山东大学计算机系统原理实验:设计MIPS五级流水线模拟器中的Cache
计算机系统原理实验:设计MIPS五级流水线模拟器中的Cache
- 一、所需环境
- 二、基础知识
-
- cache知识
- 实验要求介绍
- 延迟机制
- 三、具体实现
-
- 举例icache
- 最后总结
)
设计cache的实验是从19级才开始进行的,所以刚开始做实验的时候我也摸不到什么头绪,也走了很多弯路,一直在门外兜圈子,也不知道该怎么开始,希望我的经验能够帮助学弟学妹们解答疑惑,避免浪费太多的时间。 ——SDU 19 ZRK
一、所需环境
如果实在windows系统下进行的话,首先需要安装MinGW,MinGW安装教程
其次还需要安装python,安装python和配置环境的教程在CSND上还是比较多的,大家自行安装即可。
但安装好以后,可能依旧跑不起来程序,还需要安装的插件按照界面提示安装即可(有啥问题找助教嘛)
二、基础知识
cache知识
cache的知识,大家在课上都应该学过了,不过可能也没有听的太透彻,大家可以根据这一篇博客再去学习一下,[cache写回策略](https://blog.csdn.net/xingzhe22222/article/details/81988101)实验要求介绍
按照19级的实验文档来说,看完实验文档就去做实验还是一头雾水啊。那么我就来帮大家分析一下:|-your_lab_dir
|-Makefile
|-run2 : python2运行脚本
|-run3 : python3运行脚本
|-basesim : 标称对比答案使用
|-basesim.exe : 标称对比答案使用,兼容windows
|-inputs/ : 测试文件
|-src/ : 可以自行添加其他文件,如cache.c,cache.h
|-pipe.c :流水线程序,自行修改
|-pipe.h:
|-shell.c
|-shell.h
|-mips.h : MIPS相关的定义
再进行试验之前,大家还是要读一下pipe.c,pipe.h,shell.c,shell.h中的代码,才能对整个实验流程有深刻的体会。例如其中几个比较重要的变量:stat_cycles ,stat_inst_retire ,stat_inst_fetch等,都要搞清楚是干什么用的。
大家只需要在src文件夹下,新建cache.c cache.h ,然后对pipe.c进行修改就可以了。
并且由于在他给出的实验文件中pipe.c中,没有加入延迟机制,需要自行加入延迟机制。
延迟机制
为什么会产生延迟?
访问内存的时间消耗,是远大于CPU的执行时间的,因此会产生延迟。当cpu进行取指令,或者进行访问内存时,按照题目中的要求有50个cycle延迟消耗。
那么如果说在五级流水线的第一个阶段进行取指令,但是指令不在cache中,我们需要去内存中取指令,需要消耗50个CPU周期的时间,那么紧跟在后面的译码,执行,访存,写回都不能进行了吗?并不是的,我希望你能深刻体会到5级流水线的思想,仔细思考一下这个问题。
之前提到的几个变量中的stat_cycles,是用来记录cpu执行的周期数。对于一个物理上真实的CPU来说,在一个周期中,会同时执行IF,ID,EX,MEM,WB这五个操作,并且是5个不同指令的操作。
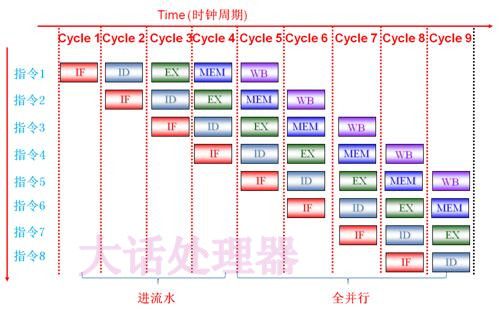
有些人在处理访存延迟时会直接将stat_cycles加50,这样的处理是错误的。这就相当于,他本来要等待50个周期,但你却直接把表拨快了50个周期,而他并没有真正的进行等待。正确的处理应该是,因为在源代码中,对于五个阶段的操作,每个阶段对应一个函数,所以例如当取指令进行等待时可以直接将对应的函数return,连续return 50次以达到等待50个周期的效果。
并且,这与直接加50的区别是:如果直接加50,相当于IF,ID,EX,MEM,WB都同时暂停了,等了50个周期,接着又同时继续。然而,事实上是,如果IF进行等待,ID,EX,MEM,WB在接下来的几个周期内可能还会继续进行处理,在接下来也会进入空转等待,所以是有区别的。建议大家去了解一下冒泡机制。
三、具体实现
举例icache
typedef struct
{
uint32_t dirty_bit;
uint32_t lru;
uint32_t tag;
uint8_t data[LINE_SIZE];//32字节
}cache_Line;
typedef struct
{
uint32_t lru_now;
cache_Line line[SETS_NUM][WAYS_NUM];//4路,64组
}i_Cache;
这样我们就构造了一个icache,当然不同的人会有不同的构造策略,我的方法也不一定是最优解。
void icache_init();
int icache_hit(uint32_t address);
uint32_t icache_get_32_hit(uint32_t address);
uint32_t icache_get_32_miss(uint32_t address);
我们用对应的函数来完成icache的各种功能,icache的功能较为简单,并不涉及写回,只涉及从cache中读取。具体cache写回的流程在一开始我就给出了资料,希望大家好好参考。剩余的拓展部份要看大家的能力了,对于lru,lfu等替换算法可以在网上搜到资料,但具体的实现,每个人的方法都不一样。
最后总结
要完成这个实验其实也并不难,关键是读懂他给出的代码。有写环节的处理,完全可以仿照源代码进行。而且,配合注释,是可以发现源程序中也有许多延迟的处理。关键是下功夫,弄懂源码,但不要求全都读懂,只需要弄懂关键部分即可。最后给出一个问题,这个问题时助教提出来的,在验收时问住了很多人.
//在函数pipe_cycle()中
pipe_stage_wb();
pipe_stage_mem();
pipe_stage_execute();
pipe_stage_decode();
pipe_stage_fetch();
为什么流水线的5个环节是倒过来写的?实际上,在真实的cpu中,五个环节同时进行,那么五个环节顺序是怎样的应该都无妨才对。但是这里是模拟流水线执行,由于程序的执行只能一条一条执行,所以要讲求一个顺序,但为什么是倒过来写呢?而不是按照IF,ID,EX,MEM,WB的顺序呢?希望大家继续按照这个思路思考,关键是读代码。