机器学习实战——感知机
-
- 感知机
- 学习策略
- 具体实现
- 数据集最大最小规范化
- 训练过程
- 测试
- 最终结果
感知机是二分类的线性分类模型,由Rosenblatt于1957年提出,是支持向量机和神经网络的基础。感知机将学习到一个线性划分的分离超平面,属于判别模型。
感知机
输入空间为 Rn 空间, n 是特征数目,输出空间y={+1,−1}。感知机学习一个如下的符号函数:
f(x)=sign(wx+b)
作为模型的判别函数, w 和 b 为模型的权值和偏置。对于超平面 wx+b=0 , w 是其法向量,b 是截距,这个超平面将特征空间完全正确划分为两个部分。从几何上很容以看出对于线性可分的特征空间存在多个这样的超平面,因为不像 SVM中限制寻找最优分割超平面,故感知机模型对初始点的选取和每次迭代过程中选取的错分样板点都有很大关系,鲁棒性不是太好。但是,由于其实现简单方便,对于简单分类问题是很有容易求解的,同时也是后来发展的SVM和神经网络算法的基础,因此依然需要关注。
学习策略
损失函数使用的是错分类点到分类超平面S的总距离,任意一点x到超平面的距离使用如下公式计算:
1||w|||wx+b|
当分类错误时, yi 与 wxi+b 的乘积是小于零的,而 yi 的取值范围为 {+1,−1} ,故得到任一点到超平面的距离如下:
−1||w||yi(wxi+b)
不考虑 ||w|| 时,就可以得到感知机学习的损失函数如下(设错分类点的集合为M):
L(w,b)=∑xi∈M−yi(wxi+b)
该损失函数是经验损失函数,对于一个特定样板点的损失函数,分别是参数 w 和b 的线性函数,因此是连续可导的,使用随机梯度下降方法进行优化即可,梯度由如下公式给出:
∇wL(w,b)=−∑xi∈Myixi
∇bL(w,b)=−∑xi∈Myi
随机选取一个错分类点 (xi,yi) ,对损失函数的w和b进行更新:
w←w+δyixi
b←b+δyi
其中的 δ 是学习速率或者步长,用来控制学习的速度和迭代的步骤。
上述方法的解释如下:当一样本点被分类错误后,则要调整w和b的值,使得错分点里超平面的距离减小,知道所有错分类点都被正确分类。
具体实现
使用的是同样的一个垃圾邮件分类的数据,与另一篇博客KNN分类算法使用的是一个数据集。使用python实现了上述算法,并绘制了不同步长下训练集的错分率和测试集的正确率。
由于该实际数据集并不是线性可分的,因此使用了折中办法,寻找训练集错分率最小的步长和对应的模型,并对测试集进行测试找出正确率最大的步长和模型,二者综合获取最终的模型,同时还加入了最大迭代次数的限制,默认设置为500次。
数据集最大最小规范化
def normalize(ds):
minVals = ds.min(0)
###get an array of minimum element of each column
maxVals = ds.max(0)
ranges = maxVals - minVals
normDS = zeros(shape(ds))
n = ds.shape[0]
normDS = ds - tile(minVals, (n, 1))
##tile an array in to a n*1 matrix
normDS = normDS / tile(ranges, (n, 1))
return normDS训练过程
def percepTrain(ds, labels, stepLen = 1, maxSteps=500, err=5):
'''Don't use the completely linear seperation
but a maximum steps and error control'''
i = 0
minErrDotLen = TRAINSET_NUM + 1
params = []
w = zeros(ds.shape[1]); b = 0
while i < maxSteps:
model = labels * (dot(ds, w) + b)
iLess = model[model <= 0]
if len(iLess) < minErrDotLen:
minErrDotLen = len(iLess)
params = [w, b]
if len(iLess) <= int(TRAINSET_NUM*err/100):
### When the error classification ratio is less than err, break
break
x = ds[int(iLess[0]), :]
y = labels[int(iLess[0])]
w = w + stepLen * y * x
b = b + stepLen * y
i += 1
return params, minErrDotLen, i测试
def percepClassify(model, predict):
w,b = model
py = zeros(predict.shape[0])
py[dot(predict, w) + b > 0] += 1
return py*2 - 1最终结果
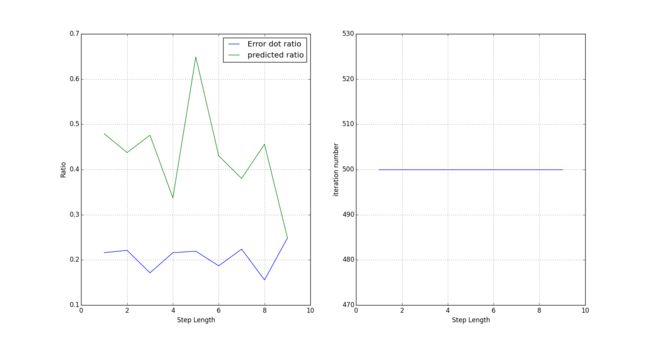
从图中可以看出当迭代步长为5时,虽然训练集的错分率不是最低,有20%多,但是测试集的准确率确是最好的,因此应该选择步长为5的对应的模型。