息能力弱
- 基于CustomEvent实现传递
- 基于props主子应用间进行通信
- 使用全局变量、redux进行通信
大前端
简单来说,大前端就是所有前端的统称,比如Android、iOS、web、Watch等,最接近用户的那一层也就是UI层,然后将其统一起来,就是大前端。大前端是web统一的时代,利用web不仅能开发出网站,更可以开发手机端web应用和移动端应用程序。
其实大前端的主要核心就是跨平台技术,有了跨平台技术,各个平台的差异性就抹平了,开发者只需要一套技术栈就可以开发出适用于多个平台的客户端。
大前端也就是囊括了很多种不同类型的设备的前端页面开发,不拘泥与pc端,也有移动端包括Android、ios、watch等移动端开发。
采用vue的weex可以实现跨平台技术开发(Android、ios、pc前端),Weex 是阿里巴巴开源的一套构建高性能、可扩展的原生应用跨平台开发方案。
采用react-native也可以完成。
6.正则表达式
let re = new RegExp("at","i"); //构造函数创建正则
let re = /at/i //通过字面量创建
//正则实例的主要方法就是exec("要捕获的字符串"),主要用于配合捕获组使用,如果找到了匹配项则返回包含第一个匹配信息的数组,数组第一个元素就是匹配到的内容;如果没有找到,则返回null,返回的数组包含index和input属性,分别代表捕获到的在原始字符串中的起始位置,input代表输入的字符串
re.exec("fat2"); //返回的数组中index为1,input为fat2
re.test("fat2"); //返回的是Boolean类型 ,匹配到就返回true,否则返回false
[]中括号是一个集合代表在里面元素中任选一个
(0-9)小括号是匹配的区间
{}代表 匹配次数
7.设计模式

设计模式就是套路,就是前人在解决问题的时候遇到频繁相似的问题,都需要去做重复的工作写重复的代码, 这就需要用一种东西去组织一下,自动化它,这就是设计模式。主要解决的问题就是怎么样让代码更好维护、有更高的复用性、更加稳健。
比如以下代码重用性维护性很差,所以我们采用一些设计模式来进行代码维护
// 最冗余的创建一个对象就是直接赋值,代码重构性是极差的,是开发过程中不推荐的
let p1 = {
name: "wh",
age: 23
}
let p2 = {
name: "xx",
age: 23
}
一. 创建型模式
a. 构造器模式
也就是通过使用构造函数创建一个“类”,以后需要创建一个所需要的对象时就不需要写重复代码,只需要传入所需要的参数,new 构造函数创建一个对象。
// 一个构造函数来进行创建对象,代码重用性高且可维护性较好
function Person(name, age) {
this.name = name;
this.age = age
}
b.原型模式
原型模式跟构造器模式一样的,只是原型模式是在构造函数的原型对象上添加属性和方法
c.建造者模式
// c.建造者模式,也就是对于创建类的时候不是直接传参了,而是在类中设置了一些方法,通过向此方法传参来修改对象属性,还有通过调用一个方法返回所创建的对象
// 然后一点就是可以通过建造者模式创建所传的参数的规则,如果不符合规则,则会有对应的措施
function Student(name, age) {
this.name = name;
this.age = age
}
function StudentBuilder() {
this.student = new Student;
this.setName = function (name) {
// 设置一些判断规则
if (name == "*") {
throw "取名不对"
}
this.student.name = name
}
// 调用此方法
this.build = function () {
return this.student
}
}
d.单例模式
保证一个类只有一个实例,并提供一个访问他的全局访问点。只有第一次new的时候会创建一个对象,以后再new这个单例构造函数时,只会返回第一次new的那个对象。
// 单例模式,在多次new对象的时候只会创建一个对象,之后new 对象的时候一直是同一个对象,也就是说只有第一次new的时候会创建一个对象,以后再new这个单例构造函数时,只会返回第一次new的那个对象
function SingleResource() {
this.balance = 100;
// 如果之前有new过实例,即存在instance
if (SingleResource.instance) {
// 直接返回已存在的实例
return SingleResource.instance
}
// instance相当于是刻在SingleResource机器上的,相当于给这个构造函数上添加了一个属性,这个属性等于创建的实例对象
SingleResource.instance = this
}
// 创建两个实例s1,s2,你会发现其实他们两个是共用的,其实是同一个对象
let s1 = new SingleResource();
let s2 = new SingleResource();
s1.balance = 50;
console.log(s2.balance); //50
e.工厂模式
工厂模式是用来创建对象的一种最常用的设计模式。不暴露创建 对象的具体逻辑,而是将逻辑封装在一个函数里面,那么这个函数就是一个工厂。
它可以很快的生成几类对象,而且每次返回的对象都是新对象
// e.工厂模式,会在构造函数里面判断所传参数内容,对于不同的内容返回对应的数据或者执行相应的逻辑
/**
*
* @param {string} name 姓名
* @param {*} subject 学科
*/
function Student(name, subject) {
this.name = name;
this.subject = subject
}
/**
*
* @param {string} name 姓名
* @param {string} type 文科还是理科
* @return {Student}
*/
function Factory(name, type) {
// 对传入的type参数先进行判断,不同的文理科返回不同的结果
switch (type) {
case "理科":
return new Student(name, ["物理", "化学", "生物"]);
break;
case "文科":
return new Student(name, ["政治", "历史", "地理"]);
break;
default:
throw "没有这个专业,别乱填哇"
}
// if (type == "理科") {
// return new Student(name, ["物理", "化学", "生物"]);
// }
// if (type == "文科") {
// return new Student(name, ["政治", "历史", "地理"]);
// }
}
let wh = new Factory("wanghe", "理科");
let xx = new Factory("xx", "文科")
二. 行为型模式
观察者模式
定义了对象键一对多的依赖关系,当目标对象的状态发生变化时,所有依赖它的对象会得到通知。并自动更新。观察者模式属于行为型模式,行为型模式关注的是对象之间的通讯,观察者模式就是观察者和被观察者之间的通讯。
目标对象会订阅多个观察者,当目标对象的观察者发生改变时,会通知观察者
观察者模式有一个别名叫“发布-订阅模式”,或者说是“订阅-发布模式”,订阅者和订阅目标是联系在一起的,当订阅目标发生改变时,逐个通知订阅者。
// 观察者模式
// 当目标状态发生改变时,需要通知给观察者
// 目标者类
class Subject {
constructor() {
// 观察者列表
this.observers = []
}
// 添加观察者
add(observer) {
this.observers.push(observer)
}
// 删除观察者
remove(observer) {
let index = this.observers.indexOf(observer)
if (index != -1) {
this.observers.splice(index, 1);
}
}
// 通知给观察者
notify() {
for (const observer of this.observers) {
observer.update()
}
}
}
// 观察者类
class Observer {
constructor(name) {
this.name = name
}
// 目标更新时触发的回调
update() {
console.log(`目标者通知我更新了,我是${this.name}`);
}
}
let o1 = new Observer("wh")
let o2 = new Observer("xxx")
let o3 = new Observer("wmg")
let sub = new Subject();
sub.add(o1)
sub.add(o2)
sub.add(o3)
sub.notify()
//目标者通知我更新了,我是wh
//目标者通知我更新了,我是xxx
//目标者通知我更新了,我是wmg
发布订阅模式
实现了对象间多对多的依赖关系,通过事件中心管理多个事件。通过事件中心管理多个事件,目标对象并不直接通知观察者,而是通过事件中心来派发通知。
事件中心先订阅事件,可以用一个数组来订阅事件,然后再发布事件。
三. 结构型模式
代理模式
在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象就可以代替一个对象去引用另一个对象,代理对象起到了中介的作用。
/**
*一个小学生不能直接开车,需要判断它的年龄是否成年,如果成年了就可以开车,否则就不能,
则就需要有一个车的代理CarProxy来在人与车之间产生关联
*/
// 车
class Car {
drive() {
return "driving"
}
}
// 驾驶人
class Driver {
constructor(age) {
this.age = age
}
}
// 车的代理
class CarProxy {
constructor(driver) {
this.driver = driver
}
drive() {
if (this.driver.age >= 18) {
return new Car().drive();
} else {
return "未满18岁,开个der的车哇"
}
}
}
let driver = new Driver(19);
let carProxy = new CarProxy(driver);
console.log(carProxy.drive()); //driving
其实也可以使用ES6的Proxy代理,也就是在目标对象之前假设一层拦截,或者叫做代理
console.log("-------------------------", "ES6代理");
let obj = {};
let proxy = new Proxy(obj, {
get: function (target, key, receiver) {
console.log("get"); //当获取值时触发get
return Reflect.get(target, key, receiver)
},
set: function (target, key, value, receiver) {
console.log("set"); //当设置值时触发set
return Reflect.set(target, key, value, receiver)
}
});
proxy.count = 1 //obj.count =1
//set
++proxy.count
//get set
console.log(obj.count); //obj.count=2
装饰模式
装饰模式是动态的给一个对象添加一些额外的功能,就增加功能来说,装饰模式比生成子类(采用继承模式,继承一个父类,然后在其子类上添加新的功能)更为灵活。
// 装饰模式
var Plane = {
fire: function () {
console.log('发射普通的子弹');
}
};
var missileDecorator = function () {
console.log('发射导弹!');
};
var fire = Plane.fire;
// 简而言之就是给一些已经存在的函数添加一些拓展功能(添加代码)
Plane.fire = function () {
fire();
missileDecorator();
};
Plane.fire();
8.vue双向绑定。要求手撕简单版。(简易版demo,以后面试就手撕这个demo)
vue中的v-model的简单实现是基于表单的value属性绑定state和表单触发input事件的语法糖。(但是这种写法还是基于vue的)
抛开vue,原生的底层实现的话是采用Object.defineProperty(object,“object的属性”,{
set:(value)=>{},
get:()=>{}
})来监听obj.val的变化,一旦发生改变就会触发里面的set和get函数
其实这也是一种vue底层的一种设计模式----发布订阅者模式,object.defineProperty只要监听到一些属性发生变化,就会通知一些订阅者(一些dom)发生改变,这也叫做观察者模式。
事实上vue2和vue3实现的数据双向绑定原理是不同的。vue2是采用了ES5的Object.defineProperty来实现,而vue3是利用ES6的proxy代理来监听某个数据实现。但是defineProperty()有一个不足,他不能监听数组的变化,所以我们需要重写数组的方法
//ES6的proxy代理实现
let obj = {}
let proxy = new Proxy(obj,{
get: function (target, key, receiver) {
console.log("get"); //当获取值时触发get
return Reflect.get(target, key, receiver)
},
set: function (target, key, value, receiver) {
console.log("set"); //当设置值时触发set
return Reflect.set(target, key, value, receiver)
}
})
//Object.defineProperty实现
<body>
<div>
<h1>h1>
<input type="text" value="" id="inp">
<button>点我加1button>
div>
<script>
let btn = document.querySelector("button")
let inp = document.querySelector("#inp")
// let name = 1
let obj = {
}
let val = inp.value
// 监听input表单的输入事件
inp.addEventListener("input", () => {
// console.log(val);
// 动态修改obj.val属性值
obj.val = inp.value
console.log(inp.value);
})
// console.log(val);
// 用于监听obj.val的变化,一旦发生改变就会触发里面的set和get函数
Object.defineProperty(obj, "val", {
//一旦 修改了val,就会调用set方法,里面的value值表示修改的内容
set: (value) => {
document.querySelector("h1").innerText = value
console.log(value);
},
// 一旦读取了name属性,就会调用get方法
get: () => {
// return出去的数据代表,以后读取name属性时的数据
return val
}
})
script>
body>
9.webpack 的工作流程?
webpack概述
webpack是一个流行的前端项目构建工具(打包工具),提供代码压缩混淆、js兼容、性能优化问题等功能,从而让程序员把工作的中心放到具体的功能实现上。

webpack使用流程
-
首先需要安装webpack相关的包:npm i webpack webpack-cli -D
-
在项目根目录中,创建名为webpack.config.js的webpack配置文件
-
在webpack.config.js配置文件中,初始化如下基本配置:
// webpack.config.js为webpack的配置文件
// 向外暴露一个配置对象
module.exports = {
// 指定构建模式为开发模式,则webpack打包时不需要对打包输出的文件做压缩,打包速度较快;而相对与production产品上线阶段,会对代码进行压缩以降低文件大小,提高性能
mode: "development"
}
- 在webpack.json包管理配置文件中新增一个dev脚本
{
"name": "webpack",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "webpack" // 新增的dev脚本
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"jquery": "^3.6.0"
},
"devDependencies": {
"webpack": "^5.65.0",
"webpack-cli": "^4.9.1"
}
}
- 然后在终端输入npm run dev启动webpack进行打包,来分析整个项目的文件依赖树以及目录结构,然后将浏览器不能识别的模块进行自动转换打包输出到项目的dist文件下的main.js中,然后再根据需求,在页面中引入打包输出的main.js文件使得让浏览器能够识别的代码。
webpack配置打包的入口和出口
webpack默认打包入口entry是src下的index.js文件、默认打包出口output是dist文件夹下的main.js
const path = require("path")
module.exports = {
// 指定构建模式为开发模式,则webpack打包时不需要对打包输出的文件做压缩,打包速度较快;而相对与production产品上线阶段,会对代码进行压缩以降低文件大小,提高性能
mode: "development",
// mode: "production"
// 配置打包入口
entry: path.join(__dirname, "./src/index.js"),
// 配置文件打包出口
output: {
// 打包输出的文件路径
path: path.join(__dirname, "./dist"),
// 打包输出的文件名
filename: "buldle.js"
}
}
配置webpack自动打包功能
- 安装支持项目自动打包的工具webpack-dev-server,其会启动一个试试打包的http服务器。npm i webpack-dev-server ,
- 修改pack.json 文件中的dev命令
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "webpack-dev-server" //由"dev": "webpack"修改为"dev": "webpack-dev-server"
},
- 将src下的index.html中的script脚本的引用路径修改为“/buldle.js”
<script src="/buldle.js">script>
- npm run dev, 重新进行打包
- 在浏览器中访问http://localhost:8080来查看自动打包效果
配置自动打包工具后的页面预览功能
- 安装生成预览页面的插件。npm i html-webpack-plugin
- 修改webpack.config.js文件头部区域,添加以下代码信息
// 导入生成预览页面的插件得到一个构造函数,其功能就是在由一个文件夹中的文件复制一个相同的文件到根目录
const HtmlWebpackPlugin = require("html-webpack-plugin")
// 创建插件实例对象
const htmlPlugin = new HtmlWebpackPlugin({
template: "./src/index.html", //指定要用到的模板文件
filename: "index.html" //指定生成的文件的名称,改文件存在于内存中是虚拟的,在目录中不显示
})
// 向外暴露一个配置对象
module.exports = {
// 修改webpack.config.js文件中向外暴露的配置对象,新增配置节点plugins
plugins: [htmlPlugin], //plugin数组是webpack打包期间会用到的一些插件列表
}
- 执行npm run dev后就可以直接在网页上看到index.html页面,而不是呈现的是各个目录文件
配置自动打包相关的参数
当运行npm run dev时自动弹出网页页面,而不需要手动复制粘贴浏览器打开。
方法:将package.js中的 "dev": "webpack-dev-server "变为 "dev": "webpack-dev-server --open --host 127.0.0.1 --port 8888"即可自动弹出浏览器,
其中--open 为打包完成后自动打开浏览器页面;--host是配置ip地址 ; --port为配置端口号
使用loader打包非js文件
在实际开发中,webpack默认只能打包处理以.js后缀结尾的模块,其他非.js模块webpack处理不了,需要使用loader加载器才可以正常打包,否则会报错。
比如sass-loader来打包.sass相关的文件、less-loader来打包.less相关的文件。
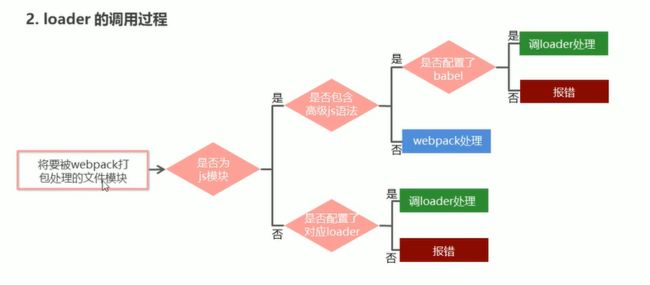
打包相关css文件的步骤:
- 安装处理css文件的loader,npm i style-loader css-loader -D
- 在webpack配置文件webpack.config.js的mudule->rules数组中,添加loader规则
// 所有第三方文件模块的匹配规则中
module: {
// 匹配规则的数组
rules: [{
// 此规则为打包css文件的规则,需安装 npm i style-loader css-loader
test: /\.css$/, //test是一个正则表达式表示匹配的文件类型,用于匹配什么样的文件
use: ["style-loader", "css-loader"] //use是一个数组表示对应要调用的loader,用什么loader加载器来处理匹配到的文件
},
{
// 打包less文件的规则,需安装npm i less less-loader
test: /\.less$/,
// loader必须要按次序调用,即先调用style-loader、再css-loader、less-loader
use: ["style-loader", "css-loader", "less-loader"]
}, {
// 打包scss文件的规则,需安装npm i sass-loader node-sass
test: /\.scss$/,
use: ["style-loader", "css-loader", "sass-loader"]
}
]
}
打包处理js文件中的高级语法比如ES6的class类(webpack低版本)
webpack低版本不能对js的高级语法进行默认打包,需要使用babel相关的loader来解析转换高级语法(但是现在的webpack较高版本可以默认打包了)
步骤:需安装babel转换器相关的包、在plugin插件数组中 添加babel相关依赖库、创建loader规则
第一题:谈谈你对webpack的理解?
webpack是一个打包模块化js的工具,在webpack里一切文件皆模块,通过loader转换文件,通过plugin注入钩子,最后输出由多个模块组合成的文件,webpack专注构建模块化项目。WebPack可以看做是模块的打包机器:它做的事情是,分析你的项目结构,找到js模块以及其它的一些浏览器不能直接运行的拓展语言,例如:Scss,TS等,并将其打包为合适的格式以供浏览器使用。
第二题:说说webpack与grunt、gulp的不同?
三者都是前端构建工具,grunt和gulp在早期比较流行,现在webpack相对来说比较主流,不过一些轻量化的任务还是会用gulp来处理,比如单独打包CSS文件等。
第三题:什么是bundle,什么是chunk,什么是module?
bundle:是由webpack打包出来的文件。chunk:代码块,一个chunk由多个模块组合而成,用于代码的合并和分割。module:是开发中的单个模块,在webpack的世界,一切皆模块,一个模块对应一个文件,webpack会从配置的entry中递归开始找出所有依赖的模块
第四题:什么是Loader?什么是Plugin?
1)Loaders是用来告诉webpack如何转化处理某一类型的文件,并且引入到打包出的文件中2)Plugin是用来自定义webpack打包过程的方式,一个插件是含有apply方法的一个对象,通过这个方法可以参与到整个webpack打包的各个流程(生命周期)。
10.做项目的时候遇见的难点,如何解决的?从现在的角度来看,有没有更好的方法去实现?
难点就是在把之前的vue项目中的登录页面拆成另一个react子项目,然后使用微前端qiankun框架技术重新把子应用合并到react项目中,主要难点就是在子应用中把异步请求收到的登录信息,传递给父应用,然后父应用判断是否可以登录成功,之前没有用到父子间的通信,而是用的本地缓存简单实现,但是也可以用父子间通信来实现更好一点。
另外一个就是封装防抖节流插件时应该在mount生命周期函数中给一些dom元素绑定。
就是移植项目时,依赖包版本不匹配所带来的问题,此时就需要用到yarn包管理工具,它的最大的好处就是安装的依赖包都是与项目中匹配的。
11. 讲讲react和vue的不同
共同点:
他们都是前端框架,简化了前端纯原生写法拼接页面写页面的复杂性,提高了代码的可维护性。
- react和vue都采用了虚拟dom,来提高浏览器的性能。
- 都支持服务器端渲染(Server-Side-Rending,SSR,也就是后端直接返回带有数据已经渲染完成的页面,这样前端收到后直接渲染这个页面块就可以了)
- 都有支持native跨平台技术开发的方案,React的React native,Vue的weex
- .都有自己的状态管理,React有redux,Vue有自己的Vuex(自适应vue,量身定做)
不同点:
- vue和react框架在制作的时候出发点角度不同,react完全是利用js语言自身能力来编写UI,而不是造轮子来增强html功能,而vue是指令式编程,可以利用一些指令比如v-model、v-for、v-show;(react只要能用到js的地方就绝对不会增加一个新的指令功能)
- react仅仅是操作mvc中的v视图层,而vue是MVVM(model-view-viewModel )都有
- virtual DOM不一样,vue会跟踪每一个组件的依赖关系,不需要重新渲染整个组件树.而对于React而言,每当父组件的state状态被改变时,则其子组件会重新渲染,所以react中会需要shouldComponentUpdate这个生命周期函数方法或者使用pureComponent纯组件把v 来进行控制
- react和vue都是基于组件式开发,但组件写法不一样, React推荐的做法是 JSX + inline style, 也就是把HTML和CSS全都写进JavaScript了,即’all in js’;Vue推荐的做法是
webpack+vue-loader的单文件组件格式,即html,css,js写在同一个文件; - state对象在react应用中不可变的,需要使用setState方法更新状态;在vue中,state对象不是必须的,数据由data属性在vue对象中管理;
- vue中表单数据可通过v-model指令实现双向绑定,而react若想要数据双向绑定,则需要通过使用js的表单inpute()事件搭配表单数据value=state.val实现
12.js垃圾回收
js有自动垃圾回收机制(与c和c++不同需要程序员手动清理,free(name)释放)。垃圾回收程序会确定哪个变量不会再使用,然后就释放它占有的内存。
所以如何查看变量是否还会使用呢?这里js是采用标记的形式,主要有两种标记策略:标记清理以及引用计数。
标记清理(常用):
垃圾回收程序在运行的时候,首先会标记内存中的所有变量(有很多方式比如维护一个变量在上下文的和不在上下文的列表),然后将上下文中的变量以及被上下文引用的标记去掉。由于上下文不访问这些变量,所以之后还存在标记的变量就是待回收的了,然后垃圾回收程序做一次内存清理,销毁带标记的所有值并收回他们的内存。
引用计数(不常用):
其思路是对每个值都记录他被引用的次数,变量被引用就+1,被覆盖就-1,当一个变量的引用为0时,就没办法访问这个值了,就会垃圾回收。
13.vuex重点
vuex也就是vue的状态管理工具,通俗说就是通过vuex的store存储库可以定义vue的全局状态(也可以说是全局变量),然后里面还定义了一些全局的修改状态的属性比如mutations、actions等
vuex有几个属性,state、getters、mutations、actions、modules
先定义vuex
import Vue from 'vue'
import Vuex from 'vuex'
Vue.use(Vuex)
export default new Vuex.Store({
// 全局数据,在任何页面中都可以通过this.$store.state访问state里面的数据
state: {
count: 0
},
// getters相当于组件中的computed计算属性,getters是全局的,computed是组件内部使用的
getters: {
count(state) {
return state.count
}
},
mutations: {
},
actions: {
},
modules: {
}
})
一. state:
export default new Vuex.Store({
// 全局数据,在任何页面中都可以通过this.$store.state访问state里面的数据
state: {
count: 0
},
// getters相当于组件中的computed计算属性,getters是全局的,computed是组件内部使用的
getters: {
count(state) {
return state.count
}
},
mutations: {
},
actions: {
},
modules: {
}
})
页面中使用state数据:
// Home组件
<template>
<div class="home">
<h1>Home:count:{{ count }}h1>
div>
template>
<script>
// @ is an alias to /src
// import HelloWorld from "@/components/HelloWorld.vue";
export default {
computed: {
// 计算属性count,需要return返回数据
count() {
// 通过this.$store来使用state
return this.$store.state.count;
},
},
};
script>
二. getters
将组建中统一使用的computed计算属性都放在getters里面来操作保存
// getters相当于组件中的computed计算属性,getters是全局的,computed是组件内部使用的
getters: {
count(state) {
return state.count
}
},
页面中使用getters的计算属性:
// about页面
<template>
<div class="about">
<h1>about: count:{{ $store.getters.count }}h1>
div>
template>
<script>
export default {
data() {
return {};
},
};
script>
三. mutations
mutations相当于组件中的methods,提交vuex状态改变的唯一方法就是mutations属性,但是他不能使用异步方法,比如定时器、axios。后面讲的actions就可以用异步函数了。
// mutations相当于组件中的methods,提交vuex状态改变的唯一方法就是mutations属性
// 但是他不能使用异步方法,比如定时器、axios
mutations: {
//计数器count加1的方法,也可以传参,payload为参数,也可以不传
handleAdd(state, payload) {
state.count++
}
},
页面中使用是通过commit()方法将方法进行提交:
<template>
<div id="btn">
<button @click="handleAdd1">点我加1撒button>
div>
template>
<script>
export default {
data() {
return {};
},
methods: {
handleAdd1() {
// 这种直接对state中的数据做修改是不推荐的,更改vuex的store中状态的唯一方法是替米提交mutation
// 即使你在页面上看到了数据的变化,但store库中的state状态数据依然是没变的
// this.$store.state.count++;
// 应该使用mutations属性来改变vuex中的全局状态
//使用commit方法来调用,也就是commit提交某个方法,这里可以传参数,参数payload可有可无
this.$store.commit("handleAdd",payload);
},
},
};
script>
四. actions
actions与mutations作用类似都是用来修改vuex中全局属性state数据的,只是mutation中的函数不能使用异步操作,而actions中可以使用异步操作,对应的调用方法也不同。mutation是采用commit方法来提交某个方法,而actions是采用dispatch来派遣某个方法。
// actions专门用来处理异步,实际修改状态值的依然是mutations
actions: {
// 点击按钮后等一秒钟再减1
// context上下文就相当图这个store实例this.$store
handleDecrease(context) {
setTimeout(() => {
// 下面代码相当于this.$store.commit("handleDecrease")
context.commit("handleDecrease")
}, 1000)
}
},
在组件使用:
<template>
<div id="btn">
<button @click="handleAdd">点我加1撒</button>
<button @click="handleDecrease">点我减1撒</button>
</div>
</template>
<script>
export default {
data() {
return {};
},
methods: {
// 点击加法按钮触发的减法方法
handleAdd() {
// 这种直接对state中的数据做修改是不推荐的,更改vuex的store中状态的唯一方法是替米提交mutation
// 即使你在页面上看到了数据的变化,但store库中的state状态数据依然是没变的
// this.$store.state.count++;
// 应该使用mutations属性来改变vuex中的全局状态
//调用store中的mutation方法,使用commit方法来调用,也就是commit提交某个方法
this.$store.commit("handleAdd");
},
// 点击减法按钮触发的减法操作方法
handleDecrease() {
// 同步操作使用mutation,对应的方法是commit
// this.$store.commit("handleDecrease");
// 异步操作使用actions,对应的方法是dispatch()派遣的意思
this.$store.dispatch("handleDecrease");
},
},
};
</script>
五. modules
我们的store可以认为是一个主模块,他下边可以分解很多子模块modules,子模块单独在一个js文件中写,写完再引入index.js文件中,然后再在store主模块的modules中进行引用
使用modules可以单独引入某个模块的store中的所有状态,这样做的好处就是使得一些具有相同用处的状态数据写在一块儿,代码更加清晰,不同模块的状态写在不同的js文件中,然后在index中对这些模块进行引入。
//mudules/user.js文件
//写一个user用户的状态store库
// 使用一个相关的整个模块module导出,供index.js在module中使用
export default {
// 命名空间,也就是说你可以在其他模块引入此模块后,可以引用我的state状态里的数据
namespaced: true,
state: {
name: "wanghe",
password: "123232",
token: "waafFfawfafwawf"
},
mutations: {
setName(state, name) {
state.name = name
}
}
}
//在index.js中进行引入
// 导入user.js模块
import user from "./modules/user"
export default new Vuex.Store({
state:{},
modules: {
// 单独引入user用户的模块vuex状态管理模块,以后就可以使用user的store库的状态
// 要获取user里面的state数据需要:this.$store.state.user
user,
}
})
//在页面中使用
<template>
<div id="btn">
<button @click="handleAdd()">点我加1撒button>
<button @click="handleDecreaseAsync()">点我减1撒button>
<div>{{ $store.state.user.name }}div>
<button @click="setName('王大哥')">点击修改名字呦button>
div>
template>
<script>
export default {
data() {
return {};
},
methods: {
// 映射修改store子模块user中的state数据的方法
...mapMutations({
// 需要加路径
setName: "user/setName",
}),
},
}
script>
六. mapState和mapSetters()辅助函数mapMutations()和mapActions()辅助函数
state里面的数据在使用的时候,一般是挂在computed里面的,因为如果你挂在data上面,只会赋值一次,不会跟着vuex里面的变化而同步变化,当然也可以通过watch $store去解决这个问题。
所以一般需要把你要用到的vuex数据变为计算属性。
但是一个一个转化为计算属性太麻烦,所以可以使用vuex提供的mapState()方法来简化映射
一般mapState和mapSetters()辅助函数映射为计算属性
mapMutations()和mapActions()辅助函数映射为methods方法
// mapState是一种映射state中数据的用法,mapState()
import { mapState } from "vuex";
// mapGetters是一种映射getters中方法的用法,mapGetters()
import { mapGetters } from "vuex";
// mapMutations和mapActions分别是一种映射mutations、和actions方法的一种方法,一般把这些方法映射为methods方法
import { mapMutations, mapActions } from "vuex";
computed: {
// 将vuex中的store库中的state状态映射为计算属性
...mapState(["count", "num"]),
// 将getters中的计算属性映射出来
...mapGetters(["count"]),
// 计算属性count,需要return返回数据
// count() {
// // 通过this.$store来使用state
// return this.$store.state.count;
// },
},
methods: {
// 使用mapMutations将mutations中改变state的方法映射为methods方法
...mapMutations(["handleAdd", "handleDecrease"]),
// 使用mapActions将actions中改变state的方法映射为methods方法
...mapActions(["handleDecreaseAsync"]),
/**
这段代码与上面那个代码有着相同的作用
...mapActions({
handleDereaseAsync:"handleDecreaseAsync"
}),
* */
// 修改store子模块user中的state数据
...mapMutations({
// 需要加路径
setName: "user/setName",
}),
// 点击加法按钮触发的减法方法
// handleAdd() {
// // 这种直接对state中的数据做修改是不推荐的,更改vuex的store中状态的唯一方法是替米提交mutation
// // 即使你在页面上看到了数据的变化,但store库中的state状态数据依然是没变的
// // this.$store.state.count++;
// // 应该使用mutations属性来改变vuex中的全局状态
// //调用store中的mutation方法,使用commit方法来调用,也就是commit提交某个方法
// this.$store.commit("handleAdd");
// },
// 点击减法按钮触发的减法操作方法
// handleDecrease() {
// // 同步操作使用mutation,对应的方法是commit
// // this.$store.commit("handleDecrease");
// // 异步操作使用actions,对应的方法是dispatch()派遣的意思
// this.$store.dispatch("handleDecreaseAsync");
// },
},
七. vuex的store中所有属性也可以支持拆分写法
也就是一个state.js文件只写关于state相关的、actions.js文件只写actions改变状态的方法相关的,然后再引入index.js中
14. typeScript了解
15.vue生命周期
vue的生命周期就是Vue实例从创建到销毁的过程就是生命周期,即从创建、初始化数据、编译模板、挂载dom到渲染、更新到渲染、销毁等一系列过程。
他主要分为8个阶段创建前后、载入前后、更新前后、销毁前、销毁后以及一些特殊场景的声明周期,如图:
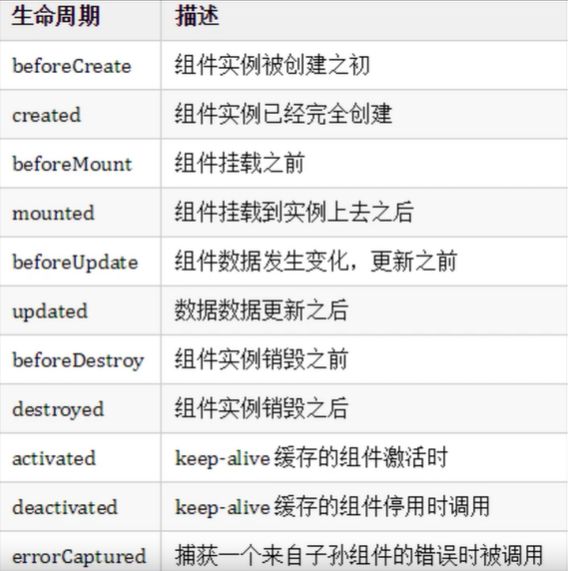
vue生命周期的整体流程:
beforeCreated :执行时组件实例还未创建,通常用于插件开发中执行一些初始化任务。
created:组件初始化完毕,各种数据可以使用,常用于异步数据获取。
beforeMount : 未执行渲染、更新,dom未创建,还未挂载
mounted:中dom已创建,已挂载到DOM上,可用于访问数据和dom元素
beforeUpdate: 更新前,可用于获取更新前各种状态
updated:更新后,所有状态已是最新
beforeDestroy:销毁前,可用于一些定时器或缓存的取消
destroyed: 组件,组件已销毁,可用于清除一些定时器或缓存
created和mounted声明周期的区别:
created是组件实例一旦创建完成后立刻会调用的生命周期,此时dom节点还未形成。也就是此组件的vue实例已经创建完成,但是还未渲染页面(挂载dom)
mounted是页面dom节点渲染完毕之后就立刻会执行的,created的触发时机要比mounted要早一些。
16. 你打算未来学什么
typescript、vue3、看一下node服务器相关的、或者根据公司的需求学一下其他框架(react、andular.js之类的)
17. vue的两种路由模式
<router-link to=""/> 相当于路由入口,会被渲染成一个a标签,to会被渲染成href属性
<router-view /> 相当于一个出口,用来做预渲染的,他会根据路由来匹配组件,然后把组件渲染出来
在vue的router中,通过修改vueRouter的mode属性来决定使用history还是hash。默认为hash模式。
hash模式的url后跟hash值#…,它的原理就是使用window.onHashChange来监听hash值的改变,一旦发生变化就找出此hash值所匹配的组件,进而将组件渲染到页面中。但是hash模式这种带hash值的url是非常丑的,项目中也很少用hash模式。
history模式中的url是以/user这种格式,比较常见,它的原理是通过history.pushState()采用改变url的path路径 进而匹配不同的组件来渲染出来。
import Vue from 'vue';
import VueRouter from 'vue-router';
Vue.use(VueRouter);
// 导入Nprogress ,加载进度条
import NProgress from 'nprogress';
import 'nprogress/nprogress.css';
import { meta } from 'eslint/lib/rules/';
// 路由信息数组
const routes = [
// 后台管理首页路由
{
path: '/',
// meta是设置路由元信息,可有可无
meta: {
title: '小贺酒店管理系统',
},
component: () => import('@v/Index.vue'),
},
// 登录页路由
{
path: '/login',
meta: {
title: '登陆页',
},
component: () => import('@v/Login.vue'),
},
// 注册页面路由
{
path: '/register',
meta: {
title: '小贺酒店管理账号注册页面',
},
component: () => import('@v/Register.vue'),
},
// 后台管理布局页路由
{
path: '/layout',
meta: {
title: '小贺酒店管理系统',
},
component: () => import('@v/Layout.vue'),
// 子路由
children: [
// 角色页面
{
path: 'role',
meta: {
title: '角色管理',
// 只有roleId为1的才可以访问这个页面
permission: [1]
},
component: () => import('@v/role/Role.vue'),
},
//admin路由
{
path: 'admin',
meta: {
title: '账户管理',
},
component: () => import('@v/admin/Admin.vue'),
},
// 客房类型路由
{
path: 'roomType',
meta: {
title: '客房类型管理',
},
component: () => import('@v/roomType/RoomType.vue'),
},
// 客房路由
{
path: 'room',
meta: {
title: '客房管理',
},
component: () => import('@v/room/Room.vue'),
},
// 客户管理路由
{
path: 'guest',
meta: { title: '客户管理' },
component: () => import('@v/guest/Guest.vue'),
},
//email路由
{
path: 'email',
meta: {
title: '电子邮箱',
},
component: () => import('@v/user/Email.vue'),
},
// Home主页路由
{
path: '',
meta: {
title: '客房管理主页',
},
component: () => import('@v/user/Home.vue'),
},
// message页面路由
{
path: 'message',
meta: {
title: 'message页面',
},
component: () => import('@v/user/Message.vue'),
},
// 个人中心页面路由
{
path: 'mine',
meta: {
title: '个人中心',
},
component: () => import('@v/user/Mine.vue'),
},
// 重置密码页面路由
{
path: 'resetPwd',
meta: {
title: '重置密码页面',
},
component: () => import('@v/user/ResetPwd.vue'),
},
// 权限路由
{
path: "permission",
meta: {
title: "权限路由页面",
permission: [1]
},
component: () => import("@v/permission/Permission")
}
],
},
// *表示剩余的全部情况
{
path: '*',
component: () => import('@v/Error404.vue'),
},
];
// 创建路由对象
const router = new VueRouter({
mode: 'history',
base: process.env.BASE_URL,
routes,
});
// 路由前置守卫
router.beforeEach((to, from, next) => {
// 显示加载进度条
NProgress.start();
// 如果要到的一个路由有源信息
if (to.meta && to.meta.title) {
document.title = to.meta.title;
}
// 表示需要验证权限
if (to.meta && to.meta.permission) {
// 在路由前置守卫中设置to.meta.permission是否为1,如果为1则继续,否则跳转到layout页面
if (to.meta.permission.includes(parseInt(localStorage.getItem("roleId")))) {
console.log(to.path);
next()
} else {
console.log(from);
// 则返回一开始的页面
router.push("/layout");
}
} else {
next();
}
});
// 路由后置守卫
router.afterEach((to, from) => {
// 关闭加载进度条
NProgress.done();
});
// 导出router对象
export default router;
hash模式
hash模式主要是根据url的hash值来跳转不同的路由页面。
采用hash模式的路由模式中,url后面有一个#,#后面包括#就是此路由的hash值,hash模式背后的原理是onhashchange事件,可以在window对象上监听这个事件:
vue中hash模式的原理就是通过监听hash值的变化来匹配不同的组件,进而来重新渲染视图。
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
<button id="btn">点我修改hash值呦button>
<script>
let btn = document.querySelector("#btn")
btn.addEventListener("click", () => {
console.log(1);
location.href = "#/user"
})
// hash值一旦修改就会触发
window.onhashchange = (e) => {
console.log(e.oldURL);
console.log(e.newURL);
console.log(location.hash);
}
script>
body>
html>
history模式
history模式原理是通过history.pushState()采用改变url的path路径 进而匹配不同的组件来渲染出来。
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
<h1>history路由实现h1>
<button id="btn">点我切换路由撒button>
<script>
let btn = document.querySelector("#btn")
btn.addEventListener("click", () => {
let state = {
name: "user"
}
// 切换路由的方法,切换到user路由
history.pushState(state, "", "user")
})
script>
body>
html>
18.手撕常见的排序算法
冒泡排序
// 冒泡排序,从小到大
// 冒泡排序的排序逻辑就是:每一轮排序都会将最大的数排到最后面
function bubbleSort(arr = []) {
// 双层for循环
let temp = 0;
for (let i = 0; i < arr.length; i++) {
// 注意:这里是从0开始,每一轮最后一位都减去i
for (let j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp
}
}
}
console.log(arr);
}
bubbleSort([1, 3, 2, 5, 8, 4, 9, 0, 8])
选择排序
// 选择排序
// 也就是每轮循环,都会将最小的数字放到这轮循环的首位处
function selectSort(arr = []) {
// 双层for循环
let temp = 0;
for (let i = 0; i < arr.length; i++) {
for (let j = i + 1; j < arr.length; j++) {
if (arr[i] > arr[j]) {
temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
}
}
}
console.log(arr);
}
selectSort([1, 3, 2, 5, 8, 4, 9, 0, 8])
插入排序
// 插入排序
// 每一论循环都将前i个数字进行排好顺序,下一轮再将第i+1个元素插入到前i个元素
function insertSort(arr = []) {
// 双层for循环
let temp = 0;
for (let i = 0; i < arr.length; i++) {
for (let j = 0; j < i; j++) {
if (arr[i] < arr[j]) {
temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
}
}
}
console.log(arr);
}
insertSort([1, 3, 2, 5, 8, 4, 9, 0, 8])
快速排序(时间复杂度较低到的一种排序算法)
// 快速排序算法俗称快排
// 快排的思想是首先找到一个基准值,然后将比这个基准值大的元素都放在它的右侧,比基准值小的元素放在其左侧,这就是一趟排序,以后再用相同的操作递归左序列和右序列
function fastSort(arr = [], L, R) {
if (L >= R) return
// 记录初始的左指针
let left = L
// 记录初始的右指针
let right = R
// 设置基准元素
let base = arr[left]
let temp;
while (left != right) {
// 首先先找右边的第一个比基准元素小的索引
while (left < right && arr[right] >= base) {
right--
}
// 再找左边的元素第一个比基准元素大的索引
while (left < right && arr[left] <= base) {
left++
}
// 交换左右方元素
temp = arr[left]
arr[left] = arr[right]
arr[right] = temp
}
//循环一遍后,将基准元素插入最终循环的索引
arr[L] = arr[left]
arr[left] = base
fastSort(arr, L, left - 1)
fastSort(arr, left + 1, R)
}
let arr = [1, 3, 2, 5, 8, 4, 9, 0, 8]
fastSort(arr, 0, 8)
console.log(arr);
19.vue的组件通信方式
父子组件通信方式一:通过props和$emit()通信
父向子组件传递数据:在父组件中通过设定子组件的属性值来向子组件传递数据,然后子组件通过props属性来接收数据;
==子组件向父组件传递数据:==在子组件中通过this.$emit(“发射事件名字”,“发送的数据”)来向父组件传递一个发射事件,此时父组件监听此发射事件,发射事件携带的参数就是所要接收的数据
==兄弟组件的通信:==就是让兄弟组件通过一个共同的父组件彼此通讯。
//父组件parent.vue
//子组件Child2.vue
孩子2:{{ name }}
父子组件通信方式二:通过eventBus(事件总线,也就是一个vue实例)来通信
首先在全局main.js中创建并导出一个eventBus全局事件总线来通信,其实原理还是通过emit()来传递一个发射函数,只是说我创建了一个全局的事件中心组件,谁想要发送一些数据谁就引入此组件来emit()传递发射事件,另一个组件也引入eventBus用enventBus.$on()来监听发射事件。
//main.js
import Vue from 'vue'
import App from './App.vue'
import router from './router'
Vue.config.productionTip = false
// 组件通信方式二:通过创建一个事件中心eventBus来通信,其实原理还是通过$emit()来传递一个发射函数,
// 只是说我创建了一个全局的事件中心组件,谁想要发送一些数据谁就引入此组件来$emit()传递发射事件,另一个组件也引入eventBus用enventBus.$on()来监听发射事件
// 在引入时需要用解构来引入eventBus,只有用export default时不需要解构
export const eventBus = new Vue()
new Vue({
router,
render: h => h(App)
}).$mount('#app')
//子组件Child1.vue用于通过eventBus中心事件传递发射事件
孩子1:{{ name }}
//在父组件parent.vue中来监听eventBus传递的事件
通信方式三:Vuex
参考13.vuex
20. 关于阿里的一些前端技术
跨平台开发weex
UI组件库 antDesign
基于vue.js的element-ui组件库
21. 用js简单实现一个vue
22. CommonJs规范和ES6模块的区别
-
commonJS模块的module.exports 输出的是一个值的拷贝(不是同一个内存地址,模块内部的变化并不会影响这个值,即原来模块中的值改变不会影响已加载的该值);而ES6模块输出export的是值的引用,即原来模块中的值改变则该加载的值也改变(共用一个内存地址)。
-
CommonJS是运行时加载,ES6模块是编译时加载输出接口。
这是因为CommonJS加载的是一个对象(即module.exports属性),该对象只有在脚本运行完后才会生成,。而ES6模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成,即边编译边执行。
-
CommonJs加载的是整个模块,即把导入的模块中所有的接口全部加载进来;而ES6可以单独加载其中的某个接口(方法)。
-
CommonJS中的this指向当前模块,而ES6中的this指向undefined
Node 应用由模块组成,采用 CommonJS 模块规范。
每个文件就是一个模块,有自己的作用域。在一个文件里面定义的变量、函数、类,都是私有的,对其他文件不可见。
ES6 模块是前端开发同学更为熟悉的方式,使用 import, export 关键字来进行模块输入输出。ES6 不再是使用闭包和函数封装的方式进行模块化,而是从语法层面提供了模块化的功能。
ES6 模块中不存在 require, module.exports, __filename 等变量,CommonJS 中也不能使用 import。两种规范是不兼容的,一般来说平日里写的 ES6 模块代码最终都会经由 Babel, Typescript 等工具处理成 CommonJS 代码。
使用 Node 原生 ES6 模块需要将 js 文件后缀改成 mjs,或者 package.json "type"`` 字段改为 "module",通过这种形式告知Node使用ES Module` 的形式加载模块。
23. CommonJS、AMD、CMD、UMD、ES6模块
由于commonJs是同步的,而浏览器需要同步加载服务器端的代码就需要耗时,所以浏览器会出现假死的状态,所以就出现了异步加载AMD(Async Model Definition, 异步模块定义)采用异步方式加载,模块的加载不影响后面代码的执行,AMD采用define()函数来定义模块,在另一文件中使用require函数来导入模块,两个函数第一个参数都是一个数组,第二个参数都采用了回调函数。AMD有个缺陷,必须要提前加载所有的依赖,所以提出了CMD实现了按需加载。
而CMD(Common Module Definition,公共模块定义)是按需加载,当在某一行代码前需要引入某个模块时再require(“”)加载进来。
UMD(Universal Model Definition,通用模块定义),比如你写了一段代码想要在浏览器端和服务器端同时使用。所以只用一个逻辑是不行的,所以可以通过if逻辑判断应该使用AMD还是CommonJS规范的方式来定义模块。
24. vue2和vue3的区别
-
数据的双向绑定底层原理不同
v-model底层实现区别
-
生命周期的不同
vue2中组件的相关销毁钩子函数是beforeDestroy以及Destroyed,在vue3中是采用在setup()函数里的onbeforeUmmount和onUnmounted()
-
vue3中支持TS
-
Vue2使用
选项类型API(Options API)对比Vue3合成型API(Composition API)
旧的选项型API在代码里分割了不同的属性:data,computed属性,methods,等等。新的合成型API能让我们用方法(function)来分割,它是为了实现基于函数的逻辑复用机制而产生的, 相比于旧的API使用属性来分组,这样代码会更加简便和整洁。
composition API:“ 以函数为载体,将业务相关的逻辑代码抽取到一起,整体打包对外提供相应能力,这就是 Composition API ”
现在我们来对比一下Vue2写法和Vue3写法在代码里面的区别。
Vue2 - 这里把两个数据放入data属性中
export default {
props: {
title: String
},
data () {
return {
username: '',
password: ''
}
}
}
在Vue3.0,我们就需要使用一个新的==setup()方法==,此方法在组件初始化构造的时候触发。相当于beforeCreate和Created()钩子函数。
为了可以让开发者对反应型数据有更多的控制,我们可以直接使用到 Vue3 的反应API(reactivity API)。
使用以下三步来建立反应性数据:
- 从vue引入
reactive - 使用
reactive()方法来声名我们的数据为反应性数据 - 使用
setup()方法来返回我们的反应性数据,从而我们的template可以获取这些反应性数据
上一波代码,让大家更容易理解是怎么实现的。
import { reactive } from 'vue'
export default {
props: {
title: String
},
setup () {
const state = reactive({
username: '',
password: ''
})
return { state }
}
}
这里构造的反应性数据就可以被template使用,可以通过state.username和state.password获得数据的值。
25. 手写vue2时的注意点
-
首先要实现除了数组以外的数据类型的数据的监听 observe()
-
实现数据代理,也就是将this._data.属性代理到vm实例上 proxy()
-
实现data中数组类型数据的监听,以及实现重写当数据为数组类型时的push、unshift、splice方法 observeArray()
-
数据的渲染
//数据渲染代码:
// 这个正则表达式是匹配{{}}中的数据
const defaultRE = /\{\{((?:.|\r?\n)+?)\}\}/g;
const util = {
getValue(vm, expr) {
// .分割主要是为了针对msg.name这种,因为直接vm[msg.name]是不正确的,只能进行递归找,这里采用reduce方法,先找到vm.msg,然后再vm.msg.name
let keys = expr.split(".")
return keys.reduce((memo, current) => {
memo = memo[current]
return memo
}, vm)
},
// 编译渲染文本的方法
compilerText(node, vm) {
// 返回匹配到的数据
// node.textContent为节点的文本数据
node.textContent = node.textContent.replace(defaultRE, function (...args) {
// 其中args为匹配到的node.textContent文本的数据元素数组
console.log(args);
// return vm[args[1]]
return util.getValue(vm, args[1])
})
}
}
function compiler(node, vm) {
// 取出子节点
let childNodes = node.childNodes;
// 将类数组转化为数组,比如arguments就是一个类数组
[...childNodes].forEach(child => {
// 此时就需要判断节点是否为元素节点还是文本节点,需要采用节点的nodeType这个属性来判断,为1则是元素节点,为3则是文本节点
if (child.nodeType === 1) {
// 为元素节点,那么就递归找其子节点,直到元素为文本元素才用textContent或innerText进行正则匹配{{}},匹配到元素后来进行渲染数据
compiler(child, vm)
} else if (child.nodeType === 3) {
// 为文本节点
util.compilerText(child, vm)
}
})
}
export { compiler, util }
-
依赖收集
Dep()类,//Dep相当于是发布者和订阅者之间的一个纽带,也可以认为Dep是服务于观察者Observer的订阅系统
// 相当于一个收集器,创建一个类来收集watcher
// 为data中的每一个属性都添加一个Dep,用来记录当前属性都有哪些observer有用到我。意思就是保存对于当前属性的观察者到订阅器中,然后当属性值改变时就会通知观察者
26.什么是MVVM
MVVM是一种前端的开发模式,是Model-View-ViewModel的简写。它本质上就是MVC 的改进版。MVVM 就是将视图 UI 和业务逻辑分开,通过VM视图模型进行数据的操作和渲染。其实Vue和react就是采用了MVVM开发的理念。
27.谈一下对于vue指令的理解, 如何封装一个指令
简单来说,vue指令就是为了实现某种特定功能比如按条件渲染、绑定属性等,而封装的一些指令,这样使用者就能够快速实现一些功能。
内置指令的使用
v-if:根据其后表达式的 bool 值进行判断是否渲染该元素
v-else:紧跟着v-if搭配使用
v-show:其后表达式的 bool 值为 false 时,对渲染的出标签添加display:none;的样式
v-for:v-for的用法: v-for="(item, index) in arr" ,类似于数组的用法,一般用:key来搭配v-for,key的值必须保证不同。key的作用:帮助vue区分不同的元素,提升vue的渲染性能。
v-bind:(:用于绑定某些属性,响应地更新 html 特性
v-on:(@):用于监听指定元素的 DOM 事件
v-once: v-once这个指令不需要任何表达式,它的作用就是定义它的元素或组件只会渲染一次,首次渲染后,不再随着数据的改变而重新渲染。也就是说使用v-once,那么该块都将被视为静态内容。
封装指令
DOCTYPE html>
<html lang="en">
<meta charset="utf-8">
<head>
<title>自定义指令title>
head>
<style type="text/css">
style>
<body>
<div id="app">
<input type="text" name="" v-focus="msg">
<input type="text" name="" v-color='msg'>
<input type="text" name="" v-background='msg1'>
<input type="text" name="" v-font="msg1">
div>
<script type="text/javascript" src="js/vue.js">script>
<script type="text/javascript">
/*
自定义指令:
Vue.directive()
*/
Vue.directive('focus', {
//加入inserted属性,指:被绑定元素插入父节点时调用(父节点存在即可调用,不必存在于 document 中)
inserted: function (el, binding) {
//el表示指令所绑定的元素
el.focus(); //focus()方法就是获取焦点
el.value = binding.value.color;// binding.value为自定义指令传的值,注意这里传入的值必须是data数据里面的值
}
});
//利用bind
Vue.directive('color', {
// bind属性,只调用一次,指令第一次绑定到元素时调用,用这个钩子函数可以定义一个在绑定时执行一次的初始化动作
bind: function (el, binding) {
el.style.color = binding.value.color; //binding为传入的绑定对象,binding.value的值为自定义指令的值
console.log(binding);
}
});
var vue = new Vue({
el: '#app',
data: {
msg: {
color: "orange"
},
msg1: {
backgroundColor: 'blue',
color: "red",
fontSize: "30px"
}
},
methods: {
},
//自定义局部指令
directives: {
background: function (el, bingding) {
el.style.backgroundColor = bingding.value.backgroundColor;
el.style.color = bingding.value.color
},
font: {
bind: function (el, bingding) {
el.style.fontSize = bingding.value.fontSize;
}
}
},
});
script>
body>
html>
28. computed计算属性和watch监听的区别
computed属性
首先computed计算属性是用于在HTML模板中表达式更加简洁,易维护。
特点:
-
computed具有缓存功能,当与computed变量相关的变量值不发生改变时,一直用的是缓存中的值,只有当依赖变量值发生改变时,computed计算属性值才会发生更新;
-
computed变量不在data中定义,而是在computed对象中定义;
DOCTYPE html>
<html lang="en">
<head>
<title>computed计算属性title>
<meta charset="utf-8">
head>
<body>
<div id="app">
<div>{{reverseString}}div>
<div>{{reverseString}}div>
div>
<script type="text/javascript" src="js/vue.js">script>
<script type="text/javascript">
var vue = new Vue({
el: '#app',
data: {
msg: 'wanghe',
msg1: 'baba'
},
methods: {},
//计算属性的用法
//计算属性是进行缓存了,而方法不存在缓存
computed: {
reverseString: function() {
console.log(this.msg);
return this.msg1.split('').reverse().join('');
},
}
});
script>
body>
html>
watch属性
特点:
-
watch监听属性监听的是data中已经存在的变量,只有当变量值发生改变时,会触发watch监听属性中的相应的方法。
-
当需要在数据变化时执行异步或开销较大的操作时,这时watch是非常有用的
-
watch只能监听简单数据类型,当监听对象、数组等复杂数据类型时,其中的元素值改变也不会触发watch中监听对象的方法。
-
但是可以采用深度监听来监听对象的变化,设置deep: true,就可以解决特点3的问题来监听某个对象的属性,但是当对象嵌套的属性太深时开销太大。
DOCTYPE html>
<html lang="en">
<meta charset="utf-8">
<head>
<title>侦听器title>
head>
<body>
<div id="app">
<div>
<span>名:span>
<span><input type="text" name="" v-model="lastname" @input="handle">span>
div>
<div>
<span>性:span>
<span><input type="text" name="" v-model="firstname" @input="handle">span>
div>
<div>
{{getFullname}}
div>
<div>{{obj}}div>
div>
<script type="text/javascript" src="js/vue.js">script>
<script type="text/javascript">
var vue = new Vue({
el: "#app",
data: {
fullname: '',
firstname: '',
lastname: '',
obj: {
name: "wh",
age: 23
}
},
methods: {
handle: function () {
this.fullname = this.firstname + this.lastname;
// 每次输入都让obj对象的age自增,对象的属性值的变化是不能触发obj监听方法的
this.obj.age++
// 注意!!!!!!!!只有当这个obj整个对象值改变时才会触发obj的watch监听方法
// this.obj = { mes: "值已经改变" }
},
},
//加入监听器,监听器会一直监听属性的变化,一旦变化,就会执行对应的方法
watch: {
//val表示firstname的当前的最新值,只要值发生变化就会触发这个方法
firstname: function (val) {
this.fullname = val + ' ' + this.lastname;
},
lastname: function (val) {
this.fullname = this.firstname + ' ' + val;
},
// 不采用深度监听不能够监听到对象属性值的改变
// obj: function (val) {
// console.log(val);
// },
// 采用深度监听来监听对象属性值的改变
obj: {
// handler为固定属性,不能改变名字
handler: function (val) {
console.log(oldval);
console.log(newVal);
},
// immediate: true代表在watch对象中声明了obj这个监听属性后会立即执行handler方法,在正常情况下只有当obj对象属性值改变时才会触发handler
immediate: true,
// 是否深度监听,默认值为false
deep: true
},
},
//添加计算属性实现
computed: {
getFullname: function () {
return this.firstname + this.lastname;
}
},
});
script>
body>
html>
29.vnode是什么,是如何渲染的
VNode是JavaScript对象。VNode表示Virtual DOM,用JavaScript对象来描述真实的DOM,把DOM标签(tag),属性(attrs),内容都变成对象的属性。
VNode的作用
主要就是将template模板描述成VNode,然后再对Vnode进行一些操作后(删除、更新节点)将更新后的真实dom进行挂载。
Vnode优点:
首先就是兼容性强,因为虚拟dom是一个js对象,所以不局限于所处的环境,不管是浏览器还是app都可以操作;
其次,相比对真实dom节点进行操作,对Vnode进行操作不需要频繁更新真实dom,只是将最后一步挂载更新dom,这样可以提高页面性能。
VNode如何生成
在Vue源码中,VNode是通过一个构造函数生成的。
export default class VNode {
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array<VNode>,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions,
asyncFactory?: Function
) {
this.tag = tag
this.data = data
this.children = children
this.text = text
this.elm = elm
this.ns = undefined
this.context = context
this.fnContext = undefined
this.fnOptions = undefined
this.fnScopeId = undefined
this.key = data && data.key
this.componentOptions = componentOptions
this.componentInstance = undefined
this.parent = undefined
this.raw = false
this.isStatic = false
this.isRootInsert = true
this.isComment = false
this.isCloned = false
this.isOnce = false
this.asyncFactory = asyncFactory
this.asyncMeta = undefined
this.isAsyncPlaceholder = false
}
}
将真实dom转化为Vnode对象:
// 模版
<a class="demo" style="color: red" href="#">
generator VNode
</a>
// VNode描述
{
tag: 'a',
data: {
calss: 'demo',
attrs: {
href: '#'
},
style: {
color: 'red'
}
},
children: ['generator VNode']
}
Vnode存放哪些信息
- data:存储节点的属性,绑定的事件等
- elm:真实DOM 节点
- context:渲染这个模板的上下文对象
- isStatic:是否是静态节点
…
VNode存放
在初始化完选项,解析完模板之后,就需要挂载DOM了。此时就需要生成VNode,才能根据 VNode生成DOM然后挂载。创建出来的VNode需要被存起来,主要存放在三个位置:parent,_vnode,$vnode。
30.谈一下keep-alive缓存组件的实现原理
keep-alive为组件缓存,当路由刷新的时候依然保持状态(一些变量值的大小等等)不会被改变。这里其实也就是在切换的时候,之前的页面没有被destroy销毁掉,而是缓存在了内存中,当再次返回到那个页面时直接从内存中拿到渲染出来就可以了。
31.如何在在vue项目中应用权限
32.在vue项目中去做导航守卫
33.说一下闭包
34.grid布局
35.做一个的与vue-cli相仿的脚手架项目
36.网站项目部署
(1)前言
将自己做的vue项目部署到服务器上,这里我采用的工具是Nginx,Nginx是一款轻量级的web服务器、反向代理服务器,由于它的内存占用小,启动快,高并发能力强,在互联网项目中广泛应用,本网站是部署到Nginx服务器上,当然也可以选用其他web服务器,这里我选择较为主流的Nginx。
可以把Nginx想象为一个中间商(中间件),我们把网站放到中间商上去,然后中间商把服务器运行起来,就可以把我们的网站用外网可以访问。
(2)服务器安装Nginx
查看服务器上是否有安装Nginx工具:
whereis nginx
出现nginx目录代表安装完成。
![]()
安装nginx:
yum install -y nginx
安装完成界面:
(3)启动nginx
启动nginx,命令·如下:
nginx
![]()
直接输入nginx即可启动服务,然后打开浏览器,访问服务器ip地址,页面出现不报错即代表启动成功。(注意只有打开nginx才能看到网页,nginx服务未打开则网页报错)
还有这里访问的是http默认端口80。
停止nginx服务,命令如下:
nginx -s stop
![]()
重启nginx服务,,命令如下:
nginx -s reload
(4)修改nginx配置
找到nginx配置文件存放位置,命令如下:
whearis nginx
![]()
此时目录/usr/sbin/nginx /usr/lib64/nginx /etc/nginx /usr/share/nginx就是nginx配置文件存放的位置。
cd到该目录下并ll查看文件:其中nginx.conf则是默认配置文件
然后用vim编辑nginx.conf配置文件,命令如下:
vim nginx.conf
进入配置文件之后按i进入输入模式进行修改文件,按esc退出输入模式进入命令模式,然后输入:wq退出文件。
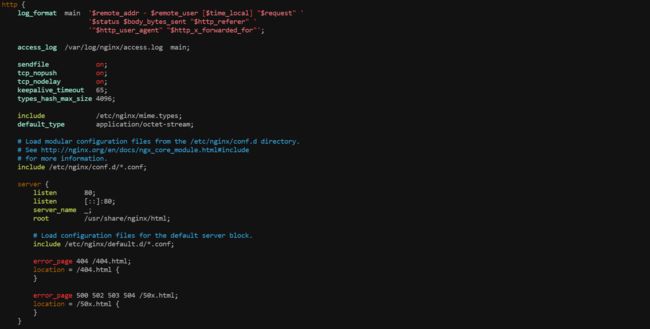
其中server对象中的listen是默认的监听端口号80;
其中server.root是用于存放显示的网页,我们需要把vue项目打包输出的dist目录下的网页存放在此目录下,那么之后再在浏览器中输入ip地址后显示的就是我们存放的网页了。
这里我设置了新的存放网页的路径为:/home/www/dist
![]()
(5)新建网站文件夹
刚刚我设置了网站存放的文件夹路径为:
/home/www/dist
此时我们就需要在服务器上新建www文件夹:
cd /home
mkdir www
![]()
我们没有新建dist文件夹,因为我们待会儿vue项目打包就会生成dist文件夹,直接上传即可。
(6)打包部署vue项目
现在就可以把我们的vue项目build之后生成dist目录下的打包输出文件放到我们的nginx.conf的root目录下了(即部署)。
(1)打包网站
使用vue打包命令生成dist文件夹:
npm run biuld
(2)上传至服务器
我们使用ftp工具将dist文件夹上的文件上传至/home/www目录下,当然也可以使用命令:
scp -r dist/ root@ip地址: 路径
scp -r dist/ [email protected]:/home/www

此时就可以在外网访问自己做的vue项目了。
留下自己做的vue项目后台管理系统(其实用了微前端技术,然后再部署一个子项目太麻烦了,就把子项目给关了,最后呈现的就是只有主项目)。
网站地址(还没买域名):http://101.43.163.169/。
github源码地址,麻烦star一下xdm:https://github.com/Wanghe0428/vue-manager
之前做项目时后台接口关了,所以后台ajax请求不到数据,不能登录,也挺无语的(做项目的时候跟着b站上的up做的,现在他把后台写的接口全关了我吐了!)。
(7)解决刷新路由404问题
当我们切换路由时,然后再刷新页面就会出现404问题。

这是因为我的vue项目是采用了history路由模式,又因为vue是单页面应用,一旦切换路由之后,之前的页面就会不存在,然后你再刷新回到之前的页面就会出现404了。(个人理解)
解决的方法:
- 将路由模式修改为hash模式(不建议,hash模式#太丑)
- 修改nginx配置
location / {
try_files $uri $uri/ /index.html; //解决页面刷新404问题
}

到此问题解决!