ImVoteNet:利用图像特征增强点云中的三维物体检测——文献总结
CVPR2020的一篇文章《ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes》,点击下载原pdf,在我上传的资源中。

文献正文:
摘要:
得益于点云深度学习的进步,3D物体检测已经取得了快速进展。最近的一些作品甚至展示了仅使用点云输入的最先进的性能(例如votenet)。然而,点云数据有其固有的局限性。它们是稀疏的,缺乏颜色信息,经常受到传感器噪声的影响。另一方面,图像具有高分辨率和丰富的纹理。因此,它们可以补充点云提供的三维几何。然而,如何有效地利用图像信息辅助基于点云的检测仍然是一个有待解决的问题。在这项工作中,我们建立在votenet的基础上,并提出了一个名为imvotenet的专门用于rgb - d场景的3D检测体系结构。imvotentis基于融合图像中的2D投票和点云中的3D投票。与以往的多模态检测方法相比,我们明确地从二维图像中提取几何特征和语义特征。我们利用摄像机参数将这些功能提升到3D。为了提高二维-三维特征融合的协同性,我们还提出了一种多塔训练方案。我们在具有挑战性的SUN RGB-D数据集上验证了我们的模型,通过5.7 map推进了最先进的结果。我们还提供了丰富的消融研究,以分析每个设计选择的贡献。
1、介绍
VoteNet已经可以实现把点云作为唯一输入的直接检测方法,但仅仅是点云无法满足3D检测的需求。
图像和点云提供了互补的信息,rgba图像比深度图像或激光雷达点云具有更高的分辨率,并包含丰富的纹理,这在点域是不可用的。此外,图像可以覆盖主动深度传感器的“盲区”,这是由于反射表面经常发生的。另一方面,图像在三维检测任务中受到限制,因为它们缺乏物体深度和尺度的绝对度量,而这正是三维点云可以提供的。这些观察增强了我们的直觉,即图像可以帮助基于云的3D检测。
前人的解决方法
如何在三维检测管道中有效地利用二维图像仍然是一个悬而未决的问题。原始的方法是直接将原始RGB值附加到点云,因为可以通过投影建立点像素对应关系,但由于3D点更稀疏,这样做我们将失去图像域的密集模式。于是有了pointnet类似的网络,使用成熟的2D探测器以截锥的形式提供初点云的筛选,但这限制了估计3D边界框的3D搜索空间,由于它的级联设计,它在初始检测中不利用3D点云,特别是,如果一个物体在2D中丢失了,那么它在3D中也会丢失。于是另一项工作]采用了一种更专注于3D的方法,将二维图像的中间ConvNet特征连接到3D体素或点,以丰富3D特征,然后再将它们用于对象建议和框回归。这种系统的缺点是,它们不直接使用2D图像进行定位,定位可以为在3D中检测物体提供有益的指导。
作者的工作
在我们的工作中,我们在votenet[33]架构的基础上,设计了一个名为IMVOTENET的联合2d -3D对象检测投票方案。利用了更成熟的2D探测器,但同时仍然保留了从全点云本身提出对象的能力——结合了两种工作方式的优点,同时避免了各自的缺点。我们设计的一个动机是在2D图像中利用几何和语义/纹理线索。几何线索来自图像中精确的2D边界框,比如2D检测器的输出。我们将对象提议过程推迟到3D,而不是仅仅依赖于2D检测对象提议。给定一个2D框,我们在图像空间上生成2D投票,其中每个投票从对象像素连接到2D模态框中心。将二维选票传递到三维,通过基于相机固有深度和像素深度的几何变换对二维选票进行提升,生成“伪”三维选票。这些伪3D投票成为附加到对象提议的3D种子点上的额外功能。除了来自2D投票的几何线索,每个像素还将语义和纹理线索传递给3D点,作为每个区域提取的特征或每个像素提取的特征。
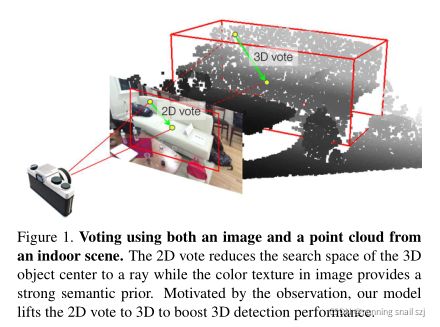
如上图:使用图像和来自室内场景的点云。二维投票将三维物体中心的搜索空间缩小为一条射线,而图像中的颜色纹理提供了很强的语义优先性。在观察的推动下,我们的模型将2D投票提升到3D,以提高3D检测性能。
在将图像中的所有特征提升并传递到3D后,我们将它们与点云骨干网络中的3D点特征连接起来。接下来遵循VoteNet的方式,这些融合了2D和3D的点信息,不受2D方框的限制,面向所有的物体中心,得出最终的三维目标检测。
此外,我们认识到,当融合2D和3D源时,必须小心地平衡两种模式的信息,以避免一种被另一种控制。为此,我们进一步引入了具有梯度混合[49]的多塔网络结构,以确保我们的网络充分利用了2D和3D特性。在测试过程中,仅使用在接头2D-3D特征上运行的主塔,从而最大限度地降低效率损失。(During testing, only the main tower that operates on the joint 2D-3D features are used, minimizing the sacrifice on efficiency.)
To summarize, the contributions of our work are:(工作总结)
- A geometrically principled way to fuse 2D object de-
tection cues into a point cloud based 3D detection
pipeline.(一种基于几何原理的方法,将二维物体检测线索融合到基于点云的三维检测管道中) - The designed deep network IMVOTENETachieves
state-of-the-art 3D object detection performance on
SUN RGB-D. - Extensive analysis and visualization to understand var-
ious design choices of the system.
2、Related Work(前人相关工作)
最相关的工作是通过RGB-D数据进行的点云检测,也进行了在多模态数据融合领域的一些额外的相关工作。
3D object detection with point clouds(基于点云的三维目标检测)
PointRCNN和 Deep Hough V oting (VOTENET) 它们分别展示了最先进的室外和室内场景3D物体检测技术。值得注意的是,这些结果是不使用theRGBinput实现的。
3D object detection with RGB-D data(基于RGB-D数据的三维目标检测)
深度和颜色通道都包含对3D物体检测有用的有用信息。先前融合这两种模式的方法大致可分为三类:2D驱动、3D驱动、功能连接:
2D驱动:首先在2D图像中检测目标,然后在3D中使用目标来引导搜索空间。
**3D驱动:在3D驱动中,我们指的是先在3D中生成区域建议,然后利用2D特征功能连接:**进行预测的方法,如Deep Sliding Shapes。最近更多的工作集中在融合2D和3D功能的早期过程中,如多模态Voxelnet ,A VOD,多传感器和3D- SIS。
而这些大多是通过2D特征与3D特征的拼接来进行融合。ImVoteNet提出的方法与第三种类型更密切相关,但在两个重要方面与之不同。首先,ImVoteNet提出明确使用来自2D检测器的几何线索,并以伪3D投票的形式将其提升到3D。其次,ImVoteNet使用多塔架构来平衡两种模式的特征,而不是简单地训练串联的特征。
Multi-modal fusion in learning(学习中的多模态融合)
如何融合来自多种模式的信号,是三维物体检测以外的一个开放的研究问题。三维场景的语义分割通常同时使用RGB和深度数据。
多模态的研究领域有两个比较火热。一是视觉和语言研究开发了一种方法,可以对视觉数据和文本进行联合推理,从而完成视觉问答等任务。二是视频+声音,其中附加的声道既可以提供监督信号,也可以提出有趣的任务来测试对两个流的联合理解。
3、 ImVoteNet Architecture(ImVoteNet框架)
如图为总结:
用于IMVOTENET的3D物体检测管道。给定rgb - dinput(将深度图像转换为点云),模型最初有两个独立的分支:一个用于图像上的2D目标检测,另一个用于点云上的点云特征提取(使用PointNet++[36]骨干)。然后我们将2D图像的投票以及语义和纹理线索提取到3D种子点(融合部分)。然后,将图像和点云特征连接起来的种子点生成指向三维物体中心的投票,并提出具有其特征的三维包围盒(联合塔)。为了推动更有效的多模态融合,我们还有另外两个塔,它们只采用图像特征(图像塔)和点云特征(点塔),用于投票和框式提案。
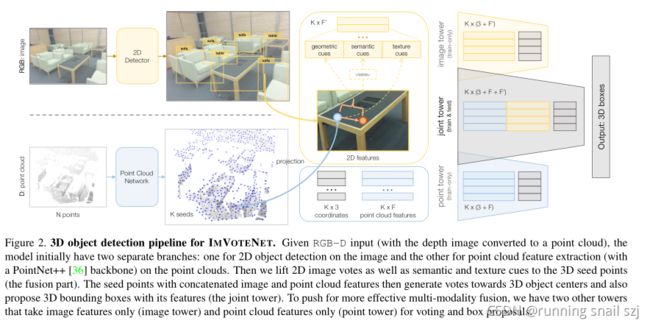 .在对原始VOTENET渠道进行简短总结后,我们将描述如何在RGB上的2D检测器的帮助下构建“2D投票”,并解释如何将2D信息提升为3D并传递到点云以改进3D投票和提案。最后,我们描述了用梯度混合融合二维和三维检测的多塔体系结构。在附录中提供了更多的实现细节。
.在对原始VOTENET渠道进行简短总结后,我们将描述如何在RGB上的2D检测器的帮助下构建“2D投票”,并解释如何将2D信息提升为3D并传递到点云以改进3D投票和提案。最后,我们描述了用梯度混合融合二维和三维检测的多塔体系结构。在附录中提供了更多的实现细节。
3.1 Deep Hough Voting(深度霍夫投票)
VOTENET是一个前馈网络,使用3D点云并输出用于3D目标检测的目标建议。
受广义霍夫变换[3]开创性工作的启发,votenet提出了一种对象检测的投票机制适应于完全可微分的深度学习框架。每一个投票都是三维空间中的一个点,其欧几里得坐标(3dim)被监督接近目标中心,同时也是为最终检测任务学习的特征向量(F-dim)。这些投票在目标中心附近形成聚类点云,然后由另一个点云网络处理,生成目标建议和分类分数。这个过程相当于上图中的管道,只有点塔,没有图像检测和融合。
votenet最近在室内三维物体检测方面取得了最先进的成果。然而,它完全基于点云输入,忽略了图像通道,正如我们在本工作中显示的,这是一个非常有用的信息来源。在IMVOTENET中,我们利用了额外的图像信息,并提出了从2D投票到3D的提升模块,以提高检测性能。接下来,我们将解释如何在图像中获得2D投票,以及如何将其几何线索与语义/纹理线索一起提升到3D。
3.2. Image V otes from 2D Detection
为了形成给定rgbimage的盒子集,我们应用了现成的2D检测器(如Faster R-CNN),对theRGB-Ddataset的颜色通道进行了预先训练。检测器输出最可靠的边界框和它们对应的类。我们将检测框内的每个像素分配给框中心一个投票。多个框内的像素被给予多次投票(每个框都复制相应的3D种子点),任何框外的像素都用零填充。接下来,我们将详细讨论如何推导几何、语义和纹理线索。
Geometric cues: lifting image votes to 3D(将图像提升为3D).
二维平移投票为三维物体定位提供了有用的几何线索。给定摄像机矩阵,图像平面上的二维物体中心成为连接三维物体中心和摄像机光学中心的三维空间射线。将该信息添加到种子点可以有效地将目标中心的3D搜索空间缩小到1D。
