【Spring基础系列2】很全的Spring IOC基础知识

主要讲解IOC和DI理解、BeanFactory和ApplicationContext、Bean生命周期和加载过程、BeanFactory和FactoryBean区别,基本包括IOC的所有重要基础知识。
往期精选(欢迎转发~~)
-
如何看待程序员35岁职业危机?
-
Java全套学习资料(14W字),耗时半年整理
-
我肝了三个月,为你写出了GO核心手册
-
消息队列:从选型到原理,一文带你全部掌握
-
肝了一个月的ETCD,从Raft原理到实践
-
更多...
温馨提示:全文接近1W字,感兴趣的同学可以收藏起来慢慢看。
前言
这两天一直在学习Spring,我把Spring分成两部分来学,分别为IOC和AOP,然后IOC我又分为纯理论知识和常用注解的使用姿势,这篇文章主要讲IOC的纯理论部分,所以看起来可能会有点枯燥,但是仔细体味一下,感觉里面还是有点意思。这些纯理论知识,基本都是来自于网络博客,我也不能再去看代码,然后重复造轮子,但是网上的示例,我肯定会自己亲自运行一遍才会贴出来。然后注解的使用,我也会自己使用完后,才会去讲解使用的方法。
至于IOC的常用注解,之前在文章《【Spring基础系列1】基于注解装配Bean》写过一部分,下一篇文章会再完善另外一部分。
谈谈对Spring IOC的理解
学习过Spring框架的人一定都会听过Spring的IoC(控制反转) 、DI(依赖注入)这两个概念,对于初学Spring的人来说,总觉得IOC、DI这两个概念是模糊不清的,然后网上讲解的也五花八门,我看了很多相关的博客,发现有一些博客总结的很到位,下面就分享2位对这两个概念的理解,应该是我看过的讲解最到位的2种。
分享Iteye的开涛对Ioc的精彩讲解
首先要分享的是Iteye的开涛这位技术牛人对Spring框架的IOC的理解,写得非常通俗易懂,以下内容全部来自原文,原文地址:http://jinnianshilongnian.iteye.com/blog/1413846
IoC是什么
Ioc—Inversion of Control,即“控制反转”,不是什么技术,而是一种设计思想。在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。如何理解好Ioc呢?理解好Ioc的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”,那我们来深入分析一下:
-
谁控制谁,控制什么:传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对 象的创建;谁控制谁?当然是IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
-
为何是反转,哪些方面反转了:有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
用图例说明一下,传统程序设计如图,都是主动去创建相关对象然后再组合起来: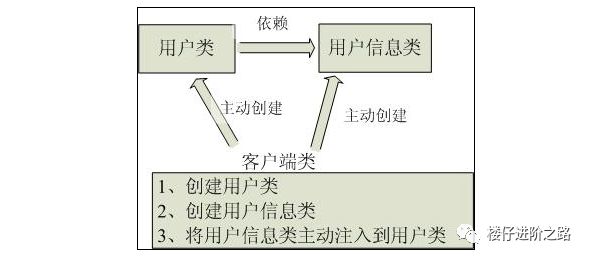
当有了IoC/DI的容器后,在客户端类中不再主动去创建这些对象了,如图所示:

IoC能做什么
IoC 不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是 松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
IoC很好的体现了面向对象设计法则之一—— 好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
IoC和DI
DI—Dependency Injection,即“依赖注入”:组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
理解DI的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”,那我们来深入分析一下:
-
谁依赖于谁:当然是应用程序依赖于IoC容器;
-
为什么需要依赖:应用程序需要IoC容器来提供对象需要的外部资源;
-
谁注入谁:很明显是IoC容器注入应用程序某个对象,应用程序依赖的对象;
-
注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
IoC和DI由什么关系呢?其实它们是同一个概念的不同角度描述,由于控制反转概念比较含糊(可能只是理解为容器控制对象这一个层面,很难让人想到谁来维护对象关系),所以2004年大师级人物Martin Fowler又给出了一个新的名字:“依赖注入”,相对IoC 而言,“依赖注入”明确描述了“被注入对象依赖IoC容器配置依赖对象”。
看过很多对Spring的Ioc理解的文章,好多人对Ioc和DI的解释都晦涩难懂,反正就是一种说不清,道不明的感觉,读完之后依然是一头雾水,感觉就是开涛这位技术牛人写得特别通俗易懂,他清楚地解释了IoC(控制反转) 和DI(依赖注入)中的每一个字,读完之后给人一种豁然开朗的感觉。我相信对于初学Spring框架的人对Ioc的理解应该是有很大帮助的。
分享Bromon的blog上对IoC与DI的讲解
IoC(控制反转)
首先想说说IoC(Inversion of Control,控制反转)。这是spring的核心,贯穿始终。所谓IoC,对于spring框架来说,就是由spring来负责控制对象的生命周期和对象间的关系。这是什么意思呢,举个简单的例子,我们是如何找女朋友的?常见的情况是,我们到处去看哪里有长得漂亮身材又好的mm,然后打听她们的兴趣爱好、qq号、电话号、ip号、iq号………,想办法认识她们,投其所好送其所要,然后嘿嘿……这个过程是复杂深奥的,我们必须自己设计和面对每个环节。传统的程序开发也是如此,在一个对象中,如果要使用另外的对象,就必须得到它(自己new一个,或者从JNDI中查询一个),使用完之后还要将对象销毁(比如Connection等),对象始终会和其他的接口或类藕合起来。
那么IoC是如何做的呢?有点像通过婚介找女朋友,在我和女朋友之间引入了一个第三者:婚姻介绍所。婚介管理了很多男男女女的资料,我可以向婚介提出一个列表,告诉它我想找个什么样的女朋友,比如长得像李嘉欣,身材像林熙雷,唱歌像周杰伦,速度像卡洛斯,技术像齐达内之类的,然后婚介就会按照我们的要求,提供一个mm,我们只需要去和她谈恋爱、结婚就行了。简单明了,如果婚介给我们的人选不符合要求,我们就会抛出异常。整个过程不再由我自己控制,而是有婚介这样一个类似容器的机构来控制。Spring所倡导的开发方式就是如此,所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
DI(依赖注入)
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了 spring我们就只需要告诉spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A不需要知道。在系统运行时,spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系的控制。A需要依赖 Connection才能正常运行,而这个Connection是由spring注入到A中的,依赖注入的名字就这么来的。那么DI是如何实现的呢?Java 1.3之后一个重要特征是反射(reflection),它允许程序在运行的时候动态的生成对象、执行对象的方法、改变对象的属性,spring就是通过反射来实现注入的。
理解了IoC和DI的概念后,一切都将变得简单明了,剩下的工作只是在spring的框架中堆积木而已。
Spring IOC原理总结
依赖注入流程
这个博主通过磨咖啡的故事,生动讲解了注入流程,将生产咖啡总结为两个阶段:
-
采摘和收集“咖啡豆”(bean)
-
研磨和烹饪咖啡
阶段一:收集和注册
第一阶段可以认为是构建和收集bean定义的阶段,在这个阶段中,我们可以通过XML或者Java代码的方式定义一些bean,然后通过手动组装或者让容器基于某些机制自动扫描的形式,将这些bean定义收集到IOC容器中。
假设我们以XML配置的形式来收集并注册单一bean,一般形式如下:
...
如果嫌逐个收集bean定义麻烦,想批量地收集并注册到IOC容器中,我们也可以通过XML Schema形式的配置进行批量扫描并采集和注册:
阶段二:分析和组装
当第一阶段工作完成后,我们可以先暂且认为IOC容器中充斥着一个个独立的bean,它们之间没有任何关系。但实际上,它们之间是有依赖关系的,所以,IOC容器在第二阶段要干的事情就是分析这些已经在IOC容器之中的bean,然后根据它们之间的依赖关系先后组装它们。如果IOC容器发现某个bean依赖另一个bean,它就会将这另一个bean注入给依赖它的那个bean,直到所有到bean的依赖都注入完成,所有bean都“整装待发”,整个IOC容器都工作即算完成。
至于分析和组装的依据,Spring框架最早是通过XML配置文件的形式来描述bean与bean之间的关系,随着Java业界研发技术和理念都转变,基于Java代码和Annotation元信息的描述方式也日渐兴盛(比如@Autowired和@Inject),但不管使用哪种方式,都只是为了简化绑定逻辑描述的各种“表象”,最终都是为本阶段都最终目的服务。
这个讲解只是给大家对IOC有一个初步的认识,下面才是核心的部分。
IOC容器的原理
IOC容器其实就是一个大工厂,它用来管理我们所有的对象以及依赖关系。
-
原理就是通过Java的反射技术来实现的!通过反射我们可以获取类的所有信息(成员变量、类名等等等)!
-
再通过配置文件(xml)或者注解来描述类与类之间的关系
-
我们就可以通过这些配置信息和反射技术来构建出对应的对象和依赖关系了!
上面描述的技术只要学过点Java的都能说出来,我们简单来看看实际Spring IOC容器是怎么实现对象的创建和依赖的:
-
根据Bean配置信息在容器内部创建Bean定义注册表
-
根据注册表加载、实例化bean、建立Bean与Bean之间的依赖关系
-
将这些准备就绪的Bean放到Map缓存池中,等待应用程序调用
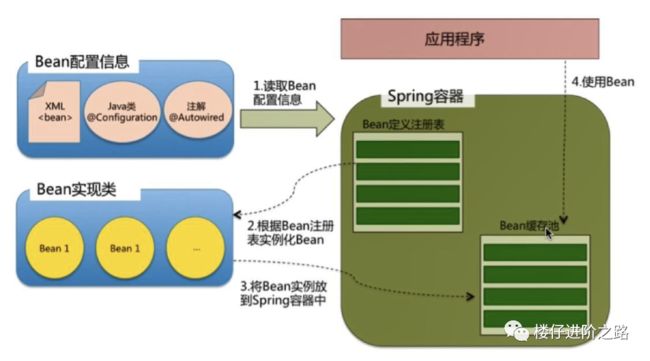
Spring容器(Bean工厂)可简单分成两种:
-
BeanFactory:这是最基础、面向Spring的
-
ApplicationContext:这是在BeanFactory基础之上,面向使用Spring框架的开发者。提供了一系列的功能!
几乎所有的应用场合都是使用ApplicationContext!
BeanFactory vs ApplicationContext
BeanFactory
BeanFactory 是 Spring 的“心脏”。它就是 Spring IoC 容器的真面目。Spring 使用 BeanFactory 来实例化、配置和管理 Bean。
BeanFactory:是IOC容器的核心接口, 它定义了IOC的基本功能,我们看到它主要定义了getBean方法。getBean方法是IOC容器获取bean对象和引发依赖注入的起点。方法的功能是返回特定的名称的Bean。
BeanFactory 是初始化 Bean 和调用它们生命周期方法的“吃苦耐劳者”。注意,BeanFactory 只能管理单例(Singleton)Bean 的生命周期。它不能管理原型(prototype,非单例)Bean 的生命周期。这是因为原型 Bean 实例被创建之后便被传给了客户端,容器失去了对它们的引用。
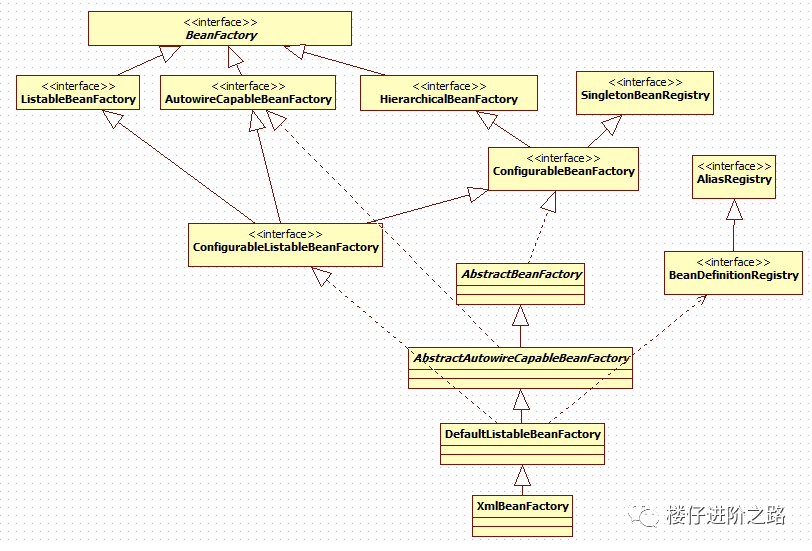
BeanFactory有着庞大的继承、实现体系,有众多的子接口、实现类。来看一下BeanFactory的基本类体系结构(接口为主):
下面写了一大堆,我觉得仅供了解即可:
BeanFactory作为一个主接口不继承任何接口,暂且称为一级接口。
有3个子接口继承了它,进行功能上的增强。这3个子接口称为二级接口。
ConfigurableBeanFactory可以被称为三级接口,对二级接口HierarchicalBeanFactory进行了再次增强,它还继承了另一个外来的接口SingletonBeanRegistry
ConfigurableListableBeanFactory是一个更强大的接口,继承了上述的所有接口,无所不包,称为四级接口。 (这4级接口是BeanFactory的基本接口体系。继续,下面是继承关系的2个抽象类和2个实现类:)
AbstractBeanFactory作为一个抽象类,实现了三级接口ConfigurableBeanFactory大部分功能。
AbstractAutowireCapableBeanFactory同样是抽象类,继承自AbstractBeanFactory,并额外实现了二级接口AutowireCapableBeanFactory
DefaultListableBeanFactory继承自AbstractAutowireCapableBeanFactory,实现了最强大的四级接口ConfigurableListableBeanFactory,并实现了一个外来接口BeanDefinitionRegistry,它并非抽象类。
最后是最强大的XmlBeanFactory,继承自DefaultListableBeanFactory,重写了一些功能,使自己更强大。
再来看一下BeanFactory的源码:
public interface BeanFactory {
/**
* 用来引用一个实例,或把它和工厂产生的Bean区分开,就是说,如果一个FactoryBean的名字为a,那么,&a会得到那个Factory
*/
String FACTORY_BEAN_PREFIX = "&";
/*
* 四个不同形式的getBean方法,获取实例
*/
Object getBean(String name) throws BeansException;
T getBean(String name, Class requiredType) throws BeansException;
T getBean(Class requiredType) throws BeansException;
Object getBean(String name, Object... args) throws BeansException;
boolean containsBean(String name); // 是否存在
boolean isSingleton(String name) throws NoSuchBeanDefinitionException;// 是否为单实例
boolean isPrototype(String name) throws NoSuchBeanDefinitionException;// 是否为原型(多实例)
boolean isTypeMatch(String name, Class targetType)
throws NoSuchBeanDefinitionException;// 名称、类型是否匹配
Class getType(String name) throws NoSuchBeanDefinitionException; // 获取类型
String[] getAliases(String name);// 根据实例的名字获取实例的别名
}
具体:
-
4个获取实例的方法。getBean的重载方法。
-
4个判断的方法。判断是否存在,是否为单例、原型,名称类型是否匹配。
-
1个获取类型的方法、一个获取别名的方法。根据名称获取类型、根据名称获取别名。一目了然!
总结:这10个方法,很明显,这是一个典型的工厂模式的工厂接口。
看一个简单的示例:
@Data
public class Cat implements Animal {
private String catName = "罗小黑";
}
@Data
public class Pets {
@Resource
private Cat cat;
public static void main(String args[]) {
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
org.springframework.core.io.Resource res = resolver.getResource("classpath:applicationContext.xml");
BeanFactory factory = new XmlBeanFactory(res);
Pets pets=factory.getBean("pets", Pets.class);
System.out.println(pets.toString());
}
}
// 输出:
// Pets(cat=Cat(catName=罗小黑))
这里需要到applicationContext.xml添加一下配置:
解读一下:
-
XmlBeanFactory通过Resource装载Spring配置信息冰启动IoC容器,然后就可以通过factory.getBean从IoC容器中获取Bean了。
-
通过BeanFactory启动IoC容器时,并不会初始化配置文件中定义的Bean,初始化动作发生在第一个调用时。
-
对于单实例(singleton)的Bean来说,BeanFactory会缓存Bean实例,所以第二次使用getBean时直接从IoC容器缓存中获取Bean。
这种方式非常不建议使用,因为我用这种方式,发现添加的@Service注解不能生效.
ApplicationContext
如果说BeanFactory是Spring的心脏,那么ApplicationContext就是完整的躯体了,ApplicationContext由BeanFactory派生而来,提供了更多面向实际应用的功能。在BeanFactory中,很多功能需要以编程的方式实现,而在ApplicationContext中则可以通过配置实现。
BeanFactorty接口提供了配置框架及基本功能,但是无法支持spring的aop功能和web应用。而ApplicationContext接口作为BeanFactory的派生,因而提供BeanFactory所有的功能。而且ApplicationContext还在功能上做了扩展,相较于BeanFactorty,ApplicationContext还提供了以下的功能:
-
MessageSource, 提供国际化的消息访问
-
资源访问,如URL和文件
-
事件传播特性,即支持aop特性
-
载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层
ApplicationContext:是IOC容器另一个重要接口, 它继承了BeanFactory的基本功能, 同时也继承了容器的高级功能,如:MessageSource(国际化资源接口)、ResourceLoader(资源加载接口)、ApplicationEventPublisher(应用事件发布接口)等。

ApplicationContext 继承了 HierarchicalBeanFactory 和 ListableBeanFactory 接口,在此基础上,还通过多个其他的接口扩展了 BeanFactory 的功能:
下面都是八股文,也是仅作了解即可:
ClassPathXmlApplicationContext:默认从类路径加载配置文件
FileSystemXmlApplicationContext:默认从文件系统中装载配置文件 ApplicationEventPublisher:让容器拥有发布应用上下文事件的功能,包括容器启动事件、关闭事件等。实现了 ApplicationListener 事件监听接口的 Bean 可以接收到容器事件 , 并对事件进行响应处理 。在 ApplicationContext 抽象实现类AbstractApplicationContext 中,我们可以发现存在一个 ApplicationEventMulticaster,它负责保存所有监听器,以便在容器产生上下文事件时通知这些事件监听者。
MessageSource:为应用提供 i18n 国际化消息访问的功能;
ResourcePatternResolver :所 有 ApplicationContext 实现类都实现了类似于PathMatchingResourcePatternResolver 的功能,可以通过带前缀的 Ant 风格的资源文件路径装载 Spring 的配置文件。
LifeCycle:该接口是 Spring 2.0 加入的,该接口提供了 start()和 stop()两个方法,主要用于控制异步处理过程。在具体使用时,该接口同时被 ApplicationContext 实现及具体 Bean 实现, ApplicationContext 会将 start/stop 的信息传递给容器中所有实现了该接口的 Bean,以达到管理和控制 JMX、任务调度等目的。
ConfigurableApplicationContext 扩展于 ApplicationContext,它新增加了两个主要的方法:refresh()和 close(),让 ApplicationContext 具有启动、刷新和关闭应用上下文的能力。在应用上下文关闭的情况下调用 refresh()即可启动应用上下文,在已经启动的状态下,调用 refresh()则清除缓存并重新装载配置信息,而调用close()则可关闭应用上下文。这些接口方法为容器的控制管理带来了便利,但作为开发者,我们并不需要过多关心这些方法。
还是看一下ClassPathXmlApplicationContext的使用姿势:
ApplicationContext context =new ClassPathXmlApplicationContext("classpath:applicationContext.xml");
//ApplicationContext context =new ClassPathXmlApplicationContext("file:/Users/mengloulv/java-workspace/Demo5/src/main/resources/applicationContext.xml");
Pets pets=context.getBean("pets", Pets.class);
System.out.println(pets.toString());
再看一下FileSystemXmlApplicationContext的使用姿势:
ApplicationContext context =new FileSystemXmlApplicationContext("file:/Users/mengloulv/java-workspace/Demo5/src/main/resources/applicationContext.xml");
Pets pets=context.getBean("pets", Pets.class);
System.out.println(pets.toString());
个人还是偏向使用ClassPathXmlApplicationContext,可以使用相对路径。
后面还有个WebApplicationContext,反正我是用的少,就不介绍了。
BeanFactory和ApplicationContext的区别
1.BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化,这样,我们就不能发现一些存在的Spring的配置问题。而ApplicationContext则相反,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误。相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
BeanFacotry延迟加载,如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常;而ApplicationContext则在初始化自身是检验,这样有利于检查所依赖属性是否注入;所以通常情况下我们选择使用 ApplicationContext。应用上下文则会在上下文启动后预载入所有的单实例Bean。通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
2.BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。(Applicationcontext比 beanFactory 加入了一些更好使用的功能。而且 beanFactory 的许多功能需要通过编程实现而 Applicationcontext 可以通过配置实现。比如后处理 bean , Applicationcontext 直接配置在配置文件即可而 beanFactory 这要在代码中显示的写出来才可以被容器识别。)
3.beanFactory主要是面对与 spring 框架的基础设施,面对 spring 自己。而 Applicationcontex 主要面对与 spring 使用的开发者。基本都会使用 Applicationcontex 并非 beanFactory 。
Bean的生命周期&加载过程
Bean的生命周期
看了上面那么多内容,是不是基本快完了?NO,NO,NO,重要的部分在这里!

-
当调用者通过 getBean(beanName)向容器请求某一个 Bean 时,如果容器注册了org.springframework.beans.factory.config.InstantiationAwareBeanPostProcessor 接口,在实例化 Bean 之前,将调用接口的 postProcessBeforeInstantiation()方法;
-
根据配置情况调用 Bean 构造函数或工厂方法实例化 Bean;
-
如果容器注册了 InstantiationAwareBeanPostProcessor 接口,在实例化 Bean 之后,调用该接口的 postProcessAfterInstantiation()方法,可在这里对已经实例化的对象进行一些“梳妆打扮”;
-
如果 Bean 配置了属性信息,容器在这一步着手将配置值设置到 Bean 对应的属性中,不过在设置每个属性之前将先调用InstantiationAwareBeanPostProcessor 接口的postProcessPropertyValues()方法;
-
调用 Bean 的属性设置方法设置属性值;
-
如果 Bean 实现了 org.springframework.beans.factory.BeanNameAware 接口,将调用setBeanName()接口方法,将配置文件中该 Bean 对应的名称设置到 Bean 中;
-
如果 Bean 实现了 org.springframework.beans.factory.BeanFactoryAware 接口,将调用 setBeanFactory()接口方法,将 BeanFactory 容器实例设置到 Bean 中;
-
如果 BeanFactory 装配了 org.springframework.beans.factory.config.BeanPostProcessor后处理器,将调用 BeanPostProcessor 的 Object postProcessBeforeInitialization(Object bean, String beanName)接口方法对 Bean 进行加工操作。其中入参 bean 是当前正在处理的 Bean,而 beanName 是当前 Bean 的配置名,返回的对象为加工处理后的 Bean。用户可以使用该方法对某些 Bean 进行特殊的处理,甚至改变 Bean 的行为, BeanPostProcessor 在 Spring 框架中占有重要的地位,为容器提供对 Bean 进行后续加工处理的切入点, Spring 容器所提供的各种“神奇功能”(如 AOP,动态代理等)都通过 BeanPostProcessor 实施;
-
如果 Bean 实现了 InitializingBean 的接口,将调用接口的 afterPropertiesSet()方法;
-
如果在通过 init-method 属性定义了初始化方法,将执行这个方法;
-
BeanPostProcessor 后处理器定义了两个方法:其一是 postProcessBeforeInitialization() 在第 8 步调用;其二是 Object postProcessAfterInitialization(Object bean, String beanName)方法,这个方法在此时调用,容器再次获得对 Bean 进行加工处理的机会;
-
如果在中指定 Bean 的作用范围为 scope=“prototype”,将 Bean 返回给调用者,调用者负责 Bean 后续生命的管理, Spring 不再管理这个 Bean 的生命周期。如果作用范围设置为 scope=“singleton”,则将 Bean 放入到 Spring IoC 容器的缓存池中,并将 Bean引用返回给调用者, Spring 继续对这些 Bean 进行后续的生命管理;
-
对于 scope=“singleton”的 Bean,当容器关闭时,将触发 Spring 对 Bean 的后续生命周期的管理工作,首先如果 Bean 实现了 DisposableBean 接口,则将调用接口的afterPropertiesSet()方法,可以在此编写释放资源、记录日志等操作;
-
对于 scope=“singleton”的 Bean,如果通过的 destroy-method 属性指定了 Bean 的销毁方法, Spring 将执行 Bean 的这个方法,完成 Bean 资源的释放等操作。
可以将这些方法大致划分为三类:
-
Bean 自身的方法:如调用 Bean 构造函数实例化 Bean,调用 Setter 设置 Bean 的属性值以及通过的 init-method 和 destroy-method 所指定的方法;
-
Bean 级生命周期接口方法:如 BeanNameAware、 BeanFactoryAware、 InitializingBean 和 DisposableBean,这些接口方法由 Bean 类直接实现;
-
容器级生命周期接口方法:在上图中带“★” 的步骤是由 InstantiationAwareBean PostProcessor 和 BeanPostProcessor 这两个接口实现,一般称它们的实现类为“ 后处理器” 。后处理器接口一般不由 Bean 本身实现,它们独立于 Bean,实现类以容器附加装置的形式注册到 Spring 容器中并通过接口反射为 Spring 容器预先识别。当Spring 容器创建任何 Bean 的时候,这些后处理器都会发生作用,所以这些后处理器的影响是全局性的。当然,用户可以通过合理地编写后处理器,让其仅对感兴趣Bean 进行加工处理
ApplicationContext 和 BeanFactory 另一个最大的不同之处在于:ApplicationContext会利用 Java 反射机制自动识别出配置文件中定义的 BeanPostProcessor、 InstantiationAwareBeanPostProcessor 和 BeanFactoryPostProcessor,并自动将它们注册到应用上下文中;而后者需要在代码中通过手工调用 addBeanPostProcessor()方法进行注册。这也是为什么在应用开发时,我们普遍使用 ApplicationContext 而很少使用 BeanFactory 的原因之一。
这是对Bean的生命周期解释的最详细的一篇博文,没有之一,这个八股文就需要多看几遍,虽然有些地方还不能完全理解,我打算后面再看看源码,应该就能理解了。
Bean加载过程
Spring的高明之处在于,它使用众多接口描绘出了所有装置的蓝图,构建好Spring的骨架,继而通过继承体系层层推演,不断丰富,最终让Spring成为有血有肉的完整的框架。所以查看Spring框架的源码时,有两条清晰可见的脉络:
-
接口层描述了容器的重要组件及组件间的协作关系;
-
继承体系逐步实现组件的各项功能。
接口层清晰地勾勒出Spring框架的高层功能,框架脉络呼之欲出。有了接口层抽象的描述后,不但Spring自己可以提供具体的实现,任何第三方组织也可以提供不同实现, 可以说Spring完善的接口层使框架的扩展性得到了很好的保证。纵向继承体系的逐步扩展,分步骤地实现框架的功能,这种实现方案保证了框架功能不会堆积在某些类的身上,造成过重的代码逻辑负载,框架的复杂度被完美地分解开了。
Spring组件按其所承担的角色可以划分为两类:
-
物料组件:Resource、BeanDefinition、PropertyEditor以及最终的Bean等,它们是加工流程中被加工、被消费的组件,就像流水线上被加工的物料;
-
BeanDefinition:Spring通过BeanDefinition将配置文件中的配置信息转换为容器的内部表示,并将这些BeanDefinition注册到BeanDefinitionRegistry中。Spring容器的后续操作直接从BeanDefinitionRegistry中读取配置信息。
-
加工设备组件:ResourceLoader、BeanDefinitionReader、BeanFactoryPostProcessor、InstantiationStrategy以及BeanWrapper等组件像是流水线上不同环节的加工设备,对物料组件进行加工处理。
-
InstantiationStrategy:负责实例化Bean操作,相当于Java语言中new的功能,并不会参与Bean属性的配置工作。属性填充工作留待BeanWrapper完成
-
BeanWrapper:继承了PropertyAccessor和PropertyEditorRegistry接口,BeanWrapperImpl内部封装了两类组件:(1)被封装的目标Bean(2)一套用于设置Bean属性的属性编辑器;具有三重身份:(1)Bean包裹器(2)属性访问器 (3)属性编辑器注册表。PropertyAccessor:定义了各种访问Bean属性的方法。PropertyEditorRegistry:属性编辑器的注册表。
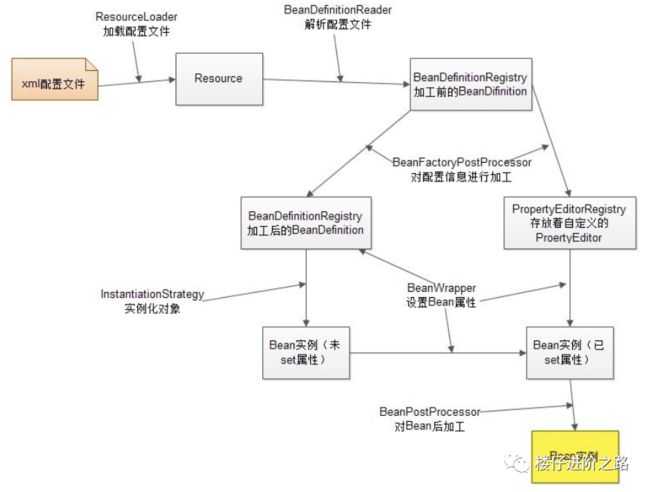
该图描述了Spring容器从加载配置文件到创建出一个完整Bean的作业流程:
-
ResourceLoader从存储介质中加载Spring配置信息,并使用Resource表示这个配置文件的资源;
-
BeanDefinitionReader读取Resource所指向的配置文件资源,然后解析配置文件。配置文件中每一个解析成一个BeanDefinition对象,并保存到BeanDefinitionRegistry中;
-
容器扫描BeanDefinitionRegistry中的BeanDefinition,使用Java的反射机制自动识别出Bean工厂后处理后器(实现BeanFactoryPostProcessor接口)的Bean,然后调用这些Bean工厂后处理器对BeanDefinitionRegistry中的BeanDefinition进行加工处理。主要完成以下两项工作:
-
对使用到占位符的元素标签进行解析,得到最终的配置值,这意味对一些半成品式的BeanDefinition对象进行加工处理并得到成品的BeanDefinition对象;
-
对BeanDefinitionRegistry中的BeanDefinition进行扫描,通过Java反射机制找出所有属性编辑器的Bean(实现java.beans.PropertyEditor接口的Bean),并自动将它们注册到Spring容器的属性编辑器注册表中(PropertyEditorRegistry);
-
Spring容器从BeanDefinitionRegistry中取出加工后的BeanDefinition,并调用InstantiationStrategy着手进行Bean实例化的工作;
-
在实例化Bean时,Spring容器使用BeanWrapper对Bean进行封装,BeanWrapper提供了很多以Java反射机制操作Bean的方法,它将结合该Bean的BeanDefinition以及容器中属性编辑器,完成Bean属性的设置工作;
-
利用容器中注册的Bean后处理器(实现BeanPostProcessor接口的Bean)对已经完成属性设置工作的Bean进行后续加工,直接装配出一个准备就绪的Bean。
小结一下:
Spring IOC容器主要有继承体系底层的BeanFactory、高层的ApplicationContext和WebApplicationContext。
Bean有自己的生命周期,容器加载Bean原理:
BeanDefinitionReader读取Resource所指向的配置文件资源,然后解析配置文件。配置文件中每一个解析成一个BeanDefinition对象,并保存到BeanDefinitionRegistry中;
容器扫描BeanDefinitionRegistry中的BeanDefinition;调用InstantiationStrategy进行Bean实例化的工作;使用BeanWrapper完成Bean属性的设置工作;
单例Bean缓存池:Spring 在 DefaultSingletonBeanRegistry 类中提供了一个用于缓存单实例 Bean 的缓存器,它是一个用 HashMap 实现的缓存器,单实例的 Bean 以 beanName 为键保存在这个HashMap 中。
BeanFacotry vs FactoryBean
这个面试经常会问到,然后对这块我觉得也有点意思,就作为基础内容的一部分。
两者区别
BeanFactory是接口,提供了OC容器最基本的形式,给具体的IOC容器的实现提供了规范,
FactoryBean也是接口,为IOC容器中Bean的实现提供了更加灵活的方式,FactoryBean在IOC容器的基础上给Bean的实现加上了一个简单工厂模式和装饰模式,我们可以在getObject()方法中灵活配置。其实在Spring源码中有很多FactoryBean的实现类。
区别:BeanFactory是个Factory,也就是IOC容器或对象工厂,FactoryBean是个Bean。在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似。
BeanFactory
回顾一下:BeanFactory,以Factory结尾,表示它是一个工厂类(接口), 它负责生产和管理bean的一个工厂。在Spring中,BeanFactory是IOC容器的核心接口,它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。BeanFactory只是个接口,并不是IOC容器的具体实现,但是Spring容器给出了很多种实现,如 DefaultListableBeanFactory、XmlBeanFactory、ApplicationContext等,其中XmlBeanFactory就是常用的一个,该实现将以XML方式描述组成应用的对象及对象间的依赖关系。XmlBeanFactory类将持有此XML配置元数据,并用它来构建一个完全可配置的系统或应用。
更详细的内容,直接看文章的”BeanFactory“部分。
FactoryBean
一般情况下,Spring通过反射机制利用的class属性指定实现类实例化Bean,在某些情况下,实例化Bean过程比较复杂,如果按照传统的方式,则需要在中提供大量的配置信息。配置方式的灵活性是受限的,这时采用编码的方式可能会得到一个简单的方案。Spring为此提供了一个FactoryBean的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。Spring自身就提供了70多个FactoryBean的实现,它们隐藏了实例化一些复杂Bean的细节,给上层应用带来了便利。
接口中定义的方法如下:
public interface FactoryBean {
/**
* 返回对象的实例
*/
T getObject() throws Exception;
/**
* 返回对象的类型
*/
Class getObjectType();
/**
* 是否是单例
*/
boolean isSingleton();
}
最好的学习就是动手实践一下,我们看一下spring如何通过Factorybean配置Bean,我们先定义一个car对象:
@Data
public class Car {
private int maxSpeed;
private String brand;
private double price;
}
在定义一个CarFactoryBean,用来包装Car实例:
public class CarFactoryBean implements FactoryBean {
private String carInfo ;
/**
* 自定义创建bean的过程,可以定制复杂的创建过程
*/
@Override
public Car getObject() throws Exception {
Car car = new Car();
String[] infos = carInfo.split(",");
car.setBrand(infos[0]);
car.setMaxSpeed(Integer.valueOf(infos[1]));
car.setPrice(Double.valueOf(infos[2]));
return car;
}
/**
* 获取FactoryBean创建bean的类型
*/
@Override
public Class getObjectType() {
return Car.class;
}
/**
* 创建的bean,是否是单例
*/
@Override
public boolean isSingleton() {
return false;
}
public String getCarInfo() {
return carInfo;
}
/**
* 接受逗号分隔符,设置属性
*/
public void setCarInfo(String carInfo) {
this.carInfo = carInfo;
}
}
这里是重点,需要添加如下配置:
最后测试用例如下:
public class MyFactoryBeanTest {
/**
* 测试验证FactoryBean原理,代理一个servcie在调用其方法的前后,打印日志亦可作其他处理
* 从ApplicationContext中获取自定义的FactoryBean
* context.getBean(String beanName) ---> 最终获取到的Object是FactoryBean.getObejct(),
* 使用Proxy.newInstance生成service的代理类
*/
@Test
public void testFactoryBean() {
ApplicationContext context =new ClassPathXmlApplicationContext("classpath:applicationContext.xml");
Car car = (Car) context.getBean("car");
System.out.println(car.toString());
}
}
// 输出:
// Car(maxSpeed=420, brand=法拉利跑车, price=2600000.0)
测试的时候,我还特意打了个断点,确实会进入getObject()中:
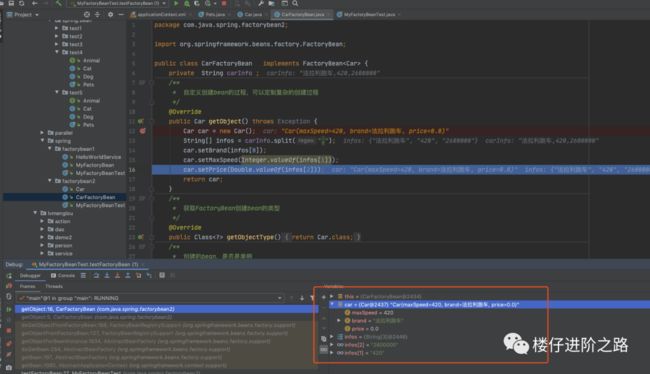
网上本来找了2个示例,但是有一个一直跑步起来,然后这个示例,我找了N多个相关的博客,给出的示例都是缺胳膊少腿,完全不能运行,倒腾了大半个小时,终于倒腾出一个能运行的完整版本。
总结
对于IOC和DI理解,本文给出了2个比较经典的说明;对于BeanFactory和ApplicationContext的区别是使用方式,本文也从整体架构和使用姿势上,给了详细的说明;对于Bean生命周期和加载过程,这个应该是本文非常重要的内容,我觉得这块也是最有意思的。最后就是BeanFactory和FactoryBean,其实主要讲解FactoryBean,然后给了一个完整的示例。
这篇文章,除了示例部分是我写的,或者是我加工后的,八股文部分全部是摘抄自网络的博客,为了整理这篇比较全的IOC文章,也是看了大量的博客,之前本来打算买一本Spring相关的书籍来看的,因为时间原因,就还是找博客来学习吧,等我把Java生态的基础知识都学完后,我再重点学习更深入的知识,比如Spring框架源码。
可能有同学会说,你把网络上的整理资料汇总起来,有什么意义呢?其实这个对自己还是有很大帮助的,一方面你汇总这些资料,你其实需要看更多的资料,只有当你基本全部消耗完后,你才知道如何去整理相关文章,我之前没有写整理类的文章,这些博客看完后,过段时间就忘了。然后还有很重要的一点,整理文章,可以让你重新去熟悉这些知识,你能整理出来,证明你基本已经掌握了这些知识。因为这是你自己整理的知识,所以如果你想再捡起来,其实很很快,因为这篇文章是你概括的核心重点,如果你没有整理,等忘记是再重新去翻阅网络上的博客,你会被大量知识给淹没。
正所谓我不入地狱,谁如地狱,文章核心点都给大家整理好了,你如果想学习相关内容,整理好的资料你都不想看,你觉得你好意思么?
主要参考资料:
-
Spring IOC知识点一网打尽:https://juejin.cn/post/6844903609067372558#heading-30
-
Spring系列之beanFactory与ApplicationContext:https://www.cnblogs.com/xiaoxi/p/5846416.html
-
Spring IOC原理总结:https://zhuanlan.zhihu.com/p/29344811
-
详解Spring IOC:https://www.jianshu.com/p/b60c30fdcc65 BeanFactory和FactoryBean区别:https://www.cnblogs.com/aspirant/p/9082858.html
欢迎大家多多点赞,更多文章,请关注微信公众号“楼仔进阶之路”,点关注,不迷路~~