C/C++ 知识点总结
-
- 静态编译与动态编译
- malloc和new的区别
- 关于STL中的map和hash_map
- STL 中的 set 和 map
- static作用
- extern 的作用
- struct 和 class 区别
- 堆 和 堆栈内存
- 重载
- Overload Override 和 Overwrite
- 排序算法的时空复杂度稳定性分析
- 如何选择排序算法
- CC内存泄露和检测7
- JAVA的垃圾回收机制
- C派生类对象的初始化
- 如何一字节对齐
- 大端和小端对齐
- 重定位
- 简述C虚函数作用及底层实现原理虚函数表
- new内存失败后的正确处理
- 虚函数和纯虚函数的区别
- 设计模式
原文地址:http://blog.csdn.net/quzhongxin/article/details/48833345
1. 静态编译与动态编译
动态编译的可执行文件需要附带一个的动态链接库,在执行时,需要调用其对应动态链接库中的命令。所以其优点一方面是缩小了执行文件本身的体积,另一方面是加快了编译速度,节省了系统资源。缺点一是哪怕是很简单的程序,只用到了链接库中的一两条命令,也需要附带一个相对庞大的链接库;二是如果其他计算机上没有安装对应的运行库,则用动态编译的可执行文件就不能运行。
静态编译就是编译器在编译可执行文件的时候,将可执行文件需要调用的对应动态链接库(.so)中的部分提取出来,链接到可执行文件中去,使可执行文件在运行的时候不依赖于动态链接库。所以其优缺点与动态编译的可执行文件正好互补。
malloc和new的区别
1、new 是c++中的操作符,malloc是c 中的一个函数
2、new 不止是分配内存,而且会调用类的构造函数,同理delete会调用类的析构函数,而malloc则只分配内存,不会进行初始化类成员的工作,同样free也不会调用析构函数
3、内存泄漏对于malloc或者new都可以检查出来的,区别在于new可以指明是那个文件的那一行,而malloc没有这些信息。
4、new 和 malloc效率比较
new可以认为是malloc加构造函数的执行。
new出来的指针是直接带类型信息的。
而malloc返回的都是void指针。
一:new delete 是运算符,malloc,free是函数
malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
对于非内部数据类型的对象而言,光用maloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
因此C++语言需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理与释放内存工作的运算符delete。注意new/delete不是库函数。
关于STL中的map和hash_map
在网上看到有关STL中hash_map的文章,以及一些其他关于STL map和hash_map的资料,总结笔记如下:
1、STL的map底层是用红黑树实现的,查找时间复杂度是log(n);
2、STL的hash_map底层是用hash表存储的,查询时间复杂度是O(1);因为冲突,最差O(n)
3、什么时候用map,什么时候用hash_map?
- 关键看查询的次数和要保证的是整体平均时间还是单个的查询时间。
hash_map : 多次,整体; map:少次,单个查询恒定
- 这个要看具体的应用,不一定常数级别的hash_map一定比log(n)级别的map要好,hash_map的hash函数以及解决地址冲突等都要耗时间,而且众所周知hash表是以空间换时间的,因而hash_map的内存消耗肯定要大,一般情况下,如果记录非常大,考虑hash_map,查找效率会高很多,如果要考虑内存消耗,则要谨慎使用hash_map。
STL 中的 set 和 map
相同点:红黑树实现,O(log n),有序
区别:
set:数据集合,存储的是一个数据,数据不能重复
map: 映射,存储的是一对数据
static作用
- static 函数 主要用来限制作用域,只限本源文件有效
必要的时候声明为内部函数有什么好处呢?
- 可以避免重命名的问题。
内核代码这么多,很容易就遇到了重命名问题,如果声明为内部函数
即使出现重命名,编译器也不会报错。 - 可以提高代码的健壮性。
有些内部函数指定了作用域相对于对外是透明的,外面就调用不了。
所以可以避免代码的错宗复杂引发的错误。
- 可以避免重命名的问题。
- 修饰全局变量, 限定在本源文件有效
全局变量的空间的开辟在静态区,加static修饰后仍然在静态区。
唯一有变化的就是作用域,加static作用域限定在本文件,**不加static的全居变量作用域为整个
源程序(只需在别的源文件extern声明)**。 - 修饰局部变量,延长生命周期
static局部变量的存储在静态存储区,声明周期直到程序结束,它的值始终存在,static局部变量只被初始化一次,下次使用的依然是上一次的值。注意它的作用域没有改变,只在声明的语句块内能够访问。 - C++ static 类成员变量
表示该变量为该类及该类的所有对象所属,值都是保持一致的。内存中只有一个副本。
extern 的作用
- C语言中修饰在变量/函数,表示该变量/函数在别处已经定义,而在此处引用
- extern “C” 是使C++能够调用C语言的库文件的一个手段
在C++中调用C库函数,就需要在C++程序中用extern “C”声明要引用的函数。因为C和C++编译完成的目标代码中的命名规则不同。
struct 和 class 区别
- struct的成员默认权限是public,而class的成员默认权限是private;
- struct的默认继承方式为public,而class的默认继承为private
- “class”这个关键字还用于定义模板参数,就像“typename”。但关键字“struct”不用于定义模板参数。
- struct赋值可以用{};class赋值用构造函数
堆 和 堆栈(内存)
- 堆栈(stack):程序自动分配释放;由高地址向下生长,一块连续的内存区域,分配速度快。存放函数参数值、局部变量
- 堆(heap):程序员分配释放(new, malloc)。由低地址向上生长,分配方式类似链表,需要在空闲内存链表中找到一块大于请求的内存,将多余的内存重新放入空闲链表。会产生碎片,速度慢。
详细描述:
①管理方式:栈由编译器自动管理;堆由程序员控制,使用方便,但易产生内存泄露。
②生长方向:栈向低地址扩展(即”向下生长”),是连续的内存区域;堆向高地址扩展(即”向上生长”),是不连续的内存区域。这是由于系统用链表来存储空闲内存地址,自然不连续,而链表从低地址向高地址遍历。
③空间大小:栈顶地址和栈的最大容量由系统预先规定(通常默认2M或10M);堆的大小则受限于计算机系统中有效的虚拟内存,32位Linux系统中堆内存可达2.9G空间。
④存储内容:栈在函数调用时,首先压入主调函数中下条指令(函数调用语句的下条可执行语句)的地址,然后是函数实参,然后是被调函数的局部变量。本次调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的指令地址,程序由该点继续运行下条可执行语句。堆通常在头部用一个字节存放其大小,堆用于存储生存期与函数调用无关的数据,具体内容由程序员安排。
⑤分配方式:栈可静态分配或动态分配。静态分配由编译器完成,如局部变量的分配。动态分配由alloca函数在栈上申请空间,用完后自动释放。堆只能动态分配且手工释放。
⑥分配效率:栈由计算机底层提供支持:分配专门的寄存器存放栈地址,压栈出栈由专门的指令执行,因此效率较高。堆由函数库提供,机制复杂,效率比栈低得多。Windows系统中VirtualAlloc可直接在进程地址空间中分配一块内存,快速且灵活。
⑦分配后系统响应:只要栈剩余空间大于所申请空间,系统将为程序提供内存,否则报告异常提示栈溢出。
操作系统为堆维护一个记录空闲内存地址的链表。当系统收到程序的内存分配申请时,会遍历该链表寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点空间分配给程序。若无足够大小的空间(可能由于内存碎片太多),有可能调用系统功能去增加程序数据段的内存空间,以便有机会分到足够大小的内存,然后进行返回。,大多数系统会在该内存空间首地址处记录本次分配的内存大小,供后续的释放函数(如free/delete)正确释放本内存空间。
此外,由于找到的堆结点大小不一定正好等于申请的大小,系统会自动将多余的部分重新放入空闲链表中。
⑧碎片问题:栈不会存在碎片问题,因为栈是先进后出的队列,内存块弹出栈之前,在其上面的后进的栈内容已弹出。而频繁申请释放操作会造成堆内存空间的不连续,从而造成大量碎片,使程序效率降低。
可见,堆容易造成内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和内核态切换,内存申请的代价更为昂贵。所以栈在程序中应用最广泛,函数调用也利用栈来完成,调用过程中的参数、返回地址、栈基指针和局部变量等都采用栈的方式存放。所以,建议尽量使用栈,仅在分配大量或大块内存空间时使用堆。
使用栈和堆时应避免越界发生,否则可能程序崩溃或破坏程序堆、栈结构,产生意想不到的后果。
重载
编译器如何解决命名冲突的?
答:作用域+返回类型+函数名+参数列表
- 函数重载:c++的一大特性就是重载(overload),通过重载可以把功能相似的几个函数合为一个,使得程序更加简洁、高效。同名不同参的函数。
- 运算符重载:用于对象,将类函数功能赋予现有运算符,方便使用
Overload、 Override 和 Overwrite
- Overload 重载
- 同名不同参,注意参数有无const也视为不同
- 仅返回值不同,不构成重载
- 构成重载的各个函数具有相同的作用域。处于同一文件/全局域/namespace 内的同名不同参函数;对类成员函数,则发生在同一类域中。(基类和派生类之间不构成重载)
- Override 覆盖
- 不同作用域:分别位于基类和派生类
- 基类函数必须为vitrual函数,而派生类函数和基类虚函数同名同参
- Overwrite 隐藏
- 派生类和基类函数同名不同参,不论基类函数是否是vitrual,派生类函数被隐藏
- 派生类和基类非vitrual函数同名同参,基类函数被隐藏
- 三者之间区分
- overload是同一个类中的成员函数间的水平关系;而override/overwrite都是派生类和基类间的垂直关系
- override覆盖的前提或特点是基类函数必须为virtual
- override覆盖的结果是根据对象类型决定调用哪个函数(多态);而Overwrite隐藏则表现为根据指针类型决定调用哪个函数,这是覆盖和隐藏最直观的区别。
排序算法的时空复杂度、稳定性分析
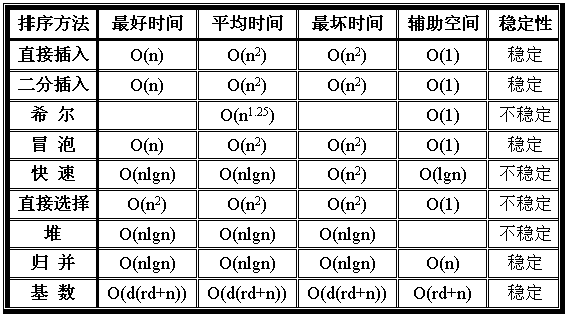
注意:快速排序的空间复杂度是因为递归造成的栈空间占用。(O(lg n)~O(n))
归并排序的空间复杂度是O(n+lg n)=O(n)
如何选择排序算法
从算法的简单性将排序算法分为:
- 简单算法:冒泡、插入、选择
- 改进算法:希尔、堆排序、归并排序、快排
- 从时间复杂度来看
- 从平均情况,后三种改进算法要胜过希尔排序,远胜简单算法
- 从最好情况(已经有序),冒泡和插入排序最优,改进算法最差
- 从最差情况(逆序),堆排序和归并排序最优,远胜快排和简单算法
- 从空间复杂度来看
- 简单算法都不占用额外空间。
- 堆排序是在数组上原位建堆,O(1);
- 快排因为递归栈占用,O(lgn)~O(n)递归深度;
- 归并,需要辅助数组O(n);
所以如果要求考虑内存空间,不能选快排和归并
- 从稳定性来看
归并排序最好。当然简单排序中的冒泡和插入也是稳定的,但同时考虑时间,则应选归并。 - 待排序的个数
待排序个数n越小,采用简单算法越合适;反之,n越大,选择改进算法。这也是快排中,对于小数组使用插入排序完成的原因。 - 待排序数据的关键字本身信息量的大小
如果信息量大,则交换的代价大。此时选择排序最优,先大量比较然后一次交换,O(n)次交换。
对于待排序个数不大,而关键字信息量大的情况,简单算法占优。
[C/C++内存泄露和检测][7]
JAVA的垃圾回收机制
C++派生类对象的初始化
程序中派生类构造函数首部如下:
Student1(int n, string nam,int n1, string nam1,int a, string ad):Student(n,nam),monitor(n1,nam1)在上面的构造函数中有6个形参,前两个作为基类构造函数的参数,第3、第4个作为子对象构造函数的参数,第5、第6个是用作派生类数据成员初始化的。
归纳起来,定义派生类构造函数的一般形式为:
派生类构造函数名(总参数表列): 基类构造函数名(参数表列), 子对象名(参数表列)
{
派生类中新增数成员据成员初始化语句
}
执行派生类构造函数的顺序是:
- 调用基类构造函数,对基类数据成员初始化;
- 调用子对象构造函数,对子对象数据成员初始化;
- 再执行派生类构造函数本身,对派生类数据成员初始化。
如何一字节对齐
// #pragma 控制编译器状态(其他参数 messege, once 等)
#pragma pack(1) //设置 1 字节对齐
...
#pragma pack() // 取消字节对齐,恢复默认状态大端和小端对齐
大端对齐:数据的低位存储在内存的高地址上,数据高位存储存储在内存的低地址上;(字符串存储)
小端对齐:数据的低位存储在内存的低地址上,数据高位存储存储在内存的高地址上;
//例如 char p[2];,
//它用大端模式表示一个数的计算方式为:
unsigned int result =p[0];
result =(result <<8)|p[1];
//用小端模式表示一个数的计算方式为:
unsigned int result =p[0];
result =(p[1]<<8)|result;重定位
程序进行重定位的技术按重定位的时机可分为两种:静态重定位和动态重定位。
静态重定位:是在目标程序装入内存时,由装入程序对目标程序中的指令和数据的地址进行修改,即把程序的逻辑地址都改成实际的地址。对每个程序来说,这种地址变换只是在装入时一次完成,在程序运行期间不再进行重定位。
优点:是无需增加硬件地址转换机构,便于实现程序的静态连接。在早期计算机系统中大多采用这种方案。
缺点:(1)程序的存储空间只能是连续的一片区域,而且在重定位之后就不能再移动。这不利于内存空间的有效使用。(2)各个用户进程很难共享内存中的同一程序的副本。
动态重定位:是在程序执行期间每次访问内存之前进行重定位。这种变换是靠硬件地址变换机构实现的。通常采用一个重定位寄存器,其中放有当前正在执行的程序在内存空间中的起始地址,而地址空间中的代码在装入过程中不发生变化。
优点:(1)程序占用的内存空间动态可变,不必连续存放在一处。(2)比较容易实现几个进程对同一程序副本的共享使用。
缺点:是需要附加的硬件支持,增加了机器成本,而且实现存储管理的软件算法比较复杂。
现在一般计算机系统中都采用动态重定位方法。
简述C++虚函数作用及底层实现原理(虚函数表)
C++中虚函数使用虚函数表 和 虚函数表指针实现,虚函数表是一个类的虚函数的地址表,用于索引类本身以及父类的虚函数的地 址,假如子类的虚函数重写了父类的虚函数,则对应在虚函数表中会把对应的虚函数替换为子类的 虚函数的地址;虚函数表指针存在于每个对象中(通常出于效率考虑,会放在对象的开始地址处), 它指向对象所在类的虚函数表的地址;在多继承环境下,会存在多个虚函数表指针,分别指向对应 不同基类的虚函数表。
new内存失败后的正确处理
- 负责内存申请的operator new才会抛出异常std::bad_alloc,用catch捕捉
- 使用
int*p = new检查 p 是否为NULLint;
虚函数和纯虚函数的区别
1、纯虚函数声明如下: virtual void funtion1()=0; 纯虚函数一定没有定义,纯虚函数用来规范派生类的行为,即接口。包含纯虚函数的类是抽象类,抽象类不能定义实例,但可以声明指向实现该抽象类的具体类的指针或引用。
2、虚函数声明如下:virtual ReturnType FunctionName(Parameter);虚函数必须实现,如果不实现,编译器将报错,错误提示为:
error LNK****: unresolved external symbol "public: virtual void __thiscall ClassName::virtualFunctionName(void)"
3、对于虚函数来说,父类和子类都有各自的版本。由多态方式调用的时候动态绑定。
4、实现了纯虚函数的子类,该纯虚函数在子类中就编程了虚函数,子类的子类即孙子类可以覆盖该虚函数,由多态方式调用的时候动态绑定。
5、虚函数是C++中用于实现多态(polymorphism)的机制。核心理念就是通过基类访问派生类定义的函数。
6、在有动态分配堆上内存的时候,析构函数必须是虚函数,但没有必要是纯虚的。
7、友元不是成员函数,只有成员函数才可以是虚拟的,因此友元不能是虚拟函数。但可以通过让友元函数调用虚拟成员函数来解决友元的虚拟问题。
8、析构函数应当是虚函数,将调用相应对象类型的析构函数,因此,如果指针指向的是子类对象,将调用子类的析构函数,然后自动调用基类的析构函数。
设计模式
单例模式:只有一个实例存在的类。
桥接模式:将一个对象的抽象部分从实现中分离出来。
组合模式:多个对象组成树状结构来表示局部与整体,这样用户可以一样的对待单个对象和对象的组合。
外观模式:为子系统中的一组接口提供一个一致的界面, 外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
原文地址:http://blog.csdn.net/quzhongxin/article/details/48833345