ELK日志系统
文章目录
- 一、ELK诞生的背景
-
- 1.1 没有ELK分析日志前
- 1.2 使用ELK分析日志后
- 二、ELK技术栈
-
- 2.1 什么是ELK
- 2.2 什么是EFK
- 2.3 什么是EFLK
- 2.4 EFK收集哪些日志
- 三、Elasticsearch
-
- 3.1 ES相关术语
-
- 3.1.1 文档 Document
- 3.1.2 索引 Index
- 3.1.3 字段 Filed
- 3.1.4 总结
- 3.2 ES操作方式
-
- 3.2.1 curl命令操作ES
- 3.2.2 Kibana操作ES
-
- 3.2.2.1 Es安装
- 3.2.2.2 安装kibana
- 3.3 ES 索引API
-
- 3.3.1 创建索引
- 3.3.2 删除索引
- 3.4 ES文档API
-
- 3.4.1 创建文档
- 3.4.2 查询文档
- 3.4.3 批量创建文档
- 3.4.4 批量查询文档
- 四、Elasticsearch 集群
-
- 4.1 部署环境
- 4.2 安装ES 、java
-
- 4.2.1 node1节点配置
- 4.2.2 node2节点配置
- 4.2.3 node3节点配置
- 4.3 ES集群健康检查
-
- 4.3.1 curl检查 可以curl集群中的任意一台主机
- 4.3.2 Cerebor检查集群状态
- 五、ES集群节点类型
-
- 5.1 Cluster State
- 5.2 Master
- 5.3 Data
- 5.4 Coordinating
- 6.1 提高ES集群可用性
- 6.2 增大ES集群的容量
- 6.3 增加节点能否提高容量
- 6.4 增加副本能否提高读性能
- 6.5 如果需要增加读吞吐量性能,应该怎么来做
- 6.6 副本与分片总结
- 七、ES集群故障转移与恢复
-
- 7.1 什么是故障转移
- 7.2 模拟节点故障
-
- 7.2.1 重新选举
- 7.2.2 主分片调整
- 7.2.3 副本分片调整
- 八、ES文档路由原理
-
- 8.1 文档的创建流程
- 8.2 文档的读取流程
- 8.3 文档批量创建的流程
- 8.4 文档批量读取的流程
- 九、ES扩展集群节点,扩展data节点和 路由节点方法
-
- 9.1 环境准备
- 9.2 扩展节点检查
- 十、ES集群调优
-
- 10.1 内核参数优化
- 10.2 es配置参数优化
- 10.3 JVM优化
一、ELK诞生的背景
1.1 没有ELK分析日志前
没有日志分析工具之前,运维工作存在哪些痛点?
- 生产出现故障后,运维需要不停的查看各种不同的日志进行分析?是不是毫无头绪;
- 项目上线出现错误,如何快速定位问题?如果后端节点过多、日志分散怎么办;
- 开发人员需要实时查看日志但又不想给服务器的登陆权限,怎么办?难道每天帮开发取日志;
- 如何在海量的日志中快速的提取我们想要的数据?比如:PV、UV、TOP10的URL?如果分析的日志数据量大,那么势必会导致查询速度慢、难度增大,最终则会导致我们无法快速的获取到想要的指标。
- CDN公司需要不停的分析日志,那分析什么?主要分析命中率,为什么?因为我们给用户承诺的命中率是90%以上。如果没有达到90%,我们就要去分析数据为什么没有被命中、为什么没有被缓存;
1.2 使用ELK分析日志后
如上所有的痛点都可以使用日志分析系统ELK解决,通过ELK,将所有的离散的服务器都收集到一个平台下;然后提取想要的内容,比如错误信息,警告信息等,当过滤到这种信息,就马上告警,告警后,运维人员就能马上定位是哪台机器、哪个业务系统出现了问题,出现了什么问题。
二、ELK技术栈
2.1 什么是ELK
-
ELK 不是一个单独的技术,而是一套技术组合,是由elasticsearch、logstash、kibana 组合而成的。
-
ELK 是一套开源免费、功能强大的日志分析管理系统。
-
ELK 可以将我们的系统日志、网站日志、应用服务日志等各种日志进行收集、过滤、清洗,然后进行集中存放,并可用于实时检索、分析。
E: elasticsearch数据存储; L: logstash数据采集、数据清洗、数据过滤; K: kibana 数据分析、数据展示;
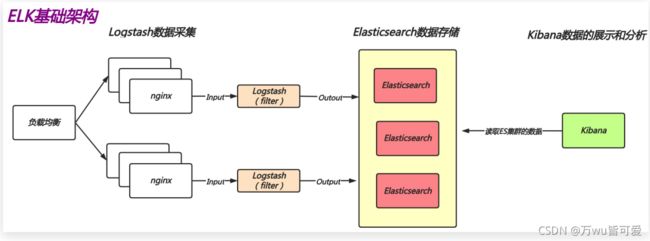
2.2 什么是EFK
简单来说就是将 Logstash 替换成了 filebeat,那为什么要进行替换?
因为 logstash 是基于 JAVA 开发的,在收集日志时会大量的占用业务系统资源,从而影响正常线上业务。而替换成 filebeat 这种较为轻量的日志收集组件,会让业务系统的运行更加的稳定。
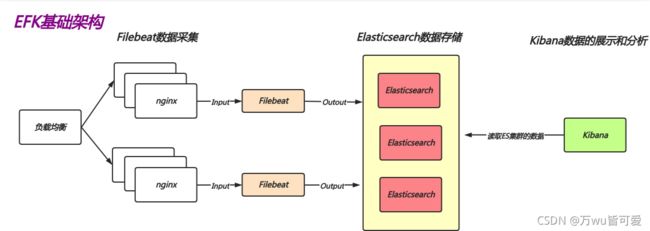
2.3 什么是EFLK
由于Filebeat处理数据能力有限,只能处理json格式的数据,Logstash的数据处理能力相对来说很强,可以组成如下的架构,让Filebeat采集数据,给Logstash进一步加工处理,然后写入Elasticsearch
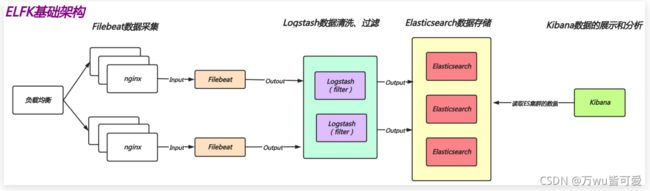
2.4 EFK收集哪些日志
代理: Haproxy、Nginx
web:Nginx、Tomcat、Httpd、PHP
db:mysql、redis、mongo、elasticsearch
存储:nfs、glusterfs、fastdfs
系统:message、security
业务:app
三、Elasticsearch
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,主要功能是数据存储、数据搜索、数据分析。
3.1 ES相关术语
3.1.1 文档 Document
Document 文档就是用户存在 es 中的一些数据,它是es 中存储的最小单元。(类似于表中的一行数据)。每个文档都有一个唯一的 ID 表示,可以自行指定,如果不指定 es 会自动生成。
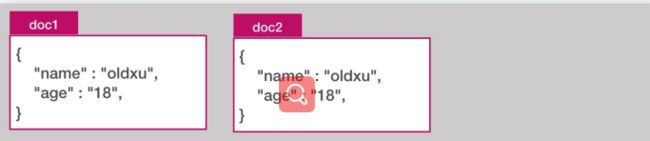
3.1.2 索引 Index
索引其实是一堆文档 Document 的集合。(它类似数据库的中的一个表)
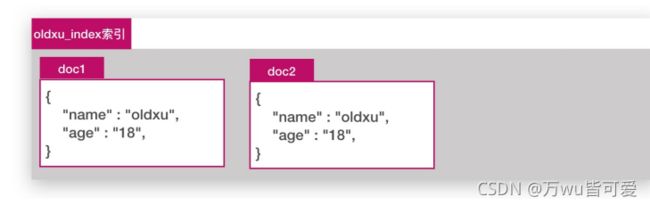
3.1.3 字段 Filed
在 ES 中,Document就是一个 Json Object,一个Json Object其实是由多个字段组成的,每个字段它有不同的数据类型。
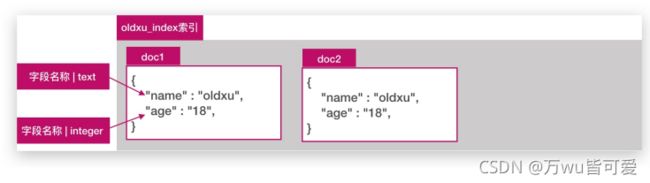
常见的字段数据类型
字符串:text、keyword。
数值型:long,integer,short,byte,double,float
布尔:boolean
日期:date
二进制:binary
范围类型:
integer_range,float_range,long_range,double_range,
date_range
3.1.4 总结
一个索引里面存储了很多的 Document 文档,一个文档就是一个json object,一个json object是由多个不同或相同的 filed 字段组成;
3.2 ES操作方式
ES 的操作和我们传统的数据库操作不太一样,它是通过 RestfulAPI 方式进行操作的,其实本质上就是通过 http 的方式去变更我们的资源状态;通过 URI 指定要操作的资源,比如 Index、Document;通过 Http Method 指定要操作的方法,如 GET、POST、PUT、DELETE;
常见操作 ES 的两种方式:Curl、Kibana DevTools
3.2.1 curl命令操作ES
# 存数据
[root@es-node1 ~]# curl -XPOST \
> 'http://127.0.0.1:9200/bertwu_index/_doc/1' \
> -H "Content-Type: application/json" \
> -d '{
> "name":"tom",
> "age":18,
> "salary": 1000000
> }'
{"_index":"bertwu_index","_type":"_doc","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}
[root@es-node1 ~]#
# 获取数据
[root@es-node1 ~]# curl -XGET "http://127.0.0.1:9200/bertwu_index/_doc/1"
{"_index":"bertwu_index","_type":"_doc","_id":"1","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{
"name":"tom",
"age":18,
"salary": 1000000
3.2.2 Kibana操作ES
3.2.2.1 Es安装
[root@es-node3 ~]# rpm -ivh elasticsearch-7.8.1-x86_64.rpm
[root@es-node3 ~]# vim /etc/elasticsearch/jvm.options # 如果内存小可以适当修改最小堆内存与最大堆内存
-Xms512m
-Xmx521m
[root@es-node3 ~]# systemctl daemon-reload
[root@es-node3 ~]# systemctl enable elasticsearch.service
[root@es-node3 ~]# systemctl start elasticsearch.service
[root@es-node3 ~]# netstat -lntp | grep java
tcp6 0 0 127.0.0.1:9300 :::* LISTEN 1408/java # elasticsearch 做集群相互间通讯的端口
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 1408/java # 对外通讯的端口
3.2.2.2 安装kibana
# 安装kibana
[root@es-node1 ~]# rpm -ivh kibana-7.8.1-x86_64.rpm
# 配置kibana
[root@kibana ~]# vim/etc/kibana/kibana.yml
server.port: 5601 #kibana默认监听端口
server.host: "0.0.0.0" #kibana监听地址段
server.name: "kibana.bertwu.net" # 域名
elasticsearch.hosts:["http://localhost:9200"] # kibana从coordinating节点获取数据
# elasticsearch.hosts: ["http://172.16.1.161:9200","http://172.16.1.162:9200","http://172.16.1.163:9200"] 后续es组成集群请改为这种形式
i18n.locale: "zh-CN" #kibana汉化
# 启动kibana
[root@kibana ~]# systemctl start kibana
[root@kibana ~]# systemctl enable kibana
3.3 ES 索引API
es 有专门的 Index API,用于创建、更新、删除索引配置等
创建索引 api 如下:
3.3.1 创建索引
# 创建索引
PUT /bertwu_index
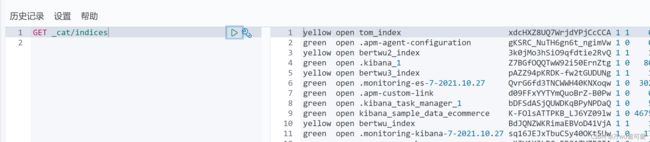
#查看所有已存在的索引
GET _cat/indices

3.3.2 删除索引
DELETE /索引名

3.4 ES文档API
3.4.1 创建文档
POST /bertwu_index/_doc/1
{
"username":"狄仁杰",
"age":18,
"role":"射手"
}

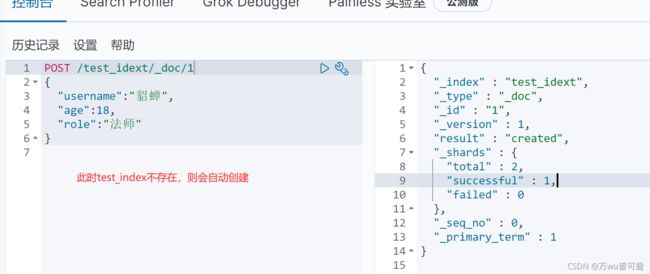
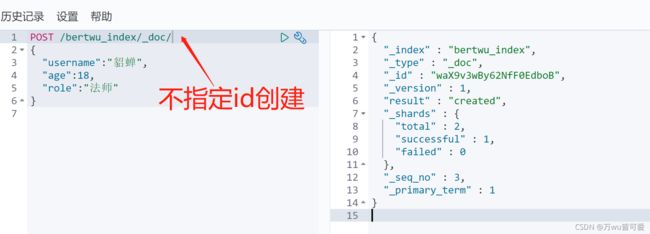
3.4.2 查询文档
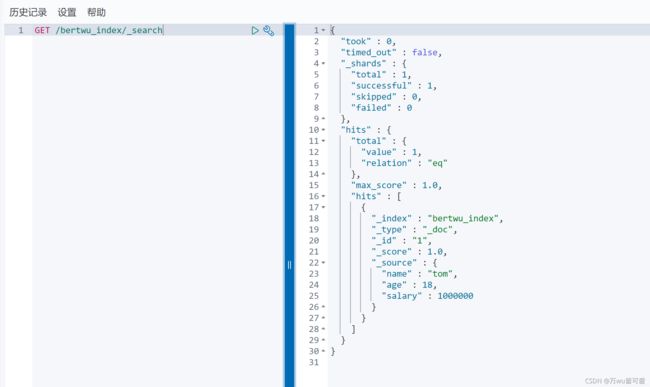
查询文档,指定要查询的文档id
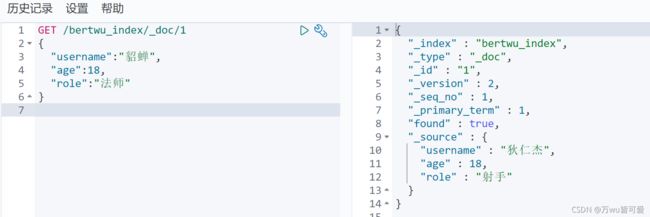
查询该索引下全部文档,用_search
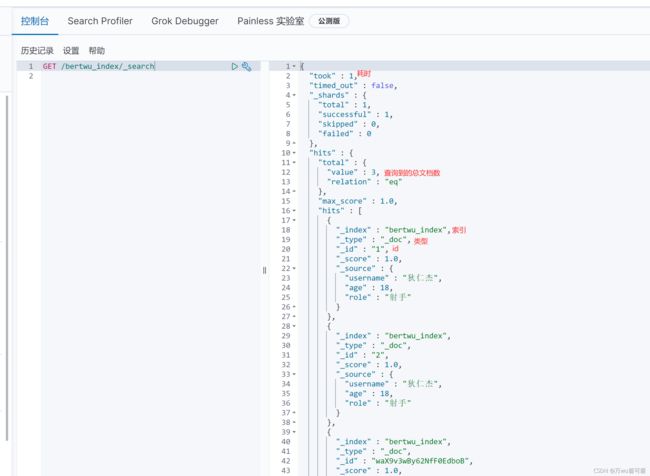
查询索引下特定文档:
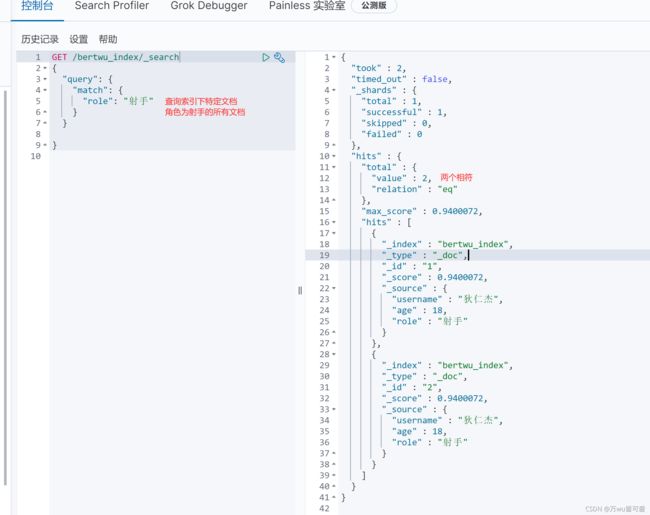
GET /bertwu_index/_search
{
"query": {
"match": {
"role": "射手"
}
}
}
3.4.3 批量创建文档
POST _bulk
{"index":{"_index":"tt","_id":"1"}} # 创建索引 tt id 1
{"name":"oldxu","age":"18"} # 添加用
{"create":{"_index":"tt","_id":"2"}} # 在tt索引下创建文档id 为2
{"name":"oldqiang","age":"30"}
{"delete":{"_index":"tt","_id":"2"}} # 删除tt索引下 id为2的文档
{"update":{"_id":"1","_index":"tt"}} # 更新 索引tt下 id为1 的文档
{"doc":{"age":"20"}}
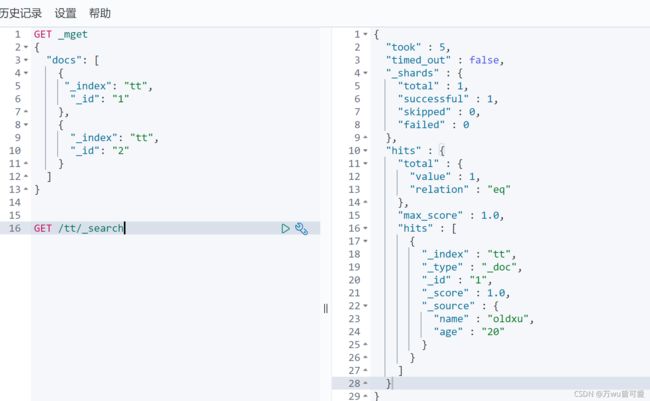
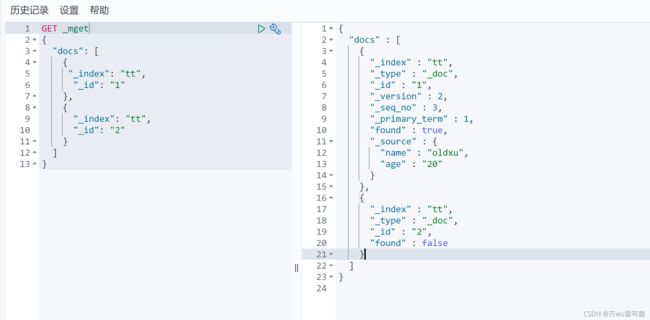
3.4.4 批量查询文档
es允许通过 _mget 一次查询多个文档。
GET _mget
{
"docs": [
{
"_index": "tt",
"_id": "1"
},
{
"_index": "tt",
"_id": "2"
}
]
}
四、Elasticsearch 集群
es天然支持集群模式,集群模式好处:
- 能够增大系统的容量,如内存、磁盘,使得 es集群可以支持PB级的数据;
- 能够提高系统可用性,即使部分节点停止服务,整个集群依然可以正常服务
如何加入:
ELasticsearch 集群是由多个节点组成的,通过cluster.name 设置集群名称,并且用于区分其它的
集群,每个节点通过 node.name 指定节点的名称。
4.1 部署环境
| 主机名称 | 外网IP WAN | 内网IP LAN |
|---|---|---|
| es-node1 | 10.0.0.161 | 172.16.1.161 |
| es-node2 | 10.0.0.162 | 172.16.1.162 |
| es-node3 | 10.0.0.163 | 172.16.1.163 |
4.2 安装ES 、java
# yum install java -y
# rpm -ivh elasticsearch-7.8.1-x86_64.rpm
4.2.1 node1节点配置
首先需要停止es,删除es中的实验测试数据,否则对创建集群有影响
[root@es-node1 ~]# rm -rf /var/lib/elasticsearch/*
[root@es-node1 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es-node1 ~]# grep "^[a-zA-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application # 集群名称,所有参加集群的节点集群名称应该保持一致
node.name: es-node1 # 节点名称
path.data: /var/lib/elasticsearch # es数据存储路径
path.logs: /var/log/elasticsearch # es日志存储路径
#bootstrap.memory_lock: true # 不使用swap分区
network.host: 172.16.1.161 # 监听在本地ip
http.port: 9200 # 监听在本地端口
discovery.seed_hosts: ["172.16.1.161", "172.16.1.162","172.16.1.163"] #集群主机列表
cluster.initial_master_nodes: ["172.16.1.161", "172.16.1.162","172.16.1.163"] # 仅第一次启动集群时对列表中的主机进行选举
4.2.2 node2节点配置
[root@es-node2 ~]# grep "^[a-zA-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application
node.name: es-node2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 172.16.1.162
http.port: 9200
discovery.seed_hosts: ["172.16.1.161", "172.16.1.162","172.16.1.163"]
cluster.initial_master_nodes: ["172.16.1.161", "172.16.1.162","172.16.1.163"]
4.2.3 node3节点配置
[root@es-node3 ~]# grep "^[a-zA-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application
node.name: es-node3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 172.16.1.163
http.port: 9200
discovery.seed_hosts: ["172.16.1.161", "172.16.1.162","172.16.1.163"]
cluster.initial_master_nodes: ["172.16.1.161", "172.16.1.162","172.16.1.163"]
4.3 ES集群健康检查
Cluster Health 获取集群的健康状态,整个集群状态包括以下三种:
- green 健康状态,指所有主副分片都正常分配
- yellow 指所有主分片都正常分配,但是有副本分片未正常分配
- red 有主分片未分配,表示索引不完备,写可能有问题。(但不代表不能存储数据和读取数据)
检查 ES 集群是否正常运行,可以通过 curl、Cerebro两种方式;
4.3.1 curl检查 可以curl集群中的任意一台主机
[root@es-node1 elasticsearch]# curl http://172.16.1.161:9200/_cluster/health?pretty=true
{
"cluster_name" : "my-application",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 1,
"active_shards" : 2,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
# 可以自定义监控项传递给zabbix监控
curl -s http://172.16.1.161:9200/_cluster/health?pretty=true | grep "status" | awk -F '"' '{print $4}'
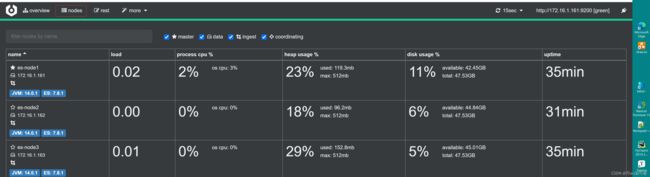
4.3.2 Cerebor检查集群状态
通过curl命令查看集群状态不直观,可以用可视化图形工具Cerebor查看
Cerebor下载
[root@es-node1 ~]# rpm -ivh cerebro-0.9.4-1.noarch.rpm
[root@es-node1 ~]# vim/etc/cerebro/application.conf
data.path: "/var/lib/cerebro/cerebro.db"
#data.path = "./cerebro.db"
[root@es-node1 ~]# systemctl start cerebro
[root@es-node1 ~]# netstat -lntp | grep java
tcp6 0 0 :::9000 :::* LISTEN 4646/java
五、ES集群节点类型
Cluster State
Master
Data
Coordinating
5.1 Cluster State
Cluster State:集群相关的数据称为 cluster state;会存储在每个节点中,主要有如下信息:
- 节点信息,比如节点名称、节点连接地址等
- 索引信息,比如索引名称、索引配置信息等
5.2 Master
- ES集群中只能有一个 master 节点,master节点用于控制整个集群的操作;
- master 主要维护Cluster State,当有新数据产生后,Master 会将数据同步给其他 Node 节点;
- master节点是通过选举产生的,可以通过node.master: true 指定为Master节点。( 默认true )
当我们通过API创建索引 PUT /index,Cluster State 则会发生变化,由 Master 同步至其他Node 节点;
5.3 Data
- 存储数据的节点即为 data 节点,默认节点都是 data类型,配置node.data: true( 默认为 true )
- 当创建索引后,索引创建的数据会存储至某个节点,能够存储数据的节点,称为data节点
5.4 Coordinating
- 处理请求的节点即为 coordinating 节点,该节点为所有节点的默认角色,不能取消
- coordinating 节点主要将请求路由到正确的节点处理。比如创建索引的请求会由 coordinating路由到 master 节点处理;当配置 node.master:false、node.data:false 则为 coordinating节点
总结:
master: 负责控制整个集群的状态;负责维护cluster state
node : 负责存储数据的,默认情况下,所有的节点都是数据节点;node.data: false
coordinating: 负责路由,所有节点都有路由功能不可以被取消:node .master node .data fasle
master-eligible 可以参与选举的节点;
六、ES集群分片副本
6.1 提高ES集群可用性
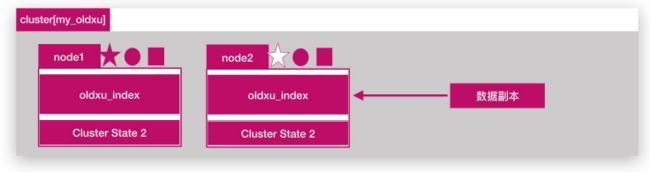
如何提高 ES 集群系统的可用性;有如下两个方面;
- 服务可用性:
1.2个节点的情况下,允许其中1个节点停止服务;
2.多个节点的情况下,坏的节点不能超过集群一半以上; - 数据可用性
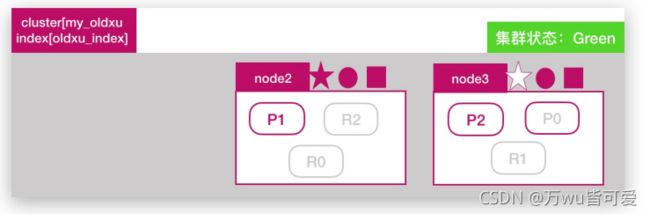
1.通过副本 replication 解决,这样每个节点上都有完备的数据。
2.如下图所示,node2上是 oldxu_index 索引的一个完整副本数据。
6.2 增大ES集群的容量
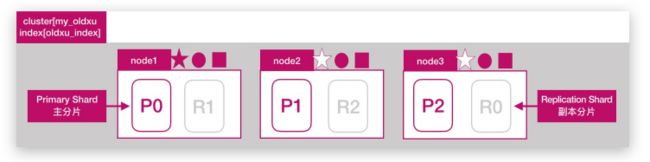
- 如何增大 ES 集群系统的容量;我们需要想办法将数据均匀分布在所有节点上;引入分片 shard 解决;
- 什么是分片,将一份完整数据分散为多个分片存储;
2.1. 分片是 es 支持 Pb 级数据的基石
2.2 分片存储了索引的部分数据,可以分布在任意节点上
2.3 分片存在主分片和副本分片之上,副本分片主要用来实现数据的高可用
2.4 副本分片的数据由主分片同步,可以有多个,用来提高读取数据性能
注意:主分片数在索引创建时指定且后续不允许在更改;默认ES7分片数为1个 - 如下图所示:在3个节点的集群中创建
oldxu_index 索引,指定3个分片,和1个副本
# 创建索引,设定主分片和副本分片 3 1 =6
PUT /oldxu_index
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
# 动态修改副本分片
PUT /oldxu_index/_settings
{
"number_of_replicas": 9
}
点击more----> create index
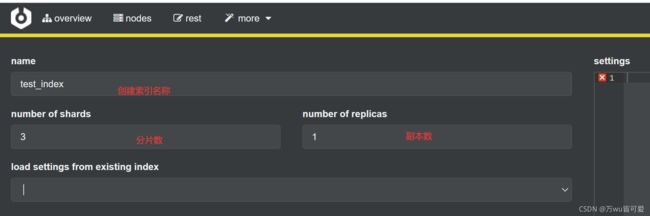
结果展示

6.3 增加节点能否提高容量
问题:目前一共有3个ES节点,如果此时增加一个新节点是否能提高 oldxu_index 索引数据容量?

答案:不能,因为 oldxu_index 只有3个分片,已经分布在3台节点上,那么新增的第四个节点对于oldxu_index 而言是无法使用到的。所以也无法带来数据容量的提升;
6.4 增加副本能否提高读性能
问题:目前一共有3个ES节点,如果增加副本数是否能提高 oldxu_index 的读吞吐量;
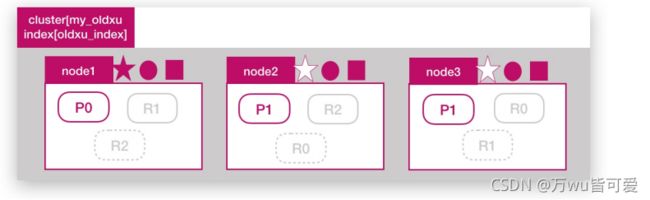
答案:不能,因为新增的副本还是会分布在这 node1、node2、node3 这三个节点上的,还是使用了相同的资源,也就意味着有读请求来时,这些请求还是会分配到
node1、node2、node3 上进行处理、也就意味着,还是利用了相同的硬件资源,所以不会提升读性能
6.5 如果需要增加读吞吐量性能,应该怎么来做

答案:增加读吞吐量还是需要添加节点,比如在增加三个节点 node4、node5、node6 那么将原来的 R0、R1、R2 分别迁移至新增的三个节点上,当有读请求来时会被分配 node4、node5、node6,也就意味着有新的 CPU、内存、IO,这样就不会在占用 node1、node2、node3 的硬件资源,那么这个时候读吞吐量才会得到真正的提升;
6.6 副本与分片总结
分片数和副本的设定很重要,需要提前规划好
- 过小会导致后续无法通过增加节点实现水平扩容;
- 设置分片过大会导致一个节点上分布过多的分片,造成资源浪费。分片过多也会影响查询性能;
- 分片数目一旦设定,不可修改
七、ES集群故障转移与恢复
7.1 什么是故障转移
所谓故障转移指的是,当集群中有节点发生故障时,这个集群是如何进行自动修复的。ES集群目前是由3个节点组成,如下图所示,此时集群
状态是 green
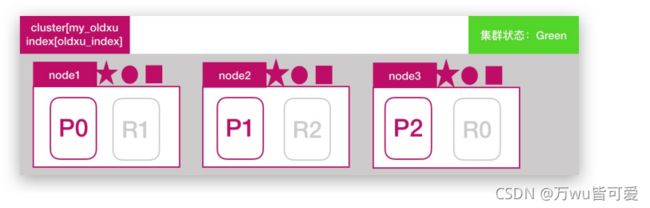
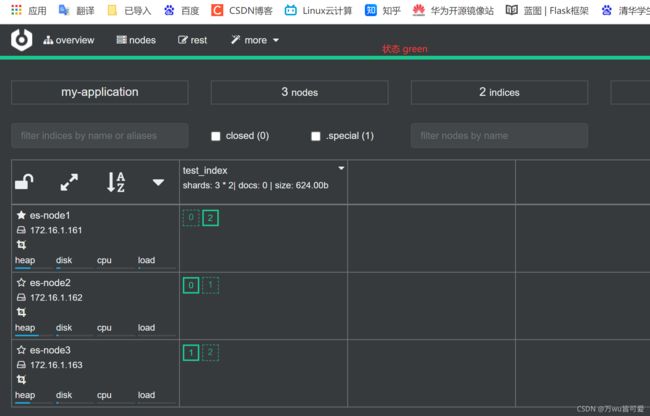
7.2 模拟节点故障
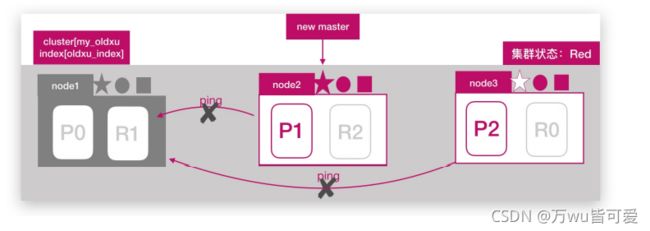
假设:node1 所在机器宕机导致服务终止,此时集群会如何处理;大体分为三个步骤:
1.重新选举
2.主分片调整
3.副本分片调整
7.2.1 重新选举
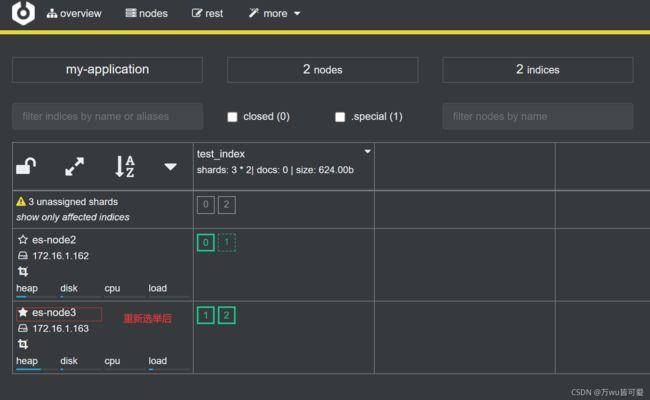
node2 和 node3 发现 node1 无法响应;一段时间后会发起 master 选举,比如这里选择 node2 为 master 节点;此时集群状态变为 Red 状态;
7.2.2 主分片调整
node2 发现主分片 P0 未分配,将 node3 上的 R0 提升为主分片;此时所有的主分片都正常分配,集群状态变为 Yellow状态;

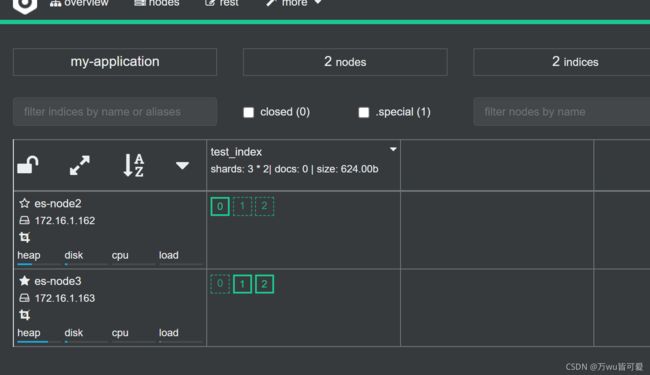
7.2.3 副本分片调整
node2 将 P0 和 P1 主分片重新生成新的副本分片 R0、R1,此时集群状态变为 Green;
八、ES文档路由原理
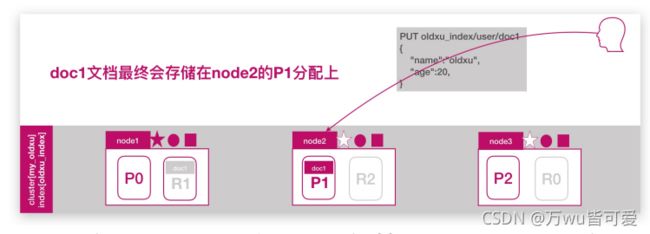
ES文档分布式存储,当一个文档存储至 ES集群时,存储的原理是什么样的?
如图所示,当我们想一个集群保存文档时,Document1是如何存储到分片P1的?选择P1的依据是什么?
其实是有一个文档到分片的映射算法,其目是使所有文档均匀分布在所有的分片上,那么是什么算法呢?随机还是轮询呢? 这种是不可取的,因为数据存储后,还需要读取,那这样的话如何读取呢?
实际上,在ES 中,通过如下的公式计算文档对应的分片存储到哪个节点,计算公式如下:
shard = hash(routing) % number_of_primary_shards
# hash 算法保证将数据均匀分散在分片中
# routing 是一个关键参数,默认是文档id,也可以自定义。
# number_of_primary_shards 主分片数
# 注意:该算法与主分片数相关,一但确定后便不能更改主分片。
# 因为一旦修改主分片修改后,Share的计算就完全不一样了
索引中的文档数据会被均匀的分配在不同分片中。
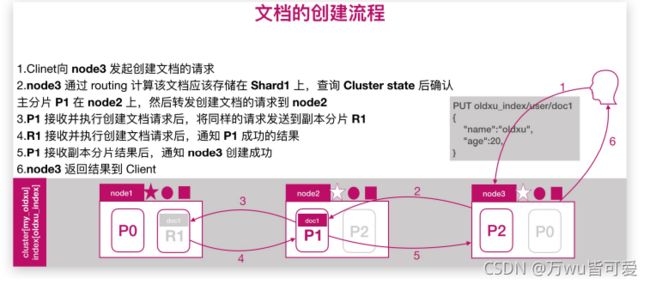
8.1 文档的创建流程
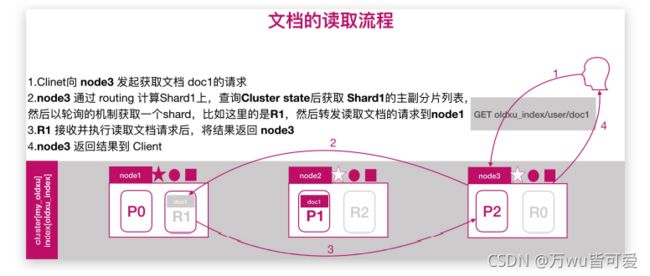
8.2 文档的读取流程
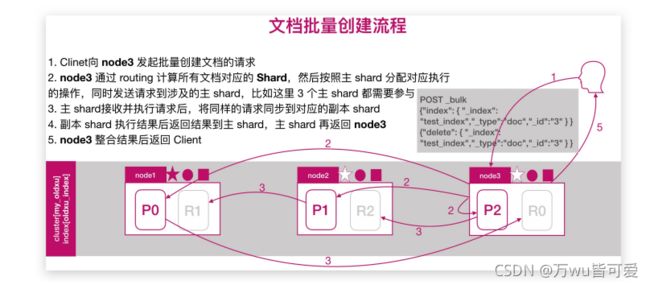
8.3 文档批量创建的流程
8.4 文档批量读取的流程

九、ES扩展集群节点,扩展data节点和 路由节点方法
9.1 环境准备
| 主机名称 | 外网IP WAN | 内网IP LAN |
|---|---|---|
| es-node4 | 10.0.0.164 | 172.16.1.164 |
| es-node5 | 10.0.0.165 | 172.16.1.165 |
扩展节点4配置,为存储节点
[root@es-node4 ~]# grep "^[a-zA-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application
node.name: es-node-4
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 172.16.1.164
http.port: 9200
discovery.seed_hosts: ["172.16.1.161", "172.16.1.162","172.16.1.163"] # 从这些主机中发现集群加入组织,可以写多个
node.data: true # 存储节点
node.master: false # 不参与master选举
扩展节点5配置,只充当路由节点 Coordinating
[root@es-node5 ~]# grep "^[a-zA-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application
node.name: es-node5
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 172.16.1.165
http.port: 9200
discovery.seed_hosts: ["172.16.1.161", "172.16.1.162","172.16.1.163"]
node.data: false # 不存储
node.master: false # 不参与竞选
9.2 扩展节点检查
通过 cerebor检查集群扩展后的状态;如果出现集群无法加入、或者加入集群被拒绝,尝试删除/var/lib/elasticsearch 下的文件,然后重启 es;
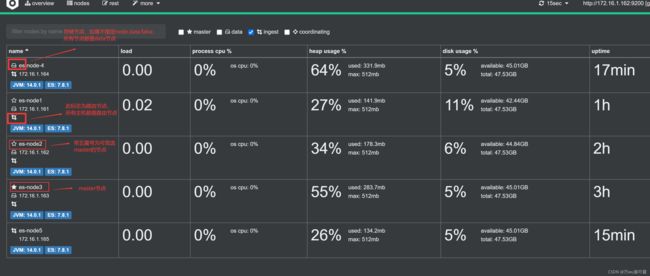
如果将 已经存在的data节点修改为 Coordinating 节点;需要清理数据,否则无法启动;
[root@es-node5 ~]# /usr/share/elasticsearch/bin/elasticsearch-node repurpose
十、ES集群调优
10.1 内核参数优化
fs.file-max=655360 # 设定系统最大打开文件描述符数,建议修改为655360或者更高,
vm.max_map_count = 262144 # 用于限制一个进程可以拥有的虚拟内存大小,建议修改成262144或更高。
net.core.somaxconn = 32768 # 全连接池大小
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 1000 65535
net.ipv4.tcp_max_tw_buckets = 400000
[root@node1 ~]# sysctl -p
# 调整最大用户进程数(nproc),调整进程最大打开文件描述符(nofile)
[root@node ~]# rm -f /etc/security/limits.d/20-nproc.conf # 删除默认nproc设定文件
[root@node ~]# vim /etc/security/limits.conf
* soft nproc 20480
* hard nproc 20480
* soft nofile 65536
* hard nofile 65536
10.2 es配置参数优化
# 1.锁定物理内存地址,避免es使用swap交换分区,频繁的交换,会导致IOPS变高。
[root@es-node ~]# vim /etc/elasticsearch/elasticsearch.yml
bootstrap.memory_lock: true
#2.配置elasticsearch启动参数
[root@es-node ~]# sed -i '/\[Service\]/a LimitMEMLOCK=infinity' /usr/lib/systemd/system/elasticsearch.service
[root@es-node ~]# systemctl daemon-reload
[root@es-node ~]# systemctl restart elasticsearch
10.3 JVM优化
JVM内存具体要根据 node 要存储的数据量来估算,为了保证性能,在内存和数据量间有一个建议的比例:像一般日志类文件,1G 内存能存储48G~96GB数据; jvm堆内存最大不要超过31GB;
其次就是主分片的存储量,单个控制在30-50GB;
假设总数据量为1TB,3个node节点,1个副本;那么实际要存储的大小为2TB,因为有一个副本的存在;2TB / 3 = 700GB,然后每个节点需要预留20%的空
间,意味着每个node要存储大约 700/0.8=875GB 的数据;
按照内存与存储数据的比率计算:
875GB/48=18GB,小于31GB,因为 31*48=1.4TB 及每个Node可以存储1.4TB数据,所以3个节点足够;
875GB/30=29/2=15个主分片。因为要尽量控制主分片的大小为30GB
假设总数据量为2TB,3个node节点,1个副本,则实际需要存储4TB, 4TB/3=1365GB,然后每个节点需要预留20%的空间,意味着每个node需要存储 大约
1365GB/0.8=1706GB的数据。
按照内存与存储数据的比率计算:
1706GB/48G=35 大于 31GB, 因为 31*48=1.4TB及每个Node可以存储1.4TB数据,所以至少需要4个node
1706/30=56/2=28个主分片
[root@es-node ~-]# vim /etc/elasticsearch/jvm.options
-Xms 31g #最小堆内存
-Xmx31g #最大堆内存
#根据服务器内存大小,修改为合适的值。一般设置为服务器物理内存的一半最佳,但最大不能超过32G
#每天1TB左右的数据量的服务器配置
16C 64G 6T 3台ECS