【动手学深度学习PyTorch版】17 深度卷积神经网络 AlexNet
上一篇请移步【动手学深度学习PyTorch版】16 经典卷积神经网络 LeNet_水w的博客-CSDN博客
目录
一、深度卷积神经网络 AlexNet
1.1 核方法
1.2 发展
◼ 特征工程
◼ 数据和算力不同阶段的发展程度
1.3 AlexNet
◼ ImageNet
◼ AlexNet
1.3.1 AlexNet架构与LeNet比较
1.3.2 AlexNet与LeNet的区别
1.3.2 AlexNet的每层
第四层:
1.3.3 复杂度
1.3.4 总结
三、AlexNet网络的代码实现
3.1 AlexNet网络(使用自定义)
一、深度卷积神经网络 AlexNet
1.1 核方法

首先提取特征,这里有一个关键是利用核函数来计算相关性,就会变成凸优化问题。所以有很好的数学定理。
这也就是为什么核方法可以替代掉当年的神经网络,成为机器学习当时主流的网络。
现在SVM还是被广泛使用,因为它不需要调参。
1.2 发展
◼ 特征工程
卷积神经网络,2D,通常被用在计算机视觉,也就是图片上。

在10年前或者15年前,计算机视觉最重要的是特征工程,怎么样进行特征提取?就是对一张图片怎么去抽取特征。我们之前是直接把图片的原始像素拿进我们的模型。
但是实际上,直接把图片的原始像素拿进SVM模型,效果会非常差。
如果特征工程抽取的比较好的话,那么之后就会是一个简单的多分类模型。
◼ 数据和算力不同阶段的发展程度
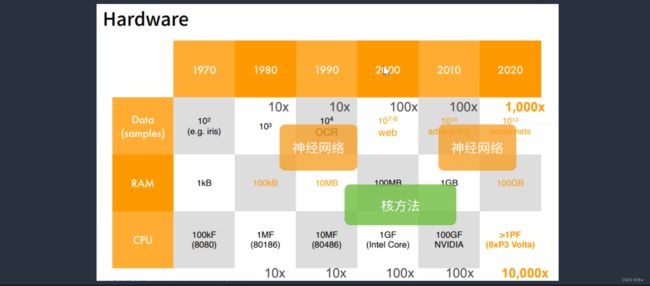
最近10年,因为GPU的兴起,导致计算比数据增加更快。由于计算和数据的增长速率不同,导致了各种各样模型的出现。
在90年代的时候,数据不够大, 计算也还行,比较均匀的情况下,大家比较喜欢用神经网络。因为神经网络是一个相对便宜的网络。
到了2000左右的时候,内存和cpu也不错,数据规模有增加,核方法是一个比较合适的方法,因为第一它有理论,第二它简单,第三是我们能够跑它。在这情况下,计算核矩阵是比较好的。
现在来说,我们又回到了神经网络,是因为我的计算量比以前更大了,计算比数据增加更快,我可以构造更深的神经网络,用计算来换取精度。
1.3 AlexNet
◼ ImageNet
首先,数据是一个非常重要的事情。
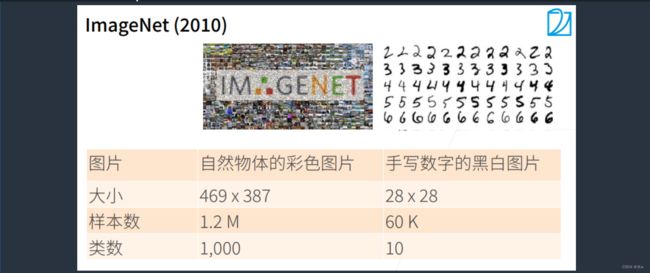
首先图片上来说,不只是做简单的黑白图片数字识别了,而是做一个自然物体的彩色图片,平均的大小是469X387。其次,样本数也挺大,有1.2M个样本,1000个类别。
因为有这么大的数据集,所以运行使用更深的神经网络来抽取里面更复杂的信息。
◼ AlexNet
AlexNet网络,是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。在那年之后,更多的更深的神经网路被提出,比如优秀的vgg,GoogleLeNet。其官方提供的数据模型,准确率达到57.1%,top 1-5 达到80.2%.。分类准确率由传统的 70%+提升到 80%+。这项对于传统的机器学习分类算法而言,已经相当的出色。也是在那年之后,深度学习开始迅速发展。
AlexNet本身是一个更深更大的LeNet。

AlexNet创新点:
- 成功应用ReLU激活函数(所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快) ;
- 成功使用Dropout机制(使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合);
- 使用了重叠最大池化(Max Pooling)(目前较少使用);
- 使用LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率(局部响应归一化)(目前较少使用,以BN为主);
- 在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模(目前训练使用较少);
- 使用了数据增强策略(Data Augmentation)缓和过拟合问题;
- 平移和翻转;
- 使用了PCA对RGB像素降维的方式;
1.3.1 AlexNet架构与LeNet比较
(1)第一层:卷积层
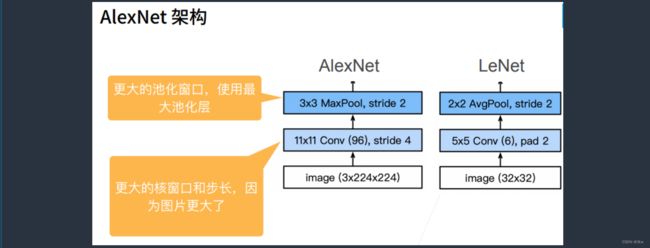
AlexNet的rgb的图片输入进来是224×224×3,而LeNet输入进来是32×32×1,channel数为1,是灰度图。
LeNet的第一层卷积的卷积核大小为5*5,而AlexNet用了一个更大的核窗口11X11,这是因为图片更大了,那么一个5*5的窗口看到的信息就变少了,因此AlexNet需要一个更大的窗口去看更多的信息。
AlexNet的通道数从6变成了96,用了比较大的通道数就是说图片里更多的模式想在第一层就尝试识别。stride为4,是因为如果stride不够大,相对来说后面的计算就会变得特别难。
(2)第二层:池化层
相对于LeNet,AlexNet用的3X3的池化层,两个的步幅都是2,步幅等于2将高宽减半。如果说LeNet的第二层2X2的池化层允许像素往右一点点偏移不会影响输出,那么AlexNet用的3X3的池化层,就相当于允许像素往右一点点偏移并且往左一点点偏移,也不会影响输出。
另外,LeNet用的是AvgPooling,而AlexNet用的是MaxPooling最大池化。
(3)第二层之后:
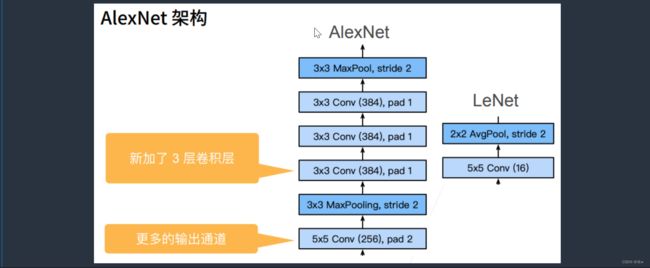
LeNet在第二层池化层之后,接了一个5X5卷积层,通道数16,同样跟着一个AvgPooling均值的池化层。
而AlexNet是在第二层池化层之后,也是接了一个5X5卷积层,pad=2使得输入和输出的尺寸相同,输出通道数由LeNet的16变成了256,用了比LeNet更大的输出通道,是因为我觉得我应该去识别那更多的模式。接下来跟着一个MaxPooling最大池化层,步幅等于2将高宽减半。
接下来,AlexNet又比LeNet新加了三个卷积层, 连续3个3X3的通道数为384的卷积层放在一起,最后再做一个池化层。
(4)最后:全连接层
LeNet是使用2个隐藏层,再到softmax做回归。第一个隐藏层大小是120,第二个隐藏层是84,最后是10做输出。
AlexNet与LeNet是一样的,也用了2个隐藏层,但是隐藏层的大小不同,变成了4096。第一个隐藏层大小是4096,第二个隐藏层是4096,最后是1000做输出。
(5)更多细节:

数据增强:对一幅图片进行截取,亮度、色温等进行改变,增加训练数据,可以减小卷积神经网络对图片位置、颜色等信息的敏感性。
1.3.2 AlexNet与LeNet的区别
第一:模型构造不同
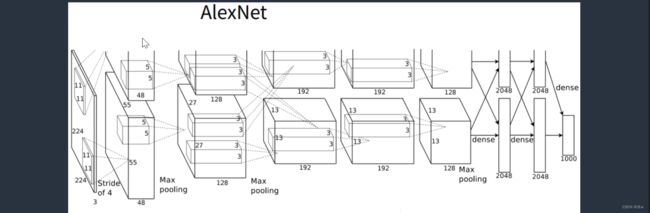
AlexNet与LeNet(指较小的卷积神经网络)在构造上有不同,AlexNet网络包含8层,其中包括5层卷积和2层全连接隐藏层,以及1个全连接输出层,其中
第一卷积层使用的 Kernel为11*11, 后接3*3 步幅为2的 池化层;
第二卷积层使用的 Kernel为5*5,后接3*3 步幅为2的池化层;
第三卷积层使用的 Kernel为3*3,直接与第四层相连;
第四卷积层使用的 Kernel为3*3,直接与第五层相连;
第五卷积层使用的 Kernel为3*3,后接3*3 步幅为2的池化层;
接下来,卷积部分结束后,其后紧跟两个输出均为4096的全连接隐藏层,最后为1个全连接输出层。
其结构图如下图所示:
第二:激活函数的改变
传统的LeNet网络使用的是sigmoid激活函数,而AlexNet使用的是ReLU函数。
ReLU函数比sigmoid函数计算上更为简单(不用求幂运算),且ReLU函数在不同的参数初始化方法下可以让模型更容易训练。
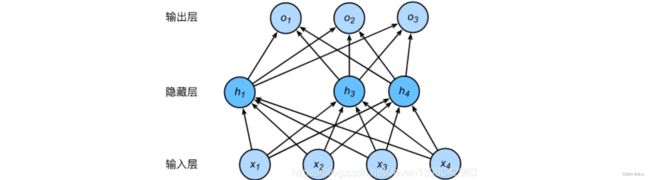
第三:AlexNet使用丢弃法来控制全连接层的模型复杂程度
丢弃法是深度模型中常用来应对过拟合问题的方法之一,其具体操作核心就是随机的丢弃某些层中(一般是中间层)的某些神经元,以此来降低后一层在计算中对上一层(随机丢弃的层)的过度依赖,起到正则化的作用(所谓正则化是指:在学习中降低模型复杂度和不稳定程度,是为了避免过拟合),但要注意的是丢弃法只在训练模型时使用。下图为使用了丢弃法的由两层全连接层构成的二层网络的结构,该网络中隐藏层的神经元随机丢失。
第四:AlexNet中引入了图像增广
AlexNet中引入了图像增广,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。所谓的图像增广指的是:该技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模;其另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力(样本数据的适应能力)。
1.3.2 AlexNet的每层
第一层:
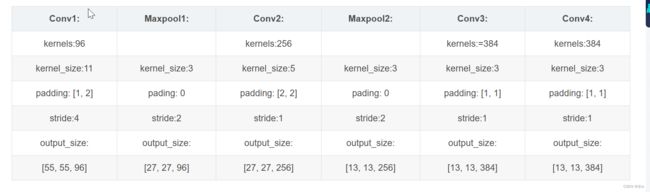
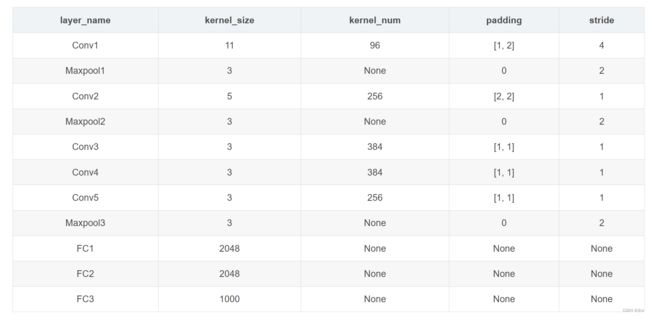
卷积层1,输入为 224×224×3,经过验算,原文应该有误,正确图像尺寸为 227×227×3的图像,卷积核的数量为96,论文中两片GPU分别计算48个核; 卷积核的大小为 11×11×3; stride = 4, stride表示的是步长,pad = 0, 表示不扩充边缘;
卷积后的图形大小是怎样的呢?
wide = (227 + 2 * padding - kernel_size) / stride + 1 = 55
height = (227 + 2 * padding - kernel_size) / stride + 1 = 55
dimention = 96
然后进行 (Local Response Normalized), 后面跟着池化pool_size = (3, 3), stride = 2, pad = 0 最终获得第一层卷积的feature map
最终第一层卷积的输出为2727128*2。
第二层:
卷积层2, 输入为上一层卷积的feature map, 卷积的个数为256个,论文中的两个GPU分别有128个卷积核。卷积核的大小为:5×5×48 ; pad = 2, stride = 1; 然后做 LRN,最后 max_pooling, pool_size = (3, 3), stride = 2;
第三层:
卷积3, 输入为第二层的输出,卷积核个数为384, kernel_size = (3×3×256 563×3×256), padding = 1, 第三层没有做LRN和Pool
第四层:
卷积4, 输入为第三层的输出,卷积核个数为384, kernel_size = (3×3 3), padding = 1, 和第三层一样,没有LRN和Pool
第五层:
卷积5, 输入为第四层的输出,卷积核个数为256, kernel_size = (3×3 3), padding = 1。然后直接进行max_pooling, pool_size = (3, 3), stride = 2;
第6,7,8层:
第6,7,8层是全连接层,每一层的神经元的个数为4096,最终输出softmax为1000,因为上面介绍过,ImageNet这个比赛的分类个数为1000。全连接层中使用了RELU和Dropout。
1.3.3 复杂度
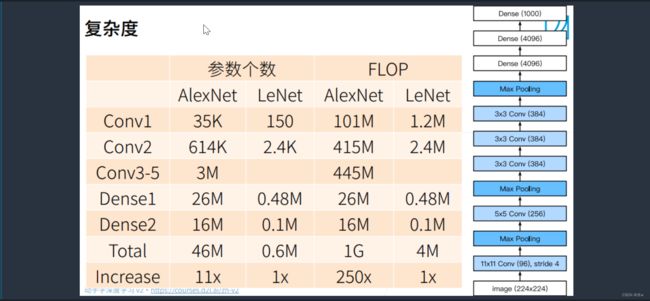
LeNet确实是不大的,而AlexNet从150直接变成了35K,架构比较大, 有46M个可以学习的参数,需要10亿(1G)计算。
1.3.4 总结

增加了三个卷积层和一个池化层,能更好的提取特征,更深
隐藏层(全连接层)的节点数变多,更胖
三、AlexNet网络的代码实现
3.1 AlexNet网络(使用自定义)
AlexNet与LeNet没什么区别,
# 深度卷积神经网络 (AlexNet)
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 数据集为fashion_mnist图片,所以输入通道为1,如果是Imagnet图片,则通道数应为3。激活函数为ReLU
nn.Conv2d(1,96,kernel_size=11,stride=4,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2), # 最大池化层
nn.Conv2d(96,256,kernel_size=5,padding=2),nn.ReLU(), # 卷积层:输入通道为96,输出通道数256
nn.MaxPool2d(kernel_size=3,stride=2), # 最大池化层
# 三个卷积层
nn.Conv2d(256,384,kernel_size=3,padding=1),nn.ReLU(), # 卷积层:输入通道为256,输出通道数384
nn.Conv2d(384,384,kernel_size=3,padding=1),nn.ReLU(), # 卷积层:输入通道为384,输出通道数384
nn.Conv2d(384,256,kernel_size=3,padding=1),nn.ReLU(), # 卷积层:输入通道为384,输出通道数256
nn.MaxPool2d(kernel_size=3,stride=2),nn.Flatten(), # 最大池化层
nn.Linear(6400,4096),nn.ReLU(),nn.Dropout(p=0.5), # 全连接层:隐藏层大小是4096,丢弃率为0.5(50%把输出置为0)
nn.Linear(4096,4096),nn.ReLU(),nn.Dropout(p=0.5), # 全连接层:隐藏层大小是4096,丢弃率为0.5(50%把输出置为0)
nn.Linear(4096,10)) # 输出层:使用小数据集fashion_mnist,所以大小是10。我们可以看一下每一层的输出形状,
X = torch.randn(1,1,224,224)
for layer in net:
X = layer(X) #
print(layer.__class__.__name__,'Output shape:\t', X.shape) 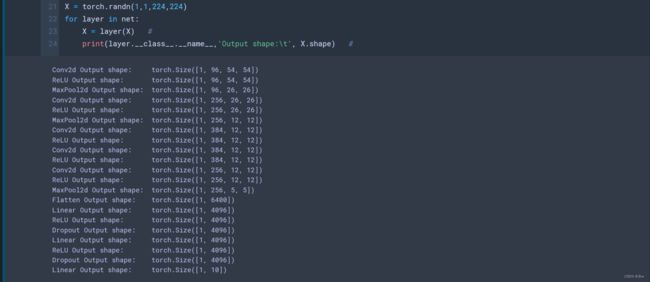
接下来,就是训练了,
# Fashion-MNIST图像的分辨率28X28,低于ImageNet图像。为了满足AlexNet模型的需求,将它们拉到224×224。
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
lr, num_epochs = 0.01, 10 # 迭代10次,学习率很低为0.01
d2l.train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())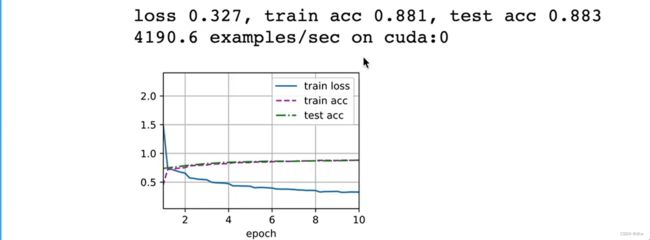
LeNet的测试精度是0.82,,现在AlexNet的精度有提升,测试精度为0.88。
没有太多的过拟合,是因为训练模型的时候设置的学习率很低为0.01,而且只迭代10次,没有跑很多次数据。
代价是LeNet的训练速度大概是9万,现在AlexNet的训练速度大概是4000,大概慢了20倍。是因为AlexNet的批量大小很小, 卷积也很小,它的并行度很差,根本无法用上gpu上的上千个核。
所以AlexNet相对来说会好一点,但后面的网络会更加适合gpu的计算。