论文超详细精读|八千字:DGNN
文章目录
- 前言
- 总览
- 一、Introduction
-
- 背景
- 问题解决过程
- 主要贡献
- 二、Related work
-
- 2.1 Skeleton-based action recognition(骨架动作识别)
- 2.2 Graph networks(图网络)
- 三、Method
-
- 3.1 Bone Information(骨骼信息)
- 3.2 Graph Construction(图的构建)
- 3.3 Directed graph neural network(有向图神经网络)
-
- 如何表示局部和全局信息?
- 3.3.1 Directed graph network block(有向图网络块)
- 3.3.2 Implementation of the DGN block(DGN区块的实施)
- 3.3.3 Adaptive DGN block(自适应DGN块)
- 3.3.4 Temporal information modeling(时态信息建模)
-
- 网络框架:
- 3.3.5 Two-Stream Framework(双流框架)
前言
笔者从人工智能小白的角度,力求能够从原文中解析出最高效率的知识。
之前看了很多博客去学习AI,但发现虽然有时候会感觉很省时间,但到了复现的时候就会傻眼,因为太多实现的细节没有提及。而且博客具有很强的主观性,因此我建议还是搭配原文来看。
请下载原文《Skeleton-Based Action Recognition with Directed Graph Neural Networks》搭配阅读本文,会更高效哦!
总览
首先,看完标题《Skeleton-Based Action Recognition with Directed Graph Neural Networks》,摘要和结论,我了解到了以下信息:
1.DGNN有向图神经网络:基于自然人体关节和骨骼之间的运动依赖性,将骨骼数据表示为有向无环图(DAG)。设计了一种新的有向图神经网络,用于提取关节、骨骼及其关系的信息,并根据提取的特征进行预测。
2.图拓扑的自适应:为了更好地拟合动作识别任务,在训练过程的基础上对图的拓扑结构进行了自适应处理,取得了显著的改进。
3.利用骨架序列的运动信息与空间信息相结合,进一步提高了双流框架的性能。
一、Introduction
背景
1.三种方法下,关节坐标表示:
- 递归神经网络(RNNs):向量序列
- 卷积神经网络(CNNs):伪图像
- 图卷积网络(GCNs):图
2.骨骼方向和长度信息的重要性:代表骨骼方向和长度的骨骼信息是直观的,因为我们人类会很自然地根据人体骨骼的方向和位置来评估行动,而不是关节的位置。
3.关节和骨骼信息相辅相成:将两者结合可以进一步提高识别性能。对于自然的人体来说,关节和骨头是强耦合的,每个关节(骨头)的位置实际上是由它们相连的骨头(关节)决定的。例如肘关节的位置取决于上臂骨的位置,上臂骨的位置同时也决定了前臂骨的位置。现有的基于图的方法通常将骨骼表示为无向图,用两个独立的网络对骨骼和关节建模,不能充分利用关节和骨骼之间的依赖性。
问题解决过程
1.解决关节和骨骼之间依赖性的问题:作者将骨架表示为一个有向无环图,其中关节为顶点,骨骼为边,关节和骨骼之间的依赖关系可以很容易地通过图的有向边建模。在此基础上,设计了一种新颖的有向图神经网络(DGNN)对所构建的有向图进行建模,该有向图可以在相邻关节和骨骼中传播信息,并在每一层更新相关信息。最终提取的特征不仅包含了每个关节和骨骼的信息,还包含了它们之间的依赖关系,便于动作识别。
2.解决原本固定的图关系:原来的骨架是根据人体的结构手工设计的,可能并不适合动作识别任务。例如,双手在鼓掌、拥抱等动作类中有很强的依赖性,但在基于人体结构构建的图中不存在这种联系。作者用自适应图来代替受启发的固定图来解决这个问题,这意味着图的拓扑是参数化的,是可以在学习过程中是化的。在这项工作中,作者提出了一种简单而有效的方法,既保证了训练过程的稳定性,又避免了灵活性的丧失,带来了明显的改善。
3.双流框架(运动信息与空间信息):基于双流的架构是一种广泛应用于基于rgb的动作识别的方法,它提取视频的光流场来建模帧间的时间依赖性。这种方法是有效的,因为有些动作类别强烈依赖于动作的顺序信息,例如“向左边挥手”与“向右边挥手”。因此,作者从关节和骨骼中提取运动信息来帮助识别。提出了一种融合空间信息流和运动信息流结果的双流框架,进一步提高了性能。
主要贡献
1.有向无环图:第一个将骨骼数据表示为有向无环图来建模关节和骨骼之间的依赖关系的工作。设计了一种新的有向图神经网络来提取这些依赖关系,以完成最终的动作识别任务。
2.采用自适应学习的图结构:在训练过程中与模型参数一起进行训练和更新,以更好地适应动作识别任务。
3.双流框架(运动信息与空间信息):双流提取连续帧间的运动信息进行时间信息建模。空间和运动信息都被输入到一个双流框架中,用于最终的识别任务。
二、Related work
2.1 Skeleton-based action recognition(骨架动作识别)
1.基于深度学习的方法主要有三种框架:
- 基于序列:根据设计的遍历策略将骨架数据表示为关节序列,然后使用基于RNN的体系结构对其建模。
- 基于图像:将骨架数据表示为伪图像,实现了成功应用于图像分类领域的CNN。
- 基于图:不是将骨架数据表示为序列或伪图像,而是将数据建模为一个图,其中关节为顶点,骨骼为边缘。
与基于序列的方法和基于图像的方法相比,基于图形的方法更加直观,因为人体的自然组织形式是一个图形,而不是一个序列或图像。
2.2 Graph networks(图网络)
直接在图上操作和解决基于图的问题的方法:
1.Kipf等人[15]提出了一种无监督神经关系推理模型,可以从物理模拟的观测数据中推断相互作用并学习动力学。
2.Gilmer等[9]提出了一种解决化学预测问题的消息传递网络,该网络可以直接从分子图中提取特征,且对图同构不变化。
3.Wang等人[33]将视频表示为时空区域图,以建模人与物体之间的时间动态和关系,然后可用于理解人的行为。
三、Method
实现过程如下:
1.输入:原始骨架数据是一系列帧,每一帧都包含一组关节坐标。
2.提取信息:给定骨骼序列,首先根据关节的2D或3D坐标提取骨骼信息。
3.有向无环图:将每一帧中的关节和骨骼(空间信息)表示为有向无环图中的顶点和边缘,并将其输入有向图神经网络(DGNN)提取特征进行动作识别。
4.双流框架(空间与运动):利用与空间信息相同的图结构对运动信息进行提取,并将其与空间信息结合在一个双流框架中,进一步提高性能。
3.1 Bone Information(骨骼信息)
骨骼表示为两个相连关节之间的坐标差。以三维骨骼数据为例:原始数据中的关节被表示为一个具有三个元素的向量,即其x坐标、y坐标和z坐标。给定两个关节 v 1 = ( x 1 , y 1 , z 1 ) v_1 = (x_1, y_1, z_1) v1=(x1,y1,z1) 和 v 2 = ( x 2 , y 2 , z 2 ) v_2 = (x_2, y_2, z_2) v2=(x2,y2,z2) ,从 v 1 v_1 v1 连接到 v 2 v_2 v2 的骨可用两个关节向量的差表示,即 e v 1 , v 2 = ( x 1 − x 2 , y 1 − y 2 , z 1 − z 2 ) e_{v_1,v_2} = (x_1−x_2, y_1−y_2, z_1−z_2) ev1,v2=(x1−x2,y1−y2,z1−z2) 。
3.2 Graph Construction(图的构建)
1.以前:传统的方法总是将骨架数据建模为矢量序列或伪图像,由RNN或CNN处理。
问题:这些表示忽略了关节和骨骼之间的运动学依赖关系。在人体解析中,骨架数据总是根据人体的物理结构建模为基于树的图形结构。
2.解决:本文将骨骼数据表示为有向无环图(DAG),关节为顶点,骨骼为边。
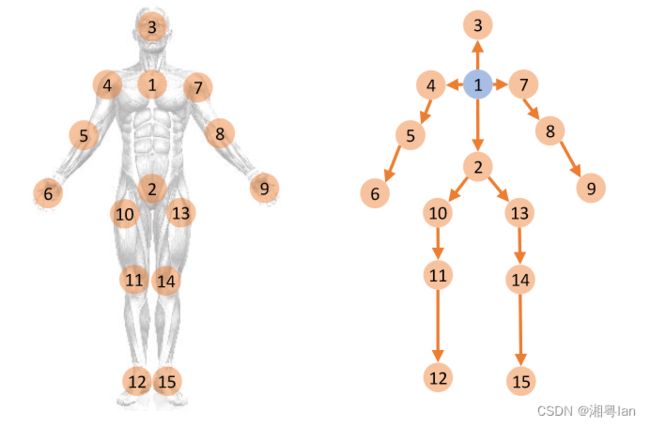
具体:每条边的方向由顶点和根顶点之间的距离决定,其中靠近根顶点的顶点指向距离根顶点更远的顶点。这里,根顶点被定义为骨架的重心。
上图,显示了一个骨架示例及其对应的有向图表示,其中顶点1是根顶点。这种表示是直观的,因为人体自然是一个铰接系统。
离人体中心较远的关节总是受到靠近中心的相邻关节的物理控制。
例如,手腕的位置是由肘部的位置和前臂的形状决定的。
那么,前臂就可以
表示为一条从肘部指向手腕的有向边缘。
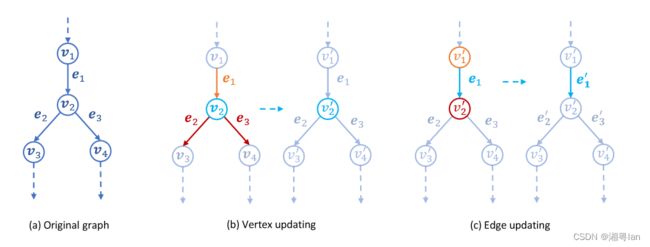
(a)是原始图形。
(b)表示出了顶点更新的过程,其中顶点本身的属性 ( v 2 v_2 v2) 及其进入边 ( e 1 e_1 e1) 和外出边( e 2 e_2 e2 和 e 3 e_3 e3) 的属性被组合以获得更新的顶点 ( v 2 ′ v_2^′ v2′)。
(c)表示出了边更新的过程,其中边本身的属性 ( e 1 e_1 e1) 及其源顶点 ( v 1 ’ v_1^’ v1’) 和目标顶点 ( v 2 ’ v_2^’ v2’) 的属性被组合以获得更新的边 ( e 1 ’ e_1^’ e1’) 。蓝色圆圈表示正在更新的边(或顶点)。橙色圆圈和红色圆圈分别表示更新中涉及的源顶点(或引入边)和目标顶点(或引出边)。
3.3 Directed graph neural network(有向图神经网络)
上一步已经将骨骼数据表示为有向图,现在的问题在于如何提取图中包含的信息用于动作分类,特别是如何利用图中关节和骨骼之间的依赖关系。本文提出了一个有向图神经网络DGNN来解决这个问题。
网络结构:
该网络包含多个层,每一层都有一个包含顶点和边的属性的图形,并输出具有更新属性的相同图形。这里,属性表示被编码为向量的顶点和边的属性。在每一层中,顶点和边的属性根据其相邻的边和顶点进行更新。
如何表示局部和全局信息?
1.在底层,每个顶点或边只能从其相邻的边或顶点接收属性。这些层中的模型旨在在更新属性时提取顶点和边的局部信息。例如,模型可以提取关节的角度信息,只需要一个关节及其两个相连骨骼的信息。
2.在顶层,来自彼此相距较远的关节和骨骼的信息可以累积在一起。因此,提取的信息对于识别任务来说更加全局和语义化。这个概念类似于卷积神经网络的原理,即分级表示和局部性。
3.3.1 Directed graph network block(有向图网络块)
有向图网络(DGN)块是有向图神经网络的基本块,包含:
1.更新函数 h v h_v hv 和 h e h_e he :用于基于顶点和边的连接边和顶点来更新顶点和边的属性。
2.聚合函数 g e − g^{e^-} ge− 和 g e + g^{e^+} ge+:用于聚合连接到一个顶点的多条传入(传出)边中包含的属性。这是因为连接到每个顶点的输入(输出)边的数量是变化的,而参数的数量是固定的。因为这些边没有明显的顺序,所以聚合函数对于其输入的排列应该是不变的,并且可以采用可变数量的参数,例如平均池、最大池和元素相加。
从形式上看,该过程表述如下:
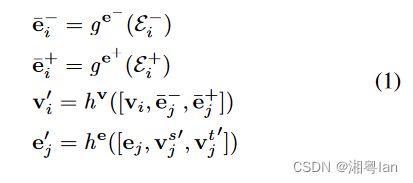
其中 [ ] [\ \ ] [ ] 表示串联操作。 v ’ v^’ v’ 和 e ’ e^’ e’ 分别是 v v v 和 e e e 的更新版本。该过程包括四个步骤:
- 对于每个顶点 v i v_i vi,指向它的所有边都由传入的聚合函数 g e − g^{e^-} ge− 处理,它返回聚合结果 e ‾ i ‾ \overline{e}_{\overline{i}} ei。
- 类似于上一步骤,从 v i v_i vi 发出的所有边都由输出聚合函数 g e + g^{e^+} ge+处理,该函数返回聚合结果 e ‾ i + \overline{e}_i^+ ei+
- v i , e ‾ i ‾ , e ‾ i + v_i,\overline{e}_{\overline{i}},\overline{e}^+_i vi,ei,ei+ 连接在一起,并传入更新函数 h v h_v hv,该函数返回 v i ’ v^’_i vi’ 作为 v i v_i vi 的更新版本。
- 对于每个边 e j e_j ej,它的源顶点、目标顶点和它自己被连接起来,并由边更新函数 h e h_e he处理。该函数返回 e j ′ e^′_j ej′,这是边 e j e_j ej的更新版本。
该过程也可以概括为顶点更新过程,之后是边更新过程,如上图所示。
本文中聚合函数:传入边和传出边中应用平均池化。
更新函数:单个全连接层。
3.3.2 Implementation of the DGN block(DGN区块的实施)
在实现DGN块时,
- 顶点的输入数据: C × T × N v C×T×N_v C×T×Nv张量 f v f_v fv ,其中 C C C 是通道数, T T T 是帧数。 N v N_v Nv表示骨架图中的顶点数。
- 边的数据形成 C × T × N e C×T×N_e C×T×Ne 张量 f e f_e fe,其中 N e N_e Ne是图中的边数。
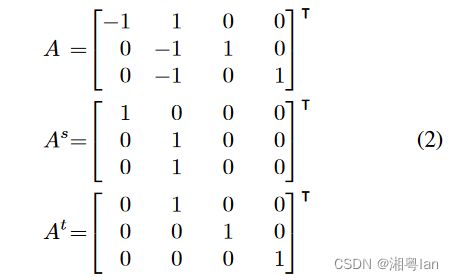
根据上一节,我们知道,DCN块关键是找到每个顶点的输入边和输出边,还有每个边的源顶点和目标顶点,因此,作者使用了图的关联矩阵:
- 如果 v i v_i vi 是 e j e_j ej 的源顶点,则 A i j = − 1 A_{ij}=−1 Aij=−1
- 如果 v i v_i vi 是 e j e_j ej 的目标顶点,则 A i j = 1 A_{ij}=1 Aij=1。
- 如果 v i v_i vi 和 e j e_j ej 之间没有连接,则 A i j = 0 A_{ij}=0 Aij=0 。
为了分离源顶点和目标顶点,作者使用 A S A^S AS 来表示源顶点的关联矩阵,该矩阵只包含 A A A 中小于0的元素的绝对值。同样,我们将 A t A^t At 定义为目标顶点的关联矩阵,它只包含 A A A 中大于0的元素。例如,等式2显示了图1(a)所示的图的关联矩阵及其对应的 A s A^s As 和 A t A^t At 。
给定输入张量和关联矩阵,我们现在可以过滤所需的边和顶点,并通过矩阵乘法执行聚合功能。例如,给定 f v f_v fv 和 A s A^s As,我们首先将 f v f_v fv 重塑为 C T × N v CT×N_v CT×Nv矩阵;然后, f v f_v fv 和 A s A_s As 的乘法可以提供 C T × N e CT×N_e CT×Ne 张量。根据矩阵乘法的定义,该张量的每个元素对应于对应边的源顶点的和。
3.3.3 Adaptive DGN block(自适应DGN块)
1.目前存在问题:DGN块的输入图形是根据人体的自然结构手动设计的。但这种配置可能不适合动作识别任务。例如,左手和右手之间没有联系,然而,对于许多动作,如鼓掌和拥抱,双手之间的关系对于识别很重要。
2.传统解决方法:为了给图的构造提供更大的灵活性,传统方法的目的是在训练过程中通过学习图结构的拓扑来构造自适应图。例如,在原始邻接矩阵上应用注意图,为不同的边分配不同级别的重要性。
3.如果用 A o A_o Ao 表示原邻接矩阵,则新的邻接矩阵 A A A 的计算公式为 A = P A o A=PA_o A=PAo。
其中P的元素被初始化为1,并在训练过程中更新。
****然而,乘法运算不能改变原始邻接矩阵中为 0 0 0 的元素,这意味着该方法只能改变现有边的重要性,而不能添加新的边,例如双手之间的边。
4.与ST-GCN不同的是,Shih等人直接将邻接矩阵设置为网络参数。为了稳定训练过程,他们设置了 A = A o + P A=A_o+P A=Ao+P,其中 P P P 的大小与 A o A_o Ao相同,并被初始化为 0 0 0 。这样,如果需要,可以在学习过程中通过参数 P P P 添加新的边。
****然而,由于 A o A_o Ao是不可修改的,我们不能移除我们不想要的边缘,这也降低了模型的灵活性。然而,如果去掉 A o A_o Ao,不加任何限制地直接学习图的结构会降低性能。
5.本文解决方法:作者发现《NonLocal Graph Convolutional Networks for Skeleton-Based Action Recognition.》中有或没有 A o A_o Ao的情况的区别,主要在于训练过程的开始(注意,这里的 A A A 表示关联矩阵,而不是像以前的工作那样表示邻接矩阵)。这一结果是直观的,因为训练过程的开始存在更多的不确定性,因此,约束较少但参数较多的模型容易收敛到局部最优。添加固定拓扑图相当于基于人体先验知识对模型进行正则化,可以帮助模型收敛到全局最优。
基于这一观察,作者提出了一个简单而有效的策略来解决这个问题。直接将 A A A 设置为模型的参数,但将其固定在前几个训练周期。早期固定图形结构可以简化训练,之后取消固定图形结构可以为图形构造提供更大的灵活性。
3.3.4 Temporal information modeling(时态信息建模)
通常,一个动作被记录为一系列基于骨架的帧。
上面介绍的DGN块只能处理单帧的空间信息。因此,现在推进到在骨架序列中建模时间动态的任务。
传统做法:伪三维CNN在基于RGB的动作识别领域表现出了其优越性,它先用二维卷积对空间信息建模,再用一维卷积对时间信息建模。伪三维CNN通过对时空维度的解耦,可以更经济有效地对时空信息进行建模。
本文:受此启发,作者在**更新每个DGN块中关节和骨骼的空间信息后,沿时间维度应用一维卷积对时间信息进行建模。**这很容易实现,因为所有框架中的相同关节或骨骼可以自然地组织成一维序列。
网络框架:
与DGN块类似,每个1D卷积层后面都跟着一个BN层和一个ReLU层,形成一个时域卷积块(TCN)。
有向图神经网络(DGNN)的总体结构有9个单元,每个单元包含一个DGN块和一个TCN块。
该单元的输出通道为64、64、64、128、128、128、256,256和256。
最后加上一个全局平均聚类层和一个softmax层,用于类预测。
3.3.5 Two-Stream Framework(双流框架)
传统做法:一些动作,比如“站起来”和“坐下来”,很难从空间信息中识别出来。传统的基于RGB的动作识别方法通常使用光流场来描述视频的运动信息,其计算连续帧之间的像素运动信息。
本文:受这些方法的启发,作者提取了关节的运动和骨骼的变形,以帮助识别。由于骨骼数据表示为关节的坐标,因此关节的运动很容易计算为沿时间维度的坐标差。类似地,骨骼的变形表示为连续帧中同一骨骼的矢量差。形式上,关节 v v v 在时间 t t t 中的运动计算为 m v t = v t + 1 − v t m_{v_t} = v_{t+1}− v_{t} mvt=vt+1−vt 骨骼变形的定义类似于 m e t = e t + 1 − e t m_{e_t}=e_{t+1} − e_t met=et+1−et与空间信息建模一样,运动信息被表示为一系列有向非循环图
![]()
其中![]()
![]()
然后,运动图被送到另一个DGNN中,以对动作标签进行预测。通过添加softmax层的输出分数,最终融合两个网络。